目录
[编辑 编辑编辑](#编辑 编辑编辑)
[超级块(Super Block)](#超级块(Super Block))
[块位图(Block Bitmap)](#块位图(Block Bitmap))
[inode 位图(Inode Bitmap)](#inode 位图(Inode Bitmap))
[i 节点表(Inode Table)](#i 节点表(Inode Table))
[数据区(Data Block)](#数据区(Data Block))
一、磁盘
磁盘是计算机核心的磁性外存储设备,以磁性介质为载体记录数据,属于非易失性存储(断电后数据不会丢失),是计算机长期存储数据的核心 "仓库"。虽然当前笔记本主流存储设备是固态硬盘SSD,但机械磁盘依靠成本低,容量大依旧是组装服务器的首选。
且磁盘结构与Linux底层文件管理系统强相关,学习磁盘有助于Linux学习。
磁盘结构

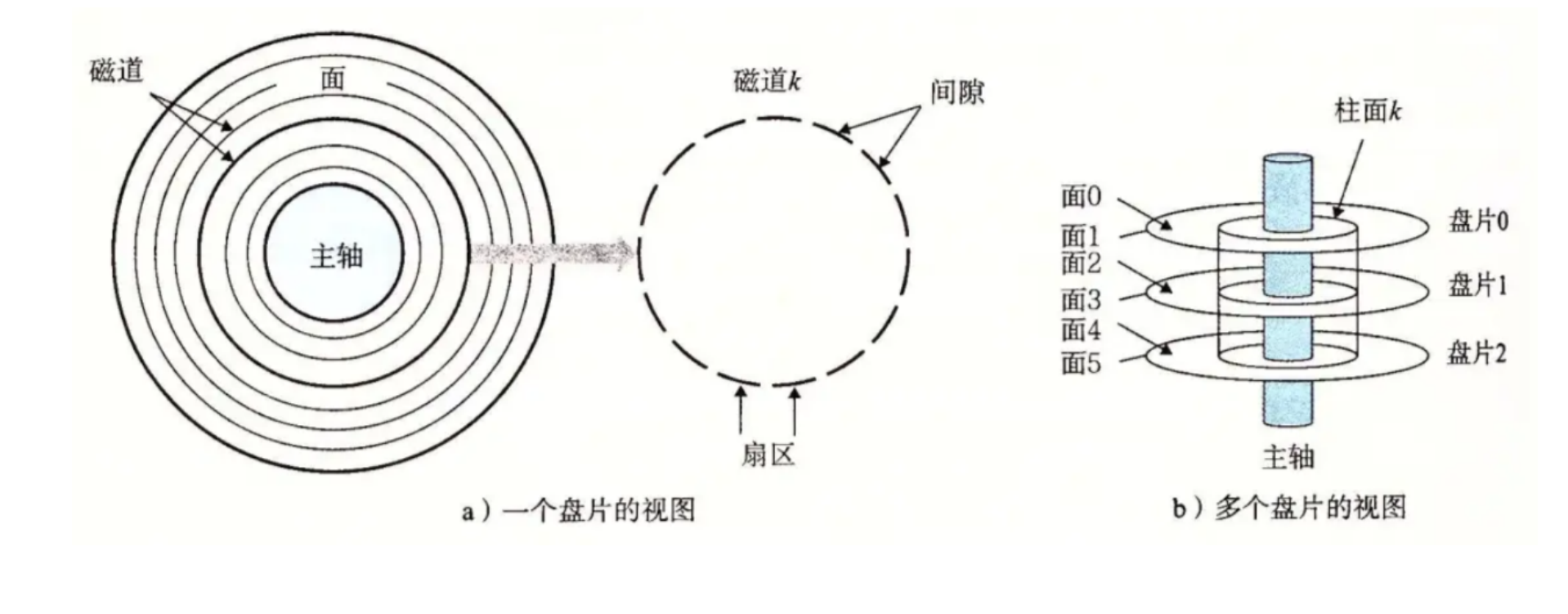
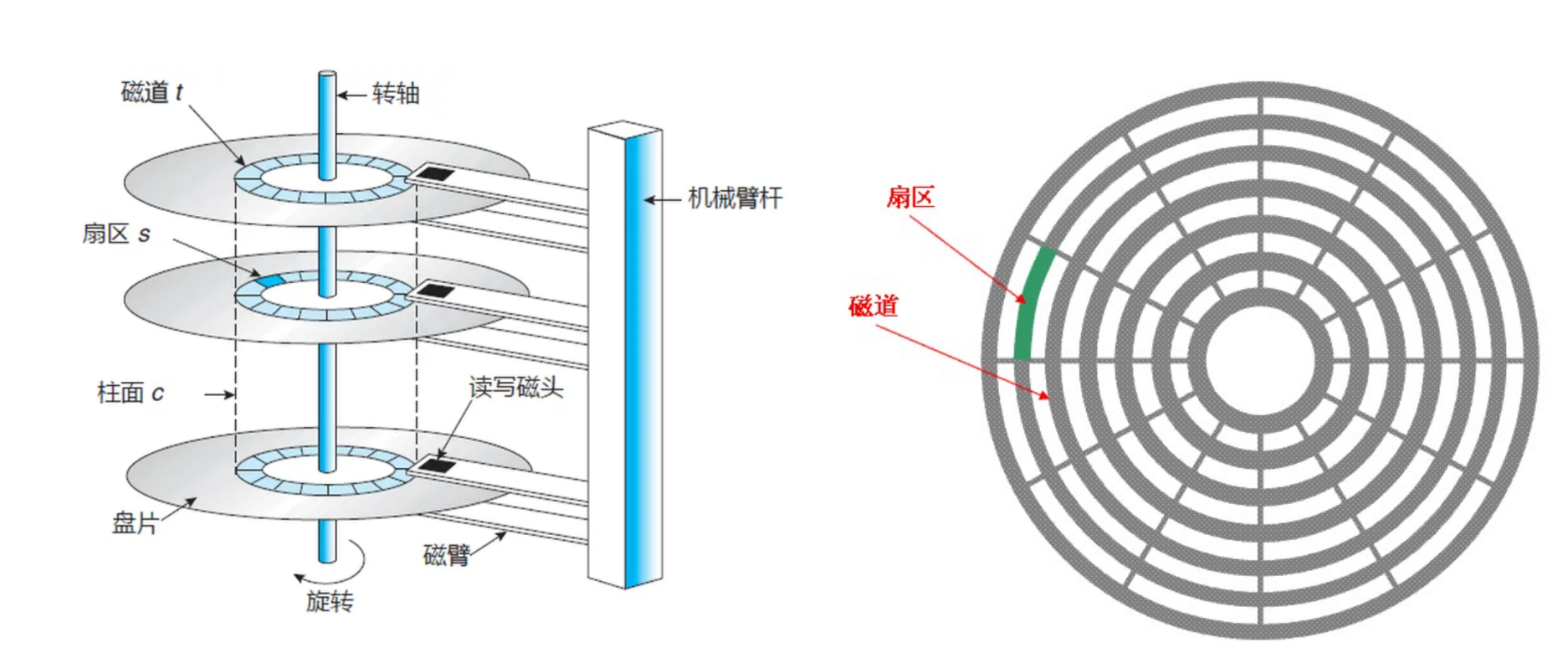
磁盘中往往存在多个盘片,在每个盘片上以转轴为中心有多个半径不同的圆环--磁道,每个磁道又是以多个扇区组成。扇区上的磁性代表着01机械码,也就是存储数据。
最经典的每个扇区能存储512字节数据(当然也有4k版本),当转轴高速转动的时候读写磁头会有规律的摆动,当探测到目标扇区后会进行对应的读写操作。
扇区是从磁盘读出和写入信息的最小单位,通常大小为 512 字节。
- 磁头(head)数:每个盘片一般有上下两面,分别对应 1 个磁头,共 2 个磁头
- 磁道(track)数:磁道是从盘片外圈往内圈编号 0 磁道,1 磁道......,靠近主轴的同心圆用于停靠磁头,不存储数据
- 柱面(cylinder)数:磁道构成柱面,数量上等同于磁道个数
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘片的数量
- 磁盘容量 = 磁头数 × 磁道 (柱面) 数 × 每道扇区数 × 每扇区字节数
我们要注意将柱面与圆盘分别开来,柱面是统一半径,各圆盘上的磁道总称,柱面不是单指某一个圆盘。
如何定位扇区
要定位一个扇区,首先需要确定其所在哪个柱面,再确定在哪个盘面上(各读写磁头是共进退的),最后确定在哪个扇区。在逻辑上就是一个三维数组。
回想过去常见的二维数组,我们要定位二维数组中的元素是通过行和列两步分别确定的。在磁盘上的定位逻辑与此相同(都是多维数组)。在之前C语言基础上,我们统一将多维数组看成线性结构。
在磁盘中定位扇区,步骤是:1.先定位所处柱面,2.再定位所处盘面,3.最后定位扇区
为什么先定位柱面?
首先磁盘上的多个读写磁头是共进退的(固定在同一转轴上),如果第一步判断所处盘面就会导致读取效率最慢的判断柱面/磁道动作需要执行两遍,效率远不如第一步判断柱面。
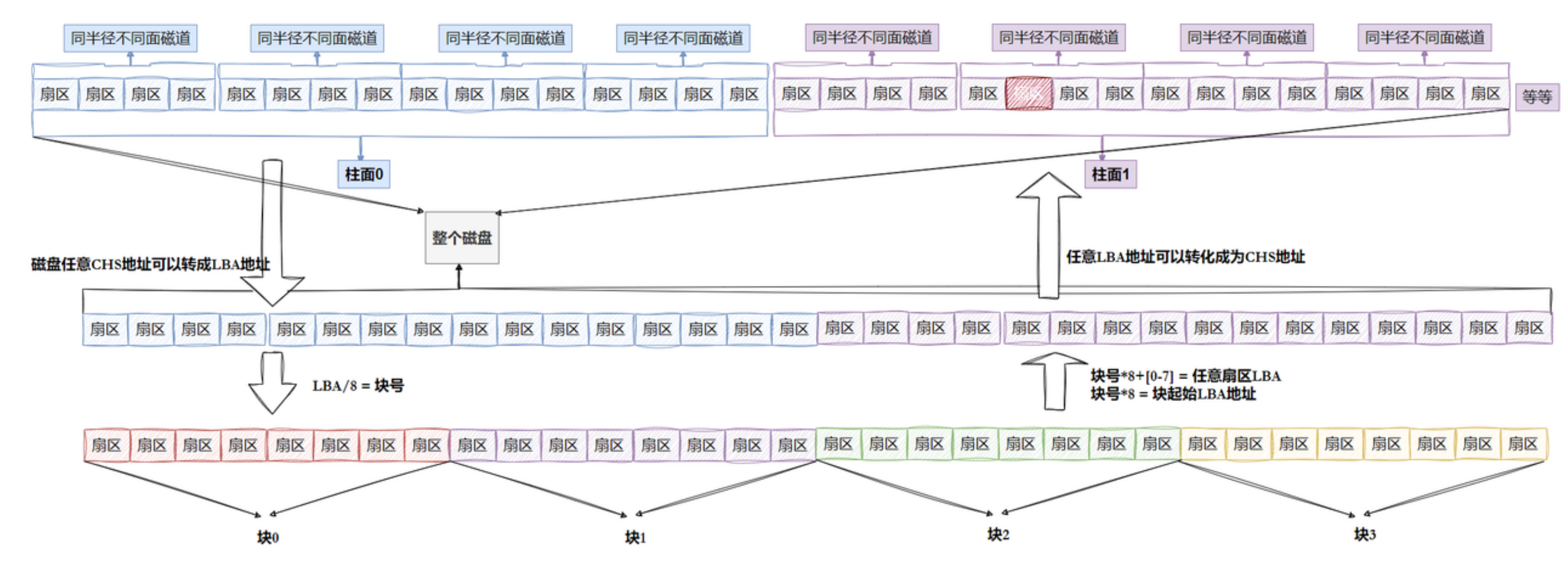
CHS地址和LBA地址
CHS(Cylinder-Head-Sector,柱面 - 磁头 - 扇区)是早期磁盘的物理寻址方式,而 LBA(Logical Block Address,逻辑块地址)是现代操作系统(包括 Linux)使用的线性寻址方式,两者本质是对同一物理扇区的不同编号方式。
说明白点CHS地址是三维的,而LBA地址是一维线性的。Linux采用LBA地址模式。
在Linux中,磁盘的存储容量会被视为对应容量的一维数组,下标从0开始。对于如何具体管理区分不同磁道、盘面、扇区则会由一套算法进行CHS地址和LBA地址之间的转化:
Linux会自动处理CHS和LBA地址之间的转化,并不需要我们进行额外处理。CHS和LBA的设计目的就是为了将硬件底层与操作系统解耦,当扇区存储大小为4k时仅需要改变转化算法,而不需要从头设计设配的数据结构。
二、文件系统
块和分区
磁盘上的扇区很多,如果读取文件需要一个个读取扇区就很慢,为了提升效率Linux系统将多个扇区组合到一起,这个由多个扇区组成的结构被称为"块"。
一个块的大小是在格式化的时候就确立的,不能被更改。一般是8个扇区为一块,存储空间为512*8=4096字节=4kb。
块是文件存储的最小单位。
电脑上通常分有C盘D盘分区,磁盘上的分区结构也主要是为了把整块物理磁盘的存储空间做「逻辑隔离与精细化管理」,解决「整盘使用的各种痛点」。最常见的就是C盘D盘的分区就是为了防止普通文件过多占用系统盘导致卡顿崩溃。
inode--索引节点
文件=内容+属性,我们使用ls和stat指令能获取文件的属性信息
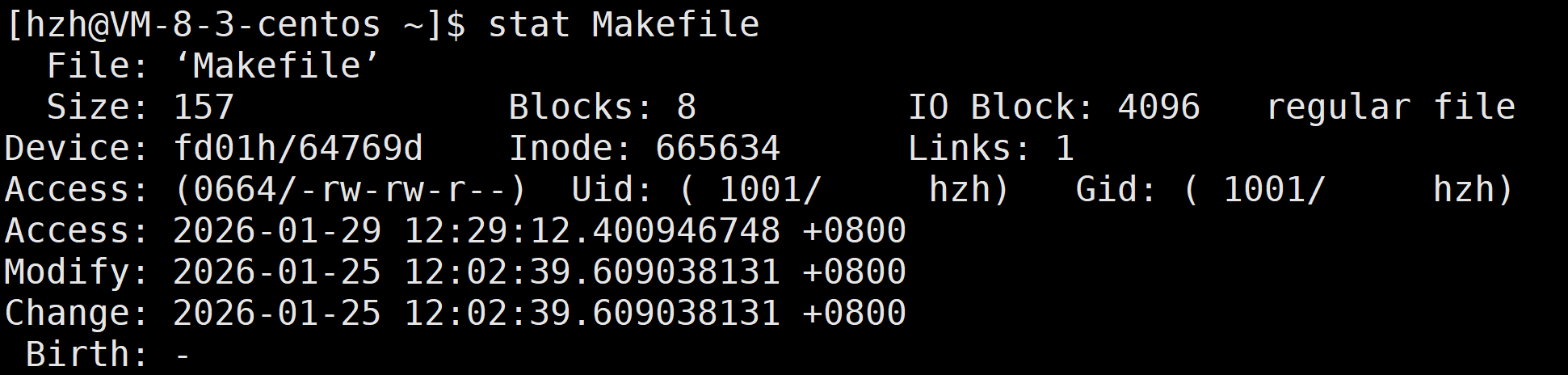
因为文件都是存储在块中的,每个文件的属信息也是如此。Linux文件的属性和内容是分开存储的,保存文件属性的集合叫做inode,一个文件,一个inode形成映射关系。inode内有一个唯一的标识符,叫做inode号。
值得注意的是,文件名这一属性并没有纳入到inode数据结构中,而是存放在路径下。inode数据结构一般大小为128字节或256字节,不同文件之间的存储内容大小可能不同但文件的属性大小一定相同。
三、ext2文件系统
文件要存储在磁盘上时,需要先在磁盘上格式化为某种文件系统,这样才能存储文件。而ext2文件系统就是Linux上的经典文件系统。
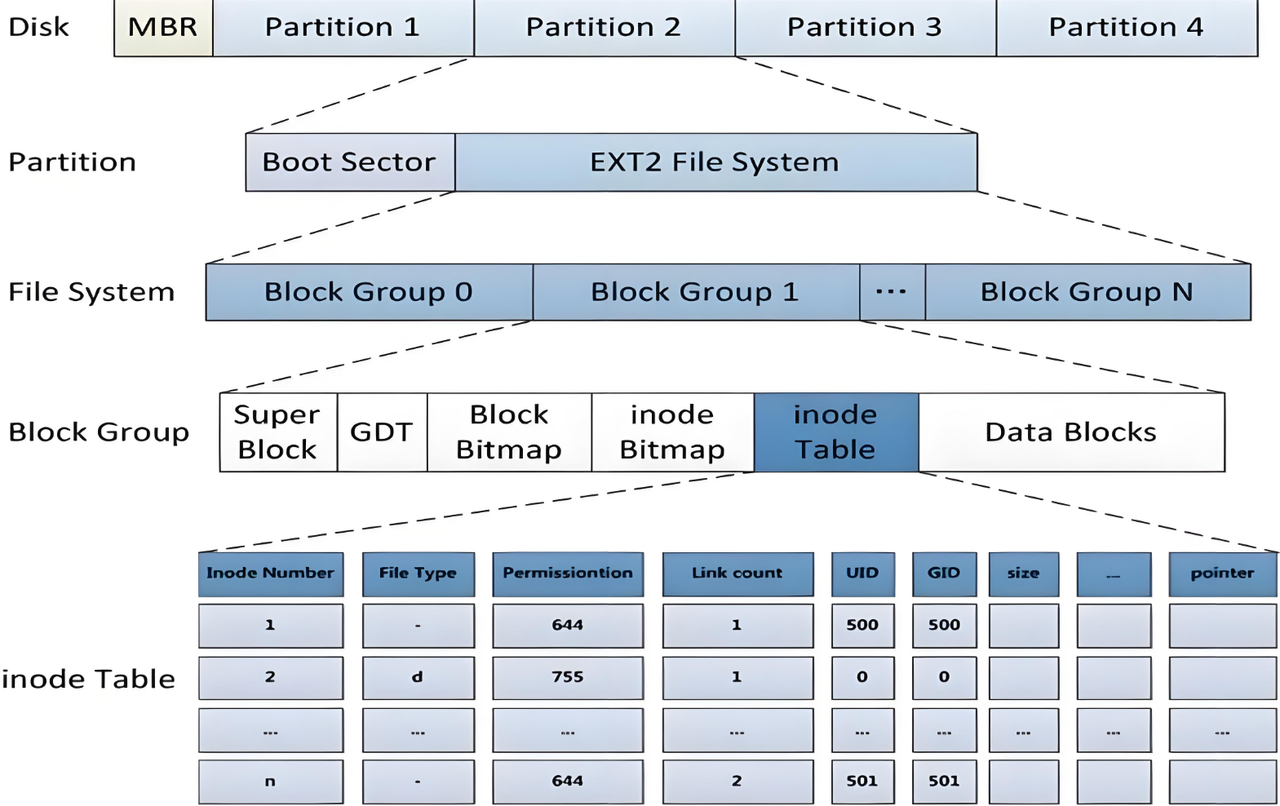
如上图所示,ext2文件系统将磁盘各分区划分成一个个块组
超级块(Super Block)
超级块中存储的是整个文件系统的全局元数据,包括总块数、inode 总数、块大小、inode 大小、文件系统版本、挂载时间、最后检查时间、空闲块数 / 空闲 inode 数等核心信息。超级块是文件系统的 "总控信息库",对文件系统的完整性至关重要;为防止单点故障,除块组 0 存储主超级块外,还会在多个关键块组(如 1、3、7、15 等)中保存备份拷贝,便于文件系统损坏后的恢复。
块组描述符表(GDT)
块组描述符表用于逐一描述每个块组的关键信息,包括该块组的块位图、inode 位图、inode 表的磁盘起始块号,以及块组内空闲块数、空闲 inode 数、已用目录项数等状态信息。整个分区中有多少个块组,就对应多少个块组描述符;这些描述符连续排列组成 GDT,且 GDT 会随超级块一同在多个块组中备份,确保块组信息可恢复。
块位图(Block Bitmap)
块位图是每个块组专属的元数据,以二进制位为最小单位,每一位对应数据区中的一个文件系统块:位为 1 表示该块已被占用(存储数据),位为 0 表示该块空闲可分配。块位图通常占用 1 个文件系统块,系统可通过扫描块位图快速找到空闲数据块,是数据块高效分配 / 回收的核心依据。
inode 位图(Inode Bitmap)
inode 位图是每个块组专属的元数据,为一整块连续的字节(通常占 1 个文件系统块,如 4KB);其中每一个二进制位对应块组内的一个 inode:位为 1 表示该 inode 已被文件 / 目录占用,位为 0 表示该 inode 空闲可分配。系统通过 inode 位图可快速定位空闲 inode,完成文件创建时的 inode 分配。
i 节点表(Inode Table)
i 节点表是每个块组的核心元数据区域,存放该块组内所有 inode 的完整属性,包括文件大小、所有者 UID / 所属组 GID、文件权限、访问时间 / 修改时间 / 属性修改时间、数据块指针、硬链接数等。i 节点表是当前块组所有 inode 属性的集合;inode 编号以 "整个分区" 为单位从 1 开始全局连续划分(0 号 inode 保留),不同块组的 inode 编号无重叠,且绝对不可跨分区。
数据区(Data Block)
数据区(Data Block)是每个块组中用于存放文件实际数据内容的区域,如文本、图片、视频、程序代码等,也是文件系统中占用空间最大的存储区域;数据区以文件系统块为最小分配单位(常见大小为 4KB),即使文件仅 1 字节,也会占用 1 个完整块。数据区中每个块的空闲与已使用状态由块位图(Block Bitmap)进行标记;普通文件的数据区存储实际内容,目录文件的数据区则存储其下所有文件的 "文件名 - 对应 inode 编号" 映射关系;数据块分配以块组为单位管理,系统优先在文件所属 inode 所在的块组内分配数据块,减少磁盘寻道开销。
全局分配特性
在同一个分区内部的 Ext 文件系统中,inode 总数、数据块总数在文件系统格式化阶段就已固定,是提前规划设计好的,不会随文件的创建、删除等操作动态增减。
inode 编号和数据块编号均以整个分区为单位全局有效,而非仅在所属块组内有效。
数据区作为存储文件实际数据的核心区域,其空间范围是整个分区级别的全局有效,块组只是文件系统为提升管理效率划分的逻辑单元,不改变数据区的全局属性。
在ext2角度看待文件增删查改
增删
对于新建文件而言,系统会先在 inode 位图中查找空闲 inode 并分配,将其标记为已使用;接着初始化(也可以称为格式化)该 inode 的文件属性(大小、所有者、修改时间等),再通过块位图分配空闲数据块,将文件实际数据存入数据区;最后在所属目录中记录文件名与对应 inode 编号的映射关系,完成文件创建。
如果要删除文件,只需清除目录中该文件的文件名 - inode 映射,将文件对应的 inode 在 inode 位图中标记为空闲(即注销 inode),同时通过块位图回收文件占用的数据块,被释放的 inode 与数据块空间即可被后续文件重新使用。
查改
在 Linux 上使用指令时可直接用指令名而无需带路径,是因为环境变量保存了指令的搜索路径;我们访问文件时常只需使用文件名,核心原因是目录会存储其下所有文件的文件名--inode 编号映射关系。
查询文件时,系统通过文件名找到对应 inode,再从 inode 中读取文件属性、定位数据块位置,进而获取文件实际数据;修改文件时,若修改内容则更新数据区数据,并同步修改 inode 内的文件大小、修改时间等属性,若修改权限、所有者等属性,则直接更新对应 inode 中的相关字段即可。
inode和datablock映射
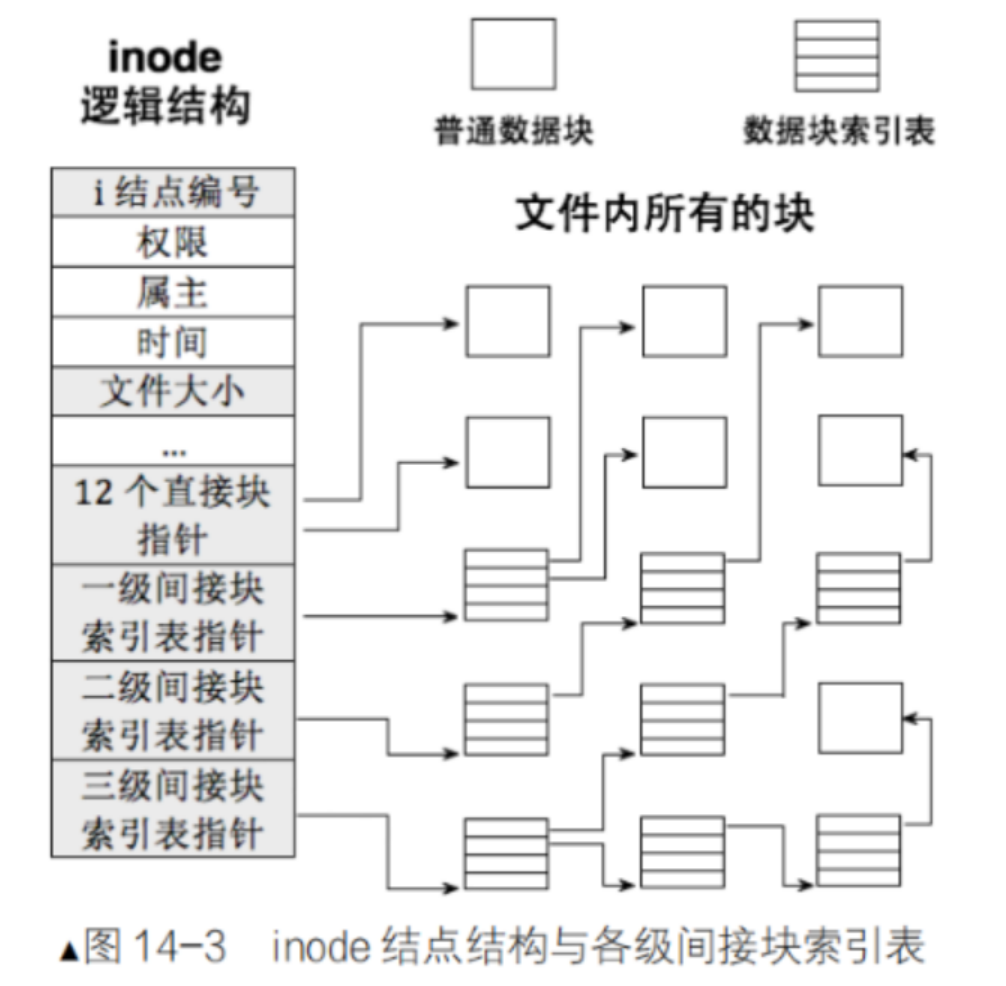
如上图所示,inode节点中存在一、二、三级间接块索引表指针和12个直接块指针。当datablock中存储的内容比较小时,可直接使用12个直接块指针指向一个块来存储数据。
当数据较大时则可以使用一、二、三级间接块索引表指针,一级间接块索引表指针中有4个块,每个块分别指向另一个块用于存储数据。
二级间接块索引表指针同样指向是4个块,但每个块指向一级间接块索引表指针。三级间接块索引表指针也指向4个块,但这4个块分别指向二级间接块索引表指针。
各级间接块索引表指向的大小
| 指针类型 | 可寻址数据块数 | 可寻址空间 | 总容量 |
|---|---|---|---|
| 直接指针 | 12 | 48KB | 48KB |
| 一级间接 | 1024(32位下指针为4字节) | 4MB | 4MB+48KB |
| 二级间接 | 1024² = 1,048,576 | 4GB | 4GB+4MB+48KB |
| 三级间接 | 1024³ = 1,073,741,824 | 4TB | 4TB+4GB+4MB+48KB |
所以一般而言不用担心文件太大存不下的情况(当然磁盘空间要富裕)。
文件与目录名
Linux下目录也是文件的一种。
既然我们进行文件操作的时候需要对应的inode编号,那为什么我们使用文件名就可以进行文件操作,这是因为目录文件保存的内容是目录下的文件名+inode映射关系。
所以说要进行文件操作,必须打开对应目录。
路径缓存
严格来说,Linux下不存在专门的目录,Linux下一切皆文件,文件=内容+属性。
如果要进行一个文件操作,原则上必须从根目录开始依次向下找到文件,但这样太慢,所以Linux中有一个数据结构struct dentry 专门用来维护树状路径结构。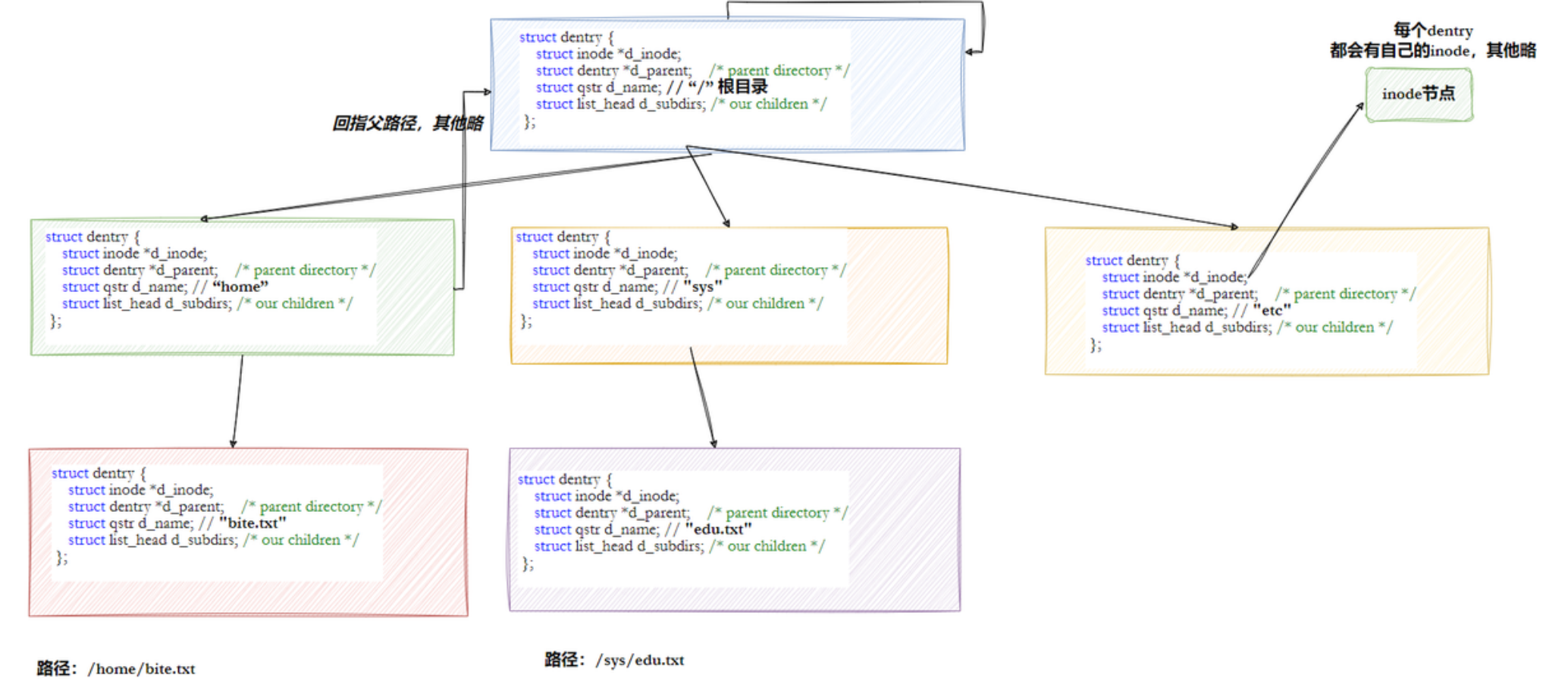
每个文件都包含一个denty,denty树状结构整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
格式化与挂载
格式化是在磁盘分区上创建文件系统的元数据结构如inode表,经过格式化后的文件系统是不能直接使用的,还需要挂载。
所谓挂载就是把一个文件系统(分区)关联到文件系统树中的某个目录,这样才能进行文件操作。
格式化=创建一个仓库,挂载=在仓库上安装门。