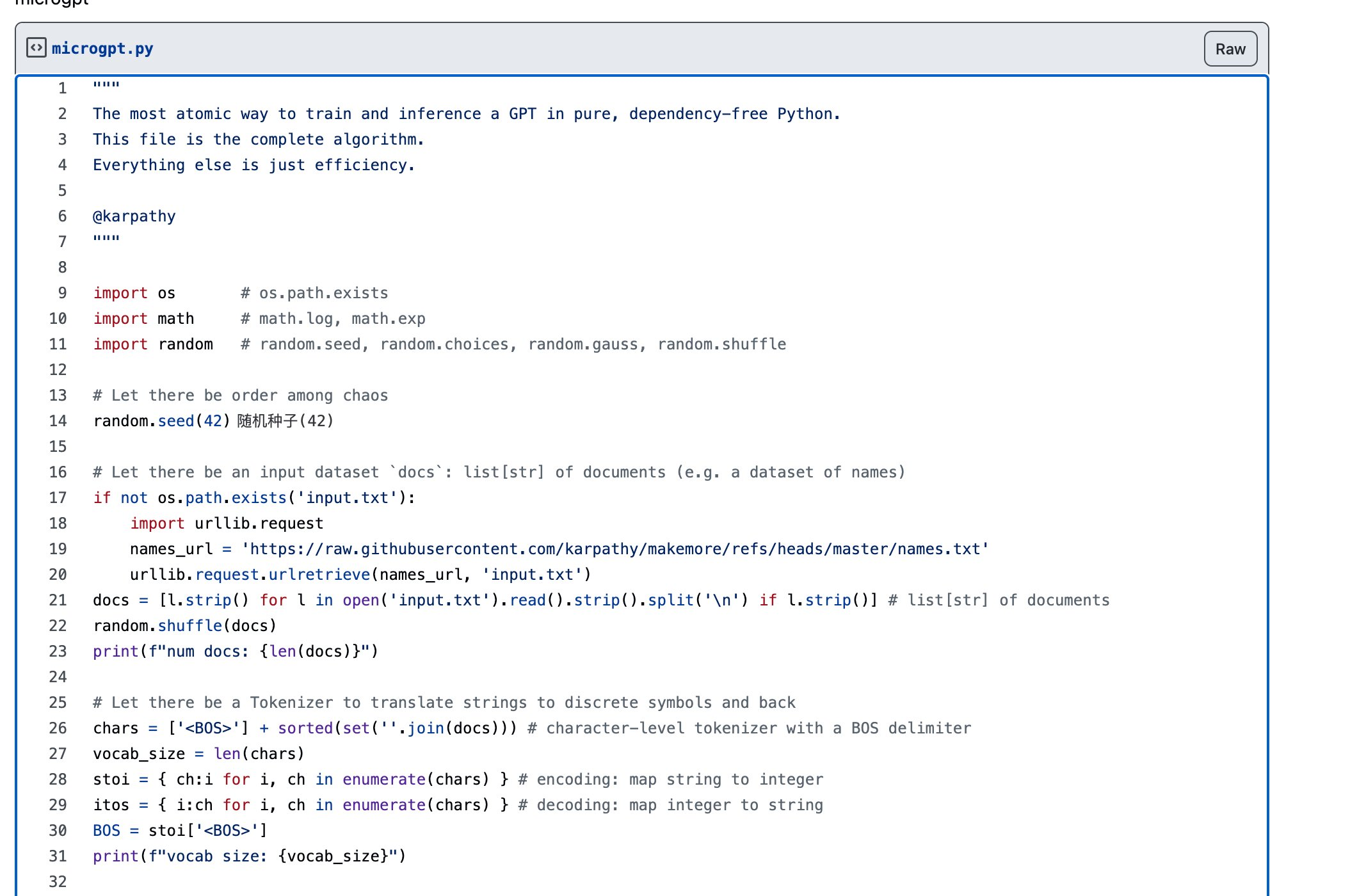
你看到的这份 microgpt.py,厉害之处不在"短",而在"狠"。它把 GPT 这套体系里最核心的那条链路------数据 → token → 前向 → loss → 反向 → 参数更新 → 采样生成------压缩成一个人可以完整读完、在脑子里跑通的实现。
这篇文章按"从输入到输出"的顺序,把它拆成 8 个层级。你读完会获得两种东西:一套 GPT 的可执行直觉,一套看任何 Transformer 代码都能对齐的坐标系。
1)这份代码到底"实现了什么 GPT"
microGPT 做的是一个字符级(char-level)的小 GPT,常用 names 数据集训练,目标是学会生成"像名字的字符串"。这意味着:
-
词表是字符集合,不是 BPE/WordPiece
-
模型规模很小,能在 CPU 上跑
-
实现强调算法链路完整性,性能和规模不在目标里
你可以把它当成"可执行的 Transformer 教科书"。它覆盖了 GPT 的核心结构与训练推理闭环,覆盖不了工业级大模型那套工程系统(GPU 张量库、自动微分、并行、混合精度、KV cache 优化、分布式通信等)。
2)数据与 Tokenizer:GPT 的第一道"语义-数字翻译"
你截图里那段代码就在干这件事:把文本翻译成整数序列。
2.1 训练样本:docs
names 数据集每行一个名字,最后得到:
-
docs: list[str],样本列表 -
shuffle 打乱,避免训练顺序偏置
2.2 词表:chars
chars = ['<BOS>'] + sorted(set(''.join(docs)))
vocab_size = len(chars)关键点有两个:
-
set(''.join(docs))把全数据集出现过的字符都收集出来,形成词表 -
<BOS>是序列起始符,训练与生成时用来让模型知道"从头开始"
2.3 映射表:stoi / itos
stoi = {ch:i for i, ch in enumerate(chars)}
itos = {i:ch for i, ch in enumerate(chars)}
BOS = stoi['<BOS>']这就是 tokenizer 的全部:字符 ⇄ 整数。
这一步的意义很"物理":神经网络只吃数字。语言这层外壳必须被剥离成离散 token,模型才能开始学习统计规律。
3)训练数据如何喂给模型:从"文本样本"变成"监督信号"
GPT 的训练目标是:给定前缀,预测下一个 token。
对于一个名字 "emma",加上 <BOS> 后对应 token 序列可能是:
<BOS> e m m a
训练会构造监督对齐:
-
输入序列:
<BOS> e m m -
目标序列:
e m m a
也就是把序列整体右移一格,形成 "x → y"。
这件事在所有 GPT 训练里都成立。差别只在 token 的粒度与序列长度。
4)模型参数长什么样:Transformer 被拆成"几块矩阵"
microGPT 的核心设计思路是:用最少的数据结构表示 Transformer。你通常会看到几类参数:
1)Embedding(词向量表)
-
token_embedding_table: [vocab_size, n_embd] -
把 token id 映射成向量
2)Position Embedding(位置向量表)
-
position_embedding_table: [block_size, n_embd] -
给每个位置一个可学习向量,让模型区分"第 1 个字"和"第 10 个字"
3)Attention 的 Q/K/V 投影矩阵
-
Wq, Wk, Wv: [n_embd, head_size]或合并形式 -
把输入向量映射到 query/key/value
4)Attention 输出投影矩阵
Wo: [n_embd, n_embd]
5)MLP(前馈网络)
W1, b1、W2, b2两层线性,中间一个非线性(常见 tanh/relu)
6)最终输出层(语言模型头)
-
Wlm: [n_embd, vocab_size] -
把隐藏状态投影回词表维度,得到每个 token 的 logits
这些矩阵合在一起,就构成了一个完整 GPT Block 的最小表达。
5)前向传播:从 token 到 logits 的整条路径
前向传播是推理的核心,也是训练的第一步。它会把输入 token 序列 idx 变成每个位置对下一个 token 的预测分布。
典型路径长这样:
5.1 token + position
x = tok_emb[idx] + pos_emb[pos]
这一步把"字"与"位置"融进一个向量空间。没有 position embedding,注意力机制无法感知顺序。
5.2 自注意力(Self-Attention)
注意力做的事可以用一句话描述:
每个位置产生一个 query,去和所有历史位置的 key 做相似度,得到权重,再对 value 做加权求和。
数学上:
-
q = x Wq -
k = x Wk -
v = x Wv -
att = softmax(q k^T / sqrt(d)) -
out = att v
5.3 因果遮罩(causal mask)
GPT 训练与推理必须满足"只看过去"。所以注意力矩阵会强制:
-
当前位置只能 attend 到
<= 当前的位置 -
att[i, j] = -infforj > i(softmax 后变成 0)
这就是 GPT 与 BERT 的结构分水岭:GPT 的注意力是单向因果的。
5.4 残差 + 归一化(实现可能简化)
工业实现会有 LayerNorm + Residual,microGPT 可能用更原始的形式表达,核心目的在于保持信号稳定,便于训练。
5.5 MLP
x = x + MLP(x)
MLP 提供非线性表达能力,注意力提供信息路由能力,两者组合才是 Transformer 的完整威力。
5.6 输出 logits
logits = x Wlm
logits 的维度是 [T, vocab_size],每个时间步都对应一个词表分布的未归一化分数。
6)Loss:把"预测"变成可优化的标量
训练目标是最大化正确 token 的概率,等价于最小化交叉熵。
对于某个位置的 logits 向量 z:
-
p = softmax(z) -
loss = -log p[target_id]
训练会对所有时间步求平均,得到一个标量 loss。
这一步非常关键,因为它把"语言建模"这个任务变成一个数值优化问题。只有 loss 是标量,反向传播才有明确方向。
7)反向传播:这份代码最"硬核"的地方
真正让人佩服的是:它在没有任何深度学习框架的情况下,仍然实现了梯度计算并更新参数。
这里你要抓住一个核心事实:
训练=前向图 + 反向链式法则 + 参数更新。
PyTorch 之类框架帮你做了"计算图与自动微分"。microGPT 选择手写。
7.1 softmax 的梯度
softmax + 交叉熵的组合有一个著名的简化:
dlogits = p; dlogits[target] -= 1
再除以 batch/sequence 的平均系数。
这一步让反向传播非常直接,避免手动推导完整的 softmax Jacobian。
7.2 矩阵乘法的梯度
对于 y = xW:
-
dW = x^T dy -
dx = dy W^T
Transformer 的大部分梯度都在重复这条规则。
7.3 Attention 的梯度
注意力里最麻烦的是:
-
att = softmax(scores) -
out = att v -
scores = q k^T / sqrt(d)+ mask
每一块都要往回传梯度,softmax 需要处理数值稳定,mask 需要确保未来位置梯度为 0。
microGPT 的写法通常会把中间缓存保存下来(比如 q/k/v、att、softmax 输出),让反向阶段能读到这些中间量完成链式回传。
这种"前向缓存 + 反向用缓存"是手写反传的通用模式。
8)参数更新:最朴素的 SGD
训练最后一步是:
param -= lr * grad
代码短到可怕,意义也简单到可怕:
-
梯度给方向
-
学习率给步长
-
更新重复很多步,模型就会拟合数据分布
工业级训练会用 AdamW、weight decay、梯度裁剪、学习率调度、混合精度等。microGPT 用最朴素的方式把"优化闭环"跑通。
9)推理生成:从概率分布里"采样未来"
推理阶段的关键动作是:拿到 logits,转成概率,采样一个 token,拼回上下文。
9.1 只取最后一个位置的 logits
因为我们在生成下一个 token:
-
输入是当前上下文
-
输出只关心最后一步的预测
9.2 softmax + sampling
-
p = softmax(logits_last) -
next_id = random.choices(range(vocab_size), weights=p)[0]
这一步决定生成风格:
-
直接 argmax 会变得更确定、更重复
-
采样会更发散、更像自然语言
9.3 自回归循环
把 next_id append 回输入序列,继续跑下一步,直到生成长度够了或生成到终止符(字符级数据集通常没有 EOS,会用长度控制)。
这就是 GPT 的"自回归本质":模型每次只预测一步,文本是一步一步长出来的。
10)你那句"普实无华搞定 GPT"如何改成更硬的表述
你这句本身很有传播力,适合社媒。技术文章里可以写得更锋利一点:
-
这份代码用标准库实现了 GPT 的训练与推理闭环,完整覆盖 tokenizer、Transformer 前向、交叉熵损失、手写反向传播与采样生成。
-
代码规模很小,强调可读性与概念完整性,计算效率与工业可扩展性不在目标里。
-
它把 GPT 从"神秘系统"还原成"可推导、可运行、可修改"的算法骨架,读完之后看任何框架版实现都能迅速对齐结构。
11)读完之后你该怎么看这份代码
如果你打算把它变成"自己的能力",建议用三次阅读把它吃透:
第一次只看数据与生成流程:从 docs 到 stoi/itos 到 sample(),建立闭环直觉。
第二次只看 attention:找到 q/k/v、mask、softmax、加权求和,画一张数据流图。
第三次只看 backward:把每个矩阵乘的梯度写到纸上,和代码逐行对齐。
你做完第三次,你就拥有了"拆任何 Transformer 实现"的通用技能。