一、Self-Forcing:从 Wan2.1 到因果视频推理
Wan2.1:全帧并行的视频扩散模型
Wan2.1 是阿里巴巴团队开源的大规模视频生成基础模型,基于主流的扩散 Transformer(DiT)架构,并采用 Flow Matching 作为训练框架,在多个视频生成评测基准上展现了领先的生成质量。
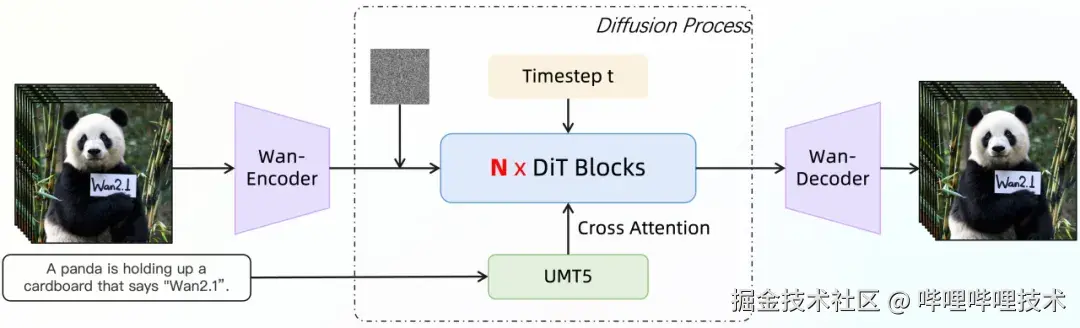
在模型设计上,Wan2.1 采用典型的全时空并行建模思路。模型使用 Full Spatio-temporal Attention,使得所有视频帧在时间和空间维度上完全互相可见,从而实现双向的信息流动与全局一致性建模。视频首先通过 3D Causal VAE 被压缩到 4×8×8 的时空比例,latent 维度为 16,文本侧则使用 umT5 编码器,将中英文输入映射为 512 tokens、4096 维的语义表示,并通过 Cross-Attention 注入到生成过程中。
从规模上看,Wan2.1 同时提供了面向效率和质量的不同版本:1.3B 模型采用 1536 维隐藏层、30 层 Transformer 和 12 个注意力头,更适合资源受限场景,14B 模型则扩展到 5120 维隐藏层、40 层 Transformer 和 40 个注意力头,以追求更高的生成上限。
在推理阶段,Wan2.1 会一次性处理所有视频帧,通过 40--50 步去噪迭代生成完整视频。这种全帧并行的生成方式在中短视频场景中能够有效保证时序一致性,但其设计假设也直接决定了模型在更长视频和实时推理场景下会遇到不可回避的瓶颈。
全局扩散模型在长视频推理中的瓶颈
随着视频长度的增加,基于双向全注意力的扩散模型逐渐暴露出结构性问题。首先是显存和计算复杂度的快速膨胀。自注意力的复杂度为 O(N²),其中 N 为 token 序列长度。以 Wan2.1 生成 5 秒、16 FPS、832×480 分辨率视频为例,经过 VAE 压缩后仍然会形成约 3 万级别的 token 序列,当视频长度翻倍时,注意力相关的显存需求将增长至原来的四倍,这使得单卡生成更长视频变得困难。
其次,全局并行注意力隐含了固定长度假设。由于所有帧必须同时参与计算,模型在训练阶段通常就需要设定最大帧数,当推理阶段希望生成更长的视频时,只能通过滑动窗口或分段拼接来变通处理,而这往往会带来明显的时间接缝和长程一致性退化,模型本身并不具备自然向更长时间轴扩展的能力。
更重要的是,这种双向依赖的建模方式使得模型无法进行流式推理。由于当前帧的生成会受到未来帧的反向影响,系统必须等待整个视频生成完成后才能输出结果,首帧延迟往往达到数十秒甚至更长。这种"离线式"的推理模式显然无法满足实时交互、在线生成或视频续写等应用需求。
这些问题并非简单的工程优化可以解决,而是源自全局扩散模型在时间建模上的基本假设。
Self-Forcing:用因果生成重构视频扩散推理
Self-Forcing 提出了一种因果自回归的视频扩散训练与推理方式,其核心思想是将 Wan2.1 这类全帧并行模型,改造为只依赖历史信息的逐步生成模型,同时避免传统自回归模型中常见的误差累积问题。
在模型结构上,Self-Forcing 引入因果注意力约束,使当前帧只能关注历史帧而无法"看到"未来信息。这一约束通过 Block Mask 施加在注意力计算中,并配合 Flex Attention 实现高效计算。由于满足因果性,模型在推理时可以安全地复用历史帧的 Key / Value,从而引入 KV 缓存机制,避免在每一步生成中重复计算已经确定的上下文。
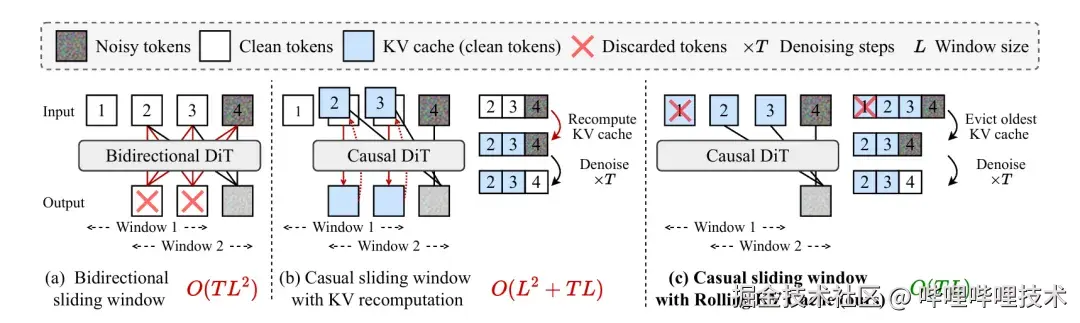
在此基础上,Self-Forcing 采用逐块生成策略,将视频按帧或按小段 latent 分块生成。每一块完成去噪后,其结果会被写入 KV 缓存,作为后续生成的上下文;当缓存达到上限时,通过 Rolling KV Cache 自动淘汰最早的 tokens,从而在有限显存下支持任意长度的视频生成。这种设计将注意力的峰值复杂度从 O(N²) 降低到 O(B×N),其中 B 为单次生成的块大小。
从工程实现上看,Self-Forcing 使用 CausalWanModel 替代原始 WanModel,并在注意力层中系统性地引入因果掩码、KV 缓存以及编译级优化。在保持训练与推理一致性的前提下,模型在生成质量上与 Wan2.1 基本持平,VBench 指标甚至略有提升,同时将首帧延迟降低到亚秒级,并在单卡 H100 上实现了接近实时的视频生成速度。
总体而言,Self-Forcing 并不是对 Wan2.1 的局部加速,而是一次从全局扩散范式向因果推理范式的结构性转变,为长视频生成、流式推理和实时交互提供了可行的技术路径。
二、推理优化工作详解
序列并行实现
官方的 Self-Forcing 实现并未支持序列并行(Sequence Parallelism, SP),这在单卡显存受限、尤其是长视频推理场景下,成为扩展模型能力的主要瓶颈。为了解决这一问题,我们的算法团队在 Self-Forcing 因果注意力的基础上,参考 Megatron 以及 Ulysses 的设计,引入了对 SP 的完整支持。
在 SP 模式下,序列维度被均匀切分到多个并行 rank 上,每个 rank 仅持有长度为 L/P 的局部序列。整体的计算流程如下所示:

在实际的性能分析中,我们注意到两个关键问题:一方面,RoPE 在整个自注意力模块的计算中占据了显著的时间比例;另一方面,现有 Causal RoPE 的实现需要完整序列信息,其计算依赖于前面的三次 all-gather 通信,导致 RoPE 无法与通信阶段重叠执行,从而进一步放大了通信带来的性能损耗。
在 Self-Forcing 的分块自回归生成中,时间位置需要通过全局偏移来编码,这使得 RoPE 的计算逻辑相比传统实现有所不同。为了保证 KV Cache 与因果注意力的一致性,我们需要在序列分片内部正确应用全局时间索引,实现 Causal-RoPE 的局部化计算。
分块自回归下的旋转位置编码
Wan2.1 使用的 3D Rotary Positional Encoding 与 Qwen2.5-VL 中的多模态 RoPE(M-RoPE)在设计上是一致的:将旋转频率在维度上拆分为时间(temporal)、高度(height)和宽度(width)三部分,从而对视频 token 的三维空间位置进行编码。
在具体实现上,Qwen2.5-VL 采用传统的 cos/sin 形式,并通过 rotate_half 实现旋转:
arduino
q_embed = (q * cos) + (rotate_half(q) * sin)而 Wan2.1 则直接使用复数形式来表达旋转操作,将 RoPE 显式建模为复平面上的乘法:
scss
# freqs 在 rope_params 中已通过 torch.polar 转换为复数
freqs = freqs.split([c - 2 * (c // 3), c // 3, c // 3], dim=1)
x_i = torch.view_as_complex(x[i, :seq_len].to(torch.float64).reshape(
seq_len, n, -1, 2))
freqs_i = torch.cat([
freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
], dim=-1)
x_i = torch.view_as_real(x_i * freqs_i).flatten(2)这种实现方式更贴近 RoPE 的数学本质,其核心等价关系可以写为:
RoPE(x,θ)=x⋅eiθ=x⋅(cosθ+isinθ)
在 Self-Forcing 框架下,为了支持分块因果推理与 KV Cache,引入了额外的
start_frame 参数,用于显式指定当前生成块在全局时间轴上的起始位置:
scss
def causal_rope_apply(x, grid_sizes, freqs, start_frame=0):
freqs_i = torch.cat([
freqs[0][start_frame:start_frame + f].view(f, 1, 1, -1).expand(f, h, w, -1),
freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
], dim=-1)通过这一改动,3D RoPE 被自然地扩展为适用于分块自回归生成的因果形式。对于时间--空间位置为 (t,h,w) 的 token,其位置编码可以形式化表示为:
Causal-RoPE(xt,h,w)=xt,h,w⊙ei(tglobalθT+hθH+wθW)
其中,全局时间索引定义为:
tglobal=t+s,s=kτ
这里 k 为块索引, τ 为块大小。以 chunk-wise(每块 3 个 latent 帧)为例,不同生成块对应的 start_frame 分别为 0、3、6 ...,依此类推。
如果仅使用局部时间索引,不同块中处于相同相对位置的 token 将获得完全相同的位置编码,从而导致全局时间顺序混淆,并使 KV Cache 中的位置信息失真。通过显式引入全局时间偏移,Causal-RoPE 保证了位置编码与自回归生成顺序之间的一一对应关系。
局部计算的可行性
在序列并行设置下,序列维度被划分到 ∣R∣ 个并行 rank 上。对于 rank r ,其负责的序列区间为 [r⋅L,(r+1)⋅L) ,其中 L=⌈S/∣R∣⌉ 。
由于 token 在序列中按照"帧优先"的顺序排列,序列切分在效果上等价于对时间维度的近似划分。对于 rank r 中局部索引为 ilocal 的 token,其对应的全局序列位置和全局时间索引分别为:
iglobal=r⋅L+ilocal
tglobal=s+⌊H×Wiglobal⌋
其中 s 为当前块的 start_frame。
可以看到,对每个 token,Causal-RoPE 的计算仅依赖其自身特征、全局时间位置以及共享的频率参数 θT,θH,θW 。在分块自回归 + SP 的组合下,我们通过在每个 rank 内应用正确的全局时间索引,实现了 RoPE 的完全局部计算,无需额外跨 rank 通信,同时保持了因果一致性。
这一结论为后续的优化提供了理论基础。
实现方案与性能对比
基于上述分析,我们将 RoPE 的计算下沉到序列分片内部,先在本地完成 Causal-RoPE 的计算,再通过一次融合的 all-to-all 通信,同时完成序列维度与注意力头维度的重排,从而替代原始实现中的三次 all-gather 和一次 split 操作:

在第一阶段优化中,我们进一步缓存 RoPE 所需的 sin/cos,并基于 TileLang 实现算子融合,相比社区常见的 Triton 实现获得了约 10% 的性能提升,整体优化方案的 profile 结果如下所示:
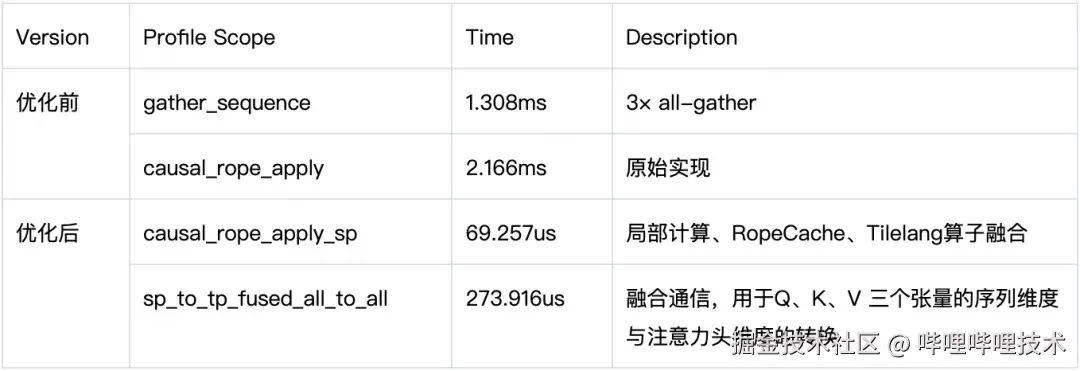
在一次典型的 5s 480P 视频推理中,会触发 920 次的自注意力计算,整体耗时降低约:
ΔTe2e=920×(1.308+2.166)−(0.069257+0.273916)ms≈2.88s
相比优化前 8.86s 的端到端耗时,整体推理性能实现 约 1.48× 无损加速(≈47.5% speedup),与实际的实验结果高度一致。后续我们在做计算图优化的时候,注意到 RoPE 的缓存逻辑对整图优化不友好,进一步将动态的缓存逻辑改成了预计算逻辑,并将结果存储在连续张量中,绕过 Host Op,在推理过程中直接在 GPU 上进行寻址,使用预计算的 cos / sin 对输入张量进行旋转编码计算,优化了 CUDA 的计算流,实现了计算性能的进一步提升。
三、总结与展望
本文分享了我们在视频生成模型推理优化中的一系列实践,重点围绕分块自回归视频模型在序列并行场景下的计算与通信优化展开。除上述工作外,我们还在低比特量化、计算图优化等方向持续探索,为后续更大规模、更低延迟的视频生成系统打下基础。
-End-
作者丨storyicon、在喝可乐的派派