前言
上面那篇文章我们提到了线程和锁的一些概念,但是代码有些冗余,比如需要我手动执行start,手动执行join,子线程数量少还好,如果多起来的话,就会显得代码很呆,因此引出下一个概念-->线程池(ThreadPoolExecutor)
线程池-submit版本
示例代码
python
from concurrent.futures import ThreadPoolExecutor
from threading import Thread, Lock
import time
total_money = 200
l = Lock()
def speed_money(name: str, sp_money: int):
time.sleep(1)
with l:
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
time.sleep(1) # 只是增加了这步
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
with ThreadPoolExecutor() as executor:
e1 = executor.submit(speed_money, "第一个线程", 100)
e2 = executor.submit(speed_money, "第二个线程", 100)
e3 = executor.submit(speed_money, "第三个线程", 100)
print("\ne1,e2,e3都submit了~~~~~")
print("\n开始依次获取执行结果")
print(e1.result())
print(e2.result())
print(e3.result())
print("\ne1,e2,e3都result完了,")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))执行结果

我们可以看到 在submit的时候,3个子线程就依次启动了,并且是没有阻塞主线程的,然后在子线程获取result的发现主线程是又被阻塞的 因此得出
结论
- 线程池submit和线程Thread的start很像(ps都是启动子线程,并且不会阻塞主线程)
- 线程池result和线程Thread的join很像(ps都是阻塞主线程,直到子线程执行完)
- 不同点是result是会获取子线程的结果的,但是join不行
线程池-map版本
示例代码
python
from concurrent.futures import ThreadPoolExecutor
from threading import Thread, Lock
import time
total_money = 200
l = Lock()
def speed_money(name: str, sp_money: int):
time.sleep(1)
with l:
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
time.sleep(1) # 只是增加了这步
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
with ThreadPoolExecutor() as executor:
results = executor.map(
speed_money,
["第一个线程", "第二个线程", "第三个线程"], # speed_money接受的传入第一个参数的可迭代对象
[100, 100, 100] # speed_money接受的传入第二个参数的可迭代对象
)
print("\ne1,e2,e3开始map了~~~~~")
print("\n开始依次获取执行结果")
for result in results:
print("\n result", result)
print("\ne1,e2,e3都map完了,")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))执行结果
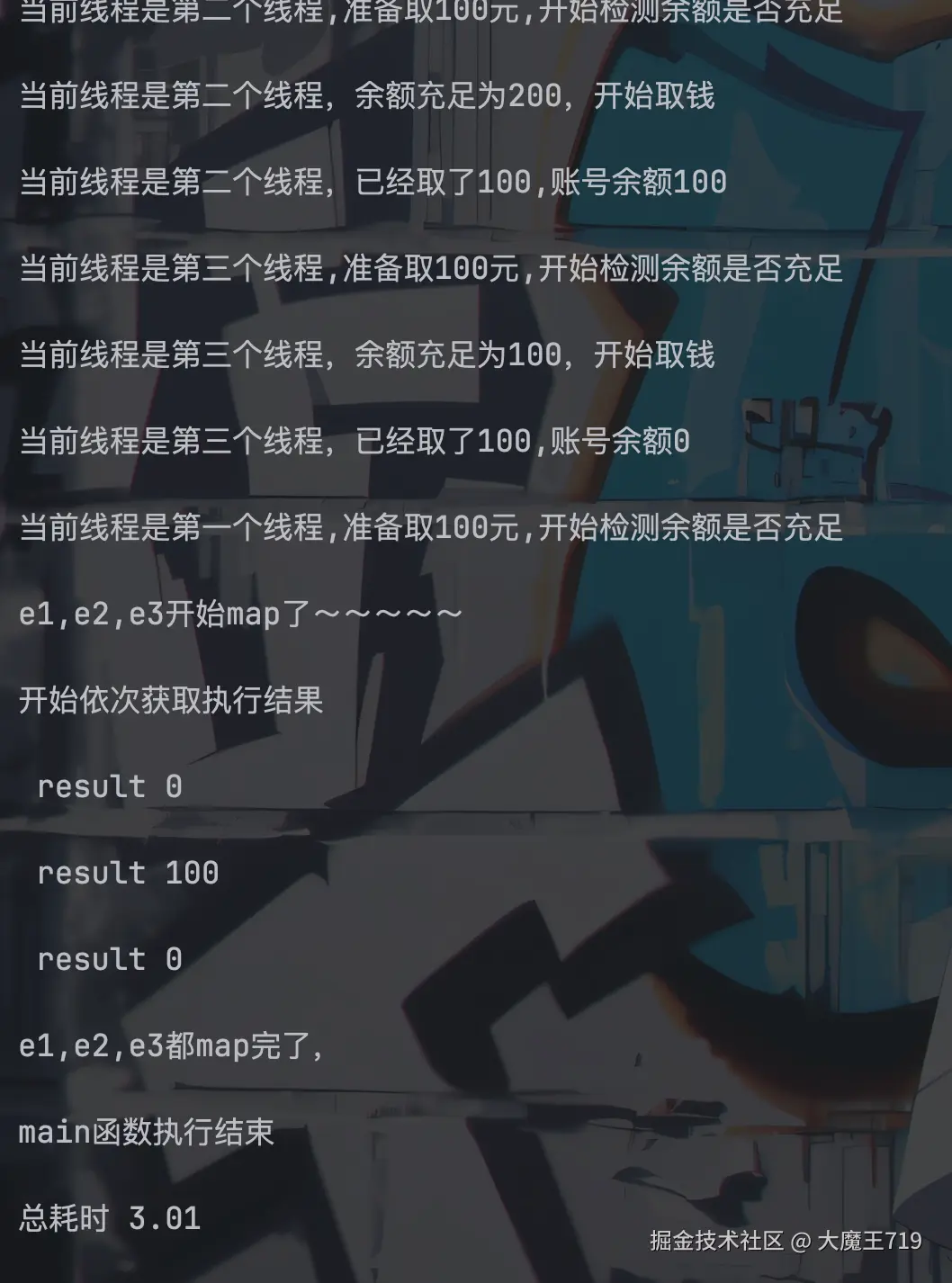
通过结果可以发现,基本上和submit打印的都是一样的,所以说数据也是没问题的,但是相较于submit的话,map就很通用了,使用方式和普通的map保持一致,也是在map的时候子线程就会执行,执行完得到的是一个可迭代对象,需要使用for或者next来获取子线程的返回值
map和submit的区别
