重写图文描述(Recaptioning)| 基于 data_engineering_book让文本更适配模型、更贴合图片
在多模态项目落地中,我们常会遇到「图片描述文本质量差」「文本风格不匹配模型输入习惯」「单描述覆盖不了图片核心信息」等问题------而Recaptioning(重写图文描述/重新生成图片标题) 正是解决这些问题的核心手段。本文基于《Data Engineering Book》核心内容,从Recaptioning的应用价值、核心策略、工程化实现到效果评估,手把手教你落地高质量的Recaptioning流程。
 GitHub地址: github.com/datascale-a...
GitHub地址: github.com/datascale-a...
一、为什么需要Recaptioning?
先看两个真实场景:
- 场景1:爬取的商品图描述是"好看的杯子",语义模糊,用在CLIP微调中几乎无价值;
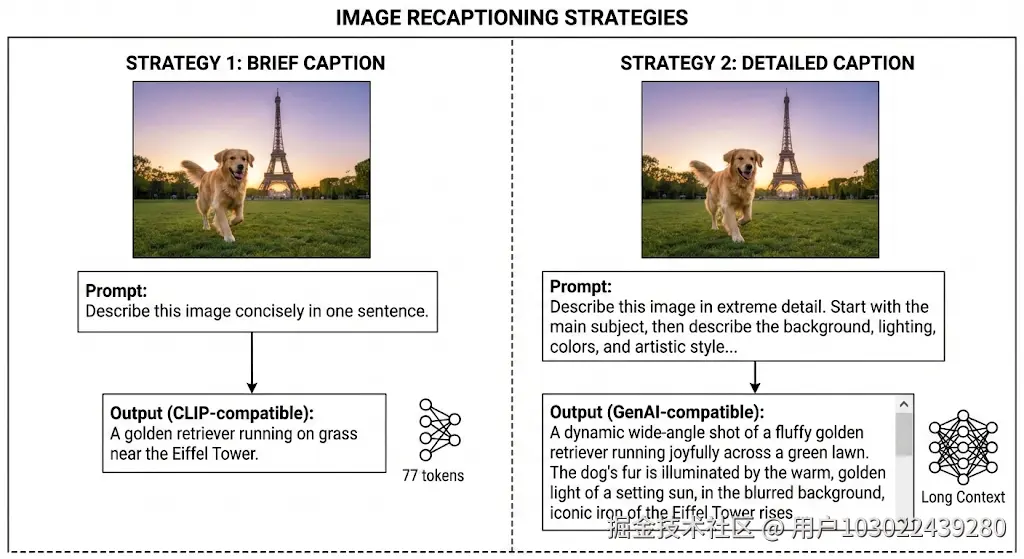
- 场景2:开源数据集的描述是长句("这是一个放在木质桌子上的白色陶瓷马克杯,杯身有蓝色条纹,容量约350毫升"),超出模型77token限制,直接用会被截断;
- 场景3:同一张图的描述只有1句,无法覆盖"外观+材质+使用场景"等多维度特征,图文检索召回率低。
Recaptioning的核心价值:
- 提升语义对齐度:修正错误、模糊、虚构的描述,让文本100%贴合图片;
- 适配模型输入:调整文本长度、风格、格式,匹配CLIP/BLIP/LLaVA等模型的输入习惯;
- 丰富描述维度:为单张图生成多段不同角度的描述,提升多模态任务的鲁棒性;
- 统一数据风格:将杂乱的原生描述(口语化、缩写、错别字)标准化,降低模型训练噪声。
二、Recaptioning的核心策略(从简单到复杂)
根据数据规模和成本,推荐3类Recaptioning策略,可按需组合使用:
1. 规则式Recaptioning(低成本、小批量)
适合数据量少(万级以内)、场景简单的场景,通过预设规则修正/重构文本,核心是"标准化+补全+精简"。
| 规则类型 | 示例(原生描述→重写后) | 实现思路 |
|---|---|---|
| 纠错补全 | "好看的杯子"→"白色陶瓷马克杯,圆形杯柄,容量350ml" | 基于图片标签(如OCR/物体检测结果)补全核心属性(颜色、材质、尺寸) |
| 长度适配 | 超长句→"白色陶瓷马克杯 木质桌面 蓝色条纹 350ml" | 按模型token限制截断,保留核心关键词,用空格/顿号分隔关键特征 |
| 风格统一 | "这杯子贼好用!"→"实用型陶瓷马克杯,易握持,耐高温" | 去除口语化/感叹词,统一为陈述句,禁用网络用语、缩写 |
| 维度扩展 | "马克杯"→"白色条纹马克杯", "350ml陶瓷咖啡杯", "木质桌面摆放的马克杯" | 基于图片特征,从"外观/尺寸/场景/功能"等维度生成多段短描述 |
规则式实现示例(Python):
python
import re
def rule_based_recaption(original_caption, image_attrs):
"""
规则式重写描述
:param original_caption: 原生描述文本
:param image_attrs: 图片属性(物体检测/OCR提取,如{"color":"白色","material":"陶瓷","size":"350ml"})
:return: 重写后的描述列表
"""
# 1. 清洗:去除特殊符号、口语化词汇、冗余前缀
clean_caption = re.sub(r"[!@#¥%&*()(){}【】]", "", original_caption)
clean_caption = re.sub(r"这是一个|好看的|好用的|漂亮的", "", clean_caption).strip()
# 2. 补全核心属性
core_attrs = [image_attrs.get("color", ""), image_attrs.get("material", ""), clean_caption, image_attrs.get("size", "")]
core_caption = " ".join([attr for attr in core_attrs if attr])
# 3. 生成多维度短描述(适配模型输入)
recaptions = [
core_caption, # 核心描述
f"{image_attrs.get('color', '')} {clean_caption} {image_attrs.get('scene', '')}", # 颜色+主体+场景
f"{image_attrs.get('material', '')} {clean_caption} {image_attrs.get('function', '')}" # 材质+主体+功能
]
# 4. 长度过滤(≤77token,这里简化为字符数≤60)
recaptions = [cap for cap in recaptions if len(cap) > 0 and len(cap) ≤ 60]
# 去重
recaptions = list(dict.fromkeys(recaptions))
return recaptions
# 测试
original = "好看的杯子!"
image_attrs = {"color":"白色", "material":"陶瓷", "size":"350ml", "scene":"木质桌面", "function":"咖啡饮用"}
print(rule_based_recaption(original, image_attrs))
# 输出:
# ['白色 陶瓷 杯子 350ml', '白色 杯子 木质桌面', '陶瓷 杯子 咖啡饮用']2. 模型生成式Recaptioning(中规模、高性价比)
当数据量达到10万级,规则式无法覆盖所有场景时,用图文生成模型自动重写描述是最优解------既保证效率,又能生成多样化、高质量的文本。
核心选型(按落地难度排序)
| 模型/工具 | 优势 | 适用场景 |
|---|---|---|
| BLIP-2(开源) | 轻量、适配中文、支持多轮生成 | 中小规模数据(10万级) |
| LLaVA(开源) | 结合大语言模型,描述更流畅 | 需要复杂/长文本描述场景 |
| GPT-4V/文心一言VL(闭源) | 效果最优、支持细粒度描述 | 核心数据精修、少量样本标注 |
工程化实现示例(基于BLIP-2)
python
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
from PIL import Image
class ModelBasedRecaptioner:
def __init__(self, model_name="Salesforce/blip2-opt-2.7b"):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载处理器和模型
self.processor = Blip2Processor.from_pretrained(model_name)
self.model = Blip2ForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16 if self.device == "cuda" else torch.float32
).to(self.device)
def generate_recaptions(self, image_path, num_captions=3, max_length=50):
"""
为单张图片生成多段重写描述
:param image_path: 图片路径
:param num_captions: 生成描述数量
:param max_length: 单段描述最大长度
:return: 重写后的描述列表
"""
# 加载图片
image = Image.open(image_path).convert("RGB")
# 构建prompt(引导模型生成标准化描述)
prompt = "请为这张图片生成简洁、准确的描述,包含颜色、材质、核心特征,格式为陈述句,长度不超过50字,生成3段不同角度的描述:"
# 预处理
inputs = self.processor(images=image, text=prompt, return_tensors="pt").to(self.device, torch.float16)
# 生成描述(设置do_sample增加多样性)
outputs = self.model.generate(
**inputs,
max_length=max_length,
num_return_sequences=num_captions,
do_sample=True,
temperature=0.7, # 温度越高,描述越多样
top_p=0.9,
repetition_penalty=1.2 # 避免重复
)
# 解析结果
recaptions = []
for output in outputs:
caption = self.processor.decode(output, skip_special_tokens=True).strip()
# 过滤模型生成的冗余前缀(如"1.""-")
caption = re.sub(r"^\d+\.|^-", "", caption).strip()
recaptions.append(caption)
return recaptions
# 实例化并测试
if __name__ == "__main__":
recaptioner = ModelBasedRecaptioner()
recaptions = recaptioner.generate_recaptions("data/images/mug.jpg", num_captions=3)
print("重写后的描述:")
for i, cap in enumerate(recaptions):
print(f"{i+1}. {cap}")3. 人机结合式Recaptioning(大规模、高质量)
对于百万级数据,纯规则太粗糙、纯模型有误差,推荐"模型生成+人工校验+规则兜底"的组合策略:
- 模型批量生成:用BLIP-2/LLaVA为所有图片生成3~5段候选描述;
- 规则初筛:过滤明显错误(如描述里有图片没有的物体)、长度超限、重复的描述;
- 人工抽检修正:按5%~10%的比例抽检,修正模型生成的错误(如把"玻璃杯"改成"陶瓷杯"),并将修正案例补充到规则库;
- 最终筛选:为每张图保留2~3段高质量描述,用于后续训练/检索。
三、Recaptioning效果评估:怎么判断重写得好不好?
避免"凭感觉"评估,推荐3个可量化的维度:
| 评估维度 | 评估方法 |
|---|---|
| 语义对齐度 | 用CLIP计算"重写文本-图片"的余弦相似度(越高越好,需高于原生描述) |
| 文本质量 | 1. 人工评分(1~10分,维度:准确性/完整性/简洁性);2. 检查是否有拼写/语法错误 |
| 任务适配性 | 在下游任务(如图文检索)中对比重写前后的指标(召回率/精确率) |
自动化评估示例(CLIP相似度):
python
from transformers import CLIPModel, CLIPProcessor
def evaluate_caption_alignment(image_path, captions, model_name="openai/clip-vit-base-patch32"):
"""计算描述与图片的CLIP相似度"""
processor = CLIPProcessor.from_pretrained(model_name)
model = CLIPModel.from_pretrained(model_name).to("cuda")
image = Image.open(image_path).convert("RGB")
# 预处理图片和文本
inputs = processor(
images=image,
text=captions,
return_tensors="pt",
padding=True,
truncation=True
).to("cuda")
# 计算特征
image_features = model.get_image_features(inputs["pixel_values"])
text_features = model.get_text_features(inputs["input_ids"])
# 归一化并计算余弦相似度
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
similarity = (image_features @ text_features.T).squeeze(0).tolist()
return dict(zip(captions, similarity))
# 测试:对比原生描述和重写描述的相似度
original_captions = ["好看的杯子"]
rewritten_captions = ["白色陶瓷马克杯 350ml 蓝色条纹", "木质桌面摆放的陶瓷咖啡杯"]
similarity_original = evaluate_caption_alignment("data/images/mug.jpg", original_captions)
similarity_rewritten = evaluate_caption_alignment("data/images/mug.jpg", rewritten_captions)
print("原生描述相似度:", similarity_original)
print("重写描述相似度:", similarity_rewritten)四、落地避坑指南
| 常见坑点 | 避坑方案 |
|---|---|
| 模型生成描述同质化严重 | 调大temperature(0.7~1.0)、增加top_p,或更换更优秀的基座模型(如BLIP-2-FlanT5) |
| 中文描述不流畅/有语法错误 | 用中文优化版模型(如Salesforce/blip2-opt-2.7b-cn),或在prompt中明确要求"中文、无语法错误" |
| 大规模生成速度慢 | 1. 多卡并行推理;2. 用FP16/INT8量化模型;3. 批量处理图片(而非单张) |
| 人工校验成本高 | 先按CLIP相似度筛选高分描述,再人工抽检(只校验前30%高分样本) |
五、总结
Recaptioning不是"简单改写文本",而是让文本精准匹配图片、适配模型、服务下游任务的核心环节。小批量数据可优先用规则式,中规模用模型生成,大规模则必须人机结合------最终目标是让每一段描述都能成为多模态模型的"有效燃料"。
如果你的项目中也遇到了图文描述质量差的问题,不妨试试本文的Recaptioning策略。欢迎在评论区分享你的落地经验/踩坑经历,后续会继续拆解多模态数据处理的其他核心模块~
希望本文能帮你夯实 LLM 开发的基础环节,欢迎访问 github.com/datascale-a... 获取完整代码和实战文档,也欢迎在仓库中交流经验, 觉得有帮助的朋友,欢迎点个 Star ⭐️ 支持一下!