一.整体概述
LlamaFactory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LlamaFactory,我们可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
二.数据处理
LlamaFactory训练所需要的所有数据,都集中存放在了该项目所在的data目录下。data目录中主要是包含了用于定义和管理数据集配置信息的dataset_info.json文件,以及其他各种格式的训练数据文件。
dataset_info.json
dataset_info.json文件是用于定义和管理数据集的配置信息,这些配置信息主要包括了数据集的名称和路径、数据集格式、样本数量、列名绑定等元数据。
dataset_info.json包含了所有经过预处理的本地数据集和在线数据集。本地数据集主要是LLaMAFactory所提供的一些demo样例数据集以及我们自定义的数据集。而在线数据集主要是Hugging Face和ModelScope所提供的数据集。
dataset_info.json的格式模板如下:
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"split": "所使用的数据集切分(可选,默认:train)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集所使用的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"videos": "数据集代表视频输入的表头名称(默认:None)",
"audios": "数据集代表音频输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
在LLaMA-Factory中添加一个数据集比较简单,本文中以自定义数据集为例,来演示一下如何添加一个数据集。
我们可以登录modelscope下载一个数据集文件,本例中下载的是一个huanhuan.json的数据集文件。该文件中是以电视剧《甄嬛传》中角色人物的对话作为模型的训练语料。
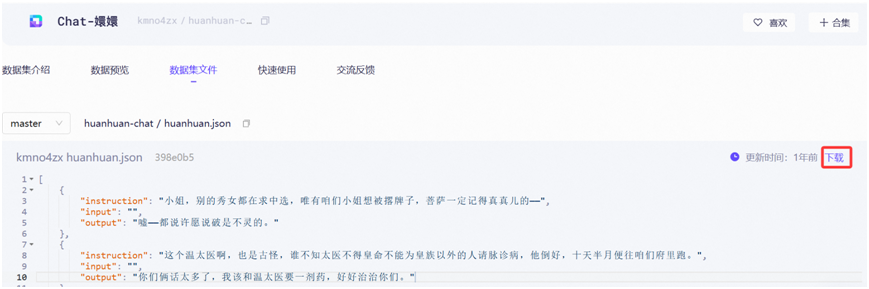
我们将下载的huanhuan.json这个数据集文件放入到LLaMAFactory项目所在的data目录下,这个data目录中LLaMAFactory已经预留了很多demo数据集文件。
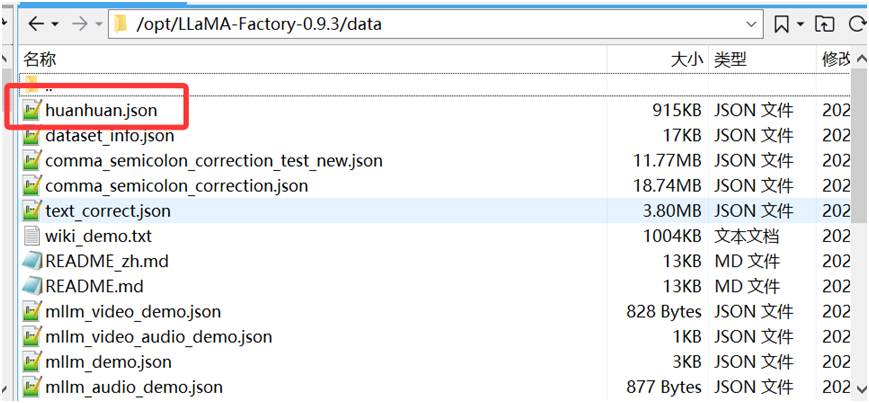
最后我们在dataset_info.json文件中,增加huanhuan.json这个数据集文件的配置信息。
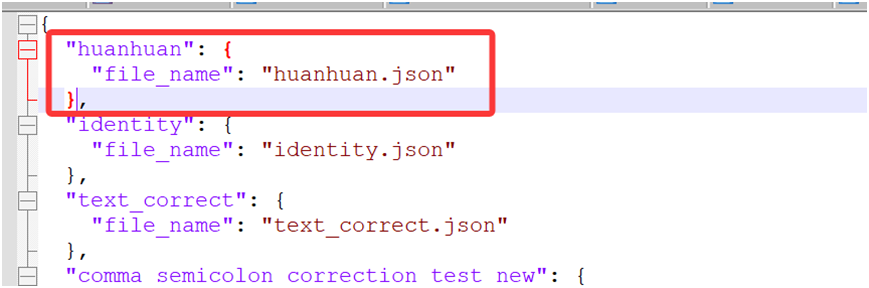
经过以上步骤后,我们就可以在LLaMAFactory的WebUI界面中的"数据集"一栏中,看到刚才添加的数据集。并且可以对添加的huanhuan.json数据集的数据项进行预览。
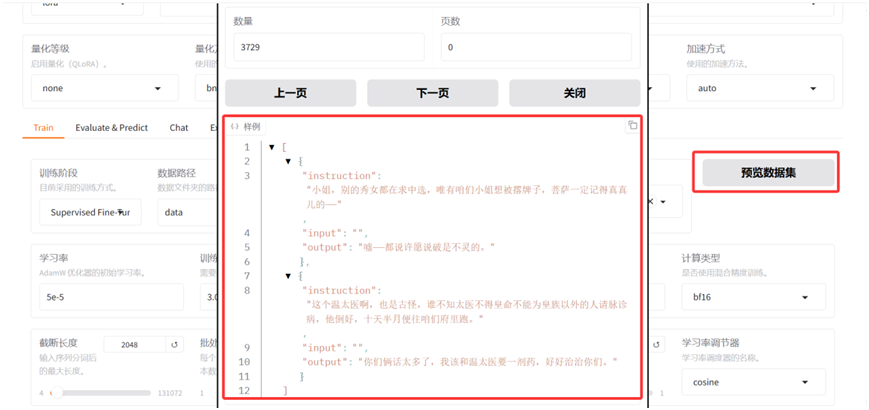
数据集格式
目前LLaMA-Factory支持的数据集格式主要是Alpaca和ShareGPT两种,Alpaca是由斯坦福大学提出,专注于单轮指令微调,适合于训练模型来执行具体任务。ShareGPT来自社区项目,它以多角色连续对话流为核心,适合于训练多轮对话模型,更贴近实际聊天场景。
Alpaca
Alpaca数据集是一种专门为指令微调大语言模型设计的轻量且结构化的数据格式。Alpaca是结构化的"指令-输出"对,侧重于让模型学会遵循并完成特定任务;
1.指令监督微调
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答,来优化模型在特定指令下的表现。
指令监督微调数据集的格式如下:
[
{
"instruction" : "人类指令(必填)",
"input" : "人类输入(选填)",
"output" : "模型回答(必填)",
"system" : "系统提示词(选填)",
"history" : [
** "第一轮指令(选填)"**,** "第一轮回答(选填)"**,
** "第二轮指令(选填)"**,** "第二轮回答(选填)"**
]
}
]
从以上的指令监督微调格式模板中可以看出,该指令主要包含了六个部分:
- instruction列:人类的指令,是用户想要模型执行的具体任务,明确的告诉模型要做什么。通常是告诉模型需要执行的操作或回答的问题。必填。
- input列:人类的输入,必填;
- output列:模型回答,必填;
- system列:系统提示词,非必填;
- history列:由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习,非必填。
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name" : {
"file_name" : "data.json",
"columns" : {
"prompt" : "instruction",
"query" : "input",
"response" : "output",
"system" : "system",
"history" : "history"
}
}
在进行指令监督微调时,instruction列对应的内容会与input列对应的内容拼接后作为最终的人类输入,即人类输入为`instruction-input`。而 output 列对应的内容为模型回答。如果指定了system列,system列对应的内容将被作为系统提示词。history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
{ **"instruction"** : "请对以下文本进行中文拼写、语法纠错,仅输出纠错后的文本。", **"input"** : "都分患者不清楚白天和黑夜。", **"output"** : "部分患者不清楚白天和黑夜。" }, { **"instruction"** : "请对以下文本进行中文拼写、语法纠错,仅输出纠错后的文本。", **"input"** : "他是位新进奶爸。", **"output"** : "他是位新晋奶爸。" }, { **"instruction"** : "请对以下文本进行中文拼写、语法纠错,仅输出纠错后的文本。", **"input"** : "这份地图对后来的反"扫荡"战斗中起到了重要作用。", **"output"** : "这份地图在后来的反"扫荡"战斗中起到了重要作用。" }
在上述指令监督微调的示例数据集中,我们给模型的指令"instruction"是要求对中文拼写和语法进行纠错后,输出正确的文本。input是我们输入的有拼写或者语法错误的样例文本。output是我们期望模型进行纠正后输出的正确文本。
2.预训练
大语言模型通过学习未被标记的文本来进行预训练,从而学习语言的表征。预训练是让通用的基座模型,吸收并内化大量新的或特定领域的数据,从而为后续的精确指令微调打下基础。在预训练时,只有text列中的内容会用于模型学习。
预训练数据集文本描述格式如下:
{**"text"** : "document"}, {**"text"** : "document"}
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"columns": {
"prompt ": "text"
}
}
3.偏好训练
偏好数据集在大语言模型的训练和优化中扮演着至关重要的角色,其主要作用训练大模型理解并符合人类的偏好,例如让回答更准确、更安全或更有帮助,而不是仅仅追求语法正确。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答。偏好训练在其一轮问答中的格式如下:
{ "**instruction** ": "人类指令(必填)", "**input** ": "人类输入(选填)", "**chosen** ": "优质回答(必填)", "**rejected** ": "劣质回答(必填)" }
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"dataset_name": {
"file_name ": "data.json",
"ranking ": true,
"columns": {
"prompt ": "instruction",
"query ": "input",
"chosen ": "chosen",
"rejected ": "rejected"
}
}
4.多模态
LLaMA-Factory目前支持图像、视频、音频等多模态数据集。
- 图像数据集
多模态图像数据集需要额外添加一个images列,包含输入图像的路径。注意图片的数量必须与文本中所有<image>标记的数量要严格一致。
{ "**instruction** ": "人类指令(必填)", "**input** ": "人类输入(选填)", "**output** ": "模型回答(必填)", "**images**": \[ "图像路径(必填)"
}
]
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"columns": {
"prompt ": "instruction",
"query ": "input",
"response ": "output",
"images ": "images"
}
}
- 视频数据集
多模态视频数据集需要额外添加一个videos列,包含输入视频的路径。注意视频的数量必须与文本中所有<video>标记的数量要严格一致。
{ "**instruction** ": "人类指令(必填)", "**input** ": "人类输入(选填)", "**output** ": "模型回答(必填)", "**videos**": \[ "视频路径(必填)"
}
]
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"columns": {
"prompt ": "instruction",
"query ": "input",
"response ": "output",
"videos ": "videos"
}
}
- 音频数据集
多模态音频数据集需要额外添加一个audio列,包含输入图像的路径。注意音频的数量必须与文本中所有<audio>标记的数量要严格一致。
{ "**instruction** ": "人类指令(必填)", "**input** ": "人类输入(选填)", "**output** ": "模型回答(必填)", "**audios**": \[ "音频路径(必填)"
}
]
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"columns": {
"prompt ": "instruction",
"query ": "input",
"response ": "output",
"audios ": "audios"
}
}
ShareGPT
与alpaca格式数据集不同的是,sharegpt格式的数据集是以多轮对话的序列形式呈现,适合训练聊天机器人或对话模型。sharegpt支持多个角色(如human、gpt、observation、function等),通过from字段来区分角色身份。sharegpt平衡了可读性、灵活性和处理效率,成为社区共享对话数据的事实标准,尤其适合用于微调开源对话模型。
指令监督微调
Sharegpt格式的指令监督微调数据集支持更多的角色种类,角色种类构成一个对象列表呈现在conversations列中。其中human和observation必须出现在奇数位置,gpt和function必须出现在偶数位置。
{ "**conversations**": \[ { "**from** ": "human", "**value** ": "人类指令" }, { "**from** ": "function_call", "**value** ": "工具参数" }, { "**from** ": "observation", "**value** ": "工具结果" }, { "**from** ": "gpt", "**value** ": "模型回答" } \], "**system** ": "系统提示词(选填)", "**tools** ": "工具描述(选填)" }
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"formatting ": "sharegpt",
"columns": {
"messages ": "conversations",
"system ": "system",
"tools ": "tools"
}
}
偏好训练
与Alpaca相似,Sharegpt格式的偏好数据集同样需要在chosen列中提供更优的消息,并在rejected列中提供更差的消息。
{ "**conversations**": \[ { "**from** ": "human", "**value** ": "人类指令" }, { "**from** ": "gpt", "**value** ": "模型回答" }, { "**from** ": "human", "**value** ": "人类指令" } \], "**chosen**": { "**from** ": "gpt", "**value** ": "优质回答" }, "**rejected**": { "**from** ": "gpt", "**value** ": "劣质回答" } }
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"formatting ": "sharegpt",
"ranking ": true,
"columns": {
"messages ": "conversations",
"chosen ": "chosen",
"rejected ": "rejected"
}
}
OpenAI格式
OpenAI格式仅仅是sharegpt格式的一种特殊情况,其中第一条消息可能是系统提示词。
{ "**messages**": \[ { "**role** ": "system", "**content** ": "系统提示词(选填)" }, { "**role** ": "user", "**content** ": "人类指令" }, { "**role** ": "assistant", "**content** ": "模型回答" }
}
]
对于上述格式的数据,dataset_info.json中的数据集描述应为:
"dataset_name": {
"file_name ": "data.json",
"formatting ": "sharegpt",
"columns": {
"messages ": "messages"
},
"tags": {
"role_tag ": "role",
"content_tag ": "content",
"user_tag ": "user",
"assistant_tag ": "assistant",
"system_tag ": "system"
}
}
三.模型训练
1.训练阶段
LlamaFactory主要包含了预训练,指令监督微调,偏好训练的三个阶段。
预训练
预训练是模型训练的第一阶段,它指的是在海量无标注文本数据上,通过自监督学习来训练模型。预训练相当于给一个基础模型进行"通识教育",让模型学习语言的通用规律,其中包括词汇、语法、句法、常识、事实知识和简单的逻辑推理。通过预训练,在模型获得"语言直觉"后,可以为后续的专项任务打下基础。
预训练就像我们小学到高中的九年业务教育,广泛的学习各学科的文化知识。在有了这些文化基础后,我们会在大学阶段进入专业领域的知识学习。而大学阶段就相当于后续模型的监督微调。
预训练需要大量计算资源和海量的通用知识数据,对于大多数普通的用户,可跳过此阶段,直接使用已经预训练好的开源模型。
LlamaFactory中的预训练,特指对已具备基础能力的大语言模型所进行的增量预训练。它是在已有预训练模型的基础上,使用特定领域的数据(如医学、法律、金融文本)进行额外训练,以增强模型在该领域的知识。旨在让模型从新的、海量领域数据中学习通用知识,从而扩展其基础能力。
监督微调
监督微调是大模型训练流程中的关键阶段。它是在已完成预训练的大规模基础上,使用高质量的、带有"输入-输出"配对的人工标注数据,对模型进行进一步的针对性训练,以使模型适应特定任务、遵循人类指令或提升输出质量的过程。
监督微调就像是请了一个私人教练,将预训练好的大模型这个"通才"转变成为一个"专才"的技术手段。
在LlamaFactory中,使用的是指令监督微调让预训练好的大语言模型学会精准理解和执行人类指令。它通过提供大量"指令-输入-输出"的标注数据,用监督学习的方式调整模型参数,从而显著提升模型在特定任务上的表现和指令遵循能力。在该过程中,模型学习如何根据给定的指令和输入信息生成合适的回答。
LlamaFactory可以让我们通过WebUI的简单配置和可视化操作来完成指令监督微调,这个过程对于开发者来说十分友好方便。
偏好训练
偏好训练是一种通过人类反馈来对齐大模型输出与人类价值观和偏好的技术。它的核心目标是让模型的输出不仅"正确",而且"有用、诚实、无害",使其行为更符合人类偏好。
预训练和监督微调后,模型虽然知识丰富,但输出可能不够精准、有用或者不符合人类价值观。偏好训练就是为了解决这个问题,让模型输出更"靠谱"、更"贴心"。
LlamaFactory支持DPO,KTO,ORPO等偏好训练,但DPO是目前社区实践最广泛、也是LlamaFactory支持最完善的方法。
LlamaFactory的偏好训练功能,特别是其对直接偏好优化(DPO)等算法的集成,让大模型根据人类标注的"偏好数据"来调整自己,从而生成更符合人类期望的内容。
LlamaFactory的偏好训练功能,可以通过易用的WebUI界面和配置文件,极大地降低了大模型与人类价值观对齐的技术门槛。
2.微调方法
全参数微调(full)
全参数微调是大模型微调中最基础、最彻底的方法。其核心思想是在预训练模型的基础上,对模型的所有参数进行更新,以使模型充分适配特定的下游任务。
全参数微调通过在下游任务的数据集上重新训练整个模型,更新模型中每一层的参数,这种方法旨在让模型尽可能地吸收任务相关的知识,从而达到最优性能。全参数微调适合于有充足的计算资源和海量的高质量数据,需要追求最佳性能的场景。
在LlamaFactory中,若需要使用全参数微调,则需将finetuning_type设置为full。
冻结微调(freeze)
Freeze冻结微调是一种在微调预训练大模型时,冻结模型的大部分参数,只训练剩余的一小部分参数的技术。它的核心思想是:利用模型在预训练阶段学到的强大通用知识和表征能力,仅通过极小的参数变动,使其适应下游新任务。
冻结微调中通常会冻结模型底层(即低级特征提取层)的参数,而只更新高层(即任务特定层)的参数。通过这种方式,模型可以保留模型原有的语言理解能力的同时,仅调整高层参数以适应特定任务。Freeze冻结微调主要就是"冻结底层参数,微调高层参数"。
在LLaMA-Factory中启用冻结微调时,用户需要将finetuning_type参数设置为freeze,并根据需求指定需要解冻的层数(如:freeze_trainable_layers)以及解冻的模块(如:freeze_trainable_modules)。
低秩适应(lora)
低秩适应(LoRA)是一种高效的大模型微调技术,核心思想是通过添加低秩矩阵来适应新任务,而不是直接修改原始模型的权重。该方法在保持原模型的强大泛化能力的同时,又能显著减少了需要训练的参数量和内存消耗。
低秩适应(LoRA)本质是一种对模型微调过程中"权重变化"的低秩近似建模。它通过冻结预训练模型权重,并注入可训练的低秩分解矩阵到Transformer层的特定结构中,实现了用极小的训练参数量,高效地将大模型适配到下游任务。
低秩适应(LoRA)可以仅用极少的训练参数,而达到接近全参数微调的效果。它已成为当今大模型微调领域最主流、最实用的技术之一。
在LLaMA-Factory中启用冻结微调时,用户需要将finetuning_type参数设置为lora。
3.示例
在本例中我们将介绍如何使用低秩适应(LoRA)的微调方法,对下载的开源模型进行监督微调训练。
(1). 模型下载
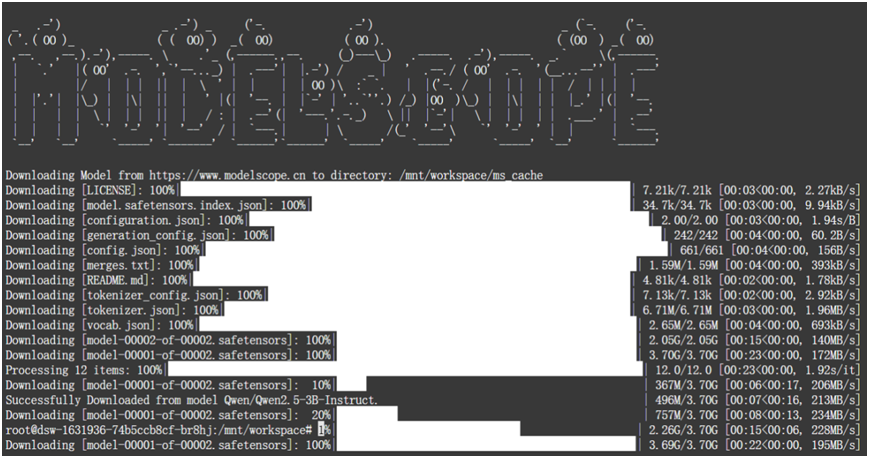
本例中使用的通义千问Qwen2.5-3B-Instruct这个模型来作为基座模型。我们可以在modelscope上下载这个模型。
模型下载命令为:
bash
modelscope download --model 'Qwen/Qwen2.5-3B-Instruct' --local_dir '/mnt/workspace/ms_cache/'上述命令可以将模型文件下载到服务器的/mnt/workspace/ms_cache/这个目录下。
(2). 设置数据集
modelscope上提供了很多开源的数据集用于模型的训练。本文中我们是在modelscope上下载了电视剧《甄嬛传》中人物对话的作为语料,来对模型的进行指令监督微调训练。

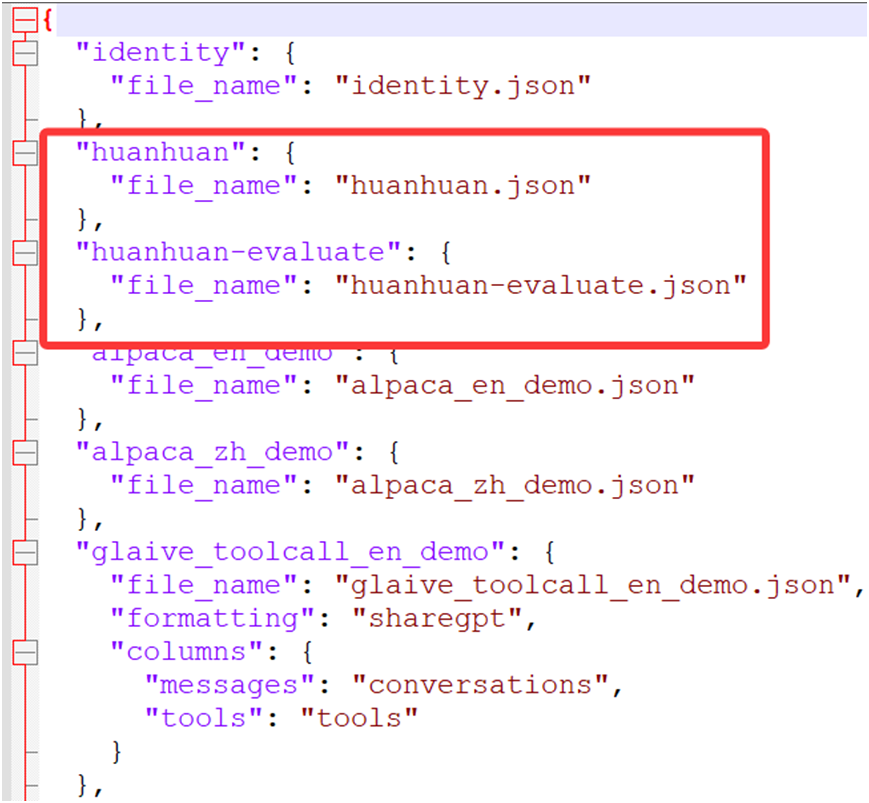
我们可以把下载的"huanhuan.json"这个数据集文件按照比例分成两个文件。80%的数据集作为模型指令微调的数据,其中的20%的数据集用于模型的评估。
本文示例中是将"huanhuan.json"这个数据集分成了"huanhuan.json"和"huanhuan-evaluate.json"两个文件分别用于指令微调和评估。
在LlamaFactory工程的data目录下, 修改dataset_info.json这个文件中添加这两个数据集文件。
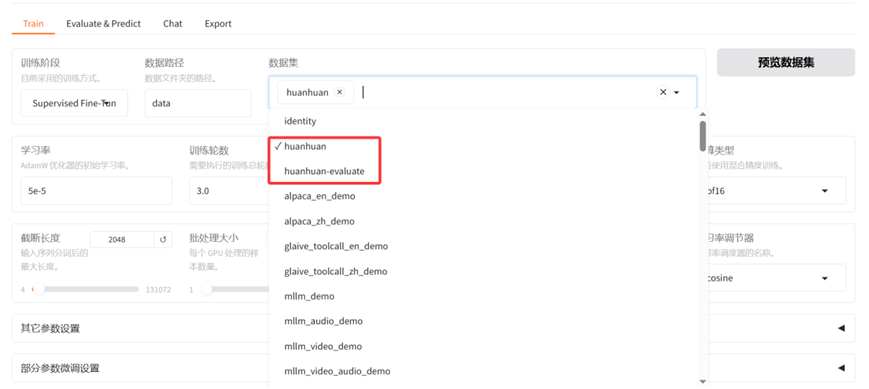
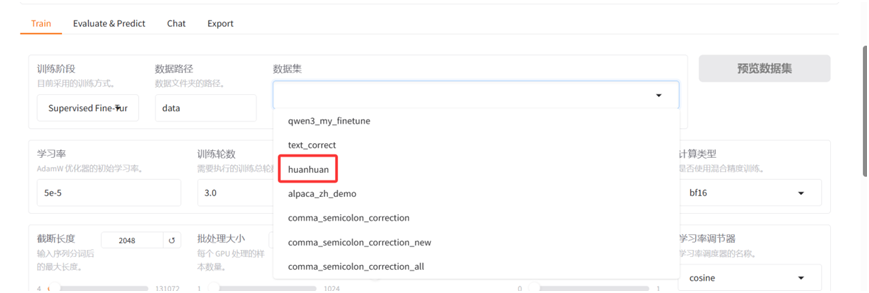
设置好数据集后,在LlamaFactory的WebUI界面的数据集的下拉框中,我们可以看到多了一个"huanhuan"的数据集选项。选择这个数据集后,我们可以对这个数据集中的数据进行预览。

(3). 参数配置
- 语言:
LlamaFactory是在支持中文的,我们可以在WebUI界面中将语言一栏设置为"zh"中文,以方便我们使用。
- 模型名称 :
由于本文中的示例中使用的是 "通义千问Qwen2.5-3B-Instruct"这个版本的开源模型。所以"模型名称"要设置为:"Qwen2.5-3B-Instruct"。
- 模型路径:
如何已经将开源模型文件下载到了本地服务器,这里就设置模型文件下载的本地路径。本例中模型文件是下载到了"/mnt/workspace/ms_cache/"这个目录下,所以模型路径设置为"/mnt/workspace/ms_cache/"。
- 模型下载源:
如果我们没有模型文件下载到服务器本地,就可以选择模型下载源。如:从Hugging Face,ModelScope或者OpenMind中,选择一个来下载模型文件。国内的话,建议选择ModelScope。
- 对话模板:
基础模型选择的是通义千问的模型,所以对话模板选择为qwen。
- 微调方法:
我们是要对基础模型进行低秩适应的微调,所以微调方法选择"lora"。
- 训练阶段:
我们是要对基础模型进行监督微调,所以训练阶段选择"Supervised Fine-Tuning"。
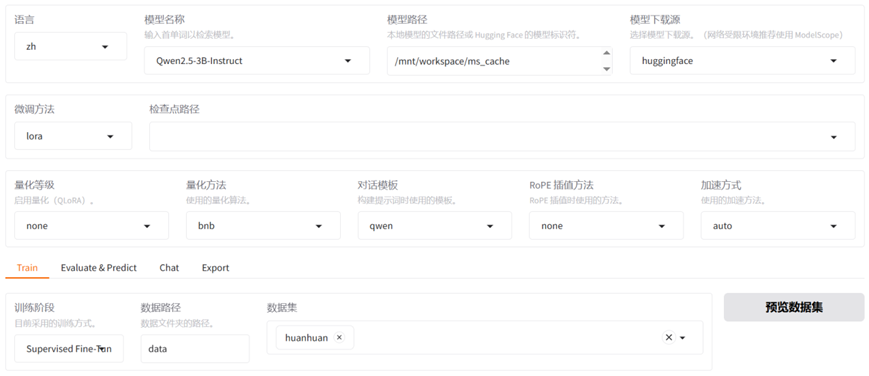
在训练阶段,LlamaFactory的WebUI界面上"Train"的tab页面上,有"预览命令","保存训练参数","载入训练参数","开始","中断"5个按钮。
预览命令:当我们完成界面参数配置后,点击该按钮会生成一条模型微调训练的命令行指令,我们可以复制这条命令,在LlamaFactory的终端环境中运行。
保存训练参数:该按钮的作用是将当前配置的训练参数保存到一个配置文件中,以便后续可以快速加载并复现相同的训练任务,这样极大的提高了反复实验和任务复现的效率。
载入训练参数:该按钮的作用是将之前保存的训练配置重新导入到LLaMA-Factory的训练界面中,让我们可以一键恢复当时所有的参数设置,避免重复的手动配置。
**开始:**根据用户预先配置好的参数和数据集,该按钮用于正式启动训练任务。
**中断:**该按钮的作用是优雅地停止正在进行的训练任务,确保训练进程能够正常退出,并保存当前最新的检查点。中断训练后我们可以利用已保存的检查点,从上次中断的地方继续训练,而不是从头再开始。
现在我们已经设置训练参数,配置好了数据集,点击"开始"按钮,就可以对模型进行指令微调的训练了,WebUI界面中会输出模型训练过程中日志,。
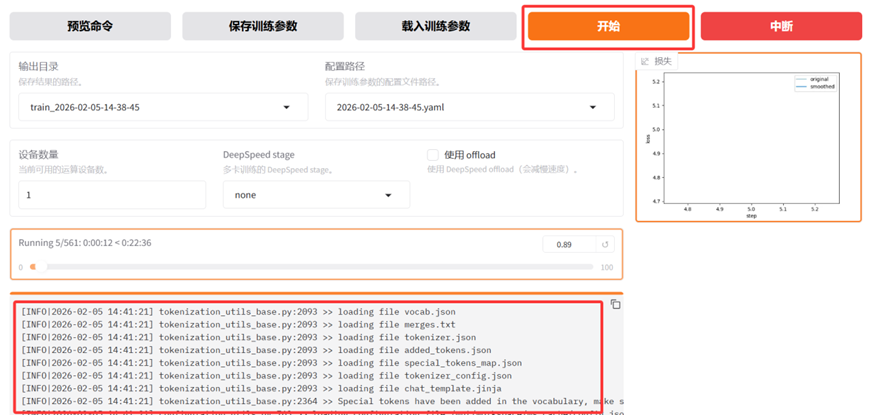
LlamaFactory训练完成后,WebUI界面会给一个训练损失曲线图,界面上的"输出目录"会给出训练结果的保存位置。
LlamaFactory会把所有的训练结果都保存到自身项目所在的saves目录下。在saves目录中, LlamaFactory会按具体的模型名称,微调方法和时间戳来层级创建目录,最后将每一次的训练结果都保存在这个目录下。本文中示例是将结果保存到了saves/Qwen2.5-3B-Instruct/lora/train_2026-02-05-14-38-45/的这个目录下。
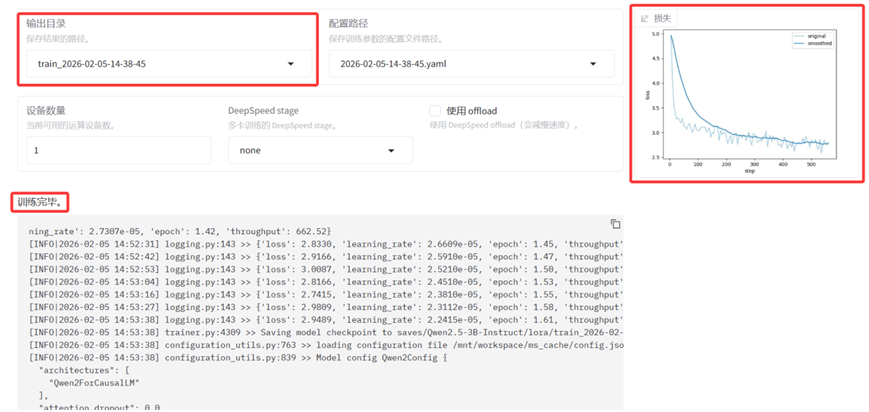

四.模型评估
LlamaFactory的模型评估是在对微调后的模型进行质量校验。其核心作用是科学量化微调后的模型在特定任务上的性能表现,判断微调是否有效,为模型迭代优化和落地部署提供数据支撑。LlamaFactory的模型评估有通用能力评估和NLG评估的两种方式。
使用LlamaFactory对模型进行评估之前,我们需要准备好一个用于评估的数据集和一个已经完成微调的模型检查点。
在本例中我们在LlamaFactory的WebUI界面中,点击"Evaluate&Predict"这个tab页面。检查点路径选择"train_2026-02-05-14-38-45", "train_2026-02-05-14-38-45"这个检查点路径是上一步骤中模型微调训练后保存的路径,数据集选择"huanhuan-evaluate"这个专门用于评估的数据集。
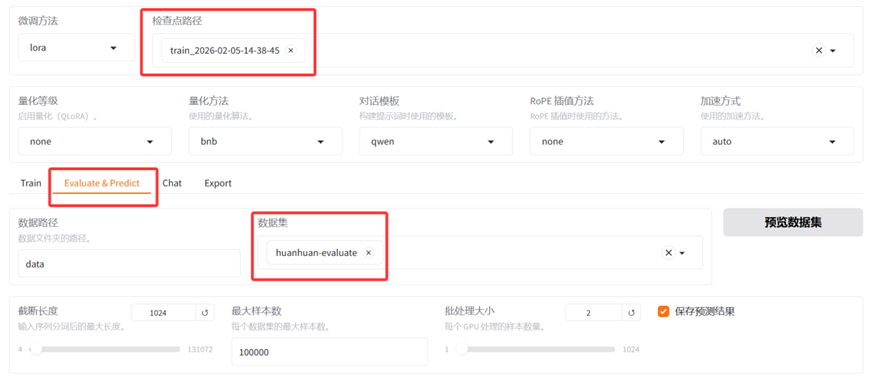
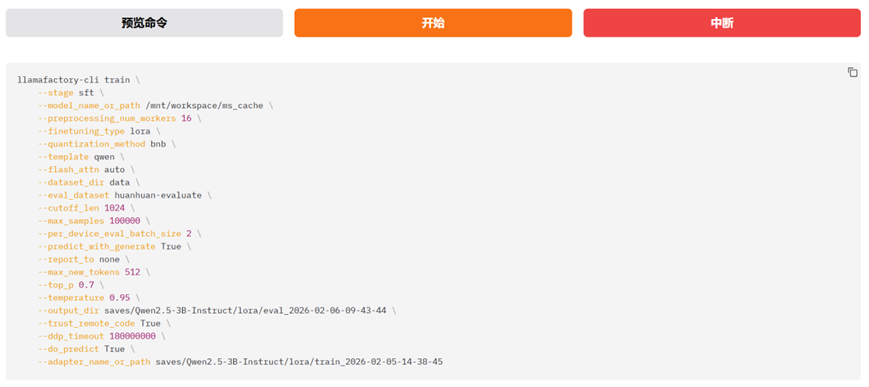
点击WebUI界面"预览命令"的按钮,LlamaFactory会生成一条模型评估的命令行指令。我们可以复制这条命令,在LlamaFactory的终端环境中运行。我们也可以直接点击页面的"开始"按钮,对微调模型进行评估,页面上会实时输出评估过程中的日志。
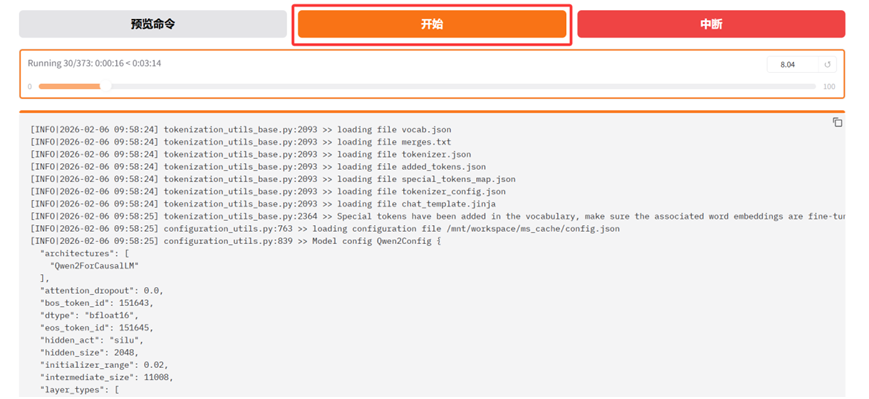
LlamaFactory对微调模型评估完成后,会将最终的评估结果显示出来。
五.模型推理
在LlamaFactory框架中,模型推理是指对训练好的模型输入新的数据,让模型生成预测结果或对话回复的过程。模型推理是训练或微调好的大模型投入实际使用的"最后一公里"。
LlamaFactory的模型推理支持CLI、批量、API、WebUI等多种方式的模型推理。
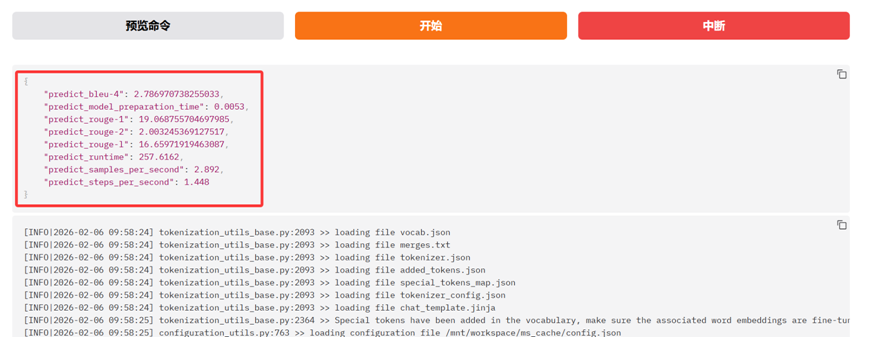
本文中我们将使用WebUI的方式,对已经微调好的模型进行推理。我们点击"Chat"这个tab页面。检查点路径选择"train_2026-02-05-14-38-45",然后点击"加载模型"的按钮。待模型加载完成后,我们就可以和已经微调后的模型进行聊天,可以看看微调训练的模型是否符合预期。

六.模型导出
LlamaFactory中我们使用LoRA等方法微调模型后,得到只是一个小型的适配器文件,而非完整的模型。
LlamaFactory模型导出是将微调后的模型适配器文件与原始基座模型文件合并,生成一个独立、完整、可部署的新模型文件。导出的新模型文件我们可以部署在如Xinference等开源模型平台上,从而获得新模型的离线推理、服务化封装和API接口调用的能力。
LlamaFactory模型导出解决了适配器与基础模型分离带来的部署复杂性问题,尤其是对LoRA微调方式而言,系统可自动完成权重融合与设备映射,省去手动操作的繁琐流程。
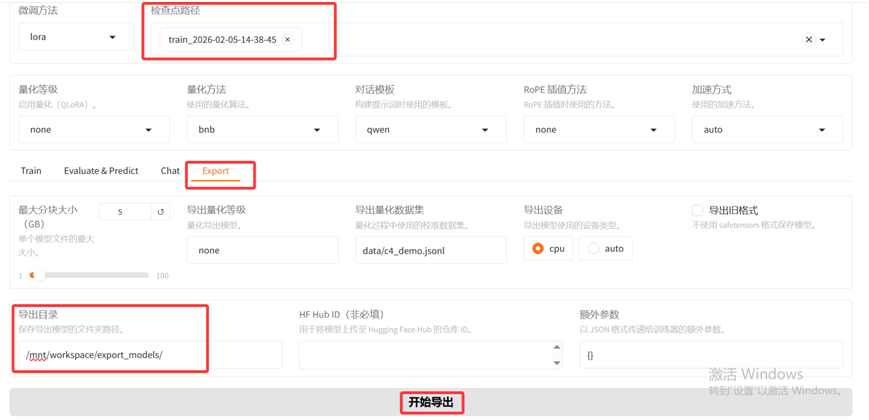
LlamaFactory中支持WebUI界面和命令行(CLI)的两种方式来导出模型,本文中将介绍如何WebUI的方式来导出模型。
导出模型之前,我们需要先加载好模型。在上一步骤模型推理的时候,我们已经加载好了检查点路径为"train_2026-02-05-14-38-45"的模型。
我们点击"Export"这个tab页面,设置好导出目录。页面上导出设备默认是cpu,如果资源充足且有GPU可用的情况下,我们可以选择auto。
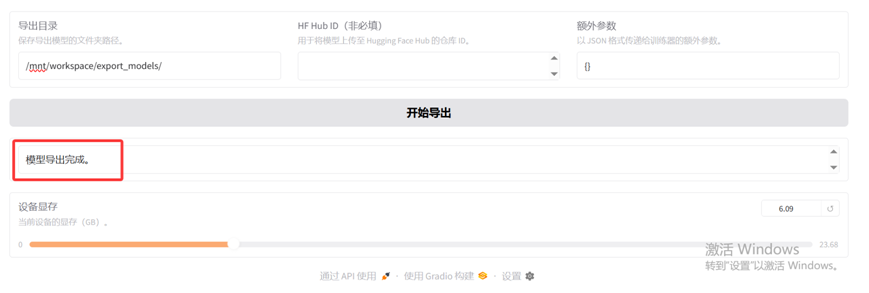
模型导出完成后,本例中在"/mnt/workspace/export_models"目录下,我们可以发现生成了一系列的模型文件。这些模型文件我们可以加载到Xinference等开源模型平台上,提供模型能力给外部所使用。
