随着eBay持续作为跨境卖家选品、定价、竞品监控的核心数据源,越来越多团队开始尝试对eBay进行数据抓取,用于:动态定价、跟卖机会识别、类目趋势判断、供应链比价、季节性波动分析。
但很快会遇到一个问题:代码没问题,数据却抓不到,或者抓取几天就被封号。要想稳定抓取eBay商品数据,核心是构建一个足够接近真实买家的采集环境。
一、eBay价格分析需要抓取什么数据?
1. 商品核心数据
- **商品ID:**唯一标识,去重基准
- **标题:**关键词挖掘、类目映射
- **当前售价:**实时比价、调价依据
- **划线原价:**折扣力度分析
- **运费:**最终到手价测算
- **商品状态:**全新/二手,比价前提
2. 销量与卖家数据
- **月销量/历史销量:**价格-销量弹性分析
- **卖家ID:**竞品定价策略追踪
- **卖家评分:**信誉对溢价的影响
- **店铺类型:**企业店/个人店区分
3. 促销与价格衍生数据
- **优惠券:**真实成交价还原
- **多件折扣:**批量采购场景
- **价格历史走势:**动态定价决策
- **缺货/下架状态:**跟卖机会窗口
4. 辅助分析数据
- **上架时间:**新品识别
- **类目路径:**价格带分布
- **商品属性:**同款比价基准
注意:**不同数据采集难度不同。**详情页、历史销量、登录态字段风控等级最高;搜索列表页、公开类目页相对宽松。

二、eBay 抓取商品价格数据的3大工具
方法一:官方工具
1. eBay API
- 特点:零封号风险,数据结构化
- 可获取:商品ID、标题、当前价、运费、卖家名称、上架时间
- 无法获取:历史销量、价格走势、优惠券、缺货状态
- 适合:品牌卖家、合规优先、预算充足的企业
2. eBay Seller Hub
- 特点:内置市场分析工具,零技术门槛
- 可获取:类目平均售价、热销价格区间、历史成交趋势
- 无法获取:无法导出原始数据,不能追踪具体竞品
- 适合:个人卖家快速了解市场价格水位
用API换合规,用Seller Hub换便捷,但是字段受限、无法定制、竞品洞察停留在表面。如果你的业务需要盯着具体对手、分析历史价格波动、捕捉优惠券后的真实成交价,官方工具满足不了。
方法二:第三方采集软件
如果你不需要每天抓几万条数据,也没有开发资源,第三方工具是"今天下单、明天出数"的最短路径。
- 浏览器插件(Instant Data Scraper等)
- 操作:框选价格区域,一键导出CSV
- 优势:5分钟上手,零代码
- 缺点:翻页超过10页易卡死,无法登录态采集
- 适合:临时比价、20个SKU以内的小规模调研
- 专业采集平台(WebScraper等)
- 操作:可视化编排采集流程,云服务器定时执行
- 优势:支持登录态、定时任务、无需维护服务器
- 缺点:月费200-1000元,规模化后成本线性上升
- 适合:中小卖家监控20-100个竞品,无开发资源团队
第三方工具如果是500个SKU以内,高效使用;500个SKU以上,成本高、维护难、响应慢------这时候就需要考虑代码方案了。
方法三:代码爬虫
当你需要每天监控数千个SKU、采集API拿不到的字段、构建自己的历史价格数据库时,代码爬虫相当有效。
1. Python + Requests + Beautiful Soup
- 逻辑:发请求拿HTML → 解析定位价格 → 入库
- 优势:灵活度高,可抓API拿不到的字段
- 缺点:2026年纯Requests直连接存活率已极低
- 适合:技术验证、临时任务、配合高质量代理的小规模采集
2. Python + Playwright/Selenium
- 逻辑:浏览器自动化驱动,模拟真人操作
- 优势:绕过TLS指纹检测,登录态稳定
- 缺点:性能低,单机日采难破5000条
- 适合:需要登录态、复杂交互的中小规模采集
3. Java + Jsoup + HttpClient
- 逻辑:连接池+多线程+代理中间件
- 优势:内存控制,7×24小时稳定运行
- 适合:日采万级SKU、数据服务商、大型采集中台
三、为什么eBay数据采集容易踩"坑"?
很多新手以为eBay数据采集的难点在"写代码",真正跑起来才发现------代码没问题,数据却抓不到,或者抓几天就被封。这不是技术问题,是对eBay风控逻辑的认知问题。
1. IP层
- 数据中心IP存活时间极短,eBay对云服务商IP段有明确识别
- 共享IP,会导致整个IP段被标记
- IP位置频繁变动,与账号注册地或历史登录地不符
2. 请求层
- 单IP请求频率超过阈值
- 请求间隔无随机化,呈现固定节律
- 只请求数据接口,不加载页面资源
- 访问深度过浅,仅停留在详情页
3. 指纹层
- 浏览器指纹未改变,被识别为同一设备
- 无头浏览器默认配置暴露自动化特征
- WebRTC未禁用,代理环境下仍可能泄露真实IP
4. 登录层
- 新账号未经养号直接高频采集,行为异常
- 采集账号与主力店铺账号共用IP,关联风险
- IP同时登录多个采集账号,批量操作
5. 维护层
- 无日志监控,被封后无感知
- 无异常处理机制,遇到验证码直接崩溃
- 采集策略长期不更新,无法适应eBay反爬迭代
四、如何成功构建eBay抓取商品数据体系?
整个数据抓取体系中,真正决定采集系统能跑多久的,不是代码写得多好,而是中间两层------代理池与请求行为控制。
当采集任务进入到长期监控阶段,瓶颈通常会集中在以下几个问题上:
- IP地址是不是真实住宅出身?
- IP归属国与采集目标是否一致?
- IP被封后,系统能否自动感知并替换?
- 代理服务商是否允许长期、中高频的数据采集行为?
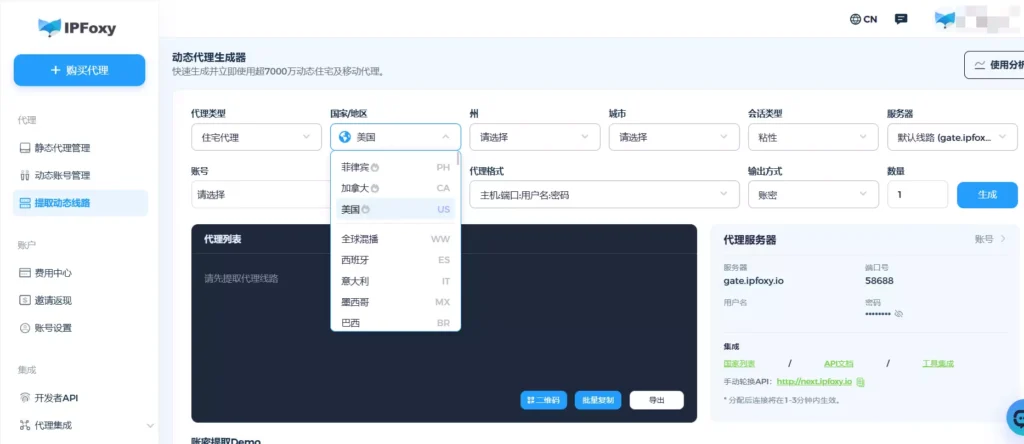
市面上很多代理一旦进入持续请求,存活率会断崖式下跌。对于需要长期稳定运行的eBay价格采集系统,选择专业代理服务商,通过合规渠道获取IP以支撑IP池的低重复率,更适合eBay长期价格监控,我分别测试过多家代理商,提供给大家一个最近在数据采集场景中的测试表现不错的代理商IPFoxy。
- IP池子超90000万,IP重复率低,覆盖全球200+地区
- 支持粘性会话与每次请求两种轮换模式,粘性时长超过30分钟
- 提供API级调度控制,适配自动化采集架构
五、FAQ
Q1:eBay允许数据采集吗?这合法合规吗?
eBay在robots.txt中明确禁止非授权自动化访问,但公开数据抓取在法律上处于灰色地带。
不要踩这三条红线:
不造成服务器压力
不抓取非公开数据(买家隐私等)
不用于恶意跟卖、侵权、欺诈
Q2:每天抓多少条数据算"安全"?
没有绝对安全的数字,但有阈值:
单IP + 单指纹环境:建议≤3000请求/日
单IP + 单指纹环境 + 登录态:建议≤1000请求/日
单账号:建议≤500次详情页请求/日
超过这些阈值,无论什么IP、什么指纹,封禁概率都会显著上升。
Q3:采集账号被封会影响主力店铺吗?
会。采集号与主力号最好要做到IP、设备、指纹、支付四重隔离。
六、总结
eBay运营,选择合适的抓取工具和技术非常重要,但反爬机制和封号问题常常困扰着用户。要稳定抓取数据,必须模拟真实用户行为,使用高质量的代理池、合理的请求控制和浏览器指纹管理。通过这些策略,你能高效地获取有价值的数据,为业务决策提供支持。