在上一章中,我们走出纯理论,观察了一个 AI 智能体在真实环境中的运行:它以自治、推理与工具相结合的方式控制了一个真实的 Kubernetes 集群。通过简洁却强大的 k8s-ai 智能体(github.com/the-gigi/k8...),我们演示了 AI 智能体的一些基础能力,例如观察、诊断、工具使用、维持 human-in-the-loop 交互,以及运行智能体循环(agentic loop)。这个仅用 61 行 Python 编写的智能体,是 AI 智能体与 LLM 能力的一个令人印象深刻的展示。
在本章中,我们将开始开发一个更复杂、更完整的 AI 框架:AI-6(github.com/Sayfan-AI/A...)。AI-6 让我们能够探索 AI 智能体能力的完整谱系,例如更复杂的记忆管理、更高级的工具管理设施,以及对多个 LLM 提供商的支持。AI-6 的设计高度"无立场"(unopinionated),并且可通过工具进行高度扩展。它的首要设计原则是保持简单:提供一小组核心能力,使你可以通过添加专用工具,在其上构建更复杂的 AI 系统。
AI-6 是一个 Python 框架,包含后端与前端。本章我们聚焦后端。在第 5 章,我们将为 AI-6 添加工具;在第 6 章,我们将聚焦前端。
我们会先从框架后端架构及其组件的概览开始,然后深入一些关键部分,例如工具管理、记忆管理,以及消息处理流水线。
最后,我们将探讨如何用新的工具与新的 LLM 提供商来扩展该框架。
在本章中,我们将涵盖以下主要内容:
- AI-6 框架后端架构与组件
- 工具系统架构
- 记忆管理
技术要求
如果你希望在阅读本章时运行并实验 AI-6,请按照 README.md(github.com/PacktPublis...)中的安装说明进行设置。
这将创建一个虚拟环境,并为后端与前端组件安装全部必要依赖。
AI-6 框架后端架构与组件
AI-6 后端由一个核心引擎驱动:它运行智能体循环、管理工具、通过提供一个通用的 LLM provider 接口来支持任意 LLM 提供商,并拥有一套记忆管理系统。session manager 负责管理与每个用户的 session(消息历史)。它使用 Session 类存储一段完整对话的全部内容。tool system 是一个可扩展子系统,用于定义工具,并提供便于实现工具的基础类。LLM providers 是另一个可扩展子系统:它定义了通用的 LLM provider 接口,并提供了一些实现(目前是 OpenAI 与 Ollama)。
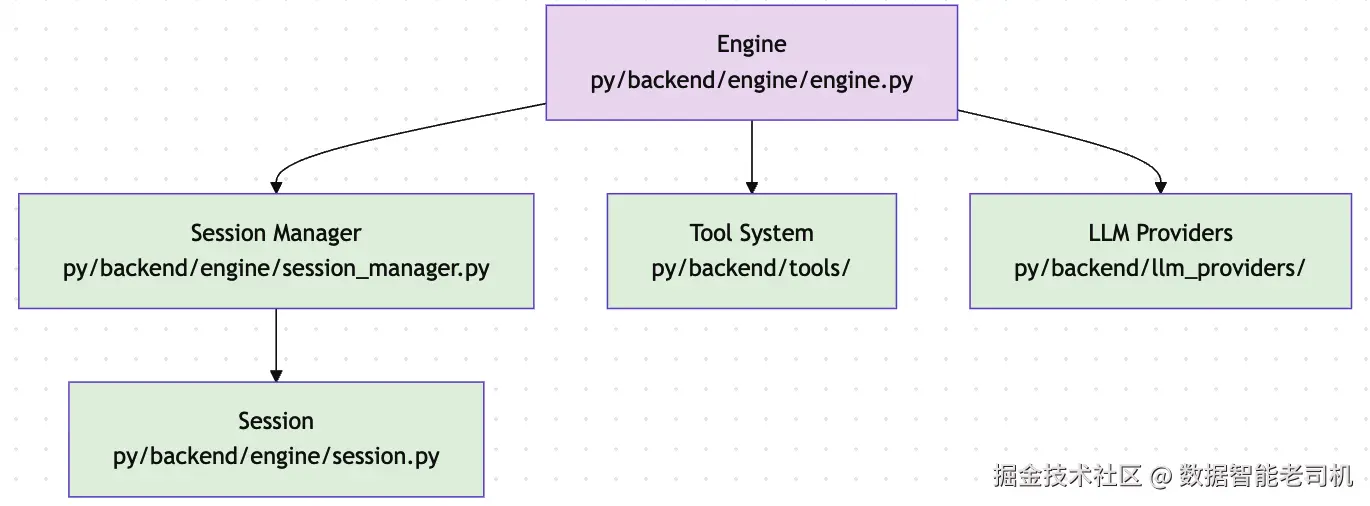
图 4.1:AI-6 核心引擎
我们来看看核心引擎如何工作。
核心引擎
核心引擎是 AI-6 框架的心脏。它协调与 LLM 提供商、工具以及会话管理的所有交互。它为不同前端提供统一接口,使其能够与 AI 模型通信,同时保持对话状态并执行工具调用。它由一个名为 Engine 的类实现(github.com/PacktPublis...。
使用 engine 很简单:先用所需配置初始化,然后运行它来执行智能体循环。我们看看具体怎么做。
初始化
当智能体 AI 系统使用 AI-6 时,engine 会以 LLM provider、工具与配置项初始化,作为核心组件。它的签名也很简单:只接收一个包含全部必要设置的 Config 实例:
ruby
def __init__(self, config: Config):
...下图说明了这个过程:
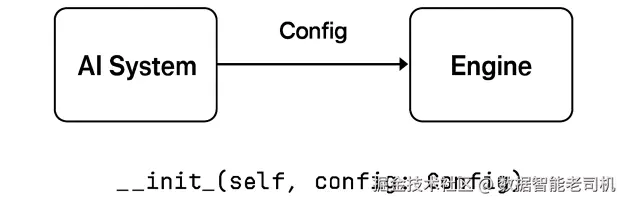
图 4.2:AI 系统用 Config 类初始化核心引擎
使用 AI-6 的 AI 系统通过一个 Config 对象为核心引擎指定配置。我们看一下 Config 类:
less
@dataclass
class Config:
default_model_id: str
tools_dir: str
mcp_tools_dir: str
memory_dir: str
session_id: Optional[str] = None
checkpoint_interval: int = 3
summary_threshold_ratio: float = 0.8
tool_config: Mapping[str, dict] = field(
default_factory=lambda: MappingProxyType({}))
provider_config: Mapping[str, dict] = field(
default_factory=lambda: MappingProxyType({}))这里信息量很大。我们逐项解释 Config 的组成:
default_model_id:默认使用的模型 ID;当没有显式指定模型时就用它。它也隐含决定默认 LLM provider,因为每个模型只属于一个 LLM providertools_dir:自定义 AI-6 工具所在目录;mcp_tools_dir:MCP 工具所在目录memory_dir:存放记忆文件的目录session_id:可选的 session 标识符,用于从上一次运行中恢复 sessioncheckpoint_interval:每隔多少次迭代保存一次 checkpointsummary_threshold_ratio:触发对会话历史进行摘要的 token 比例阈值tool_config与provider_config:映射结构,用于为每个工具与 provider 提供额外配置
如果你觉得有点"爆炸",先别慌;我们会在本章后面逐步解释每个配置项的用途。
下面我们看看 engine 如何用这个 Config 初始化。
首先,把 default_model_id 存成类属性,没什么特别的:
ruby
class Engine:
def __init__(self, config: Config):
self.default_model_id = config.default_model_id接着,根据默认模型 ID,从 model_info 模块获取 context window 大小,用它计算 token threshold(触发对话摘要的 token 数)。这是因为当对话历史接近模型上下文窗口上限时,我们需要做摘要,避免超过硬限制:
ini
# Get the context window size from model_info based on the default model
context_window_size = get_context_window_size(
self.default_model_id)
self.token_threshold = int(
context_window_size * config.summary_threshold_ratio
)然后初始化 LLM providers。engine 支持多个 provider,并能通过 discover_llm_providers() 定位它们。
之所以没有在 Config 里配置 provider 列表,是因为对用户而言"新增一个 provider"不是常见操作------当然,这也可以是一种替代设计。
在定位并确认 providers 目录存在且为目录后,调用 Engine.discover_llm_providers()。我们会在下一节深入它。该方法返回一个 provider 列表,每个 provider 可能支持多个模型:
lua
# Find LLM providers directory
llm_providers_dir = os.path.join(
os.path.dirname(os.path.dirname(__file__)), "llm_providers"
)
assert os.path.isdir(llm_providers_dir), (
f"LLM providers directory not found: {llm_providers_dir}"
)
# Discover available LLM providers
self.llm_providers = Engine.discover_llm_providers(
llm_providers_dir, config.provider_config
)engine 会据此构建一个 model_id -> llm_provider 的映射:
rust
self.model_provider_map = {
model_id: llm_provider
for llm_provider in self.llm_providers
for model_id in llm_provider.models
}接下来初始化工具。engine 同时支持自定义工具与 MCP 工具。工具初始化过程与 provider 类似:engine 调用 discovery 方法(目录来自 Config)来发现并注册工具,然后构建一个 tool_name -> tool_object 的字典,便于在智能体循环中按名称访问与调用工具。注意 MCP 工具目前还未用到;我们会在第 7 章引入 MCP 工具。
ini
# Discover available tools
tool_list = Engine.discover_tools(
config.tools_dir, config.tool_config)
# Discover MCP tools
mcp_tool_list = Engine.discover_mcp_tools(config.mcp_tools_dir)
self.tool_dict = {t.name: t for t in tool_list}初始化流程的下一部分与记忆管理相关。engine 用 session manager 处理 sessions,并用 session 对象管理对话历史。接着设置一些与周期性 checkpoint 存储相关的属性:
ini
# Initialize session and session manager
self.session_manager = SessionManager(config.memory_dir)
self.session = Session(config.memory_dir)
# Session-related attributes
self.checkpoint_interval = config.checkpoint_interval
self.message_count_since_checkpoint = 0随后设置 session:summarizer 负责在对话历史过长、接近上下文窗口上限时做摘要。然后 engine 注册 memory tools,让用户可以直接管理记忆:
ini
# Instantiate the summarizer with the first LLM provider
self.summarizer = SessionSummarizer(self.llm_providers[0])
# Register memory tools with the engine
self._register_memory_tools()最后,如果配置里给了 session ID,engine 会在该 session 存在时尝试加载它,从而恢复上一次会话并从断点继续对话:
ini
# Load previous session if session_id is provided and exists
if config.session_id:
available_sessions = self.session_manager.list_sessions()
if config.session_id in available_sessions:
# Create a new session object
self.session = Session(config.memory_dir)
# Load from disk
self.session.load(config.session_id)总结一下:我们用配置初始化了 engine,并动态加载了 LLM providers、自定义工具与 MCP 工具,然后初始化了记忆系统。接下来我们看看运行 engine 会发生什么。
运行引擎
engine 初始化完成后,我们可以运行它来启动 session。run() 方法接收多个 callable(函数)作为参数:get_input_func() 获取用户输入;on_tool_call_func() 是工具被调用时触发的回调;on_response_func() 是智能体循环生成最终回复时触发的回调。这些回调由使用 AI-6 的智能体 AI 系统或 AI-6 自带前端实现,使 engine 能通过一个通用接口通信,而不需要了解具体应用或前端细节。这种设计带来灵活性与可扩展性:不同智能体系统与前端可以实现各自版本的回调。
run() 会循环运行,直到 get_input_func() 不再提供输入。也就是说,engine 会执行多个智能体循环(每个循环由一次或多次 LLM 交互与工具调用构成),并把对话历史累积到 session 中。
run() 的签名如下:
python
def run(
self,
get_input_func: Callable[[], None],
on_tool_call_func: Callable[[str, dict, str], None] | None,
on_response_func: Callable[[str], None],
):实现也很直接:先取当前循环的输入,加入 session;然后按需创建 checkpoint(我们会在"记忆管理"一节讨论 checkpoint)。
css
try:
while user_input := get_input_func():
message = UserMessage(content=user_input)
self.session.add_message(message)
self._checkpoint_if_needed()接下来是智能体循环的核心:调用 _send() 处理输入,传入默认模型 ID,并把 on_tool_call_func 回调传进去。_send() 做了所有"重活"(我们马上会细看)。得到 response 后,把它作为 assistant message 加入 session,按需再做一次 checkpoint,最后调用 on_response_func 把 response 回给前端/应用:
scss
response = self._send(
self.default_model_id, on_tool_call_func)
message = AssistantMessage(content=response)
self.session.add_message(message)
self._checkpoint_if_needed()
on_response_func(response)最后是 finally:无论成功还是抛异常,退出 run() 时都要保存 session。这能保证即使出现问题(例如触发 LLM provider 的限流)对话历史也不会丢:
php
finally:
# Save the session when we're done
self.session.save()执行智能体循环
下面更细看 _send():它每被调用一次,就在一个 session 中执行一次完整的智能体循环。_send() 接收一个 model_id 与可选的 on_tool_call_func 回调。model_id 指定本次循环使用的模型(也就决定了使用哪个 LLM provider);on_tool_call_func 在循环中每次发生工具调用时被触发。
如果 LLM 不需要调用工具就能直接返回最终回复,那么 on_tool_call_func 就不会被调用。
这种设计让 engine 能通知前端或应用发生了工具调用,从而支持实时更新与交互。_send() 返回本次智能体循环的最终回复:即 LLM 在处理输入并执行了必要的工具调用后生成的回复。
签名如下:
python
def _send(
self,
model_id: str,
on_tool_call_func: Callable[
[str, dict, str], None
] | None = None,
) -> str:1)校验 model_id 并获取 provider
先检查 model_id 是否有效,以及对应 provider 是否存在;否则这是关键失败,直接抛 RuntimeError:
python
llm_provider = self.model_provider_map.get(model_id)
if llm_provider is None:
raise RuntimeError(f"Unknown model ID: {model_id}")2)把 session messages 与工具字典发送给 provider
接着把 session 的所有消息、工具字典以及所选模型 ID 交给 provider 发送。provider 负责与 LLM 通信并返回 response。这里是 provider-agnostic 的:AI-6 用了 LLM provider 抽象。我们会在下一节(LLM provider abstraction)详细展开。
python
try:
response = llm_provider.send(
self.session.messages, self.tool_dict, model_id
)
except Exception as e:
raise RuntimeError(f"Error sending message to LLM: {e}")3)处理 tool calls:把 provider-specific ID 统一成 UUID
如果 response 里包含 tool calls,就需要处理它们。第一步是把工具调用 ID 映射为 UUID。这是因为某些提供商返回的 tool call ID 可能不是合法 UUID,而我们希望在 provider-agnostic 的层面统一用 UUID 标识工具调用。generate_tool_call_id() 会为那些"不是有效 UUID"的 tool call ID 生成新的 UUID。id_mapping 保存从 LLM 原始 tool call ID 到新 UUID 的映射;如果 LLM 给的 ID 本身合法,就原样使用,不生成新 UUID。
ini
if response.tool_calls:
# Create a mapping of original IDs to new UUIDs if needed
id_mapping = {}
for tool_call in response.tool_calls:
# Check if we need to replace the ID with a UUID
if (
not tool_call.id or len(tool_call.id) < 32
): # Simple check for non-UUID
new_id = generate_tool_call_id(tool_call.id)
id_mapping[tool_call.id] = new_id接着,如果确实发生了替换,就更新 response 里的 tool call ID(provider 已返回 AssistantMessage,所以可以直接就地修改):
python
# Update the tool call IDs in the response if needed
if id_mapping and response.tool_calls:
for tool_call in response.tool_calls:
if tool_call.id in id_mapping:
tool_call.id = id_mapping[tool_call.id]现在可以把 assistant message 加入 session:
php
# Add the assistant message with updated tool_calls
self.session.add_message(response)在继续处理 tool calls 之前,还要把这条 assistant message 里的 tool_call_id 记录到一个 set 里,后面会用到:
ini
# Track tool_call_ids from this assistant message
tool_call_ids = set()
for tool_call in response.tool_calls:
tool_call_ids.add(tool_call.id)4)逐个执行工具调用并写回 ToolMessage
此时可以遍历 response 里的每个 tool call 并处理。执行前需要做若干准备步骤:验证工具存在于 tool_dict 中、解析 arguments JSON,并检查 tool_call_id 是否需要更新。
python
# Now process each tool call and add the corresponding tool messages
for i, tool_call in enumerate(response.tool_calls):
tool = self.tool_dict.get(tool_call.name)
if tool is None:
raise RuntimeError(f"Unknown tool: {tool_call.name}")
try:
kwargs = json.loads(tool_call.arguments)
except json.JSONDecodeError as e:
raise RuntimeError(
f"Invalid arguments JSON for tool '{tool_call.name}'"
)
# Get the potentially updated tool call ID
tool_call_id = tool_call.id
if tool_call.id in id_mapping:
tool_call_id = id_mapping[tool_call.id]随后执行工具调用:用解析后的参数运行 tool,捕获结果,生成包含工具结果的 ToolMessage(包含 tool name 与 tool_call_id),并在提供了回调时调用 on_tool_call_func。这都在 try 块里:
ini
try:
# Execute the tool without passing any ID information
tool_result = tool.run(**kwargs)
# Create the tool message with the Engine managing the tool_call_id
tool_message = ToolMessage(
content=str(tool_result),
name=tool_call.name,
tool_call_id=tool_call_id,
)
if on_tool_call_func is not None:
on_tool_call_func(
tool_call.name, kwargs, str(tool_result))如果工具调用失败,则捕获异常并生成错误消息:
ini
except Exception as e:
tool_message = ToolMessage(
content=str(e),
name=tool_call.name,
tool_call_id=tool_call_id,
)无论成功或失败,都把 tool message 加入 session。工具调用失败不会中断智能体循环;它只是在 session 里记录一条带 error 的 tool message。这样智能体可以继续处理其他 tool calls 或生成回复。至于失败该怎么处理,会由 LLM 在下一轮循环中决定。
php
# Add the tool message (ID is guaranteed to be valid since we manage it)
self.session.add_message(tool_message)5)递归继续循环
当所有 tool calls 都处理完、结果也写回 session 后,_send() 递归调用自己------这就是智能体循环继续运行的地方:
php
# Continue the session with another send
return self._send(model_id, on_tool_call_func)6)没有 tool calls 时返回最终回复
当 LLM 的 response 不包含任何 tool calls 时,方法返回最终回复内容:
kotlin
return response.content.strip()好,先停一下。这里信息量很大,而且确实不算"简单"。大部分复杂性来自:需要在 provider-specific 的 tool call 形式与 engine 内部的 provider-agnostic 形式之间做转换,以便 engine 能管理 session 与对话历史。但智能体循环的本质,和 k8s-ai 的智能体循环完全一样。
接下来,我们深入看看 LLM provider abstraction。
LLM Provider 抽象层
这是 AI-6 框架中非常重要的一部分。LLM provider 抽象层让 engine 能通过一个统一接口与任意类型的 LLM provider 通信。注意,这里有一种替代设计:框架只支持 OpenAI API。原因有二:第一,很多 LLM 提供商直接支持 OpenAI API,或通过自己的兼容层支持它(例如 Google Gemini)。第二,还有像 OpenRouter(openrouter.ai)这样的项目,它通过 OpenAI API 充当通往任意 LLM provider 的代理。那么,为什么还要构建一个 provider-agnostic 的接口?原因在于:它让框架能够完全掌控与所支持 LLM provider 的交互,并且不需要经过代理------代理会带来额外的时延、成本与安全隐患。下面我们看看 AI-6 框架里 LLM provider 抽象层是如何实现的。
LLMProvider 接口
Python 的抽象基类(ABCs)非常适合用来定义 LLMProvider 接口,该接口定义在 llm_provider.py 文件中。LLMProvider 通过允许开发者实现符合该接口的自定义 provider,使 AI-6 框架具备可扩展性。我们将按方法逐个拆解;但先看 imports。
首先,从标准库的 abc 与 typing 模块中导入必要的类与装饰器。然后,从 object_model 模块导入 Response 类,它用于表示来自 LLM 的通用响应。最后,从 tool 模块导入 Tool 类,它表示可供 LLM 使用的工具。这些都是 AI-6 后端架构的一部分。
python
from abc import ABC, abstractmethod
from typing import Iterator, Callable, Any
from backend.engine.object_model import Response
from backend.engine.tool import Tool接下来我们看 LLMProvider 类本身以及第一个方法:send()。send() 是一个抽象方法(用 @abstractmethod 装饰,子类必须实现),它负责把消息列表发送给 LLM 并接收响应。
它也会向 LLM 提供一个工具字典,以及一个可选的 model 参数。该方法返回一个 Response 对象,其中包含以通用格式表示的 LLM 响应。
python
class LLMProvider(ABC):
@abstractmethod
def send(
self, messages: list[Message], tool_dict: dict[str, Tool],
model: str | None = None
) -> AssistantMessage:
"""
Send a message to the LLM and receive a response.
:param messages: The list of messages to send.
:param tool_dict: A dictionary of tools available for the LLM to use.
:param model: The model to use (optional).
:return: The response from the LLM.
"""
passstream() 方法与 send() 类似,但它允许在响应生成时以流式方式返回。它返回一个 Response 迭代器,使调用方能在完整响应结束之前先接收响应片段。这对于希望边生成边展示的实时应用很有用。注意:stream() 不是抽象方法,它有一个默认实现:直接调用 send() 并 yield 整个响应。这意味着:子类如果支持真正的 streaming,可以覆盖该方法;否则就使用默认"整包返回"的实现。
python
def stream(
self, messages: list[Message], tool_dict: dict[str, Tool],
model: str | None = None
) -> Iterator[AssistantMessage]:
"""
Stream a message to the LLM and receive responses as they are generated.
:param messages: The list of messages to send.
:param tool_dict: The tools available for the LLM to use.
:param model: The model to use (optional).
:return: An iterator of responses from the LLM.
"""
# Default implementation just returns the full response
yield self.send(messages, tool_dict, model)models 属性是一个抽象属性,子类必须实现。它返回一个字符串形式的 model ID 列表。model ID 是 provider 所支持每个模型的唯一标识。engine 用它把 model 映射到 provider,并在请求指定模型时选择正确的 provider。
python
@property
@abstractmethod
def models(self) -> list[str]:
""" Get the list of available models."""
pass至此,我们覆盖了 LLMProvider 接口。下面我们看看 AI-6 开箱即用提供的具体 provider 实现。
支持的 Provider
我们看一下此时 AI-6 框架支持的 LLM provider。AI-6 随包提供 OpenAI 与 Ollama 两个 provider,分别覆盖云端与本地模型选项。
记住:新增 provider 很容易实现。
我们先看 OpenAI provider 的实现。
OpenAI Provider
OpenAI provider 定义在 openai_provider.py 文件中(github.com/PacktPublis...)。它使用 OpenAI Python SDK 与 OpenAI API 通信。该 provider 实现了 LLMProvider 接口,并提供发送消息、流式发送以及获取模型列表的方法。我们来看它的实现要点。
该 provider 需要 API key 进行鉴权,API key 通过构造函数传入。它还提供 API base URL 与默认模型的默认值。当 base URL 为 None 时,OpenAI SDK 会使用官方 OpenAI API endpoint:https://api.openai.com/v1。如果你想使用另一个具有 OpenAI 兼容 API 的 LLM provider,例如 Anyscale(docs.anyscale.com/reference)、DeepSeek(api-docs.deepseek.com/)、SambaNova(cloud.sambanova.ai/apis)或 Cerebras(inference-docs.cerebras.ai/resources/o...),就需要传入正确的 endpoint。
从这个角度看,OpenAI provider 本身已经支持多个提供商,当然也可以用 OpenRouter。
python
from typing import Iterator
from backend.object_model import (
LLMProvider, ToolCall, Usage, Tool, AssistantMessage)
from openai import OpenAI
class OpenAIProvider(LLMProvider):
def __init__(
self, api_key: str, base_url = None,
default_model: str = "gpt-4o"
):
self.default_model = default_model
self.client = OpenAI(base_url=base_url, api_key=api_key)LLMProvider 接口以 AI-6 的数据结构为定义基础:这些结构对 LLM provider 无关(provider-agnostic),但包含 LLM 处理用户消息与请求工具调用所需的同等信息。因此,OpenAI provider 的工作就是把 AI-6 的表示转换成 OpenAI Python SDK 的表示。
下面的 send() 方法正是做这件事。比如 OpenAI Python SDK 期望工具以 Python dict 的形式提供,因此 send() 使用私有方法 _tool2dict() 把 tool_dict 转换成 SDK 能理解的 dict 列表。
python
def send(
self, messages: list[Message], tool_dict: dict[str, Tool],
model: str | None = None
) -> AssistantMessage:
"""
Send a message to the OpenAI LLM and receive a response.
:param tool_dict: The tools available for the LLM to use.
:param messages: The list of messages to send.
:param model: The model to use (optional).
:return: The response from the LLM.
"""
if not messages:
raise ArgumentError(
"messages",
"At least one message is required to send to the LLM.")
if model is None:
model = self.default_model
tool_data = [self._tool2dict(tool) for tool in tool_dict.values()]随后,该方法调用 OpenAI Python SDK,用指定的 model、messages 与 tools 创建 chat completion:
ini
response = self.client.chat.completions.create(
model=model,
messages=messages,
tools=tool_data,
tool_choice="auto"
)接着从响应中提取 tool_calls 字段;如果为 None,就转成空列表:
ini
tool_calls = response.choices[0].message.tool_calls
tool_calls = [] if tool_calls is None else tool_calls同时提取 usage 信息,包括本次请求消耗的输入与输出 token 数:
ini
# Extract usage data
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens最后构造一个 AssistantMessage:包含响应内容、role、tool calls 与 usage。OpenAI 的 tool calls 会被转换为 AI-6 的 ToolCall 格式,其中包含 tool call ID、名称、参数,以及该工具是否 required。required 字段通过检查工具规范中参数是否必填来决定。举例来说,如果工具 get_weather_in_city 有两个参数:city(必填)与 unit(可选),当 unit 不提供时工具会默认使用摄氏度。在这种情况下,LLM 可能用两个参数调用(city: London, unit: Fahrenheit),也可能只用必填参数调用(city: London)。
ini
return AssistantMessage(
content=response.choices[0].message.content,
tool_calls=[
ToolCall(
id=tool_call.id,
name=tool_call.function.name,
arguments=tool_call.function.arguments,
required=tool_dict[
tool_call.function.name].parameters.required
) for tool_call in tool_calls if tool_call.function
] if tool_calls else None,
usage=Usage(
input_tokens=input_tokens,
output_tokens=output_tokens
)
)OpenAI provider 也实现了 stream() 方法,以支持流式输出。不过该方法较长,这里不展开。简单说,它是一个 generator:分块处理 LLM 输出,而不是等待完整响应返回。如果你感兴趣,可以查看代码:github.com/PacktPublis...
默认的 stream() 实现并不真正流式,而是委托给阻塞式的 send()(必需实现)。如果 provider 支持 streaming(OpenAI 支持),就可以覆盖 stream() 并适配该 provider 的具体返回格式。
models 属性返回 OpenAI API 上可用模型的列表,它用 OpenAI Python SDK 拉取:
python
@property
def models(self) -> list[str]:
return [m.id for m in self.client.models.list().data]为了闭环,下面是两个辅助方法:把 AI-6 的 tool 与 ToolCall 表示转换成 OpenAI SDK 所需的 Python dict 格式:
python
@staticmethod
def _tool2dict(tool: Tool) -> dict:
"""Convert the tool to a dictionary format for OpenAI API."""
return {
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": {
"type": "object",
"required": tool.parameters.required,
"properties": {
param.name: {
"type": param.type,
"description": param.description
} for param in toolparameters.properties
},
}
}
}
@staticmethod
def _tool_call2dict(tool_call: ToolCall) -> dict:
"""Convert a ToolCall to OpenAI API format."""
return {
"id": tool_call.id,
"type": "function",
"function": {
"name": tool_call.name,
"arguments": tool_call.arguments
}
}接下来我们转向 Ollama provider。
Ollama Provider
Ollama(ollama.com/)是一个本地 LLM provider,允许你在自己的机器上运行模型。这非常酷:你不需要为外部提供商付费,也不必担心敏感信息外泄。
AI-6 的 Ollama provider 实现在 ollama_provider.py 文件中。它同样实现 LLMProvider 接口,并提供发送消息与获取模型列表的方法。它没有实现 stream(),而是依赖基类 LLMProvider 的默认实现来"流式返回"(实际是一次性返回整包结果)。
该实现与 OpenAI provider 非常相似,只是它用 Ollama Python SDK 与本地运行的 Ollama API 通信。该 provider 要求系统中安装并可调用 Ollama client,并且 Ollama 服务正在运行。我们会在第 6 章看到它的实际运行。
下面是实现轮廓。我省略了多数方法的具体实现细节,因为它们与 OpenAI provider 非常相似。在 send() 方法里,我通过 ollama.chat() 调用 Ollama SDK:把 messages 与 tools 发给 Ollama 模型并返回响应:
python
import json
from dataclasses import asdict
from backend.object_model import (
LLMProvider, ToolCall, Usage, Tool, AssistantMessage, Message)
import ollama
class OllamaProvider(LLMProvider):
def __init__(self, model: str):
self.model = model
@staticmethod
def _tool2dict(tool: Tool) -> dict:
"""Convert the tool to a dictionary format for Ollama."""
...
@staticmethod
def _fix_tool_call_arguments(messages):
...
def send(
self, messages: list[Message], tool_dict: dict[str, Tool],
model: str | None = None
) -> AssistantMessage:
"""Send a message to the local Ollama model and receive a response."""
.
.
.
OllamaProvider._fix_tool_call_arguments(message_dicts)
response: ollama.ChatResponse = ollama.chat(
model,
messages=message_dicts,
tools=tool_data
)
.
.
.
@property
def models(self) -> list[str]:
"""Get the list of available models."""
return [self.model]接下来,我们将把注意力转向工具如何被调用以及其底层架构。
工具系统架构
我们已经非常详细地讲解了 AI-6 框架的核心架构及其组件:核心引擎、LLM provider 抽象层,以及工具是如何被调用的。现在,让我们更近一步看看这个可扩展的工具系统架构。
工具系统架构的设计目标包括:
- 支持自定义工具
- 支持 MCP 工具
- 允许工具安全执行
- 允许控制每个 AI-6 session 可使用的工具集合
下面我们逐项展开。
自定义工具支持
自定义工具架构与 LLM provider 抽象类似,基于抽象基类实现。它允许开发者实现符合一个比 LLM provider 还更简单接口的自定义工具,从而提供 function-calling 能力(platform.openai.com/docs/guides...)。这种机制由 OpenAI 率先推广,随后被所有主要厂商采用。相关定义都在 tool.py 文件中。我们从必需的 imports 开始拆解:它从 abc 模块导入 ABC 基类与 abstractmethod 装饰器,从 dataclasses 模块导入 dataclass 装饰器,并从 typing 模块导入 NamedTuple 类。
javascript
from abc import ABC, abstractmethod
from dataclasses import dataclass
from typing import NamedTuple接着定义 Parameter 类。它继承自 named tuple(见:docs.python.org/3/library/c...),用于表示一次函数调用中的单个参数:包含 name、type 与 description。使用 NamedTuple 作为基类的好处是:Parameter 不可变且高效。
python
class Parameter(NamedTuple):
name: str
type: str
description: strTool 类是一个抽象基类,表示一个可被 LLM 通过 function calling 使用的工具。我们来看一下,它非常简洁。它使用 @dataclass(slots=True) 装饰器:slots 让实例更受限(不能随意添加新属性)、占用更少内存,并且访问属性更快。
Tool 类包含以下属性:name、description、parameters 与 required(执行工具时必须提供的参数集合)。我们前面已经看到:这些信息会在每次请求的 tools 列表中提供给 LLM。LLM 可以据此决定调用哪些工具以及如何调用。回忆第 3 章的讨论:LLM 会基于 prompt 与/或工具描述来做这些决策。
python
@dataclass(slots=True)
class Tool(ABC):
name: str
description: str
parameters: list[Parameter]
required: set[str]configure() 方法是一个可选方法,子类可以实现它,以使用任意信息配置工具。它只接收一个 dict,内容可以是任何东西。例如,一个与数据库交互的工具可能需要连接串作为配置。
python
def configure(self, config: dict) -> None:
"""Optional: configure the tool with given parameters."""
pass最后,run() 方法是一个抽象方法,子类必须实现。它负责用 LLM 提供的参数执行工具。参数以关键字参数传入,返回一个字符串。你会记得:当智能体循环中 LLM 调用了工具时,AI-6 engine 就会执行工具的 run() 方法。
python
@abstractmethod
def run(self, **kwargs) -> str:
pass自定义工具很强,但同样重要的是支持内置工具。
内置工具怎么办?
有些模型支持内置工具。下面列出一部分(非完整)OpenAI 某些模型支持的内置工具:web search、file search、image generation、code interpreter(Python)以及 computer use。
你可以在 OpenAI 平台查看最新的可用内置工具列表:
platform.openai.com/docs/guides...
AI-6 目前不支持内置工具。原因是:内置工具的使用依赖特定 LLM provider、该 provider 的特定模型,甚至还依赖特定 API。比如 AI-6 的 OpenAIProvider 使用的是 OpenAI chat completions API,而它只支持 web search 这一项内置工具。若要使用前面提到的其他内置工具,必须使用 OpenAI responses API。
未来,AI-6 可能会通过更新配置系统来加入内置工具支持:为每个 LLM provider、每个模型配置允许使用的内置工具列表。对于 OpenAI,还需要在 OpenAIProvider 中增加对 responses API 的支持。
MCP 工具支持
AI-6 框架同样支持 MCP 工具。MCP 工具符合模型上下文协议(Model Context Protocol,MCP)的规范。MCP 是一个最初由 Anthropic 开发的标准协议,允许 LLM 以安全、可控的方式访问外部数据与工具。我们会在第 7 章用整章内容深入探讨该主题。
下面我们讨论工具系统需要考虑的安全与权限。
工具安全与权限
在一个使用工具的智能体 AI 系统中,最重要的方面之一就是控制工具对数据与资源的访问。原因是:工具在实践中由 LLM 控制,而 LLM 是一个"黑盒",你无法直接观察其内部意图与决策过程。举个例子:如果 LLM 拥有一个对生产数据库具备完全权限的数据库工具,同时被要求"提升数据访问性能并降低成本",在缺少额外约束的情况下,LLM 可能会认为最优方案是把数据库和数据全删掉,只把最近一天的数据留在内存里。幸运的是,有多种方式可以缓解这一风险。AI-6 因为设计上"无立场"并允许系统采用任意机制甚至多机制叠加,因此天然支持这些方式。
下面是你可以用来管理工具执行的多种方法,它们在严谨程度、信任与控制力度上各不相同:
全信任、全权限(Full trust, full access)
这种模式仅适用于教学目的,或当配置的工具无法访问任何敏感数据或重要资源时。LLM 可以不经检查或限制直接执行任何工具。注意:即便是看起来无害的场景(例如只读工具)也可能造成损害。比如,一个只读数据库工具无法篡改或删除数据,但仍可能读取并外传数据;它还可能通过执行超大查询引发自我 DoS(拒绝服务)攻击。
中介式细粒度工具访问(Mediated fine-grained tool access)
"中介式细粒度"意味着工具不直接在系统上执行命令、也不直接访问资源。负面例子就是 k8s-ai:它通过 kubectl 直接访问 Kubernetes 集群。如果 LLM 决定要删除所有 namespace,k8s-ai 会不加询问照做。为了解决这个问题,可以移除 kubectl 工具,替换为多个细粒度工具,例如 get_pods、create_Deployment 等。这种方式提供对 Kubernetes 的细粒度访问,并避免像"删除 namespace"这样的危险操作。它的好处是控制力极强;但像 Kubernetes 这种 API 面非常复杂的资源,用多个工具去管理访问会带来巨大的工程负担。
护栏(Guardrails)
护栏是管理 LLM 风险的另一种机制。注意,护栏概念不仅限于 LLM 的工具使用:它可以保护工具调用中的参数、工具调用的响应,也可以保护发给 LLM 的 prompt,以及模型生成并返回给用户之前的响应。我们看看几类护栏:
- 幻觉护栏(Hallucination guardrails) :防止 AI 生成事实不准确或误导性内容。实现通常需要严格评估流程,把生成输出与可信来源对照。
- 合规护栏(Regulatory-compliance guardrails) :确保 AI 生成内容符合适用法律法规,无论是通用法规还是行业/用例特定规则。
- 对齐护栏(Alignment guardrails) :让输出与用户意图及原始目标保持一致,尽量减少"跑偏"。对于语气、信息传达与品牌一致性尤其有用。
- 验证护栏(Validation guardrails) :评估生成内容是否满足预定义规则,例如某些细节必须出现或必须不出现。若验证失败,应进入纠错流程。通常这是最后一道自动化步骤,之后任何被标记或不确定的情况应进入人工审查。
基于容器的沙箱(Container-based sandboxing)
工具使用的一个主要风险是:LLM 可能在系统上执行任意代码。即便 LLM 本身并无恶意(至少目前如此),它也可能在工具使用过程中无意引发性能问题、留下安全漏洞,或总体偏离预期行为。为降低风险,通常建议把智能体系统运行在容器里,以一定程度隔离底层机器。注意这并非万无一失:容器可能被逃逸(参见:medium.com/@the.gigi/p...)。本地运行 AI 系统时,我们往往还希望它访问本地目录、文件与其他资源,这意味着容器必须配置允许访问这些资源------这是安全与受控访问之间的权衡。它也允许通过控制容器内可用文件,为智能体系统提供受限的外部服务凭证。
用户权限(User permissions)
用户权限是另一层有效控制:用一个专用的低权限操作系统用户来运行智能体,从而限制对敏感文件、目录与系统能力的访问,降低 LLM 控制的工具可读、可写、可执行范围。即使不使用容器化,这种方式也能阻止智能体修改关键系统文件或访问未授权数据,贯彻最小权限原则。比如,智能体只能写入某个目录(如 /var/agent-output/),同时被禁止访问 home 目录或系统配置。该方法还能与基于组的访问控制、文件系统 ACL、或 Linux 的 ulimit、seccomp 等机制组合,以进一步收紧权限。它在本地或轻量环境中尤其有用,因为那里全量沙箱化可能不现实。尽管用户级权限无法阻止 LLM 滥用"已允许的能力"(例如外传可读数据),但它提供了一条干净、可管理的边界,能减少非预期伤害,并让安全审计更容易。
人在回路(Human-in-the-loop)
最后,human-in-the-loop 是控制 LLM 工具使用的一种强力方式:在执行某些工具调用前,让人类审查并批准。这能有效防止非预期或有害动作,因为人类判断可以过滤掉 LLM 可能基于不完整上下文或含糊提示做出的决定。例如,在删除某个资源前,系统可以把该动作展示给人类操作员确认,确保关键操作只有在明确批准时才执行。该方式可在不同粒度实现:从每次工具调用都审批,到只对高风险动作介入。它在错误代价高或安全至上的领域尤其有效,例如基础设施管理、金融操作或医疗系统。尽管它会引入时延并要求有人可用,但会显著提升信任与可靠性,非常适合在自动化与监督之间求平衡的混合工作流。
记忆也是智能体系统的另一个关键部分。接下来我们讨论它。
记忆管理
记忆管理可以说是智能体 AI 框架最重要的工作。它当然也可以由宿主 AI 系统来做,但这件事既重要又足够微妙,最好还是让 AI 框架把这个问题一次性解决掉,让基于它构建的 AI 系统把精力放在应用层面的关注点上。正如我们在第 2 章讨论过的,AI 系统中多种类型的记忆都很重要。AI-6 通过一个统一概念来管理所有不同类型的记忆:session(会话) 。
什么是 session?
session 是与 LLM 的一次顶层交互中所有消息的集合。session 还会统计所有消息的输入与输出 token 数。一个 session 可能包含多条输入消息,可能涉及多个 AI 智能体,并且可能跨时间与机器边界持久化。
session 定义在 engine/session.py 文件中。
我们来看看它怎么工作。下面是 imports:json 用于 session 的序列化/反序列化;uuid 用于生成唯一 session ID;然后从 AI-6 的 object model 中导入一系列类:
javascript
import json
import uuid
from dataclasses import asdict
from backend.object_model import (
Usage, Message, UserMessage, SystemMessage, AssistantMessage,
ToolMessage, ToolCall)session 用一个 memory 目录初始化,该目录用于存储持久化的 session。首先生成一个随机 session ID,然后根据 session ID 生成 session title。我们稍后会看到如何通过另一个类 SessionManager 来设置已保存 session 的 title。然后初始化一个 usage 对象:
python
class Session:
def __init__(self, memory_dir: str):
self.session_id = str(uuid.uuid4())
self.title = 'Untiled session ~' + self.session_id
self.messages: list[Message] = []
self.usage = Usage(0, 0)
self.memory_dir = memory_diradd_message() 方法非常直接:接收一个 message 并追加到 session 的 messages 列表中。如果该 message 带有 usage 对象,就把它的输入/输出 token 数累加到 session 的 usage 中,从而维持一个滚动累计值。我们会在"处理长上下文"一节看到:usage 对象如何用来决定是否需要压缩上下文窗口。
python
def add_message(self, message: Message):
"""Add a Message object to the session."""
self.messages.append(message)
# Extract usage from AssistantMessage if present
if hasattr(message, 'usage') and message.usage:
self.usage = Usage(
self.usage.input_tokens + message.usage.input_tokens,
self.usage.output_tokens + message.usage.output_tokens
)save() 方法会用 dataclasses 模块的 asdict() 把每条消息转换为字典,然后再组装成一个包含所有消息字典的总字典,将其序列化为 JSON,并保存到 memory 目录下名为 <session_id>.json 的文件。这样我们就得到了一个持久化 session,即便进程崩溃也可以之后恢复。
ini
def save(self):
# Convert Message objects to dictionaries for JSON serialization
message_dicts = [asdict(msg) for msg in self.messages]
d = dict(session_id=self.session_id,
title=self.title,
messages=message_dicts,
usage=dict(
input_tokens=self.usage.input_tokens,
output_tokens=self.usage.output_tokens))
filename = f"{self.memory_dir}/{self.session_id}.json"
with open(filename, 'w') as f:
json.dump(d, f, indent=4)下面我们看一个保存后的 session。用户问当前目录是什么。LLM 返回一条 assistant 消息,其中请求运行 pwd 工具;pwd 返回当前目录。AI-6 框架正确执行了该工具,并把答案 "/Users/gigi/git/AI-6" 以 tool message 的形式发送给 LLM。然后 LLM 返回最终 assistant 消息:\n\nThe current directory is /Users/gigi/git/AI-6.。session 继续运行,用户又发了新问题,但这里我截断了。注意最后它统计了所有消息的输入与输出 token 总数:
swift
{
"session_id": "045d8889-d51b-4a48-bb3b-c97f9700af23",
"title": "Untiled session ~045d8889-d51b-4a48-bb3b-c97f9700af23",
"messages": [
{
"role": "user",
"content": "what's curr dir"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "tool_185f7ac72fb2404e95660d90964dc98f",
"type": "function",
"function": {
"name": "pwd",
"arguments": "{}"
}
}
],
"input_tokens": 551,
"output_tokens": 11
},
{
"role": "tool",
"name": "pwd",
"content": "/Users/gigi/git/AI-6",
"tool_call_id": "tool_185f7ac72fb2404e95660d90964dc98f"
},
{
"role": "assistant",
"content": "\n\nThe current directory is `/Users/gigi/git/AI-6`."
}
.
.
.
],
"usage": {
"input_tokens": 3068,
"output_tokens": 57
}
}load() 方法与 save() 相反:它接收 session ID,按命名约定定位对应 session 文件,把 JSON 读入 Python 字典,然后逐字段重建 Session 对象。为了把每条消息从 dict 转回 Message 对象(或其子类),它使用 dict_to_message() 函数:
python
def load(self, session_id: str):
"""Load session from disk, properly deserializing nested objects"""
filename = f"{self.memory_dir}/{session_id}.json"
with open(filename, 'r') as f:
d = json.load(f)
self.session_id = d['session_id']
self.title = d['title']
# Convert message dictionaries back to Message objects
self.messages = [dict_to_message(msg) for msg in d['messages']]
# Deserialize usage directly to a Usage object
self.usage = Usage(d['usage']['input_tokens'],
d['usage']['output_tokens'])session 如何承载不同类型的记忆
智能体循环中的短期记忆
在智能体循环中,AI-6 engine 可能会对 LLM 发起多次请求,并不断累积此前的所有消息。每一次工具请求以及工具执行后的响应都会加入当前 session,并在下一轮循环中作为上下文窗口的一部分对 LLM 可见。例如下面的交互:
- 用户:当前目录是什么?
- LLM(工具调用):pwd(打印工作目录)
- 用户:当前目录里有多少个 Python 文件?
- LLM(工具调用):ls *.py
- AI-6(工具调用响应):foo.py bar.py
- LLM(最终回复):当前目录里有两个 Python 文件
- 用户:它们是什么?
- LLM(最终回复):文件是 foo.py 和 bar.py
在每一步,LLM 收到的是整个对话,而不是只有最后一条消息。当用户问 "它们是什么?" 时,LLM 可以从对话历史推断出用户指的是当前目录里的 Python 文件,于是可以直接回答,而无需再次工具调用。
session 与对话连续性
当某个智能体循环结束并把最终回复返回给用户(或智能体应用)后,用户可以通过发送新的用户消息继续对话。新的用户消息会启动一个新的智能体循环,但上下文中包含当前 session 的所有历史消息。
长期记忆与 session 加载
我们已经看到 session 如何把自己保存/加载到文件中。但让这一切成为可能的机制是什么?这就轮到 session manager 出场了。session manager 定义在 engine/session_manager 文件中,它暴露三个方法来管理持久化 session:
list_sessions()delete_session()set_title()
当一个 AI-6 应用启动时,它可以调用 list_sessions() 查看所有已有 session,并决定加载一个已有 session 或删除旧 session;也可以为已有 session 设置标题。
我们看看 session manager 如何工作。它用 memory 目录初始化(session 文件就放在这里):
python
import os
import json
class SessionManager:
def __init__(self, memory_dir: str):
self.memory_dir = memory_dirset_title() 接收 session ID 与 title。它定位 session 文件(找不到则抛异常),把 JSON 读成 Python 字典,替换 title,然后写回文件。注意这里使用了一个不太常见的 seek → dump → truncate 写回序列:它是一种用单个文件句柄安全更新文件的做法,能降低"先截断文件再崩溃导致空文件"的风险。相反,如果你用 open(filename, 'w').write() 覆盖写入,而进程在 open 后立刻崩溃,就会留下一个空文件:
python
def set_title(self, session_id: str, title: str):
"""Set the title of a session."""
sessions = self.list_sessions()
if session_id not in sessions:
raise RuntimeError(f"Session {session_id} not found.")
filename = sessions[session_id]['filename']
with open(filename, 'r+') as f:
data = json.load(f)
data['title'] = title
f.seek(0)
json.dump(data, f, indent=4)
f.truncate()list_sessions() 会列出 memory 目录中所有 .json 文件,验证它们包含有效 JSON,然后返回一个字典:每个 session dictionary 里包含 title 与 filename。如果遇到问题,它只打印错误并继续处理下一个 session:
python
def list_sessions(self) -> list[dict]
"""List all sessions in the memory directory.
Returns:
A dictionary mapping session IDs to tuples of (name, filename)
"""
sessions = {}
files = os.listdir(self.memory_dir)
for f in files:
if f.endswith('.json'):
try:
# Get session ID from the filename (dropping the .json extension)
session_id = os.path.basename(f).rsplit('.json', 1)[0]
# Try to open and parse the file to verify it's valid JSON
full_path = os.path.join(self.memory_dir, f)
with open(full_path, 'r') as file:
try:
# Attempt to parse the JSON
session = json.loads(file.read())
# Only add if we could parse the JSON
sessions[session_id] = dict(
title=session['title'],
filename=full_path)
except json.JSONDecodeError:
# Skip files with invalid JSON
print(f"Skipping file with invalid JSON: {f}")
continue
except Exception as e:
# Skip any files that cause other errors
print(f"Error parsing session file {f}: {e}")
continue
return sessions删除 session 也很简单:列出 sessions、取文件名、删除文件:
python
def delete_session(self, session_id: str):
"""Delete a session by its ID."""
sessions = self.list_sessions()
if session_id not in sessions:
raise RuntimeError(f"Session {session_id} not found.")
filename = sessions[session_id]['filename']
os.remove(filename)session manager 能管理 sessions,但随着 session 变大,它们会逐渐塞满上下文。我们来理解这个问题以及如何处理它。
处理长上下文
智能体 AI 框架必须面对的最大问题之一,是管理上下文大小,使其适配模型的上下文窗口。智能体工作流可能在很长时间内跨越多次对 LLM 的请求,导致上下文越来越大。解决方案是在接近上限时压缩上下文。但问题是:该保留哪些上下文?LLM 在总结长文本方面非常擅长------那就让 LLM 来压缩上下文。这正是 summarizer 做的事。它实现在 engine/summarizer 文件中。我们看看它如何工作:它用一个 LLM provider 初始化:
python
from backend.object_model import (
Message, LLMProvider, SystemMessage, UserMessage)
class Summarizer:
"""Utility class for summarizing sessions using an LLM."""
def __init__(self, llm_provider: LLMProvider):
"""Initialize the summarizer with an LLM provider.
Args:
llm_provider: An LLM provider instance
"""
self.llm_provider = llm_providersummarize() 方法接收 message 列表与 model ID。它准备一段 system prompt,指示如何总结对话,然后把 session messages 格式化成一个包含每条 message 的 role 与 content 的长字符串(通过 _format_session()),再把 system message 与包含该字符串的 user message 一起发送给 provider,得到 session 的摘要。注意:这是直接对 provider 的一次 send() 调用,不涉及 session:
python
def summarize(self, messages: list[Message], model_id: str) -> str:
"""Summarize a list of messages using the LLM.
Args:
messages: List of message dictionaries to summarize
model_id: ID of the model to use for summarization
Returns:
A string summary of the session
"""
# Format messages for the LLM
formatted_messages = [
SystemMessage(
content=(
"You are a helpful assistant tasked with summarizing a conversation. "
"Create a concise summary that captures the key points, questions, decisions, and context "
"from the session. The summary should be informative enough that someone "
"reading it would understand what was discussed, what conclusions were reached, "
"and what important context should be carried forward. "
"Focus on preserving information that will be useful for continuing the conversation, "
"including names, technical terms, important numbers, and specific details that might "
"be referenced later. Avoid unnecessary details, repetitive information, or tangential discussions."
)
),
UserMessage(
content=(
"Please summarize the following session:\n\n" +
self._format_session(messages)
)
)
]
# Get summary from LLM
response = self.llm_provider.send(
formatted_messages, {}, model_id)
return response.content.strip()下面是 _format_session() 静态方法:把 message 列表拼成一段大字符串,包含每条消息的 role 与 content:
less
@staticmethod
@staticmethod
def _format_session(messages: list[Message]) -> str:
"""
Format a list of messages into a readable session.
Args:
messages: List of message dictionaries
Returns:
Formatted session string
"""
formatted = []
for msg in messages:
role = msg.role
content = msg.content
if role == "tool":
tool_name = getattr(msg, 'name', 'unknown tool')
formatted.append(f"Tool ({tool_name}): {content}")
else:
formatted.append(f"{role.capitalize()}: {content}")
return "\n\n".join(formatted)是否需要摘要的决策发生在 engine 的 _checkpoint_if_needed() 方法中。该方法会周期性保存 session,同时检查 session 的 token 总数(从 usage 对象获得)与上下文窗口大小的阈值对比。如果超过阈值,就触发摘要,并从此使用更短的"摘要后上下文"。
该方法定义如下:
python
def _checkpoint_if_needed(self):
"""Check if we need to save a checkpoint and do so if needed."""
self.message_count_since_checkpoint += 1
# Only save if we've reached the checkpoint interval exactly
if self.message_count_since_checkpoint == self.checkpoint_interval:
self.session.save()
self.message_count_since_checkpoint = 0
# Check and summarize if above token threshold (80% of context window)
total_tokens = (
self.session.usage.input_tokens + \
self.session.usage.output_tokens
)
if total_tokens >= self.token_threshold:
context_window_size = get_context_window_size(
self.default_model_id)
print(
f"Session tokens ({total_tokens}) have reached {self.summary_threshold_ratio * 100}% of context window ({context_window_size}). Summarizing..."
)
self._summarize_and_reset_session()注意:自动让 LLM 做摘要并不是压缩上下文窗口的唯一方式。其他方法包括:用 embedding 的语义检索只取最相关的历史轮次、基于规则的裁剪删除琐碎或重复对话、把事实与实体结构化存储以便按需注入、以及更省 token 的重编码技术(如 codebook、自定义速记格式或领域特定压缩方案)。
未来,AI-6 可能会演进到让记忆管理可扩展:当上下文窗口过大时,engine 不再直接调用 summarizer,而是以一个通用 context manager 初始化,由后者实现某种 compaction 方法。这会沿用 tools 与 LLM provider 的蓝图:engine 通过抽象接口与其他组件交互。具体来说,可以定义一个带 summarize() 方法的通用 ContextManager 接口,并由多个具体 context manager 实现;用户可配置选择最适合的 session 压缩方法。
总结
在本章中,我们了解到 AI-6 框架是一个健壮、可扩展的平台,旨在支持复杂的智能体 AI 系统。在极简的 k8s-ai 智能体基础上,AI-6 引入了模块化的后端架构,用于协调工具执行、记忆管理以及与多个 LLM provider 的通信。其核心是 Engine 类:它编排智能体循环,接收用户输入,按需调用工具,管理 session 历史,并通过统一的 provider 接口与 LLM 交互。配置通过一个简单的 Config 对象集中管理,允许用户定义工具、记忆目录、默认模型与行为参数。该系统被设计为"无立场"的,因此很容易在其之上构建更专用或更有立场的系统。
AI-6 的关键优势在于对 LLM provider 与工具的抽象。它既支持 OpenAI 这样的远程 provider,也支持 Ollama 这样的本地 provider,并通过统一接口处理消息格式化、工具集成与响应解析。工具本身通过一个轻量的 Python 接口定义,支持描述、类型化参数与执行逻辑。框架还通过细粒度工具定义、运行时护栏、基于 OS 权限或容器的沙箱,以及在必要时的人在回路控制,来安全管理工具使用。这为构建安全可靠、并能有效利用外部能力的 AI 系统打下了坚实基础。
记忆通过 session 这一概念管理:它封装所有交互历史与 token 使用情况。session 可以被保存、恢复、摘要与检查,并可由专门的 SessionManager 管理。当 session 变得过大时,内置摘要模块会用 LLM 压缩较早消息,同时保留关键上下文,从而保证 AI-6 能在长对话中运行而不超出模型限制。综合来看,这些能力构成了一个连贯、面向生产的框架,用于管理智能体行为、工具使用与 AI 系统中的长期记忆。
在下一章中,我们将看到如何为 AI-6 实现自定义工具,并尝试不同工具组合来完成有用任务。