目录
[1.1 TCU仿真命令及参数](#1.1 TCU仿真命令及参数)
[1.2 TCU WMMA矩阵基本概念](#1.2 TCU WMMA矩阵基本概念)
[1.3 TCU大矩阵分块计算](#1.3 TCU大矩阵分块计算)
[二、TCU WMMA硬件代码分析](#二、TCU WMMA硬件代码分析)
[2.1 Decode WMMA译码](#2.1 Decode WMMA译码)
[2.2 Issue WMMA rs1/rs2/rs3读地址偏移](#2.2 Issue WMMA rs1/rs2/rs3读地址偏移)
[2.3 Execute TCU WMMA](#2.3 Execute TCU WMMA)
前言
本篇重点分析Vortex RISC-V内核的6级流水线之四,Execute部分的TCU。
Execute部分包含了ALU,LSU,SFU,FPU,TCU。其中SFU在4-1已经分析过了,详看前面的4-1章节。
本系列"探索Vortex开源GPGPU:RISC-V SIMT架构"![]() https://blog.csdn.net/weixin_55313207/article/details/156224131
https://blog.csdn.net/weixin_55313207/article/details/156224131
一、TCU功能及仿真设置
TCU是Tensor Control Unit的缩写,TCU模块负责GPGPU的矩阵计算。
在Vortex中,TCU支持如下格式:
- 浮点:fp16,fp32,bf16
- 定点:int32,int8,uint8,int4,uint4
1.1 TCU仿真命令及参数
进入build目录,执行如下命令运行TCU仿例"sgemm_tcu"。
- CONFIGES="...."设定RTL相关的配置,VERILATOR会依此完成RTL里的条件编译(ifdef)
- "--debug=1"可以去掉,目的是为了dump波形和打印debug log
- TCU_BHF是Berkeley HardFloat-based FEDP(Front-end Data Path),是可综合的浮点计算RTL,还有其他两种浮点设置:DPI-based FEDP(C model,不可综合),DSP-based FEDP(FPGA macro,只适用于Xilinx/Altera FPGA)
跟矩阵功能直接相关的命令是粗体字部分:
- EXT_TCU_ENABLE是TCU模块的允许开关,默认不包含TCU
- NUM_THREAD是设定每个WARP的线程数,值越大,基本计算矩阵单元越大
- ITYPE/OTYPE指定输入/输出的数据格式
- "-m24 -n16 -k64"指定矩阵的三个参数M/N/K(K=N*ratio),它们的值跟NUM_THREADS相关
CONFIGS="-DTRACING_ALL -DDCACHE_WRITEBACK -DNUM_THREADS =8 -DISSUE_WIDTH=1 -DEXT_TCU_ENABLE -DTCU_BHF -DITYPE =uint8 -DOTYPE =int32 -DNUM_WARPS=4" \VORTEX_HOME/build/ci/blackbox.sh --debug=1 --driver=rtlsim --app=\\VORTEX_HOME/build/tests/regression/sgemm_tcu --args="-m24 -n16 -k64"
1.2 TCU WMMA矩阵基本概念
在Vortex中,最基本的矩阵计算单元称为WMMA(Warp Matrix Multiple-Accumulate) ,这是硬件定制指令集所能支持的矩阵大小。更大的矩阵,需要软件来分块调度。
WMMA 的矩阵大小跟线程数(NT)有关,如下所示。
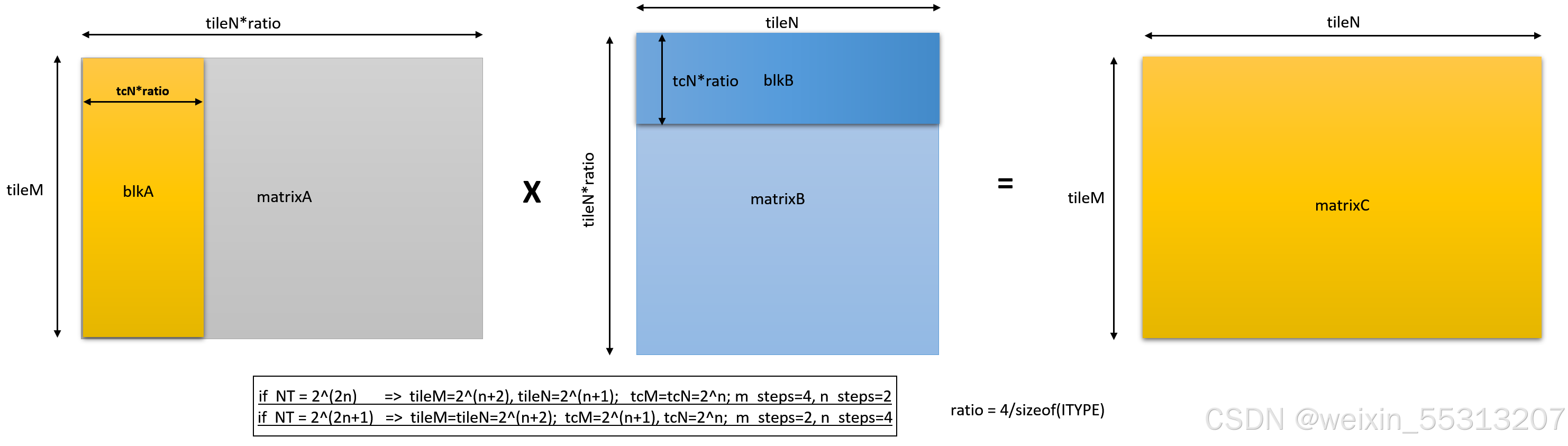
WMMA的硬件功能就是: matrixC += matrixA x matrixB
- tileM是matrixA/matrixC的行数,tileN是matrixB/matrixC的列数
- tileK = tileN*ratio是matrixA的列数,也是matrixB的行数。ratio为XLEN/sizeof(ITYPE),如果输入ITYPE是uint8,则ratio=32/8=4,其意义是RISC-V RVI32的一个数据单元存4个uint8
以线程数NT为4/8/16为例,我们有如下表格。 m_steps/n_steps是tile*系数和tc*系数的比例,WMMA计算周期数实际上为m_steps * n_step * n_steps,既16,或者32,依赖于NT是2^(2n)或者2^(2n+1)。

1.3 TCU大矩阵分块计算
大矩阵的行和列,必须是tileM,tileN的整数倍。
在前面的仿真例子里,"**-m24 -n16 -k64"**意味着行数是3倍(M/tileM=3),列数是2倍(N/tileN=2)。
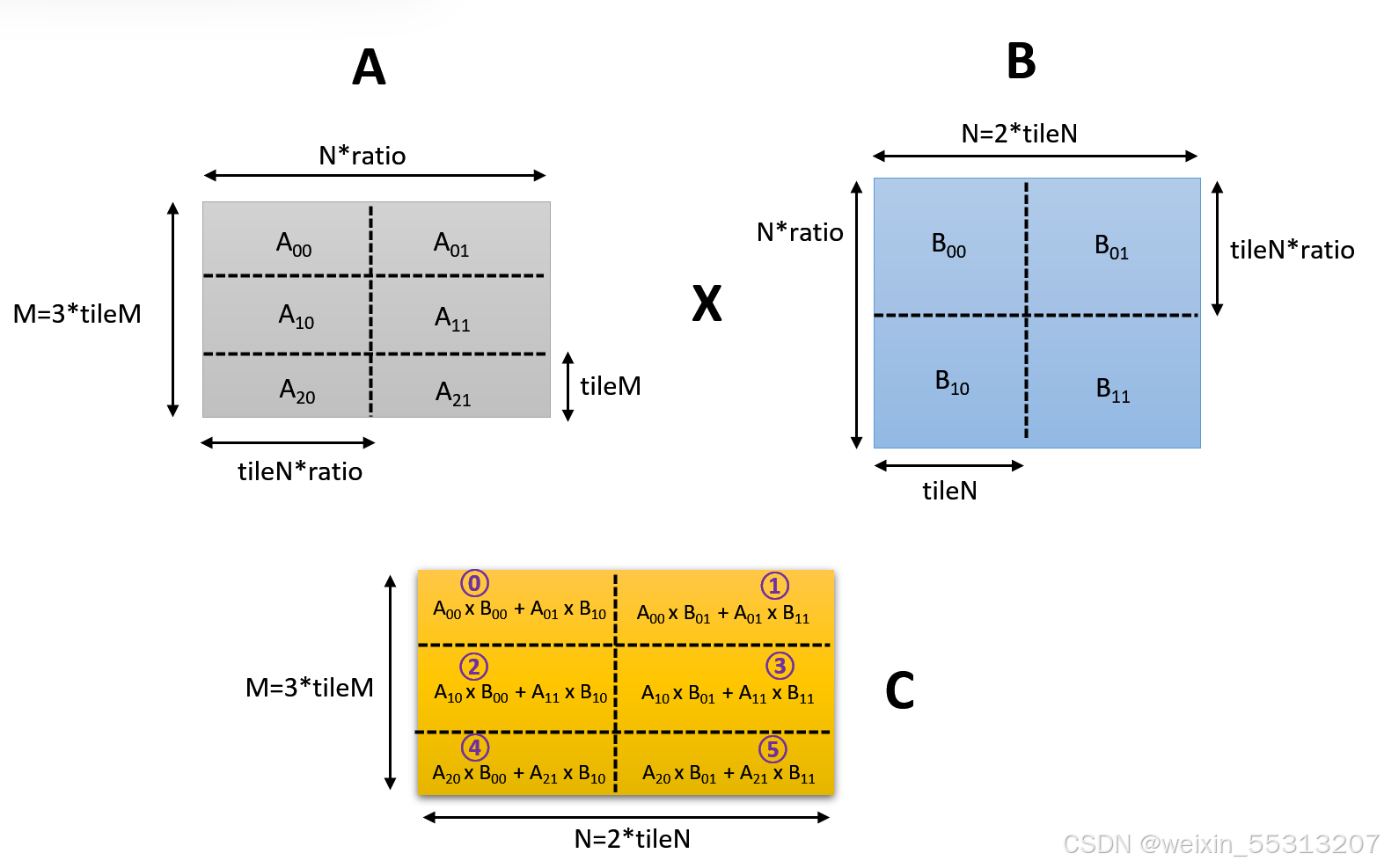
每个WMMA占用一个WARP的完整线程寄存器,其位宽 = NT * XLEN。
"**-m24 -n16"**意味着总共6(3x2)个WARP要串行执行来完成整个大矩阵的计算(单核情况下如此)。
以下假设单核情况,每个核4个WARP的配置,group_id为每个WMMA小矩阵的序号,WAPR执行情况如下。
- WAPR0执行两遍,对应group_id序号0/4
- WARP1执行两遍,对应group_id序号1/5
- WARP2执行一遍,对应group_id序号为2
- WARP3执行一遍,对应group_id序号为3
要注意的是,group_id的序号,表示的是WMMA小矩阵的块号,并不是对应每个块的计算先后顺序,group_id=4(WARP0),有可能优先于group_id=2/3,因为Schedule调度WARP的逻辑,是WAPR0优先级高于其他WARP。在WMMA计算过程中,不同WARP也可能交织在一起。

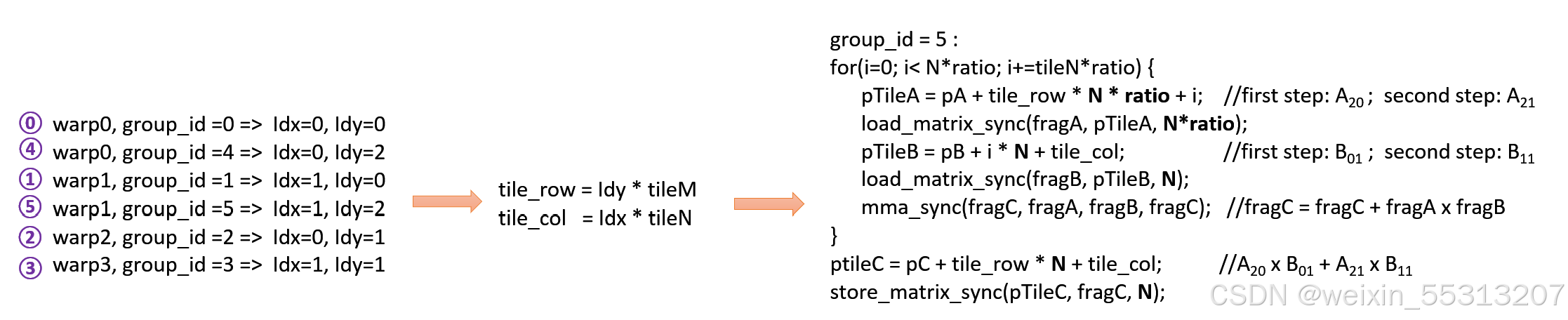
我们以group_id=5为例,描述WMMA矩阵计算步骤。
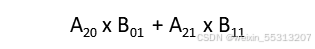
其软件伪代码如下所示:
- 由group_id=5,可以算出对应的tile_row, tile_col
- 对于每个group_id,需要遍历矩阵A里的每行的WMMA矩阵,以及对应矩阵B里的每列WMMA矩阵,执行A x B + C (C初始化为0)
- 第一次循环,先把
的数据载入fragA,再把
- 第二次循环,先把
- 在循环体外,把fragC结果存入大矩阵C对应的缓冲区,其块地址的偏移是"pC + tile_row * N + tile_col"
由此可见,大矩阵计算多了软件搬移块数据的额外开销。
更详细的CPP代码在如下目录(主要是前3个文件,前2个用了C++模板和命名空间功能,能灵活支持多种数据格式,第3个文件提供了通用的WARP和THREAD的调度功能):
- $VORTEX_HOME/kernel/include/vx_tensor.h
- $VORTEX_HOME/sim/common/tensor_cfg.h
- $VORTEX_HOME/kernel/src/vx_spawn.c
- $VORTEX_HOME/build/tests/regression/sgemm_tcu/kernel.cpp
mma_sync的代码如下所示,最核心的就是定制指令。对于不同的NT,matrixB/matrixC对应不同的输入/输出寄存器。
- matrixA : f0~f7
- NT=2^(2n+1), matrixB使用f10~f17,matrixC使用f24~f31
- NT=2^(2n),matrixB使用f28~f31,matrixC使用f10~f17
稍微解释一下**"asm volatile ...."** 的语法**:**
- 第一个冒号用来指定用了哪些输出寄存器
- 第二个冒号用来指定指令和输入立即数/输入寄存器:insn是RISCV_CUSTOM0自定义指令;fmd/fms对应rd和rs1,它们是编译后的立即数("i"的隐含意义);后面跟的则指定了所有输入寄存器
- 第三个冒号,可选;如果有的话,用来指定有哪些其他寄存器的值受指令执行影响,用来通知编译器现场保护其他寄存器
在反汇编后,在WMMA指令前的那些给FPU寄存器赋值指令是看不到的,它们都挪到了load_matrix_sync里面,猜测是因为mma_sync和load_matrix_sync都声明成inline,编译器能把不同函数里的功能进行合并优化。
; asm volatile (".insn r %insn, 0, 2, x%fmd, x%fms, x0"
800003f0: 0b 04 05 04 <unknown>
template <typename FragD, typename FragA, typename FragB, typename FragC>static attribute((always_inline )) void mma_sync(FragD &fragD, const FragA &fragA, const FragB &fragB, const FragC &fragC) {
static_assert(FragA::Use == matrix_a, "A must be matrix_a");
static_assert(FragB::Use == matrix_b, "B must be matrix_b");
static_assert(FragC::Use == accumulator, "C must be accumulator");
static_assert(FragD::Use == accumulator, "D must be accumulator");
// fragA: caller-saved registers (f0-f7)
register float fa0 asm("f0") = fragA.data0;
register float fa1 asm("f1") = fragA.data1;
register float fa2 asm("f2") = fragA.data2;
register float fa3 asm("f3") = fragA.data3;
register float fa4 asm("f4") = fragA.data4;
register float fa5 asm("f5") = fragA.data5;
register float fa6 asm("f6") = fragA.data6;
register float fa7 asm("f7") = fragA.data7;
if constexpr (FragB::NR == 8) { //NT = 2^(2n+1)
// fragB: caller-saved registers (f10-f17)
register float fb0 asm("f10") = fragB.data0;
register float fb1 asm("f11") = fragB.data1;
register float fb2 asm("f12") = fragB.data2;
register float fb3 asm("f13") = fragB.data3;
register float fb4 asm("f14") = fragB.data4;
register float fb5 asm("f15") = fragB.data5;
register float fb6 asm("f16") = fragB.data6;
register float fb7 asm("f17") = fragB.data7;
// fragC: mix of caller-saved (f28-f31) and callee-saved (f18-f21)
register float fc0 asm("f24") = fragC.data0;
register float fc1 asm("f25") = fragC.data1;
register float fc2 asm("f26") = fragC.data2;
register float fc3 asm("f27") = fragC.data3;
register float fc4 asm("f28") = fragC.data4;
register float fc5 asm("f29") = fragC.data5;
register float fc6 asm("f30") = fragC.data6;
register float fc7 asm("f31") = fragC.data7;
// Force outputs into accumulator registers
register float fd0 asm("f24");
register float fd1 asm("f25");
register float fd2 asm("f26");
register float fd3 asm("f27");
register float fd4 asm("f28");
register float fd5 asm("f29");
register float fd6 asm("f30");
register float fd7 asm("f31");
asm volatile (".insn r %insn, 0, 2, x%fmd, x%fms, x0"
: "=f"(fd0), "=f"(fd1), "=f"(fd2), "=f"(fd3), "=f"(fd4), "=f"(fd5), "=f"(fd6), "=f"(fd7)
: insn"i"(RISCV_CUSTOM0), fmd"i"(Ot::id), fms"i"(It::id),
"f"(fa0), "f"(fa1), "f"(fa2), "f"(fa3), "f"(fa4), "f"(fa5), "f"(fa6), "f"(fa7),
"f"(fb0), "f"(fb1), "f"(fb2), "f"(fb3), "f"(fb4), "f"(fb5), "f"(fb6), "f"(fb7),
"f"(fc0), "f"(fc1), "f"(fc2), "f"(fc3), "f"(fc4), "f"(fc5), "f"(fc6), "f"(fc7)
);// Write results to fragD
fragD.data = {fd0, fd1, fd2, fd3, fd4, fd5, fd6, fd7};
} else { //NT = 2^(2n)
static_assert(FragB::NR == 4, "Unsupported number of registers for FragB");
// fragB: caller-saved registers (f28-f31)
register float fb0 asm("f28") = fragB.data0;
register float fb1 asm("f29") = fragB.data1;
register float fb2 asm("f30") = fragB.data2;
register float fb3 asm("f31") = fragB.data3;
// fragC: mix of caller-saved (f10-f17)
register float fc0 asm("f10") = fragC.data0;
register float fc1 asm("f11") = fragC.data1;
register float fc2 asm("f12") = fragC.data2;
register float fc3 asm("f13") = fragC.data3;
register float fc4 asm("f14") = fragC.data4;
register float fc5 asm("f15") = fragC.data5;
register float fc6 asm("f16") = fragC.data6;
register float fc7 asm("f17") = fragC.data7;
// Force outputs into accumulator registers
register float fd0 asm("f10");
register float fd1 asm("f11");
register float fd2 asm("f12");
register float fd3 asm("f13");
register float fd4 asm("f14");
register float fd5 asm("f15");
register float fd6 asm("f16");
register float fd7 asm("f17");
asm volatile (".insn r %insn, 0, 2, x%fmd, x%fms, x0"
: "=f"(fd0), "=f"(fd1), "=f"(fd2), "=f"(fd3), "=f"(fd4), "=f"(fd5), "=f"(fd6), "=f"(fd7)
: insn"i"(RISCV_CUSTOM0), fmd"i"(Ot::id), fms"i"(It::id),
"f"(fa0), "f"(fa1), "f"(fa2), "f"(fa3), "f"(fa4), "f"(fa5), "f"(fa6), "f"(fa7),
"f"(fb0), "f"(fb1), "f"(fb2), "f"(fb3),
"f"(fc0), "f"(fc1), "f"(fc2), "f"(fc3), "f"(fc4), "f"(fc5), "f"(fc6), "f"(fc7)
);// Write results to fragD
fragD.data = {fd0, fd1, fd2, fd3, fd4, fd5, fd6, fd7};
}
}
};
二、TCU WMMA硬件代码分析
TCU WMMA硬件代码主要分布在3个流水线中,依流水线顺序展开描述。
2.1 Decode WMMA译码
Decode流水线对WMMA指令进行译码。
自定义指令集0(opcode=7'h0B) && funct7=0x2 && funct3=0x0,此为WMMA指令,指令的rd/rs1立即数存入fmt_d/fmt_s,它们表示WMMA的输出和输入格式。三个USE_IREG主要是产生标志位use_rs1/use_rs2/use_rs3,这三个标志位在Issue流水线的Scoreboard和Operand里都会用到。
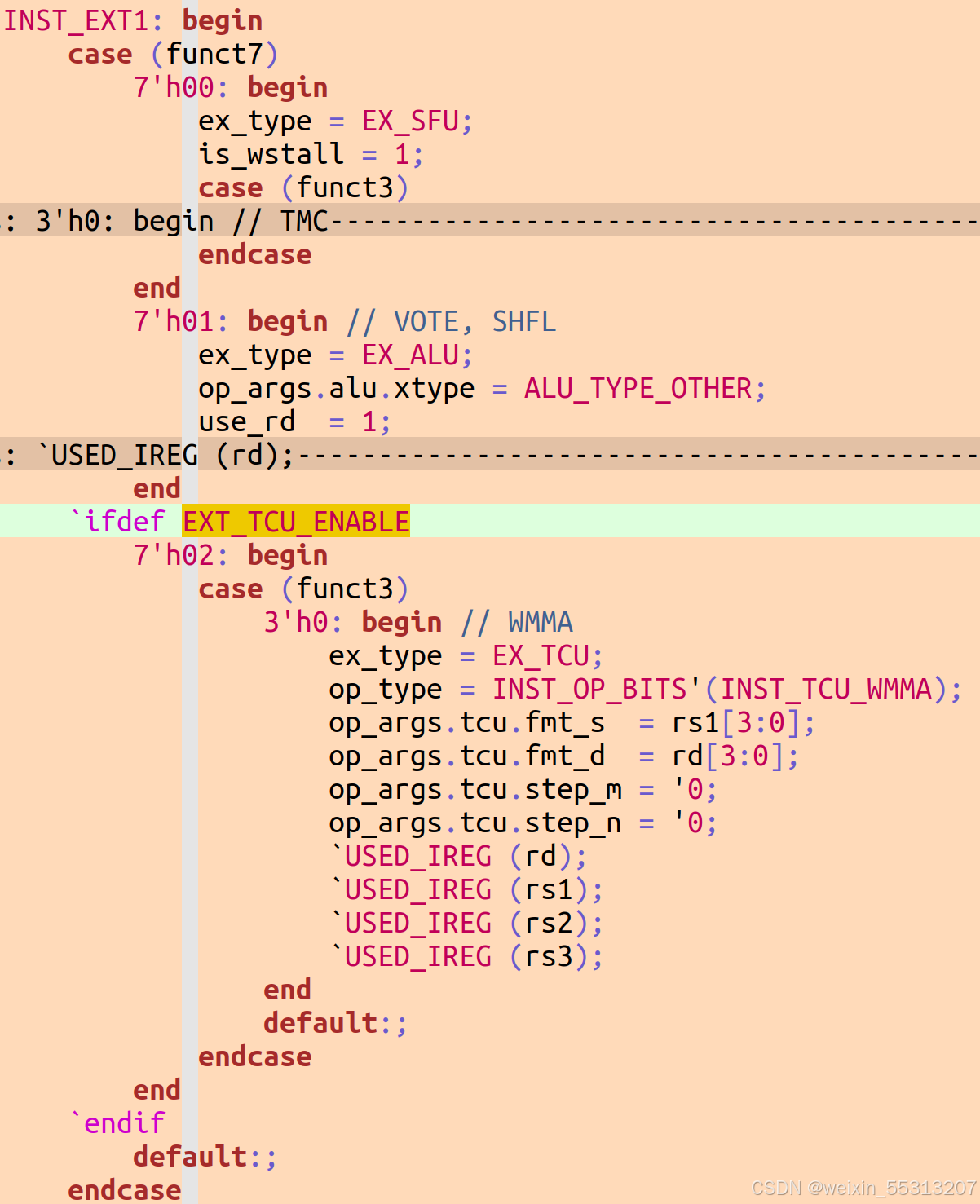
2.2 Issue WMMA rs1/rs2/rs3读地址偏移
Issue流水线的Ibuffer,对WMMA执行了以下操作,在TCU流水线会进一步解释其原因:
- WMMA指令由单个周期扩展为(K_STEPS*M_STEPS*N_STEPS)周期
- 计数值m_index/n_index赋值给op_args,Execute TCU里的乘法单元取matrixA/matrixB行列数据时需要用到。实际上m_index不需要,n_index只在NT=2^(2n+1)时用来取matrixB的数据
- 对应每个周期,输入寄存器rs1/rs2/rs3地址需要偏移,Execute TCU里的乘法单元在不同周期能遍历matrixA/matrixB的行列数据
- 计数值赋值给uuid低32位的高位,这个看过去不是很必要,可能的作用是作为debug的辅助信息
assign ibuf_out.op_args.tcu.step_m = 4'(m_index ); //计数值赋值给op_args
assign ibuf_out.op_args.tcu.step_n = 4'(n_index);
`ifdef UUID_ENABLE //计数值赋值给uuid低32位的高位
//uuid高于32位是{ core_id, wid }
//uuid总共44bits,见Schedule章节
wire 31:0 uuid_lo = {counter, ibuf_in.uuid0 +: (32-CTR_W)};
wire UUID_WIDTH-1:0 uuid = {ibuf_in.uuidUUID_WIDTH-1:32, uuid_lo};
`else
wire UUID_WIDTH-1:0 uuid = ibuf_in.uuid;
`endif
// Register offsets //计数值顺序是 { k, m, n }
wire CTR_W-1:0 rs1_offset = ((CTR_W'(m_index) >> LG_A_SB) << LG_K) | CTR_W'(k_index);
wire CTR_W-1:0 rs2_offset = ((CTR_W'(k_index) << LG_N) | CTR_W'(n_index)) >> LG_B_SB;
wire CTR_W-1:0 rs3_offset = (CTR_W'(m_index) << LG_N) | CTR_W'(n_index);
wire 4:0 rs1 = TCU_RA + 5'(rs1_offset);
wire 4:0 rs2 = TCU_RB + 5'(rs2_offset);
wire 4:0 rs3 = TCU_RC + 5'(rs3_offset);
//因为使用浮点寄存器
//所以加固定偏移32
//0~31是定点,32~63是浮点
assign ibuf_out.rs1 = make_reg_num(REG_TYPE_F, rs1);
assign ibuf_out.rs2 = make_reg_num(REG_TYPE_F, rs2);
assign ibuf_out.rs3 = make_reg_num(REG_TYPE_F, rs3 );
assign ibuf_out.rd = make_reg_num(REG_TYPE_F, rs3);
下面是$VORTEX_HOME/hw/rtl/tcu/VX_tcu_pkg.sv里的部分截图,TILE_*/TC_*对应前面描述的WMMA tile*/tc*(C代码里的变量名称),由它的计算过程可以看出:
- tileM >= tileN;tcM >= tcN
- TILE_K = TILE_N; TC_K = TC_N
- tcM*tcN=NT
- tileM*tileN = NT*8
- m_steps*n_steps必定为8
C语言里的计算公式和RTL里的计算公式,二者各写一套,都是基于同样的逻辑,交叉验证设计的正确性。
localparam TCU_NT = `NUM_THREADS;
localparam TCU_NR = 8 ;
localparam TCU_DP = 0;
// Tile dimensions
localparam TCU_TILE_CAP = TCU_NT * TCU_NR;
localparam TCU_LG_TILE_CAP = $clog2(TCU_TILE_CAP);
localparam TCU_TILE_EN = TCU_LG_TILE_CAP / 2 ;
localparam TCU_TILE_EM = TCU_LG_TILE_CAP - TCU_TILE_EN;
localparam TCU_TILE_M = 1 << TCU_TILE_EM;
localparam TCU_TILE_N = 1 << TCU_TILE_EN;
localparam TCU_TILE_K = TCU_TILE_CAP / ((TCU_TILE_M > TCU_TILE_N) ? TCU_TILE_M : TCU_TILE_N);
// Block dimensions
localparam TCU_BLOCK_CAP = TCU_NT;
localparam TCU_LG_BLOCK_CAP = $clog2(TCU_BLOCK_CAP);
localparam TCU_BLOCK_EN = TCU_LG_BLOCK_CAP / 2;
localparam TCU_BLOCK_EM = TCU_LG_BLOCK_CAP - TCU_BLOCK_EN;
localparam TCU_TC_M = 1 << TCU_BLOCK_EM;
localparam TCU_TC_N = 1 << TCU_BLOCK_EN;
localparam TCU_TC_K = (TCU_DP != 0) ? TCU_DP : (TCU_BLOCK_CAP / ((TCU_TC_M > TCU_TC_N) ? TCU_TC_M : TCU_TC_N));
// Step counts
localparam TCU_M_STEPS = TCU_TILE_M / TCU_TC_M;
localparam TCU_N_STEPS = TCU_TILE_N / TCU_TC_N;
localparam TCU_K_STEPS = TCU_TILE_K / TCU_TC_K;
2.3 Execute TCU WMMA
这一步是矩阵计算的最重要模块TCU WMMA: matrixC += matrixA x matrixB,留待TCU WMMA(2)展开。
总结
本文分析了Vortex RISC-V GPGPU中TCU(Tensor Control Unit)模块的功能实现。TCU作为执行矩阵计算的核心单元,支持多种浮点和定点数据格式。文章详细介绍了TCU仿真命令参数设置、WMMA(Warp Matrix Multiple-Accumulate)基本概念,以及大矩阵分块计算的实现方法。重点阐述了TCU硬件代码在流水线中的分布,包括Decode阶段的指令译码、Issue阶段的寄存器地址偏移处理等关键技术点。总之,Vortex采用定制指令集实现高效的WMMA矩阵运算,大规模矩阵计算则通过软件分块调度WMMA予以实现。