为应对这些挑战,我们提出了 CUAJudge,一个用于评估 CUA(计算机使用代理)执行轨迹的可靠自动评估器。我们的设计基于 WebJudge(Xue 等人,2025)流程,该流程包含三个阶段:关键点识别、关键截图识别和结果判断。具体来说,关键点识别从任务描述中提取任务关键要求;关键截图识别从轨迹中选择信息丰富的截图;结果判断通过推理任务描述、关键点、关键截图和行动历史来确定任务完成情况。然而,WebJudge 主要针对网络任务,而网络任务可以被视为更广泛的计算机使用任务的一个子集。通常,计算机使用任务表现出显著更高的复杂性,需要更细致地检查内部系统和软件状态(例如,操作系统级或应用程序状态),而网络任务通常仅需验证表层效果,例如是否已应用特定过滤器。 相应地,CUAJudge 通过两项关键改进扩展了 WebJudge,以应对通用计算机使用任务的独特挑战并提高评估可靠性:
根据 Wei 等人 (2025c) 的研究,我们将群体相对策略优化 (GRPO) 算法 (Shao 等人,2024) 扩展到多轮设置中,通过将每条轨迹分解为一系列步骤级动作组,并联合优化它们。对于给定的任务 I ,我们在环境 {τ(i)}i=1G 中采样一组 G 轨迹。每条轨迹 τ(i)={(st(i),at(i))}t=1T(i) 由多个交互步骤组成,其中 st(i) 表示步骤 t 的观测值, at(i) 表示自回归生成的动作。我们通过最小化目标函数来优化策略

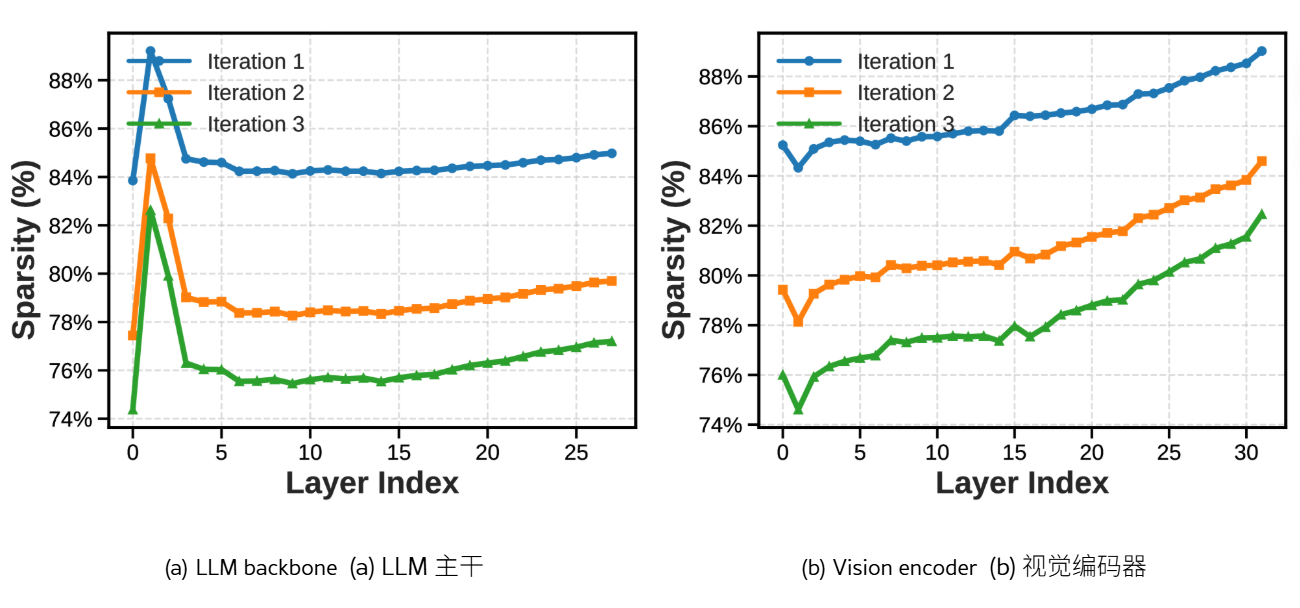
如图 2 所示,尽管稀疏性随着训练的进行逐渐降低,但 LLM 主干和视觉编码器整体上仍然高度稀疏,大约 80%的参数没有发生显著变化。这种高稀疏性有助于解释为什么智能体能够在目标环境中持续学习,同时在其他环境中基本保持性能。此外,这两个组件表现出不同的逐层模式:LLM 主干在中层和上层(第 3 层至第 27 层)保持相对均匀的稀疏性,而视觉编码器随着深度增加而变得越来越稀疏,表明更新主要集中在较低层。我们还观察到这两个模块的早期层存在显著差异。LLM 主干的头一到两层表现出异常高的稀疏性,而视觉编码器的第一层稀疏性则明显较低。这种不对称性表明,负责低级视觉感知的早期视觉层在新环境中需要更强的适应,而早期 LLM 层较少直接参与特定环境的感知或决策。
在这项工作中,我们提出了一种完全自主的课程强化学习框架(ACuRL),使计算机使用代理能够持续适应特定环境。我们的方法在零数据设置下进行,仅需目标环境本身。通过将任务生成基于累积的环境经验,并逐步调整任务难度以匹配代理不断发展的能力,我们的方法在目标环境中有效提高性能,同时保持对其他环境的泛化能力。在六个代表性环境中的实验表明,在环境内和环境间持续学习场景中均实现了持续改进,且没有灾难性遗忘。此外,我们的分析表明,这种适应是由高度稀疏的参数更新驱动的,揭示了代理如何在目标环境中持续学习的同时保持先前获得的能力。总体而言,这些结果表明我们提出的 ACuRL 方法为复杂计算机使用环境中的持续学习提供了一种可扩展且有效的范式。
Set up CPU server 设置 CPU 服务器
To ensure stable large-scale parallel execution, we recommend using a CPU server with at least 96 CPU cores and 384 GB RAM as the environment host. This configuration can reliably support up to 128 concurrent environments .
为确保稳定的大规模并行执行,我们建议使用至少拥有 96 个 CPU 核心和 384 GB RAM 的 CPU 服务器作为环境主机。此配置可以可靠地支持高达 128 个并发环境。
Please refer to this guideline for detailed instructions on how to set up the server.
请参考此指南以获取有关如何设置服务器的详细说明。
ACuRL consists of multiple stages: Environment Exploration , Context Review , Capability Evaluation , Curriculum Task Generation , and iterative RL training . The agent first interacts with the target environment to collect initial experience, then improves through iterative RL on curriculum tasks whose difficulty is tailored to the agent's current capability based on feedback from CUAJudge .
ACuRL 由多个阶段组成:环境探索、上下文审查、能力评估、课程任务生成和迭代 RL 训练。智能体首先与目标环境交互以收集初始经验,然后通过根据 CUAJudge 的反馈生成难度适合智能体当前能力的课程任务进行迭代 RL 训练来提升能力。
在论文 Autonomous Continual Learning of Computer-Use Agents for Environment Adaptation 中,研究团队主要采用了 UI-TARS-1.5-7B 作为计算机操作代理(Computer-Use Agent)的基础模型进行训练和环境适配。
为了实现自动化的持续学习闭环,该框架还协同使用了以下模型作为辅助:
- CUAJudge (自动评估器) :该组件内部集成了 Qwen3-VL-8B,主要用于在评估过程中识别关键屏幕截图。
- 结果评估 (Outcome Evaluation) :对于某些对格式要求极其敏感的任务,研究中使用了 GPT-5-mini 来判断任务最终执行是否成功,从而为模型提供反馈信号。
该研究的核心在于通过这种多模型协作的机制,让基于 UI-TARS 的代理能够在遇到未见过的数字化环境或分布偏移时,实现自主的持续演进和能力提升。
UI-TARS-1.5-7B 拥有非常强大的视觉能力。它本质上是一个原生 GUI 视觉语言模型(VLM)。
在 UI-TARS: Pioneering Automated GUI Interaction with Native Agents 这篇基础论文中明确指出,UI-TARS 与之前的代理模型最大的不同点在于:
- 纯视觉感知:它仅通过截屏(screenshots)作为输入来感知环境,不需要依赖 HTML 源码或辅助辅助功能树(Accessibility Tree)等文本信息。
- 端到端操作:它能够像人类一样直接在视觉界面上定位,并生成键盘和鼠标的操作指令。
- 模型基底:虽然它是一个 7B 规模的模型,但它针对图形用户界面(GUI)进行了深度优化,能够识别各种复杂的 UI 组件、图标以及它们之间的空间关系。
因此,在 Autonomous Continual Learning of Computer-Use Agents for Environment Adaptation 中,它正是利用这种视觉能力来观察不断变化的数字化环境,并结合强化学习来调整自己的操作策略,从而实现环境适配。