㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~
㊙️本期爬虫难度指数:⭐⭐⭐
🉐福利: 一次订阅后,专栏内的所有文章可永久免费看,持续更新中,保底1000+(篇)硬核实战内容。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract)](#1️⃣ 摘要(Abstract))
- [2️⃣ 背景与需求(Why)](#2️⃣ 背景与需求(Why))
- [3️⃣ 合规与注意事项(必写)](#3️⃣ 合规与注意事项(必写))
- [4️⃣ 技术选型与整体流程(What/How)](#4️⃣ 技术选型与整体流程(What/How))
- [5️⃣ 环境准备与依赖安装(可复现)](#5️⃣ 环境准备与依赖安装(可复现))
- [6️⃣ 核心实现:浏览器交互层(Fetcher)](#6️⃣ 核心实现:浏览器交互层(Fetcher))
- [7️⃣ 核心实现:滚动与解析层(Action & Parser)](#7️⃣ 核心实现:滚动与解析层(Action & Parser))
- [8️⃣ 数据存储与导出(Storage)](#8️⃣ 数据存储与导出(Storage))
- [9️⃣ 运行方式与结果展示(必写)](#9️⃣ 运行方式与结果展示(必写))
- [🔟 常见问题与排错(老司机的血泪史)](#🔟 常见问题与排错(老司机的血泪史))
- [1️⃣1️⃣ 进阶优化(可选但加分)](#1️⃣1️⃣ 进阶优化(可选但加分))
- [1️⃣2️⃣ 总结与延伸阅读](#1️⃣2️⃣ 总结与延伸阅读)
- [🌟 文末](#🌟 文末)
-
- [✅ 专栏持续更新中|建议收藏 + 订阅](#✅ 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
- [✅ 免责声明](#✅ 免责声明)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅专栏👉《Python爬虫实战》👈,一次订阅后,专栏内的所有文章可永久免费阅读,持续更新中。
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract)
本文将针对采用 JavaScript 动态渲染 或 无限滚动(Infinite Scroll) 技术的现代名言网站。我们将放弃传统的 HTTP 请求库,转而使用微软开源的自动化测试神器 Playwright。
通过编写异步(Async)脚本,我们将模拟真实用户的浏览器行为:自动打开网页 -> 平滑滚动底部 -> 等待数据渲染 -> 提取 DOM 元素 。最终抓取名言内容 、作者 及出处 ,并以 JSON Lines (JSONL) 格式存储,适合大数据量流式读写。
读完这篇你能获得什么?
- 🎮 浏览器操控:学会如何用代码控制 Chrome/Edge 浏览器进行点击、输入和滚动。
- ⏳ 异步思维 :彻底理解
async/await在爬虫中的应用,效率吊打同步代码。 - 🔄 动态处理:搞定那些"右键查看源代码"找不到内容的网站。
2️⃣ 背景与需求(Why)
为什么要用 Playwright?
很多"小清新"的名言站为了美观,使用了 Vue/React 框架。数据是你在浏览时通过 JS 异步加载的。
- 如果你用
requests:得到<div>Loading...</div>。❌ - 如果你用
Playwright:得到渲染完成的完整 HTML。✅
目标站点 :假设某名言站 https://quotes.example-spa.com,页面底部有一个"加载更多"按钮,或者鼠标滚到底自动加载新内容。
目标字段清单:
| 字段名 | 说明 | 示例值 |
|---|---|---|
quote_text |
名言正文 | 既然选择了远方,便只顾风雨兼程。 |
author |
作者 | 汪国真 |
source |
出处/语录集 | 《热爱生命》 |
tags |
标签 | #励志 #青春 |
3️⃣ 合规与注意事项(必写)
动态爬虫的杀伤力更大,请务必克制!
- 资源消耗 :Playwright 会启动真实的浏览器内核(Headless Mode),这比
requests消耗的内存和 CPU 高出 10 倍以上。 - 对服务器的影响 :虽然你只是一个客户端,但频繁的渲染请求会给服务器造成较大压力。务必设置
slow_mo(慢动作)延迟。 - Headless 检测:现代网站会检测你是否在使用"无头浏览器"。虽然 Playwright 伪装性很好,但尽量不要在大规模采集时并发过多。
4️⃣ 技术选型与整体流程(What/How)
技术选型:Async Playwright + Pandas
- Async Playwright :相比 Selenium,Playwright 原生支持异步,启动速度快,且支持自动等待元素出现(Auto-wait),不用像 Selenium 那样写一堆
time.sleep或WebDriverWait。 - JSONL (JSON Lines):相比 CSV,JSONL 每一行是一个 JSON 对象,非常适合这种"一边滚一边存"的流式数据,写坏了也不影响前面的数据。
整体流程图:
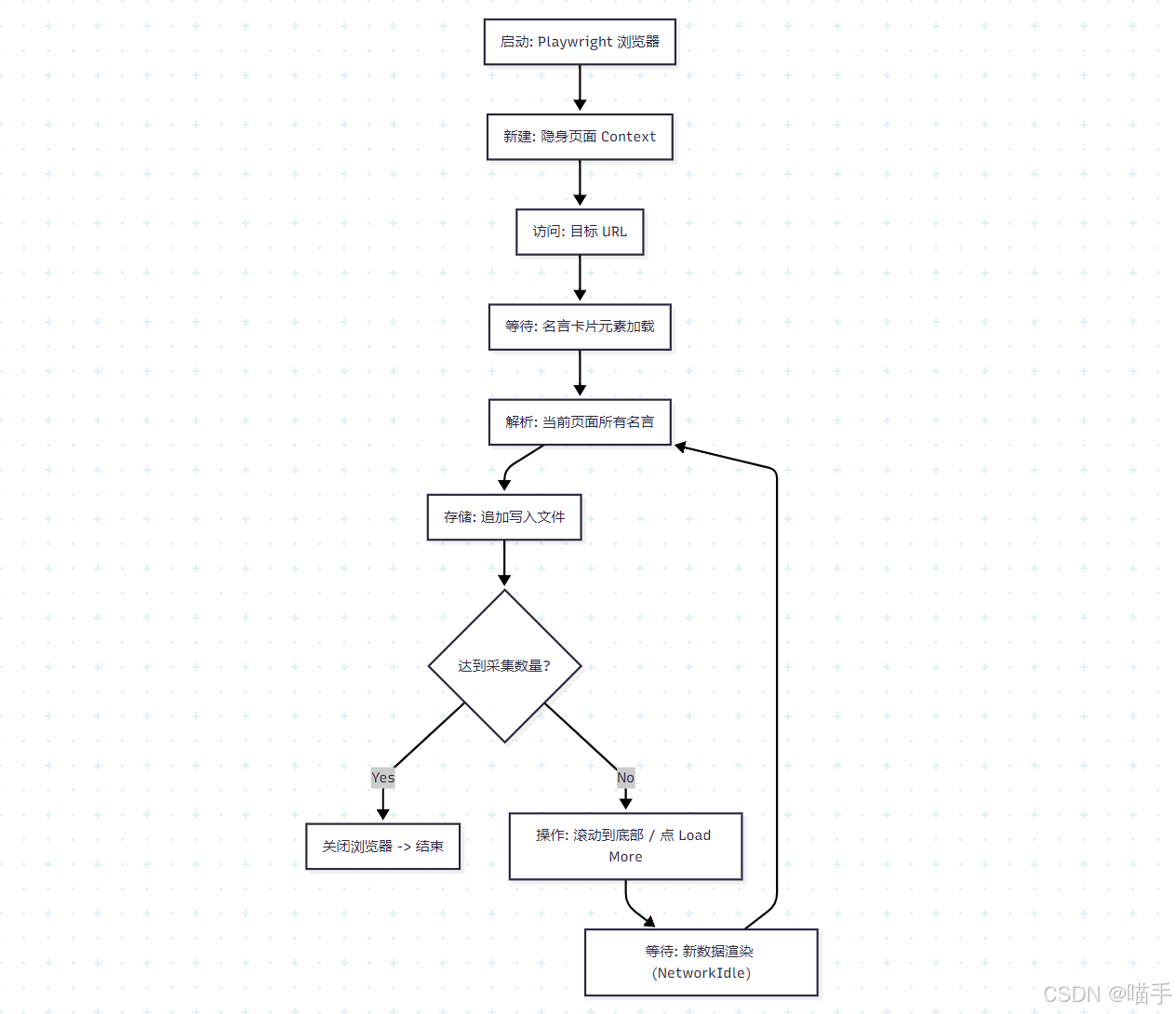
5️⃣ 环境准备与依赖安装(可复现)
Python 版本:3.8+ (异步库对版本有要求)
依赖安装 :
Playwright 需要两步安装:先装库,再下载浏览器驱动。
bash
# 1. 安装库
pip install playwright pandas
# 2. 安装浏览器内核 (Chromium, Firefox, WebKit)
playwright install项目结构:
text
dynamic_spider/
├── data/
│ └── quotes_stream.jsonl # 结果文件
├── spider_main.py # 主程序
└── config.py # 配置文件6️⃣ 核心实现:浏览器交互层(Fetcher)
这是 Playwright 的核心魅力所在。我们不仅要下载网页,还要动起来。
python
import asyncio
from playwright.async_api import async_playwright, TimeoutError
class DynamicFetcher:
def __init__(self):
self.browser = None
self.context = None
self.page = None
async def start_browser(self):
"""启动浏览器"""
self.p = await async_playwright().start()
# headless=False 可以看到浏览器界面,调试时非常有用!
# slow_mo=500 每个操作慢 500ms,像真人一样
self.browser = await self.p.chromium.launch(headless=False, slow_mo=500)
# 创建上下文,设置 Viewport 大小,伪装 UA
self.context = await self.browser.new_context(
viewport={'width': 1920, 'height': 1080},
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0 Safari/537.36'
)
self.page = await self.context.new_page()
async def close_browser(self):
"""关闭资源"""
await self.browser.close()
await self.p.stop()
async def get_page_content(self, url):
"""访问页面并等待加载"""
print(f"🌍 正在访问: {url}")
await self.page.goto(url, wait_until='domcontentloaded') # 等待 DOM 加载完即可
# 🔥 关键:等待第一个名言卡片出现,确保 JS 渲染完成
# 假设名言卡片的 class 是 .quote-card
try:
await self.page.wait_for_selector('.quote-card', timeout=10000)
except TimeoutError:
print("⚠️ 页面加载超时或未发现内容")
return None
return self.page7️⃣ 核心实现:滚动与解析层(Action & Parser)
这里我们要实现一个"滚动 -> 抓取 -> 再滚动"的循环逻辑。
python
class ActionParser:
async def parse_current_items(self, page):
"""解析当前页面可见的所有名言"""
# Playwright 的 $$ 相当于 document.querySelectorAll
cards = await page.query_selector_all('.quote-card')
results = []
for card in cards:
# 提取文本内容
# await card.query_selector('.content') 获取子元素
content_el = await card.query_selector('.quote-text')
author_el = await card.query_selector('.quote-author')
source_el = await card.query_selector('.quote-source')
# inner_text() 获取可见文本
content = await content_el.inner_text() if content_el else ""
author = await author_el.inner_text() if author_el else "佚名"
source = await source_el.inner_text() if source_el else ""
# 简单的清洗
if content:
results.append({
"content": content.strip(),
"author": author.replace('---', '').strip(),
"source": source.replace('《', '').replace('》', '').strip()
})
return results
async def load_more(self, page):
"""核心动作:滚动加载更多"""
try:
# 方式 1:如果有"加载更多"按钮,点击它
load_btn = await page.query_selector('button.load-more')
if load_btn and await load_btn.is_visible():
print("🖱️ 点击 '加载更多' 按钮...")
await load_btn.click()
return True
# 方式 2:无限滚动 (Infinite Scroll)
# 模拟 JS 滚动到底部
print("📜 滚动到页面底部...")
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# 等待新内容加载(可以通过判断页面高度变化,这里简单 wait_for_timeout)
await page.wait_for_timeout(2000) # 等待 2 秒
return True
except Exception as e:
print(f"⚠️ 加载更多动作失败: {e}")
return False8️⃣ 数据存储与导出(Storage)
对于流式采集,jsonl 是最佳伴侣。我们每抓到一批,就追加写入文件,不用担心内存溢出。
python
import json
import os
class JsonlStorage:
def __init__(self, filename="quotes_stream.jsonl"):
self.filepath = os.path.join("data", filename)
os.makedirs("data", exist_ok=True)
# 用集合来做去重(基于 content 的哈希)
self.seen_hashes = set()
def save_batch(self, items):
"""追加写入,并去重"""
new_count = 0
with open(self.filepath, 'a', encoding='utf-8') as f:
for item in items:
# 生成唯一指纹
item_hash = hash(item['content'])
if item_hash in self.seen_hashes:
continue
self.seen_hashes.add(item_hash)
# 写入一行 JSON
f.write(json.dumps(item, ensure_ascii=False) + '\n')
new_count += 1
print(f"💾 已保存 {new_count} 条新数据 (总计: {len(self.seen_hashes)})")9️⃣ 运行方式与结果展示(必写)
这里需要用 asyncio.run() 来启动整个异步流程。
python
# spider_main.py
import asyncio
from datetime import datetime
# ... 导入 DynamicFetcher, ActionParser, JsonlStorage ...
async def main():
print("🚀 Playwright 动态爬虫启动...")
fetcher = DynamicFetcher()
parser = ActionParser()
storage = JsonlStorage()
target_url = "https://quotes.toscrape.com/scroll" # 这是一个专门供练习滚动爬取的网站
# 1. 启动浏览器
await fetcher.start_browser()
page = await fetcher.get_page_content(target_url)
if not page:
await fetcher.close_browser()
return
# 2. 循环采集
max_scrolls = 5 # 演示:只滚动 5 次
scroll_count = 0
while scroll_count < max_scrolls:
scroll_count += 1
print(f"\n🔄 第 {scroll_count} 轮采集...")
# 抓取当前数据
items = await parser.parse_current_items(page)
if items:
storage.save_batch(items)
# 触发加载更多
success = await parser.load_more(page)
if not success:
print("🚫 无法继续加载,任务结束。")
break
# 随机等待,防封
await asyncio.sleep(1)
# 3. 结束清理
print("\n🏁 采集完成,正在关闭浏览器...")
await fetcher.close_browser()
if __name__ == "__main__":
asyncio.run(main())示例运行输出:
text
🚀 Playwright 动态爬虫启动...
🌍 正在访问: https://quotes.toscrape.com/scroll
🔄 第 1 轮采集...
💾 已保存 10 条新数据 (总计: 10)
📜 滚动到页面底部...
🔄 第 2 轮采集...
💾 已保存 10 条新数据 (总计: 20)
📜 滚动到页面底部...
...
🏁 采集完成,正在关闭浏览器...🔟 常见问题与排错(老司机的血泪史)
-
Playwright 安装失败 / 找不到浏览器
- 原因 :只运行了
pip install,没运行playwright install。 - 解法 :在终端运行
playwright install下载 WebKit/Chromium 核心。
- 原因 :只运行了
-
元素定位报错
ElementHandle is not attached to the DOM- 原因:这是动态网页最常见的问题。当你刚获取到一个元素对象,页面刷新了或 JS 重绘了,那个元素 ID 变了或消失了。
- 解法 :尽量每次操作前都重新查询元素,不要把 Element 对象存太久。或者使用 Locator 对象(
page.locator(...)),它是惰性的,操作时才会去查找。
-
数据重复太严重
- 原因:因为我们是"解析整个列表 -> 滚动 -> 解析整个列表"。每次都会包含上一轮已经抓过的数据。
- 解法 :所以我在
JsonlStorage里加了seen_hashes去重逻辑。这是处理无限滚动列表的必修课。
1️⃣1️⃣ 进阶优化(可选但加分)
-
拦截网络请求(Network Interception) :
Playwright 最强的一点是可以拦截 HTTP 请求。
既然页面是 AJAX 加载的,我们可以直接监听
response事件,拦截后台返回的 JSON 数据!这比解析 HTML 稳定得多。python# 示例:只监听 API 响应 async def handle_response(response): if "api/quotes" in response.url and response.status == 200: json_data = await response.json() print("🔥 捕获到 API 数据:", len(json_data)) page.on("response", handle_response) -
自动截图与生成海报 :
利用
await card.screenshot(path="quote_1.png"),你可以把抓到的每一句名言直接截图保存,做成素材库。 -
Docker 部署 :
Playwright 在 Linux 服务器上运行需要安装很多依赖。建议使用官方提供的 Docker 镜像
mcr.microsoft.com/playwright:v1.40.0-focal,省去配环境的麻烦。
1️⃣2️⃣ 总结与延伸阅读
复盘 :
这篇教程带你跨越了爬虫界的一道分水岭 ------ 从静态到动态。我们不再是简单的下载器,而是成为了浏览器的"驾驶员"。通过 Playwright,我们成功搞定了那些需要 JS 渲染、需要点击交互的现代网站。
下一步:
- 挑战验证码:如果网站弹出滑块验证码,Playwright 可以模拟鼠标拖动(Drag and Drop)来破解简单的滑块。
- 并发提速:Playwright 支持同时启动多个 Browser Context(上下文),你可以开 5 个窗口并行爬取不同分类的名言,效率直接起飞!🚀
代码写完了,别忘了去 data 文件夹里看看你收获的智慧金句哦!
🌟 文末
好啦~以上就是本期的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
✅ 专栏持续更新中|建议收藏 + 订阅
墙裂推荐订阅专栏 👉 《Python爬虫实战》,本专栏秉承着以"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一期内容都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴 :强烈建议先订阅专栏 《Python爬虫实战》,再按目录大纲顺序学习,效率十倍上升~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】等写成某期实战?
评论区留言告诉我你的需求,我会优先安排实现(更新)哒~
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
✅ 免责声明
本文爬虫思路、相关技术和代码仅用于学习参考,对阅读本文后的进行爬虫行为的用户本作者不承担任何法律责任。
使用或者参考本项目即表示您已阅读并同意以下条款:
- 合法使用: 不得将本项目用于任何违法、违规或侵犯他人权益的行为,包括但不限于网络攻击、诈骗、绕过身份验证、未经授权的数据抓取等。
- 风险自负: 任何因使用本项目而产生的法律责任、技术风险或经济损失,由使用者自行承担,项目作者不承担任何形式的责任。
- 禁止滥用: 不得将本项目用于违法牟利、黑产活动或其他不当商业用途。
- 使用或者参考本项目即视为同意上述条款,即 "谁使用,谁负责" 。如不同意,请立即停止使用并删除本项目。!!!
