在分布式系统中,如何让多个节点就某个值达成一致 是一个核心难题。当一个节点说"选A",另一个节点说"选B",第三个节点宕机时,系统该如何决策?这就是分布式共识问题。
Raft算法作为Paxos的替代者,以其清晰的结构和易理解性成为现代分布式系统的首选。Etcd、Consul、Kubernetes等知名项目都基于Raft实现高可用。本文将带你深入理解Raft的核心原理,避开实现陷阱,掌握这一分布式系统基石。
一、为什么需要共识算法?
在单机系统中,决策是简单的------只有一个节点,所有操作都是确定的。但在分布式系统中,情况完全不同:
节点1:写入 X=100
节点2:写入 X=200
节点3:宕机问题来了:最终X的值应该是多少?如果没有共识机制,每个节点可能做出不同的决策,导致系统分裂和数据不一致。
共识算法解决的核心问题:
- 一致性:所有节点最终达成相同的决策
- 可用性:只要多数节点存活,系统就能继续工作
- 容错性:能够容忍部分节点故障(通常是少数节点,即N/2-1个)
在分布式数据库、配置中心、服务注册等场景中,共识算法是保证系统正确性的基石。
二、Paxos vs Raft:为什么Raft更受欢迎?
在Raft出现之前,Paxos 是分布式共识领域的"金标准"。但Paxos存在一个致命问题:难以理解和实现。
Paxos的复杂性
Paxos协议包含多个阶段(Prepare、Promise、Accept、Accepted),每个阶段都有复杂的条件判断和边界情况。即使是经验丰富的工程师,也很难在第一次阅读时完全理解其精妙之处,更不用说正确实现了。
Raft的设计哲学
Raft的设计者Diego Ongaro和John Ousterhout将可理解性作为首要目标,通过以下方式简化了共识算法:
- 角色分离:将共识问题分解为三个独立子问题------Leader选举、日志复制、安全性
- 强Leader模型:所有写操作必须通过Leader,简化了决策流程
- 清晰的状态转换:每个节点只有三种明确状态(Follower、Candidate、Leader)
- 任期(Term)概念:用单调递增的任期号替代Paxos中复杂的提案编号
Raft不是比Paxos更强大,而是更容易理解和正确实现。 这使得它成为工业界的实际标准。
三、Raft核心机制:三步走战略
Raft协议的核心可以概括为三个部分:Leader选举 、日志复制 、安全性保证。
1. Leader选举:谁来做决策?
Raft采用心跳机制来维持Leader的存在和权威:
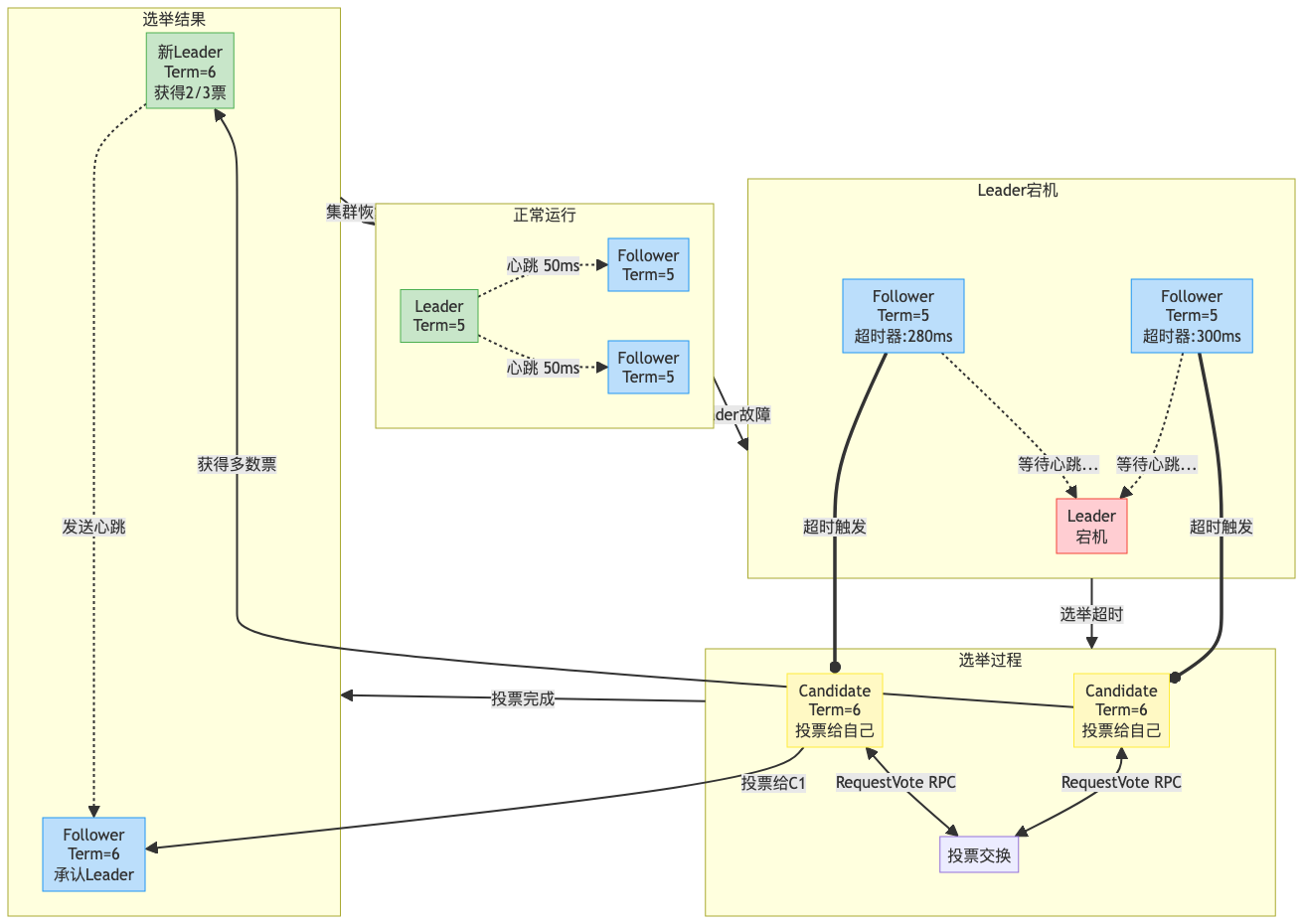
选举关键规则:
- 随机超时:每个Follower的选举超时时间随机化(通常150-300毫秒),避免同时发起选举
- 任期递增:每次选举开始时,Candidate将自己的任期号+1
- 一任期一票:每个节点在一个任期内只能投一票
- 多数派胜出:获得超过半数节点投票的Candidate成为Leader
- 心跳维持:Leader定期发送心跳(通常10-50毫秒),重置Follower的选举计时器
2. 日志复制:如何保证数据一致?
Leader选举完成后,所有客户端写请求都发送给Leader。Leader负责将日志安全地复制到集群:
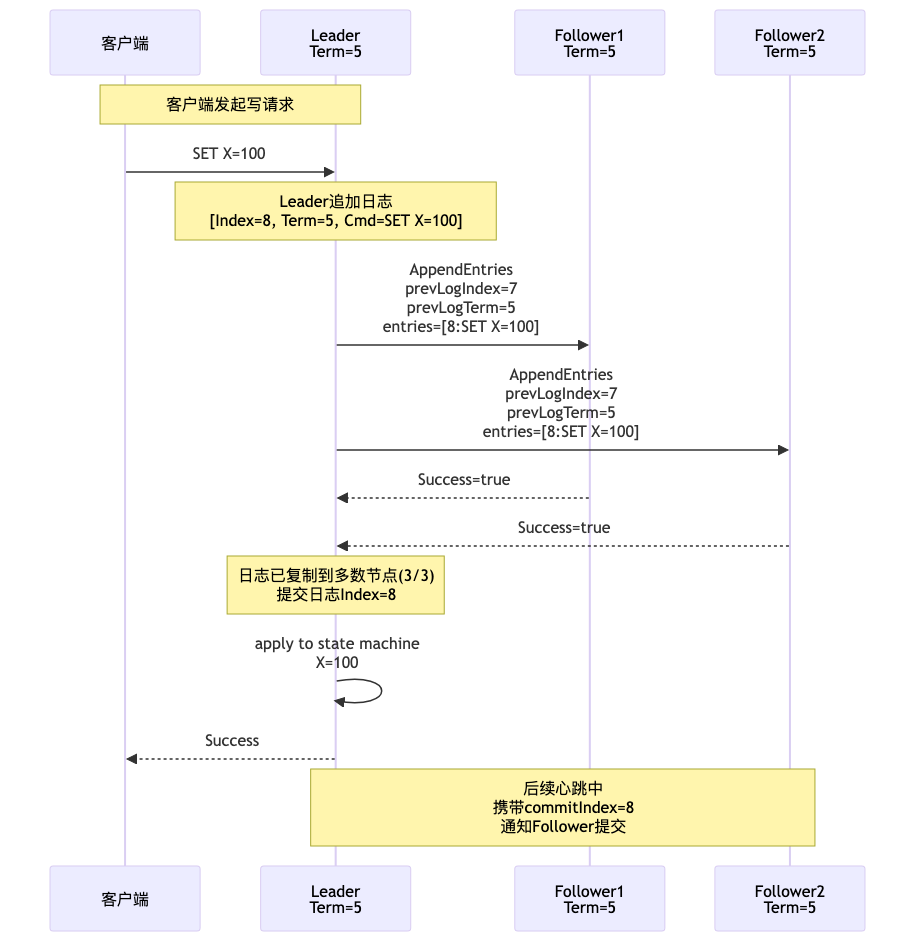
日志复制的关键机制:
- 日志结构:每条日志包含任期号(Term)、索引(Index)、命令(Command)
- 一致性检查:AppendEntries请求必须包含前一条日志的Term和Index,确保日志连续性
- 冲突处理:如果Follower发现prevLogTerm或prevLogIndex不匹配,返回失败;Leader递减nextIndex重试,直到找到匹配点
- 提交条件:当日志条目被复制到多数节点后,Leader才能提交该日志(更新commitIndex)
- 状态机应用:提交后的日志按顺序应用到状态机,保证所有节点状态一致
3. 安全性保证:为什么Raft是正确的?
Raft通过以下核心规则保证安全性,确保系统不会出现数据不一致:
规则一:选举限制
- Candidate只能获得日志"至少和自己一样新"的节点的投票
- 判断标准:比较最后一个日志条目的Term,Term大的更新;Term相同则Index大的更新
- 效果:保证新Leader包含所有已提交的日志
规则二:Leader完整性
- 如果一个日志条目在某个任期被提交,那么在后续任期中,该日志必须存在于所有Leader中
- 效果:已提交的日志永远不会被覆盖或丢失
规则三:状态机安全
- 如果一个服务器已经将某个日志条目应用到状态机,那么其他服务器不能在同一索引位置应用不同的命令
- 效果:所有节点的状态机最终状态完全一致
四、Raft集群状态转换全景图
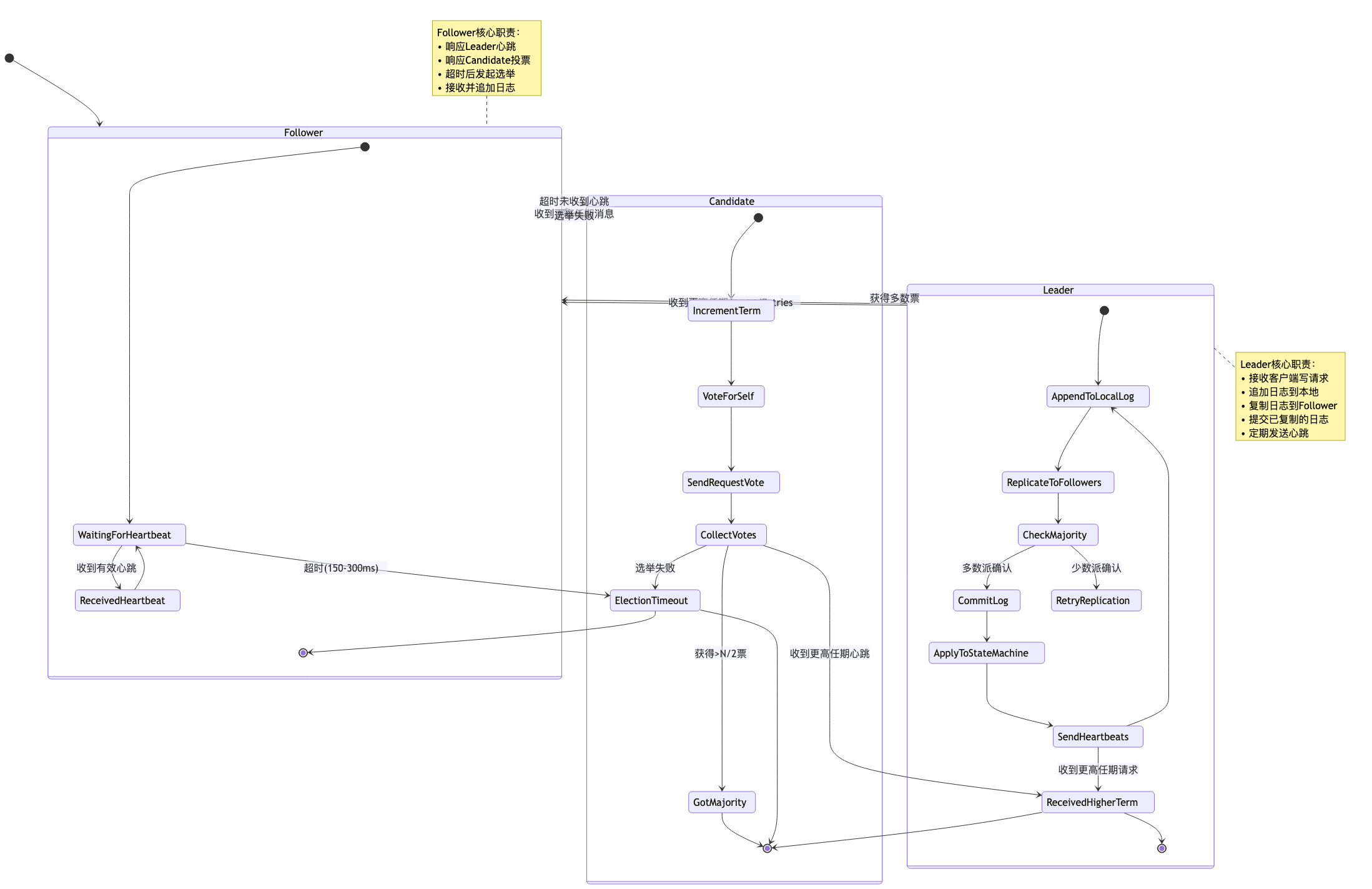
五、常见陷阱与避坑指南
1. 脑裂问题(Split Brain)
问题:网络分区导致集群分裂成两个子集,各自选举出Leader。
解决方案:
- 多数派原则:只有获得超过半数节点投票的Candidate才能成为Leader,网络分区后只有一个分区能获得多数票
- 任期号机制:当网络恢复时,低任期号的Leader收到高任期号的心跳后自动降级为Follower
2. 日志不一致恢复
问题:节点宕机重启后,其日志可能落后或包含未提交的"脏日志"。
解决方案:
- 日志匹配机制:Leader通过递减nextIndex不断尝试,直到找到与Follower匹配的日志位置
- 强制覆盖:匹配点之后的所有日志都被Leader的日志覆盖,确保一致性
- 提交安全规则:Leader只能提交当前任期的日志,避免提交前任未完全复制的日志
3. 选举风暴
问题:多个Follower同时超时,导致频繁选举,系统无法稳定。
解决方案:
- 随机化超时:每个节点的选举超时在基础值上增加随机偏移(如150-300毫秒)
- 快速降级:收到有效心跳或更高任期消息时,立即重置计时器并转为Follower
六、应用场景:Raft在现代系统中的实践
1. Etcd
Etcd是CoreOS开发的分布式键值存储,完全基于Raft实现。它是Kubernetes的核心组件,用于存储集群的全部状态信息。
Etcd 作为《微服务》第三篇的服务注册中心,其高可用依赖 Raft 共识。
2. Consul
HashiCorp的Consul使用Raft维护服务目录的一致性,确保服务发现的准确性。
3. Kubernetes
Kubernetes的控制平面依赖etcd(Raft)存储集群状态,API Server通过Raft保证配置变更的一致性。
4. 其他应用
- CockroachDB:分布式SQL数据库,使用Raft复制数据
- TiKV:分布式KV存储,Raft用于Region级别的数据复制
- ZooKeeper:虽使用ZAB协议,但思想与Raft相似
七、总结
Raft算法通过清晰的角色分离和状态转换,将复杂的分布式共识问题分解为可理解、可实现的子问题:
- Leader选举:通过心跳和随机超时机制选出唯一Leader
- 日志复制:Leader将日志复制到多数节点后安全提交
- 安全性保证:通过选举限制、Leader完整性等规则确保正确性
Raft的核心价值:
- 强Leader模型:简化写入路径和决策流程
- 多数派原则:在可用性和一致性之间取得平衡
- 日志匹配机制:优雅处理节点故障和网络分区
掌握Raft不仅是理解分布式系统理论的关键,更是设计高可用、高可靠分布式应用的必备基础。在后续文章中,我们将继续深入分布式事务、分布式锁等更贴近工程实践的主题。