MiniMax在春节假期前发布了MiniMax M2.5新版本,官方表示该模型经过数十万个真实复杂环境中的大规模强化学习训练,在编程、工具调用和搜索、办公等生产力场景达到了行业前沿水平。我们对MiniMax M2.5与上一代MiniMax M2.1进行了全面的中文场景对比评测,测试其在准确率、响应时间、token消耗和成本等关键指标上的表现差异。
需要说明的是,本次评测侧重中文综合能力场景,涵盖教育、医疗、金融、法律、推理与数学计算、语言与指令遵从、Agent工具调用等维度。而MiniMax官方重点强调的编程、复杂搜索和办公等Agentic场景能力,受限于本次评测体系的覆盖范围,可能未能充分体现其真实优势。对于有相关需求的用户,建议参考官方评测数据或实际体验产品。
MiniMax M2.5版本表现:
- 测试题数:约1.5万
- 总分(准确率):65.7%
- 平均耗时(每次调用):53s
- 平均token(每次调用消耗的token):3307
- 平均花费(每千次调用的人民币花费):26.3
1、新旧版本对比
首先对比上个版本(MiniMax-M2.1),数据如下:

 *数据来源:非线智能ReLE评测github.com/jeinlee1991...
*数据来源:非线智能ReLE评测github.com/jeinlee1991...
*输出价格单位: 元/百万token
- 整体性能稳步提升:新版本准确率从63.6%提升至65.7%,增幅2.1个百分点,排名从第57位跃升至第41位,提升了16个名次。
- 响应速度大幅优化:每次调用的平均耗时从111s缩短至53s,提升了约52%,用户体验明显改善。这与官方宣称的"比M2.1完成任务速度快37%"相呼应。
- Token效率小幅改善:每次调用平均消耗的token从3525降至3307,减少约6.2%,说明新版本在推理过程中的token利用效率有所优化。
- 成本略有下降:每千次调用的费用从28.1元降至26.3元,下降约6.4%,虽然幅度不大,但结合响应速度的大幅提升,整体成本效率比有所改善。
- 专业领域表现分化:从细分来看,新版本在多数领域都有提升,其中"医疗与心理健康"提升显著,从70.5%提升至73.7%(+3.2%);"法律与行政公务"从74.3%提升至77.0%(+2.7%);"教育"从40.0%提升至42.3%(+2.3%)。
- Agent能力显著增强:值得关注的是,"Agent与工具调用"能力从55.9%大幅提升至66.5%,增幅达10.6个百分点,这与官方强调的Agentic场景优化方向一致,也印证了模型在工具使用和任务拆解方面的进步。
- 部分领域有所回调:新版本在"金融"领域从76.7%下降至71.2%(-5.5%),"语言与指令遵从"也从62.5%下降至59.0%(-3.5%),表明在整体优化过程中存在一定的能力权衡。
2、对比其他模型
在当前主流大模型竞争格局中,MiniMax M2.5表现如何?我们从同成本档位、新旧版本迭代、开源与闭源三个维度进行横向对比分析(本评测侧重中文场景,模型在其他语言和专业领域的表现可能有所不同):
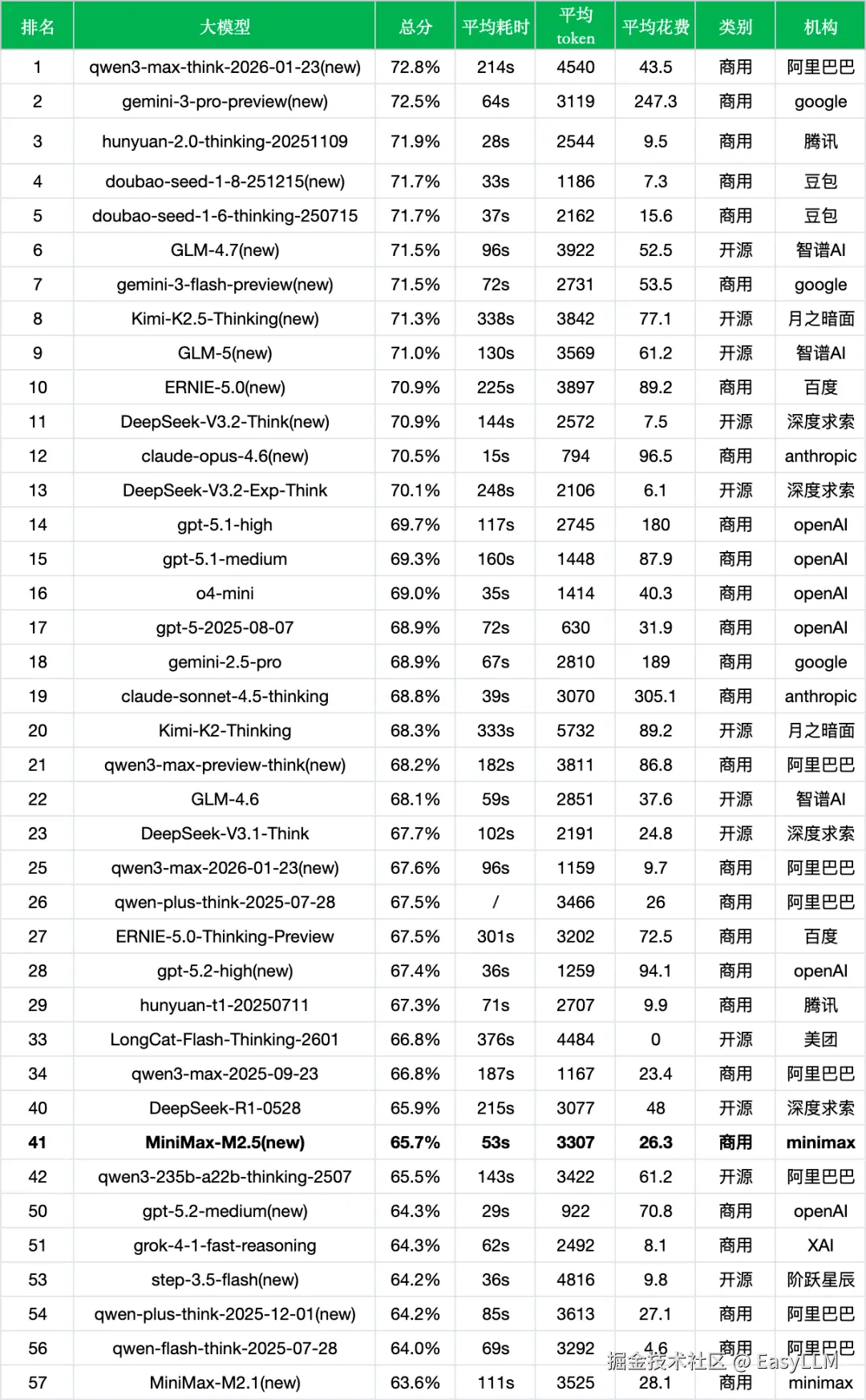
*数据来源:非线智能ReLE评测github.com/jeinlee1991...
同成本档位对比:
- 成本区间定位:MiniMax M2.5以26.3元/千次的成本处于中低成本区间。与成本相近的qwen3-235b-a22b-thinking-2507(61.2元)相比,MiniMax M2.5成本更低且准确率略高(65.7% vs 65.5%,几乎持平)。
- 成本效率比较好:对比同档位的其他模型,gpt-5.2-high(94.1元)准确率为67.4%,gpt-5-2025-08-07(31.9元)准确率为68.9%,MiniMax M2.5在成本控制方面具有一定优势。
- 速度优势明显:53s的响应时间在同档位模型中表现优异,明显快于qwen3-235b-a22b-thinking-2507(143s)、Kimi-K2-Thinking(333s)等模型。
新旧版本迭代对比:
- 版本升级成效显著:从MiniMax M2.1到MiniMax M2.5,排名从第57位提升至第41位,准确率提升2.1个百分点,响应速度提升52%,整体进步明显。
- 迭代速度行业领先:官方表示在过去108天内连续发布了M2、M2.1和M2.5三个版本,模型能力持续快速迭代,这一进步速度在行业中较为突出。
- 与同期新模型对比:相比其他近期发布的新版本,如doubao-seed-1-8-251215(71.7%)、GLM-4.7(71.5%)、ERNIE-5.0(70.9%),MiniMax M2.5的65.7%准确率存在一定差距,说明在中文综合能力维度仍有提升空间。
开源与闭源对比:
- 闭源模型定位:MiniMax M2.5作为商用闭源模型,与同为闭源的doubao-seed-1-8-251215(71.7%)、gemini-3-pro-preview(72.5%)相比,准确率存在5-7个百分点的差距。
- 开源模型竞争:对比开源模型如DeepSeek-V3.2-Think(70.9%)、DeepSeek-R1-0528(65.9%),MiniMax M2.5与后者水平相当,但成本(26.3元 vs 48元)更具优势。
- 独特优势领域:虽然在中文综合准确率上表现中等,但MiniMax M2.5在Agent工具调用(66.5%)方面表现突出,这一特点符合官方"为Agent时代而生"的产品定位。
3、官方评测
根据MiniMax官方(minimaxi.com/news/minima... M2.5在多项国际权威基准测试中取得了亮眼成绩:
编程能力:
在编程的核心测试中,M2.5 相比于上一代模型有了显著提升,达到了跟 Claude Opus 系列类似的水平。在多语言相关的任务 Multi-SWE-Bench 上,M2.5 更是达到了第一。
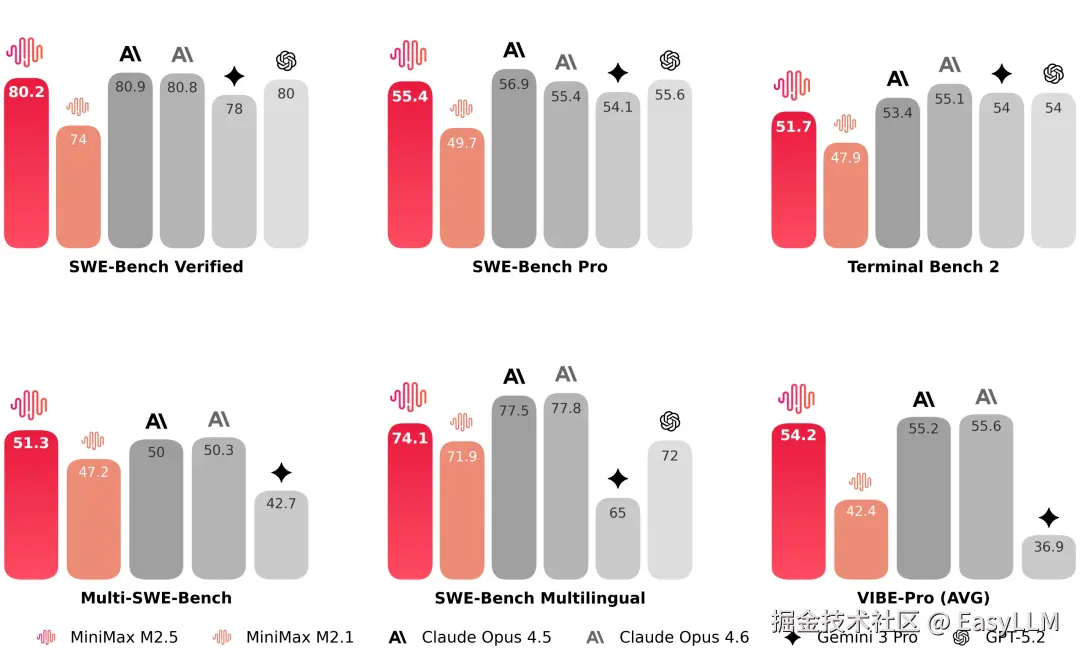
官方表示M2.5具备"像架构师一样思考和构建"的能力,模型演化出了原生Spec行为:在动手写代码前,以架构师视角主动拆解功能、结构和UI设计,实现完整的前期规划。
M2.5在超过10种编程语言(包括GO、C、C++、TS、Rust、Kotlin、Python、Java、JS、PHP、Lua、Dart、Ruby)和数十万个真实环境中进行了训练,能够胜任从0-1系统设计到90-100完备测试的全流程。
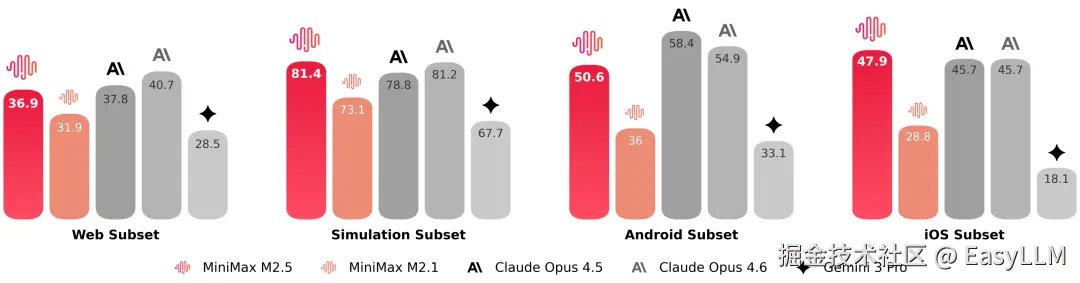
为了更精准地衡量这一能力,官方将 VIBE 基准升级为难度更高、更具挑战性的 Pro 版本,显著提升了任务复杂度、领域覆盖面及评估准确性。综合评测显示,M2.5 与 Opus 4.5 表现旗鼓相当。
搜索和工具调用:
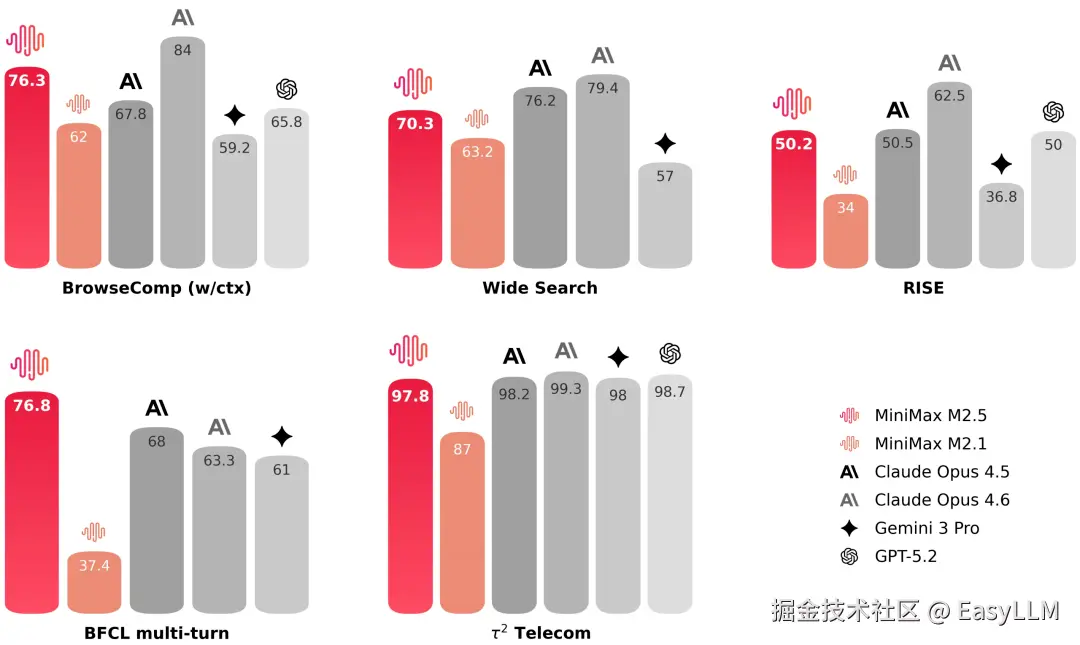
在 BrowseComp、Wide Search 等权威榜单中,M2.5 均达到了行业顶尖水平。同时,模型的泛化能力进一步增强,即便面对陌生的脚手架环境,表现依然稳定。
在专家级真实搜索任务中,使用搜索引擎往往只是第一步,更多工作在于对专业网页内容的深度挖掘。为此,官方构建了 RISE (Realistic Interactive Search Evaluation) 评测集,专门用于衡量模型在真实专业任务上的搜索与探索能力。结果证实,M2.5 在此类任务中表现卓越。
在 BrowseComp、Wide Search 及 RISE 等多项测试中,M2.5 均以更少的轮次消耗取得了更好的结果------相比 M2.1 节省了约 20% 的轮次。这说明模型不再仅仅是"做对"题目,而是找到了通往结果的最简路径。
办公场景:
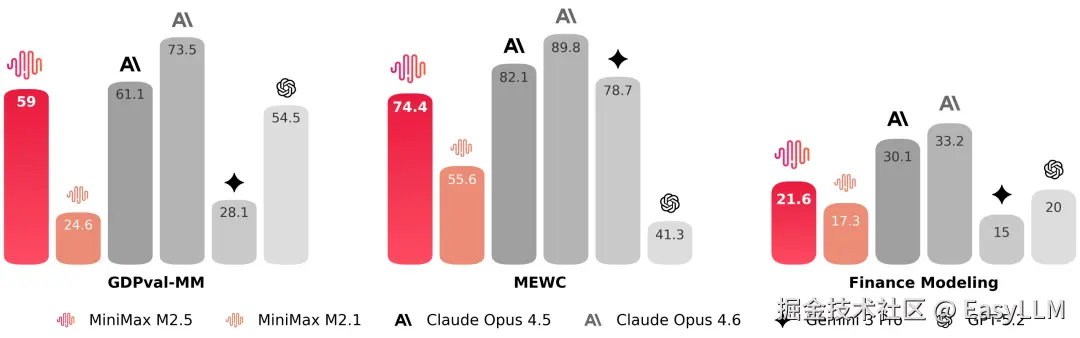
 官方与金融、法律、社会科学等领域的资深从业者合作,将行业隐性知识带入模型训练,在Word、PPT、Excel金融建模等办公高阶场景中取得显著能力提升。
官方与金融、法律、社会科学等领域的资深从业者合作,将行业隐性知识带入模型训练,在Word、PPT、Excel金融建模等办公高阶场景中取得显著能力提升。
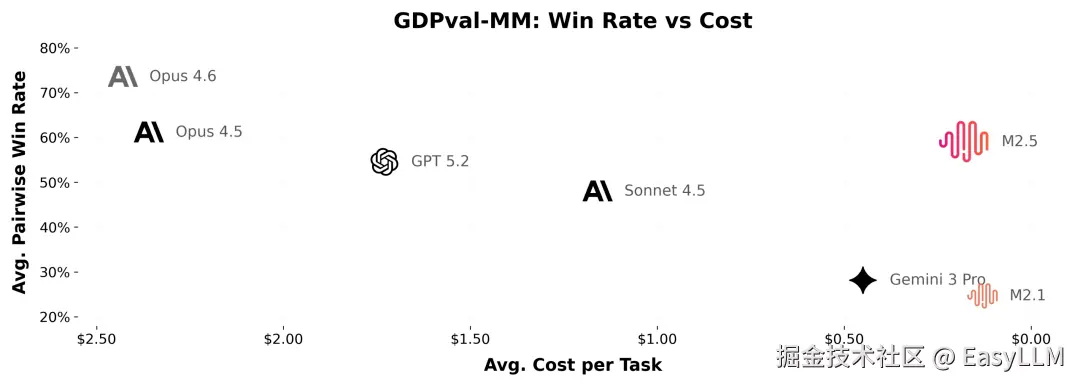
在内部GDPval-MM评测框架中,M2.5与主流模型对比取得了59.0%的平均胜率。
效率与成本:
- 在运行SWE-Bench Verified时,M2.5平均每个任务消耗3.52M token,相比M2.1的3.72M有所减少。端到端运行时间从平均31.3分钟减少到22.8分钟,速度提升37%,与Claude Opus 4.6的22.9分钟基本持平。
- 官方强调M2.5是"第一个不需要考虑使用成本可以无限使用的前沿模型"。在每秒输出100 token的情况下,连续工作一小时只需花费1美金;每秒输出50 token的情况下,只需要0.3美金。
目前所有大模型评测文章在公众号:大模型评测及优化NoneLinear