同步io相关模块的行为
gdb调试mysql io部分代码
- mysql重启下,然后启动之前把
rm -rf ib_buffer_pool删了,否则缓存了不会走io逻辑。 - gdb加个缓存,挂上去会快很多,
alias gdbp='gdb -iex "set index-cache on" -iex "set index-cache directory /tmp/gdb-cache" -iex "set pagination off" -p '。 - 执行一个insert即可,执行流程会涉及几层逻辑,这里关注后两层 :fil、os
断点位置
c
# ======= SQL → InnoDB Handler =======
b ha_innobase::write_row
# ======= Buffer Pool =======
b buf_page_get_gen
b Buf_fetch_normal::get
b buf_read_page
b buf_read_page_low
# ======= fil 层 =======
b fil_io
b Fil_shard::do_io
b pfs_os_aio_func
# ======= os 层 =======
b os_aio_func
b os_file_read_func
b os_file_read_page
b os_file_pread
b os_file_io
b SyncFileIO::execute这里关注后两层 fil层 和 os 层
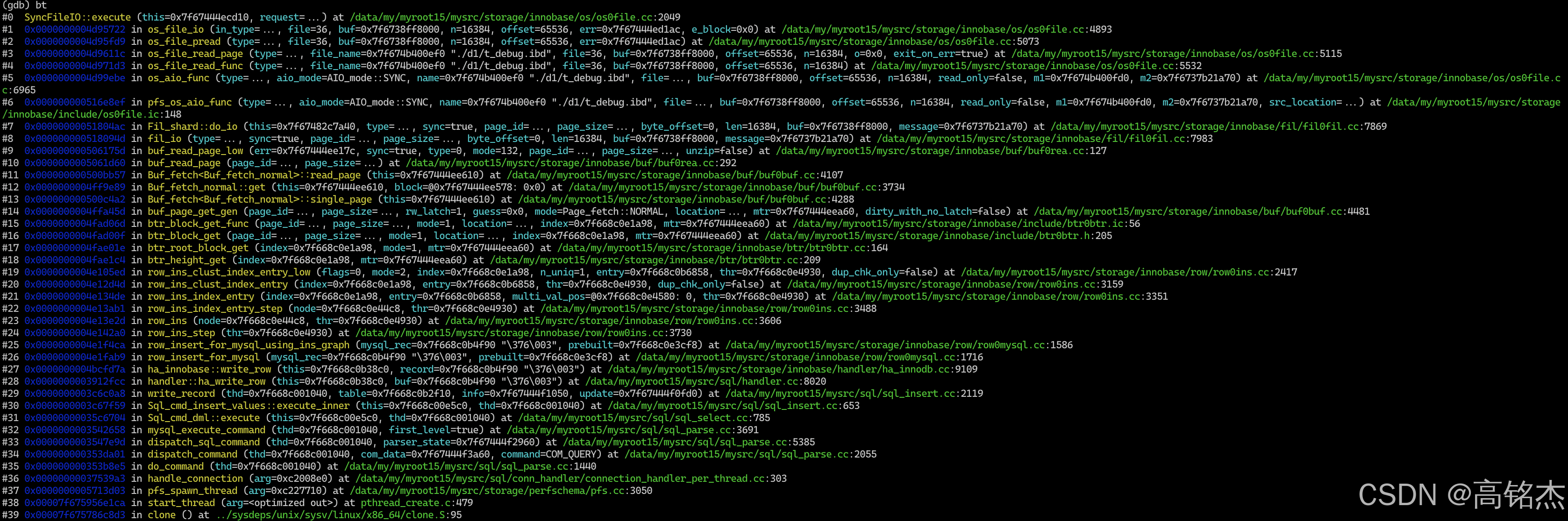
堆栈整理:
| 层级 | # | 函数 | 源文件 | 说明 |
|---|---|---|---|---|
| 线程入口 | #39 | clone() |
clone.S:95 | 系统调用,创建线程 |
| #38 | start_thread() |
pthread_create.c:479 | pthread 线程启动 | |
| #37 | pfs_spawn_thread() |
pfs.cc:3050 | PFS 包装的线程入口 | |
| 连接处理 | #36 | handle_connection() |
connection_handler_per_thread.cc:303 | 每连接一个线程,处理连接 |
| #35 | do_command() |
sql_parse.cc:1440 | 读取并分发客户端命令 | |
| #34 | dispatch_command() |
sql_parse.cc:2055 | 分发 COM_QUERY 命令 | |
| SQL 解析执行 | #33 | dispatch_sql_command() |
sql_parse.cc:5385 | 解析 SQL 文本 |
| #32 | mysql_execute_command() |
sql_parse.cc:3691 | 执行 SQL 命令 | |
| #31 | Sql_cmd_dml::execute() |
sql_select.cc:785 | DML 通用执行框架 | |
| #30 | Sql_cmd_insert_values::execute_inner() |
sql_insert.cc:653 | INSERT VALUES 执行内核 | |
| #29 | write_record() |
sql_insert.cc:2119 | 写入一条记录 | |
| 存储引擎接口 | #28 | handler::ha_write_row() |
handler.cc:8020 | Handler API 写行入口 |
| #27 | ha_innobase::write_row() |
ha_innodb.cc:9109 | InnoDB Handler 写行 | |
| InnoDB 行操作 | #26 | row_insert_for_mysql() |
row0mysql.cc:1716 | 行插入入口 |
| #25 | row_insert_for_mysql_using_ins_graph() |
row0mysql.cc:1586 | 使用插入图执行插入 | |
| #24 | row_ins_step() |
row0ins.cc:3730 | 行插入执行步骤 | |
| #23 | row_ins() |
row0ins.cc:3606 | 行插入主逻辑 | |
| #22 | row_ins_index_entry_step() |
row0ins.cc:3488 | 插入索引项步骤 | |
| #21 | row_ins_index_entry() |
row0ins.cc:3351 | 插入索引项 | |
| #20 | row_ins_clust_index_entry() |
row0ins.cc:3159 | 插入聚簇索引项 | |
| #19 | row_ins_clust_index_entry_low() |
row0ins.cc:2417 | 聚簇索引插入底层实现 | |
| B-Tree 操作 | #18 | btr_height_get() |
btr0btr.cc:209 | 获取 B-Tree 高度 |
| #17 | btr_root_block_get() |
btr0btr.cc:164 | 获取 B-Tree 根页 | |
| #16 | btr_block_get() |
btr0btr.h:205 | 获取 B-Tree 页面(内联) | |
| #15 | btr_block_get_func() |
btr0btr.ic:56 | 获取 B-Tree 页面实现 | |
| Buffer Pool | #14 | buf_page_get_gen() |
buf0buf.cc:4481 | 获取页面通用入口 |
| #13 | Buf_fetch_normal::get() |
buf0buf.cc:3734 | 正常模式获取页面 | |
| #12 | Buf_fetch<Buf_fetch_normal>::single_page() |
buf0buf.cc:4288 | 单页获取 | |
| #11 | Buf_fetch<Buf_fetch_normal>::read_page() |
buf0buf.cc:4107 | Buffer Pool 未命中,触发磁盘读 | |
| 页面读取 | #10 | buf_read_page() |
buf0rea.cc:292 | 页面读取入口 |
| #9 | buf_read_page_low() |
buf0rea.cc:127 | 页面读取底层 | |
| 文件 I/O 层 | #8 | fil_io() |
fil0fil.cc:7983 | 文件 I/O 分发(page_id → 物理文件) |
| #7 | Fil_shard::do_io() |
fil0fil.cc:7869 | Fil_shard 执行 I/O | |
| OS AIO 层 | #6 | pfs_os_aio_func() |
os0file.ic:148 | PFS 埋点包装 |
| #5 | os_aio_func() |
os0file.cc:6965 | AIO 入口(本次 mode=SYNC) | |
| #4 | os_file_read_func() |
os0file.cc:5532 | 同步读文件 | |
| #3 | os_file_read_page() |
os0file.cc:5115 | 读一个页面 | |
| #2 | os_file_pread() |
os0file.cc:5073 | pread 封装 | |
| #1 | os_file_io() |
os0file.cc:4893 | I/O 重试循环 | |
| 磁盘 I/O | #0 | SyncFileIO::execute() |
os0file.cc:2049 | 最终调用 pread() 系统调用 |
fil层
当前来到fil_io
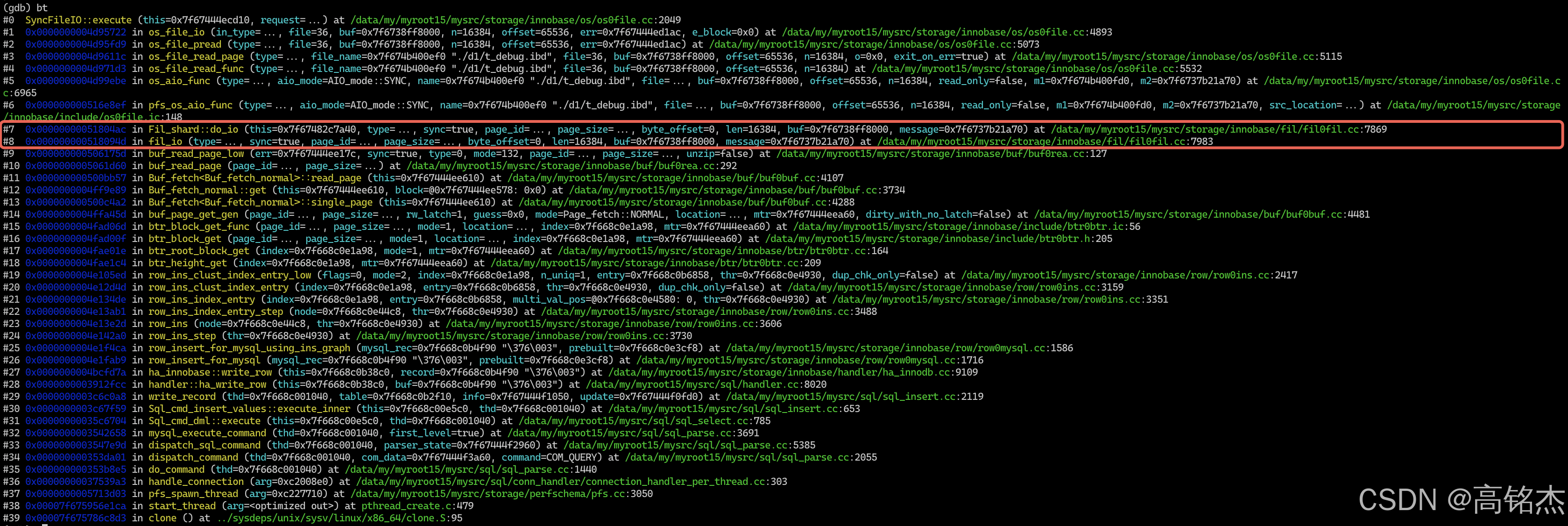
(gdb) f 8
#8 0x000000000518094d in fil_io (type=..., sync=true, page_id=..., page_size=..., byte_offset=0, len=16384, buf=0x7f6738ff8000, message=0x7f6737b21a70) at /data/my/myroot15/mysrc/storage/innobase/fil/fil0fil.cc:7983
7983 auto const err = shard->do_io(type, sync, page_id, page_size, byte_offset,fil_io函数很简单,核心逻辑:
- 通过page_id.space确定由哪个
Fil_shard处理 - 将io请求委托给
shard->do_io()
c
dberr_t fil_io(const IORequest &type, bool sync, const page_id_t &page_id,
const page_size_t &page_size, ulint byte_offset, ulint len,
void *buf, void *message) {
auto shard = fil_system->shard_by_id(page_id.space());
auto const err = shard->do_io(type, sync, page_id, page_size, byte_offset,
len, buf, message);
return err;
}进入fil_io后来一个方便的调试命令:
(gdb) printf "=== fil_io: space=%u page=%u %s sync=%d ===\n", page_id.m_space, page_id.m_page_no, type.m_type == 0 ? "READ" : "WRITE", sync
=== fil_io: space=12 page=4 WRITE sync=1 ===看下shard关键数据:m_spaces保存了spaceid到fil_space_t的映射关系
Fil_shard数据结构:
class Fil_shard {
...
using Spaces = std::unordered_map<space_id_t, fil_space_t *>;
...
private:
Spaces m_spaces;
...
}shard->m_spaces信息:
(gdb) p shard->m_spaces
$11 = std::unordered_map with 1 element = {
[12] = 0x7f674b400b80
}
# 注意这里是 fil_space_t
(gdb) p *(fil_space_t*)0x7f674b400b80
$12 = {
...
name = 0x7f674b400d70 "d1/t_debug",
...
files = ...
size = 7,
flags = 16417,
free_len = 0,
free_limit = 64,
latch = ...
unflushed_spaces = ...
m_header_page_flush_lsn = 0,
magic_n = 89472,
static s_sys_space = 0x7f67483d3220
# 注意这里是fil_node_t
(gdb) p ((fil_space_t*)0x7f674b400b80)->files[0]
$15 = {
space = 0x7f674b400b80,
name = 0x7f674b400ef0 "./d1/t_debug.ibd",
is_open = true,
handle = {
m_psi = 0x7f674fca8900,
m_file = 36
},
sync_event = 0x7f674b400f30,
is_raw_disk = false,
size = 7,
flush_size = 0,
init_size = 0,
max_size = 4294967294,
n_pending_ios = 1,
n_pending_flushes = 0,
is_being_extended = false,
modification_counter = 0,
flush_counter = 0,
LRU = {
prev = 0x0,
next = 0x0
},
punch_hole = true,
block_size = 4096,
atomic_write = false,
magic_n = 89389
}
(gdb) ptype ((fil_space_t*)0x7f674b400b80)->files[0]
type = struct fil_node_t {
fil_space_t *space;
char *name;
bool is_open;
pfs_os_file_t handle;
os_event_t sync_event;
bool is_raw_disk;
page_no_t size;
page_no_t flush_size;
page_no_t init_size;
page_no_t max_size;
size_t n_pending_ios;
size_t n_pending_flushes;
bool is_being_extended;
int64_t modification_counter;
int64_t flush_counter;
List_node LRU;
bool punch_hole;
size_t block_size;
bool atomic_write;
size_t magic_n;
public:
bool can_be_closed(void) const;
bool is_flushed(void) const;
void set_flushed(void);
typedef ut_list_node<fil_node_t> List_node;
}整理下这里的关系
fil_system (全局单例)
├─ Fil_shard[0]
│ ├─ m_spaces (hash_map: space_id → fil_space_t*)
│ │ ├─ fil_space_t (space_id=12, name="d1/t_debug")
│ │ │ └─ files: [fil_node_t(./d1/t_debug.ibd)]
│ │ └─ ...
│ └─ m_LRU (文件描述符 LRU 列表, 控制同时打开的文件数)
├─ Fil_shard[1]
│ └─ ...
├─ Fil_shard[2]
│ └─ ...
└─ Fil_shard[3] (默认68个 shard,MAX_SHARDS = 68)
└─ ...
fil_space_t fil_node_t
┌─────────────---------───────────┐ ┌──────────────────────────────┐
│ id = 12 │ │ name = "./d1/t_debug.ibd" │
│ name = "d1/t_debug" │ │ handle = {m_file = 36} │
│ size = 7 (pages) │ │ is_open = true │
│ purpose = FIL_TYPE_TABLESPACE│ │ size = 7 (pages) │
│ flags = 16417 │ │ block_size = 4096 │
│ n_reserved_extents │ │ n_pending_ios = 1 │
│ files[] ────────────┼─files────→│ space = (指回 fil_space_t) │
│ encryption_metadata │ │ punch_hole = true │
└────────────────---------────────┘ └──────────────────────────────┘这里filesystem为什么设计多个Fil_shard呢?核心目的是减少 mutex 竞争,每个 Fil_shard 都有自己独立的 mutex。
/** Constructor
@param[in] shard_id Shard ID */
Fil_shard::Fil_shard(size_t shard_id)
: m_id(shard_id),
m_spaces(),
m_names(),
m_LRU(),
m_unflushed_spaces(),
m_modification_counter() {
mutex_create(LATCH_ID_FIL_SHARD, &m_mutex);
}8.0 之前整个 fil_system 只有一把全局 mutex(fil_system_mutex)。这导致了严重的锁竞争瓶颈:
旧版本(单锁):
Thread-1 写表 A ──→ ┐
Thread-2 读表 B ──→ ├─→ 争抢同一把 fil_system_mutex ──→ 串行化!
Thread-3 读表 C ──→ ┘
新版本(分片锁):
Thread-1 写表 A (space_id=3) ──→ shard[3].mutex ──→ 并行!
Thread-2 读表 B (space_id=5) ──→ shard[5].mutex ──→ 并行!
Thread-3 读表 C (space_id=3) ──→ shard[3].mutex ──→ 仅这两个竞争- shard0 ~ shard63:共 64 个,用于普通表空间(用户表、系统表空间、临时表空间等)
- shard64 ~ shard67:共 4 个,专门用于 Undo 表空间
映射逻辑
Fil_shard *shard_by_id(space_id_t space_id) const {
if (fsp_is_undo_tablespace(space_id)) {
// Undo 表空间 → 映射到后 4 个 shard
const size_t limit = space_id % UNDO_SHARDS; // space_id % 4
return m_shards[UNDO_SHARDS_START + limit]; // shard[64..67]
}
// 普通表空间 → 映射到前 64 个 shard
return m_shards[space_id % UNDO_SHARDS_START]; // space_id % 64
}每个 Fil_shard 是一个迷你版的表空间管理器,拥有自己独立的:
| 成员 | 含义 |
|---|---|
m_mutex |
独立的互斥锁,保护本 shard 内的所有数据结构 |
m_spaces |
unordered_map<space_id, fil_space_t*>,本 shard 管辖的所有表空间 |
m_names |
unordered_map<name, fil_space_t*>,按名字索引的表空间 |
m_LRU |
本 shard 内最近使用的打开文件的 LRU 链表 |
m_unflushed_spaces |
本 shard 内有未刷盘脏数据的表空间链表 |
m_modification_counter |
本 shard 内的写操作计数器 |
分配:
fil_system (Fil_system)
├── m_shards[0] ──→ Fil_shard { mutex, spaces, LRU, ... } ← space_id % 64 == 0 的普通表
├── m_shards[1] ──→ Fil_shard { mutex, spaces, LRU, ... } ← space_id % 64 == 1 的普通表
├── m_shards[2] ──→ Fil_shard { mutex, spaces, LRU, ... } ← space_id % 64 == 2
├── ...
├── m_shards[63] ──→ Fil_shard { mutex, spaces, LRU, ... } ← space_id % 64 == 63
├── m_shards[64] ──→ Fil_shard { mutex, spaces, LRU, ... } ← Undo (space_id % 4 == 0)
├── m_shards[65] ──→ Fil_shard { mutex, spaces, LRU, ... } ← Undo (space_id % 4 == 1)
├── m_shards[66] ──→ Fil_shard { mutex, spaces, LRU, ... } ← Undo (space_id % 4 == 2)
└── m_shards[67] ──→ Fil_shard { mutex, spaces, LRU, ... } ← Undo (space_id % 4 == 3)os层
os层堆栈:
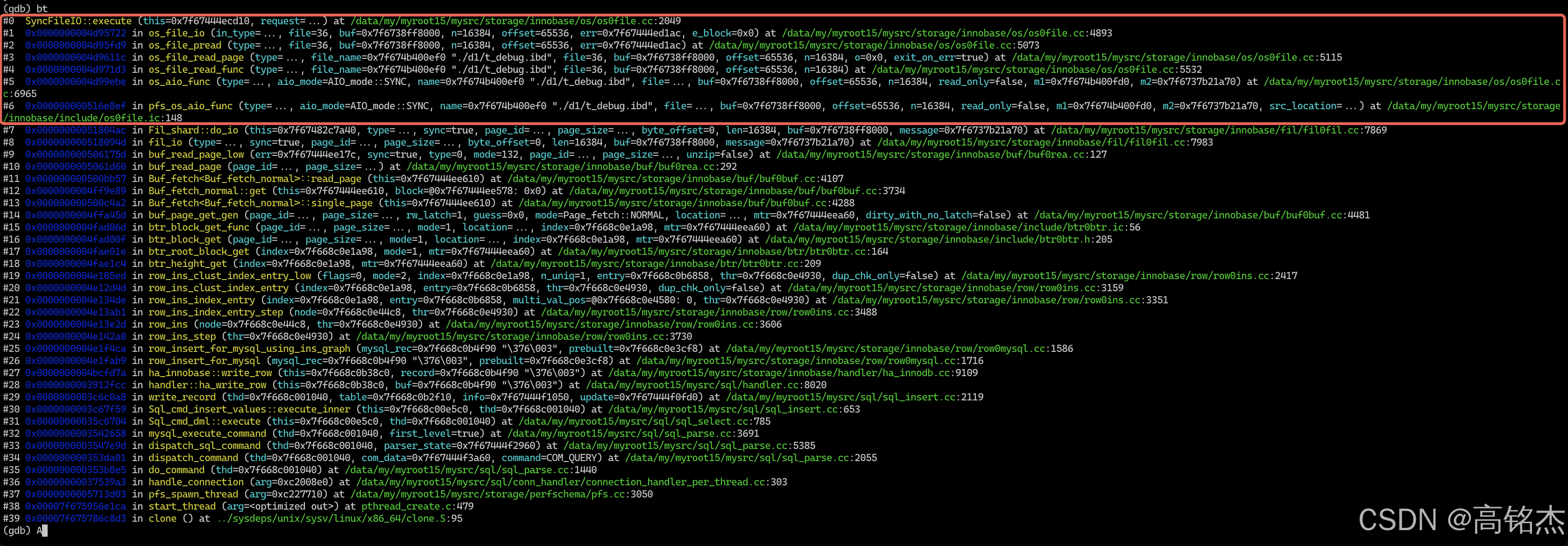
这里只分析下同步IO的场景,进入os_aio_func后,同步IO直接路由到os_file_read_func或os_file_write_func函数。
pfs_os_aio_func(SYNC, ...) ← PFS 包装层(Performance Schema)
│ register_pfs_file_io_begin()
▼
os_aio_func(SYNC, ...) ← os 层入口: SYNC 直接走同步路径
│ if (aio_mode == SYNC) → os_file_read_func()
▼
os_file_read_func(type, name, fd, ...) ← 同步读入口(thin wrapper)
│
▼
os_file_read_page(type, name, fd, ...) ← 页面读取 + 错误恢复外层循环
│ 内含 for(;;) 无限重试
▼
os_file_pread(type, fd, buf, n, offset) ← 计数器 + 监控统计
│ ++os_n_file_reads
│ MONITOR_ATOMIC_INC(MONITOR_OS_PENDING_READS)
▼
os_file_io(type, fd, buf, n, offset) ← 核心: 压缩/加密 + 部分I/O重试
│ SyncFileIO sync_file_io(fd, buf, n, offset)
│ for (i = 0; i < 10; ++i) ← NUM_RETRIES_ON_PARTIAL_IO
▼
SyncFileIO::execute(request) ← 最终: pread() 系统调用 !!!
│
▼
pread(fd=36, buf=0x7f6738ff8000, 16384, 65536) ← Linux 内核os_file_read_page读页面,要求页面读出来的字节必须是n否则报错。
os_file_io真正要读了
os_file_io
...
// ===== 创建 SyncFileIO 对象, 执行实际 I/O =====
SyncFileIO sync_file_io(file, buf, n, offset);
// ^fd ^buf ^16384 ^65536
for (ulint i = 0; i < NUM_RETRIES_ON_PARTIAL_IO; ++i) { // 最多重试 10 次
ssize_t n_bytes = sync_file_io.execute(type);
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// 最终调用 pread()/pwrite()
if (n_bytes < 0) {
break; // 硬错误, 退出
}
if ((ulint)n_bytes + bytes_returned == n) {
bytes_returned += n_bytes;
*err = DB_SUCCESS;
return original_n;
}
// ===== Partial I/O: 只完成了部分字节 =====
bytes_returned += n_bytes;
ib::warn() << n << " bytes should have been read. Only "
<< bytes_returned << " bytes read. Retrying...";
sync_file_io.advance(n_bytes);
// m_offset += n_bytes; // 文件偏移前进
// m_n -= n_bytes; // 剩余字节减少
// m_buf += n_bytes; // 缓冲区指针前进
}
*err = DB_IO_ERROR;
return bytes_returned;
}入参in os_file_io (file=36, buf=0x7f6738ff8000, n=16384, offset=65536) 的含义,从d1/t_debug.ibd文件的第65536字节处开始读取16384字节。
offset = page_no × page_size
= 4 × 16384
= 65536从堆栈可以看到,这次读取的是 B-tree 根页面(page_no = 4):
ibd文件格式
文件偏移(字节) page_no 用途
─────────────────────────────────────────
0 0 FSP_HDR (文件空间头, 管理区段分配)
16384 1 IBUF_BITMAP (Insert Buffer 位图)
32768 2 INODE (段信息节点)
49152 3 SDI (Serialized Dictionary Info, 8.0新增)
65536 4 ★★★★★★★★★★★★★★★★ B-tree 根页面 (INDEX page) ★★★★★★★★★★★★★★★★★
81920 5 第一个数据/叶子页面
...