我们公司是使用openresty作为网关,用于进行权限认证,反向代理,以及一些请求的处理。在使用过程中,我们遇到过这种情况,大部分时候openresty的性能都很好,cpu使用率都很低,但是有时候会突然cpu飙升,nginx的cpu打满,然后请求处理开始失败。但是这种情况出现次数少,持续时间不长,没法把cpu火焰图抓出来查看原因。
因此这里进行一次网关性能优化的探索,主要有两个目的,一是提高openresty的网关性能,处理偶现的这种异常情况。二是希望能有一种通用的智能的openresty限流方案,能确保在极限请求压力下,openresty能通过拒绝一部分请求的方式保障大部分请求正常被处理。
一、openresty网关性能优化
这里首先尝试探索openresty网关的性能优化方案。主要的思路就是先模拟出线上出现问题的情况,因为线上情况比较复杂,不好完全模拟,这里设计一个接口,将线上最常见的鉴权代码放进去,然后限制openresty的cpu上限,接着用高并发压测这个接口,把openresty的cpu打满,模拟线上的情况。
模拟后通过监控查看openresty的qps以及接口成功率,以这两者的乘积,即每秒的成功请求数作为最终压测的结果。 后面通过几种方案修改并重复压测,通过每秒成功数来判断方案是否有效提高了openresty的性能。
1.1 压测环境介绍
这里首先介绍下压测环境:
- openresty使用k8s部署,将其cpu limit设置为0.3,通过一个较低的cpu上线能更加容易的把cpu打满,方便压测。
- 压测工具使用hey,hey -t 5 -n 999999999 -c 3700 -q 1 'http://172.16.1.97:8001/test/nomal/request' 通过这种命令持续压测,-c 代表并发是3700,-q代表每秒每个并发最多请求一次,这样限制了总的qps最多为3700。
- 接口/test/nomal/request的逻辑如下,简单点说的话,就是先查redis查找认证信息,没查到就从mongo数据库中找,并设置到redis中供下次使用,是很常见的授权认证方式。这里简化了下,大家可以简单看下代码体会下。后面做了个处理,如果redis或者mongo中查到了数据,则返回200状态码,否则返回503状态码,这样可以在nginx监控或者压测结果中比较清楚的看出来成功率。
bash
location /test/nomal/request {
content_by_lua_block {
function getAuthInfo(id)
local authInfo = redis:get("L-" .. id)
if not authInfo then
local authInfo = get_from_mongo(id)
if authInfo and cjson.encode(authInfo) ~= "" then
redis:set("L-" .. id, authInfo)
else
return nil
end
end
return authInfo
end
local id = getAuthInfo("testId")
if not id or tostring(id)=="" then
return ngx.exit(ngx.HTTP_SERVICE_UNAVAILABLE)
end
return ngx.exit(ngx.HTTP_OK)
}
}- redis和mongo都做了限流保护,避免因为网关占用了太多连接,导致其他服务连接redis或者mongo出现问题,redis的连接池数量是500,超过这个数量的redis请求会被放在一个400长度的队列中,超出这个队列的请求会直接失败。
1.2 线上环境模拟
这里首先模拟线上环境,把openresty的cpu打满,并且通过抓取火焰图来分析cpu使用情况。压测命令都是一样的,这个后续不再说明: hey -t 5 -n 999999999 -c 3700 -q 1 'http://172.16.1.97:8001/test/nomal/request'
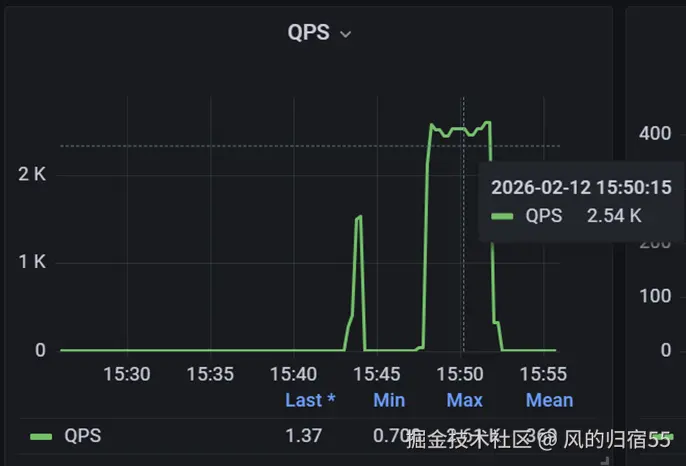
测试结果:
qps: 2500
成功率:14%
每秒成功请求数:2500*14%=350
导出的lua火焰图:

分析:
从导出的lua火焰图可以看出,lua的大部分cpu都被用在了mongo库的处理上,因此我们下一步的优化方向就是通过减少mongo请求来提升处理能力。这里推荐下,如果想要配置同款的nginx监控和lua导出火焰图,可以查看笔者之前的文章:openresty监控 以及 openresty容器导出火焰图
1.3 优化mongo请求
仔细查看日志后发现,因为cpu打满了,openresty的处理速度变慢,很多redis的连接可能等待了一秒都没被处理,这就超过了redis的连接超时时间,导致缓存穿透,请求都去查mongo了,即使mongo连接也有限制,但是查询mongo的库估计比较占用cpu,导致这部分cpu使用率较高。
于是我们可以进行代码优化,只有在redis查询成功,但是没查到数据的情况下才去查mongo,这样就能避免redis失败时穿透到mongo。
bash
function getAuthInfo(id)
local authInfo,err = redis:get("L-" .. id)
if not authInfo and not err then
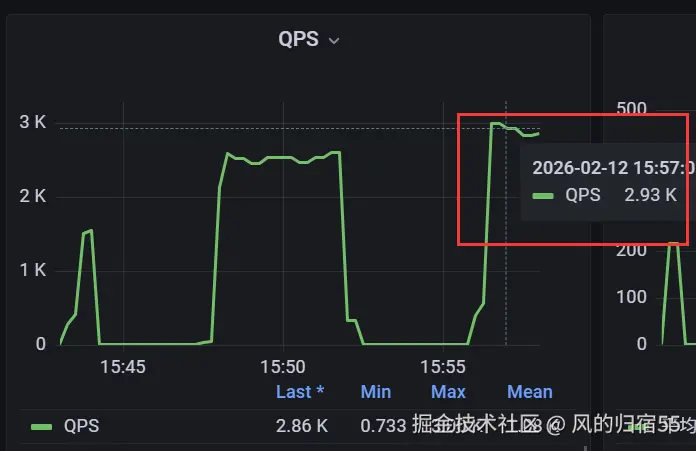
local authInfo = get_from_mongo(id)测试结果:
qps: 2816
成功率:27.4%
每秒成功请求数:2816*27.4%=771
导出的lua火焰图:

分析:
从压测的结果可以看出,qps提高了,错误率反而下降了,每秒成功请求数是之前的2倍,说明优化是有效的,但是错误率还是有点高,这个是否有办法降低。目前比较容易想到的方式是限流,只要我们根据一定指标把多余的请求拒绝掉,是否就可以确保openresty始终能处理一定量的请求了呢。
1.4 限流
我们希望找一种限流方案,最好是比较智能的方案,可以根据一个固定的阈值触发。比如一个openresty实例在固定cpu下只能处理1000个请求,那最好是能找到个指标,当超出这个指标时就进行限流,把超过openresty处理能力的请求拒绝掉,从而最大化的保障openresty处理能力,避免因为雪崩导致大部分请求无法被正常处理。
这里额外说明下为什么不用常见的漏桶和令牌等限流方式,因为我们觉得这个方式的阈值比较固定,不够智能,很多时候可能阈值达到了,但是nginx实际上还没跑满,或者nginx已经跑满出问题了,但是qps阈值还没达到。我们希望找到一个更智能的限流方式。
这个我们尝试了几个指标,都不太理想,这里直接说结论,最能体现nginx到达处理能力瓶颈的指标就是cpu使用率,当其达到阈值时就是openresty出问题的时候。 这里的探索我们后面再说明,先来看修改方案和测试结果。
我们首先简单做了个限流,当检测到openresty cpu跑满时就开始限流,按照比例限制流量,比如20%的请求直接失败,并且如果cpu没有降下来就继续提升限流比例,cpu降下来了就降低限流比例。 不过目前没有实现完整的方案,而是先简单做了一版,手动控制cpu是否跑满的开关,限流也是默认是20%,也就是默认限制20%的请求。
测试结果:
qps: 3084
成功率:29.7%
每秒成功请求数:3084*29.7%=915
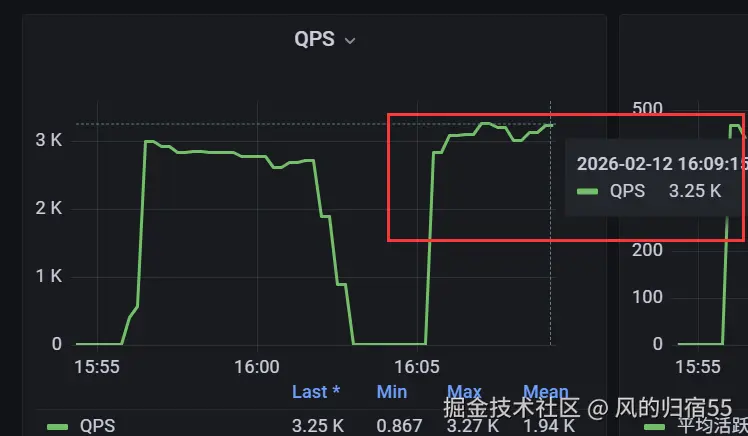
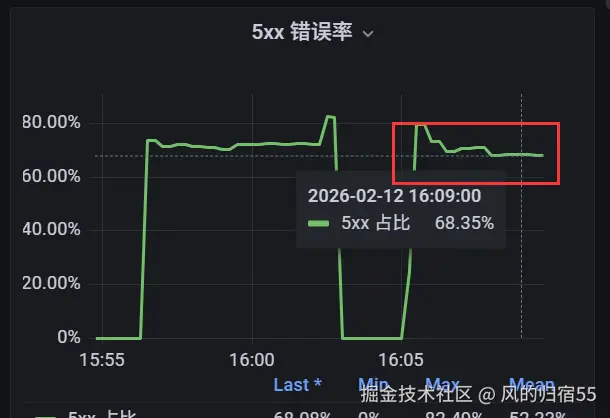
导出的nginx火焰图对比:
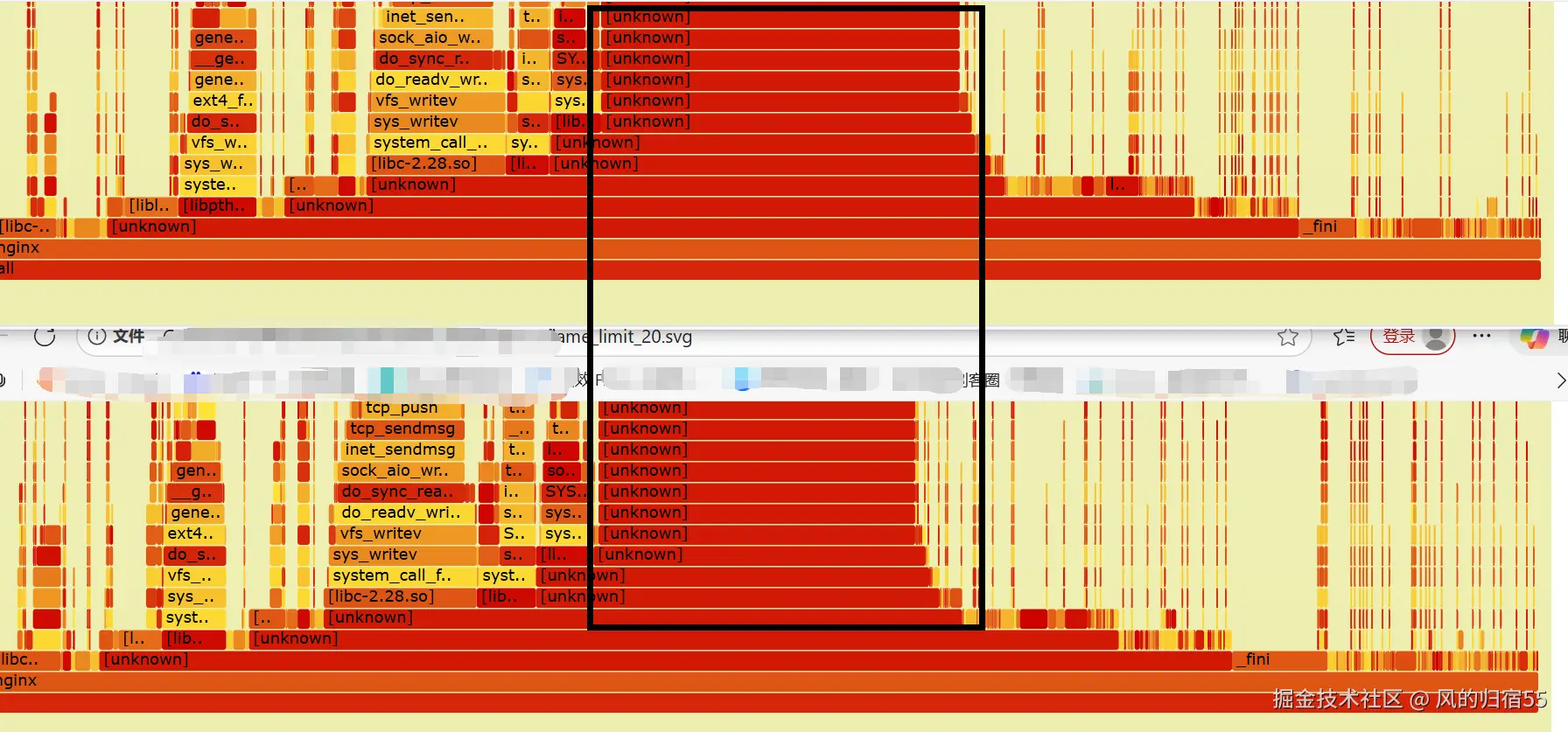
分析:
这里的火焰图是限流之前和之后的nginx cpu火焰图,黑圈中的unknown部分就是lua代码使用的cpu,可以看出限流后确实lua cpu使用率降低了,同时每秒成功请求数也提升了16%左右。但是并没有达到我们希望的理想效果,异常率还是有点高,这部分需要后面继续优化下限流方案。
这里我们重新考虑下redis,因为redis的连接池导致有部分请求失败,但是实际上redis支持的连接数上限是很高的,是否可以通过调整redis连接池配置的方式进一步优化?
1.4 redis连接池配置调整
我们这里不直接修改redis的连接池的最大连接数,修改连接数用满时的存放redis请求的队列的最大值,之前是400,我们改成2000来进行测试下。
测试结果:
qps: 2424
成功率:56.6%
每秒成功请求数:2424*56.6%=1,371
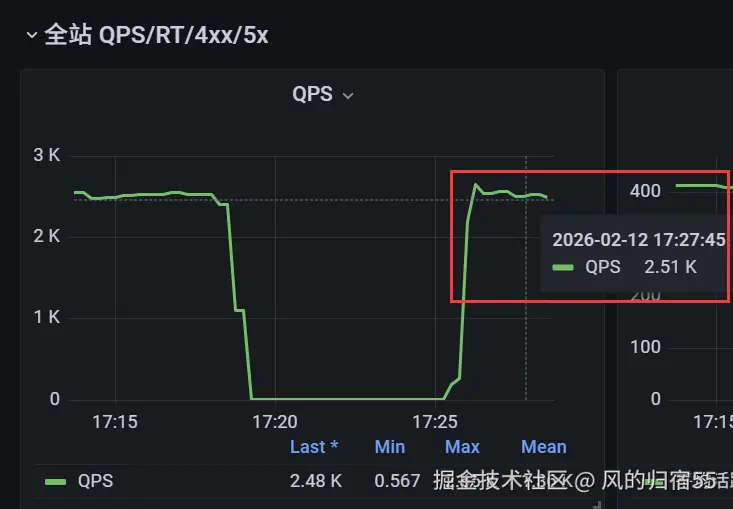
分析:
我们发现qps下降了,但是请求的成功率上升了很多,从而每秒成功请求数也上升了很多。这里分析下原因,应该是因为我们使用hey的压测是3700并发,并且每个连接每秒最多请求一次,通过这种方式控制总qps最多是3700/秒。 这里把redis请求放入了队列,导致更多的请求能够被成功处理,只是请求本身的延迟变高了,因此在每个连接上的qps就降低了。
举个例子,本来一个连接1秒一次,因为redis超过队列,就失败了,而队列加长后,可能变成每个连接的请求2秒才处理完成,但是redis请求在队列中等待,请求处理成功了,因此qps降低了,但是请求成功率上升了。
二、openresty网关限流方案探索
这里探索下openresty网关的限流方案,我们希望找到的最理想的方案就是能有一个指标可以明确表示出nginx的处理能力,这个指标出问题就说明nginx超过了其最大处理能力,请求会出问题。因此最主要的步骤就是找出这个能体现nginx处理能力是否到达阈值的指标。
我们首先参考了java的web服务器的架构,java的请求是在worker线程中一个一个处理的,未被处理的请求被放在一个队列中,因此我们可以监控这个队列,只要队列里面堆积的请求数超过一定数量,就代表到达了web服务器的处理能力上限,我们就可以直接丢弃新请求进行限流,避免服务器被冲垮。
2.1 架构区别
但是在nginx中我们发现这种方案并不适用,因为nginx和java的web服务器处理模型不一样。java的web服务器虽然也有异步,但是异步比较少,像是redis和mong这种数据库处理基本都是同步的,因此他处理请求都是一个一个处理,上一个处理完成了再处理下一个,因为查询redis和mongo的同步导致请求的处理过程也基本是同步的。
而nginx不一样,nginx是异步模型,请求被nginx的worker进程accept接收后进行处理时,数据到了就会执行lua代码进行处理,等lua执行到redis查询时,这个是一个io,nginx会异步处理,直接切换下一个请求并处理,等到redis的回复数据到了之后再回来处理之前的请求。这就导致监控他的队列没什么效果,因为他接收请求的速度很快,只要有cpu就会把请求接进来,用队列监控的方式没有效果。
那么监控正在处理中的请求数量有用么? 这个可以通过nginx的ngx.var.connections_writing变量来查询,他代表nginx正在处理的请求数,但是我们发现这个也不好使,因为你不能判断到多少的时候nginx是有问题的。那用什么指标比较合适呢?下面列一下我们尝试使用作为阈值的指标。
2.2 可能的指标
- socket中未读的数据,epollo中待处理的io数量:如果nginx来不及处理,则建立的socket中会有来不及处理的数据,Established 状态下的 Recv-Q会变大,同时因为worker实例因为cpu跑满也没时间去accept连接,则LISTEN状态下的Recv-Q也会变大,但是这个指标并不能很好的获取并用于限流,因为nginx没到极限时,这些值也会有,只是多和少的区别。
- ngx.var.connections_writing数量,nginx正在处理的请求数:这个值没法很好的体现是否堆积,因为他代表当前正在处理的请求,等于qps 乘以 延迟,比如有些请求比较慢,但是qps不高,也会导致这个值有一定的数量,无法用于判断现在是否过载。
因此,我感觉目前最合适的指标就是nginx实例的cpu使用率,这个指标显而易见,但是也是最有效的。
2.3 cpu过载的后果
假设此时qps超过了nginx本身的处理能力,cpu打满是必然现象,因为nginx会异步的不断的接收新请求并进行处理,只要cpu没满,就能接收更多的请求并处理。
cpu打满后,请求会变慢,有些io如redis,mysql和mongo请求就会超时,导致虽然请求返回200,但是状态码是失败的。同时达到最大值后,nginx从socket中获取数据处理请求的速度变慢,socket中的请求会一直得不到处理,甚至nginx建立redis连接都会失败,从而连接池中的redis连接下降,进一步导致雪崩,本来能处理的请求也处理不了了。
结论:
综上所述,只要nginx的cpu没跑满,就代表nginx没问题,可以处理更多请求。但是一旦nginx的cpu跑满,就容易出现雪崩状态,所有的请求都正在被处理,但是因为cpu不足,请求会因为各种原因失败,整体失败率大幅上升,造成雪崩。
如果出现nginx cpu跑满的情况时,可以通过动态限流或者增加nginx实例避免雪崩。