win10系统下使用conda环境部署YOLOv8
1. conda下载参考网上链接:
一步步教你在 Windows 上轻松安装 Anaconda以及使用常用conda命令(超详细)_windows anaconda-CSDN博客
使用anaconda部署YOLOv8超详细小白教程_anaconda yolov8-CSDN博客
2. win10安装 cuda 、cudnn参考链接:Win10系统安装CUDA、cuDNN、Python、PyTorch、torchvision、opencv环境,用于YOLO系列模型格式转换记录_fmql yolo-CSDN博客
3. 部署YOLOv8虚拟环境
3.1 管理员身份启动win终端,创建conda环境
shell
# 创建虚拟环境
conda create -n yolov8 python=3.8 -y
# 激活虚拟环境
conda activate yolov8
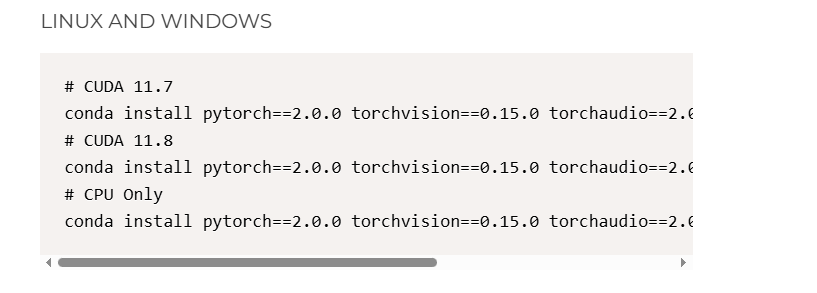
# 安装cuda11.7对应的torch、torchvision、torchaudio
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
#安装完,测试 pytorch是否安装成功,虚拟环境(yolov8)下进入python
python
import torch
import torchvision
print(torch.cuda.is_available()) ## 依次输入完,会显示 True。安装成功参考pytorch官方链接:PyTorch
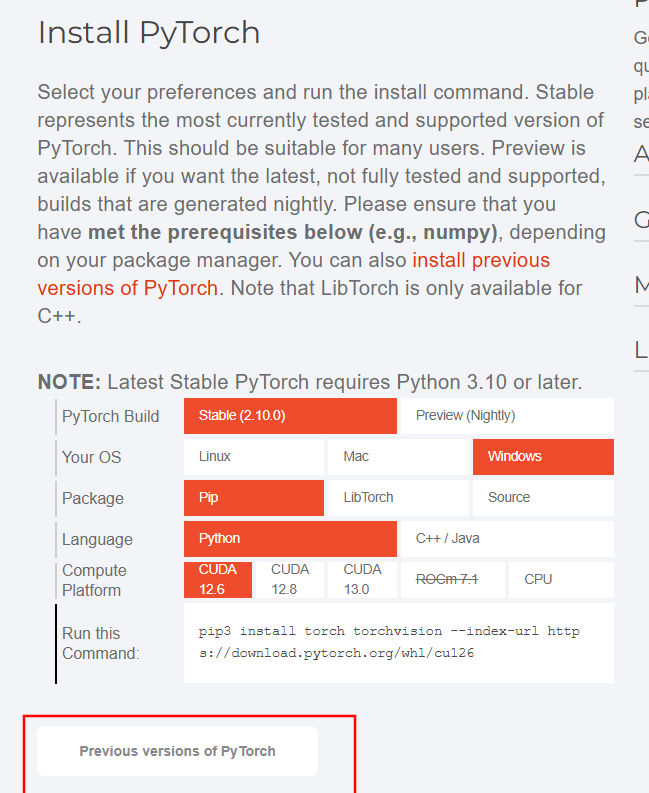
3.2 conda环境下安装ultralytics环境
shell
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ultralytics部署完成后,下载ultralytics源码,将ultralytics放在工作空间中:ultralytics/ultralytics: Ultralytics YOLO 🚀,进入ultralytics-main/路径下,测试,yolov8源码:GitHub - Pertical/YOLOv8: YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
shell
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg" ## 会下载pt模型文件,也可自行下载,提前放置在源码路径,推理完成后结果放在ultralytics-main\runs\detect路径下3.3 conda环境下mp4视频推理测试
ultralytics-main\路径下创建yolov8_video_inference.py,测试本地mp4视频文件或USB摄像头数据,实时显示播放识别结果和保存本地mp4
python
import cv2
from ultralytics import YOLO
import os
import argparse
def process_video(input_video, model_path, output_video, imgsz=1024, show=True, save=True):
"""
使用 YOLOv8 模型处理视频
参数:
input_video: 输入 MP4 视频路径
model_path: 自定义 YOLOv8 模型权重路径 (.pt 文件)
output_video: 输出结果视频路径
imgsz: 模型输入尺寸 (默认 1024)
show: 是否实时显示检测画面
save: 是否保存结果视频
"""
# 检查输入文件是否存在
if not os.path.exists(input_video):
raise FileNotFoundError(f"输入视频不存在: {input_video}")
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型文件不存在: {model_path}")
# 创建输出目录
output_dir = os.path.dirname(output_video)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
# 加载自定义 YOLOv8 模型
print(f"Loading model from {model_path} with imgsz={imgsz}...")
model = YOLO(model_path)
# 打开视频文件
cap = cv2.VideoCapture(input_video)
if not cap.isOpened():
raise IOError(f"无法打开视频文件: {input_video}")
# 获取视频属性
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"视频信息: {width}x{height}, {fps:.2f} FPS, 共 {total_frames} 帧")
# 初始化视频写入器(保存带标注的视频)
if save:
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 或使用 'XVID' / 'H264'
out = cv2.VideoWriter(output_video, fourcc, fps, (width, height))
if not out.isOpened():
raise IOError(f"无法创建输出视频文件: {output_video}")
print(f"结果视频将保存至: {output_video}")
frame_count = 0
print("开始处理视频... 按 'q' 键可提前退出")
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_count += 1
# 使用 YOLOv8 进行推理(设置 imgsz=1024)
results = model(frame, imgsz=imgsz, verbose=False)
# 绘制检测结果
annotated_frame = results[0].plot() # 自动绘制边界框和标签
# 显示处理进度
if frame_count % 30 == 0: # 每30帧打印一次
print(f"已处理 {frame_count}/{total_frames} 帧 ({frame_count/total_frames*100:.1f}%)")
# 显示画面
if show:
cv2.imshow('YOLOv8 Detection', annotated_frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
print("用户中断处理")
break
# 保存结果帧
if save:
out.write(annotated_frame)
# 释放资源
cap.release()
if save:
out.release()
if show:
cv2.destroyAllWindows()
print(f"\n✓ 处理完成! 共处理 {frame_count} 帧")
if save:
print(f"结果视频已保存: {output_video}")
if __name__ == "__main__":
# 命令行参数解析(方便灵活调用)
parser = argparse.ArgumentParser(description='YOLOv8 视频目标检测')
parser.add_argument('--input', type=str, required=True, help='输入 MP4 视频路径')
parser.add_argument('--model', type=str, required=True, help='自定义模型权重路径 (.pt)')
parser.add_argument('--output', type=str, default='output/result.mp4', help='输出视频路径')
parser.add_argument('--imgsz', type=int, default=1024, help='模型输入尺寸 (默认 1024)')
parser.add_argument('--noshow', action='store_true', help='不显示实时画面')
parser.add_argument('--nosave', action='store_true', help='不保存结果视频')
args = parser.parse_args()
# 执行视频处理
process_video(
input_video=args.input,
model_path=args.model,
output_video=args.output,
imgsz=args.imgsz,
show=not args.noshow,
save=not args.nosave
)运行
shell
python yolov8_video_inference.py --input ./a.mp4 --model ./yolov8n.pt --output ./detected_video.mp4 --imgsz 640