前言:
文件系统是操作系统管理存储的核心机制,却常常被开发者视为"黑盒"。本文将从磁盘硬件原理出发,深入浅出地剖析 Linux 中经典的ext 文件系统如何组织数据、管理文件,并揭示inode、块、软硬链接等关键概念的底层实现。通过理解这些机制,你不仅能更高效地使用文件系统,还能在调试、优化乃至数据恢复时多一份底气。让我们一起揭开文件系统的神秘面纱!
文章目录
- 一、硬件理解
-
- [1.1 磁盘物理结构](#1.1 磁盘物理结构)
- [1.2 磁盘的逻辑结构](#1.2 磁盘的逻辑结构)
- 二、Ext文件系统
-
- [2.1 文件属性与分区](#2.1 文件属性与分区)
- [2.2 组管理字段](#2.2 组管理字段)
- [2.3 inode编号查询文件](#2.3 inode编号查询文件)
- [2.4 路径缓存(目录树)](#2.4 路径缓存(目录树))
- [2.5 inode与Data Blocks的映射](#2.5 inode与Data Blocks的映射)
- [2.6 文件结构图解](#2.6 文件结构图解)
- 三、软硬连接原理
-
- [3.1 软连接](#3.1 软连接)
- [3.2 硬链接](#3.2 硬链接)
一、硬件理解
文件存储通常位于计算机硬盘上,属于一种"永久性"存储,硬盘有固态硬盘(SSD)和机械硬盘(HDD) 。固态硬盘是电子设备,机械硬盘是计算机中唯一的机械设备。
固态硬盘:

机械硬盘:

本章节我们通过机械硬盘(磁盘)来理解文件系统的运作。
为什么磁盘可以做存储?底层理论支持:我们存储数据本质是存储二进制,即0或1。我们都知道高低电频可以表示1,0,但不足以持久化存储,而 磁铁分为南北极,具有二值性,就可以表示0和1。
磁铁分为南北极,具有二值性,就可以表示0和1。
- 存数据:通过电信号产生磁场,改变磁性材料的磁性颗粒特定方向,即电 → 磁 → 材料磁化方向改变。
- 取数据: 通过磁化区改变电阻变化,从而影响电流大小,即磁 → 电阻变化 → 电信号 。
1.1 磁盘物理结构
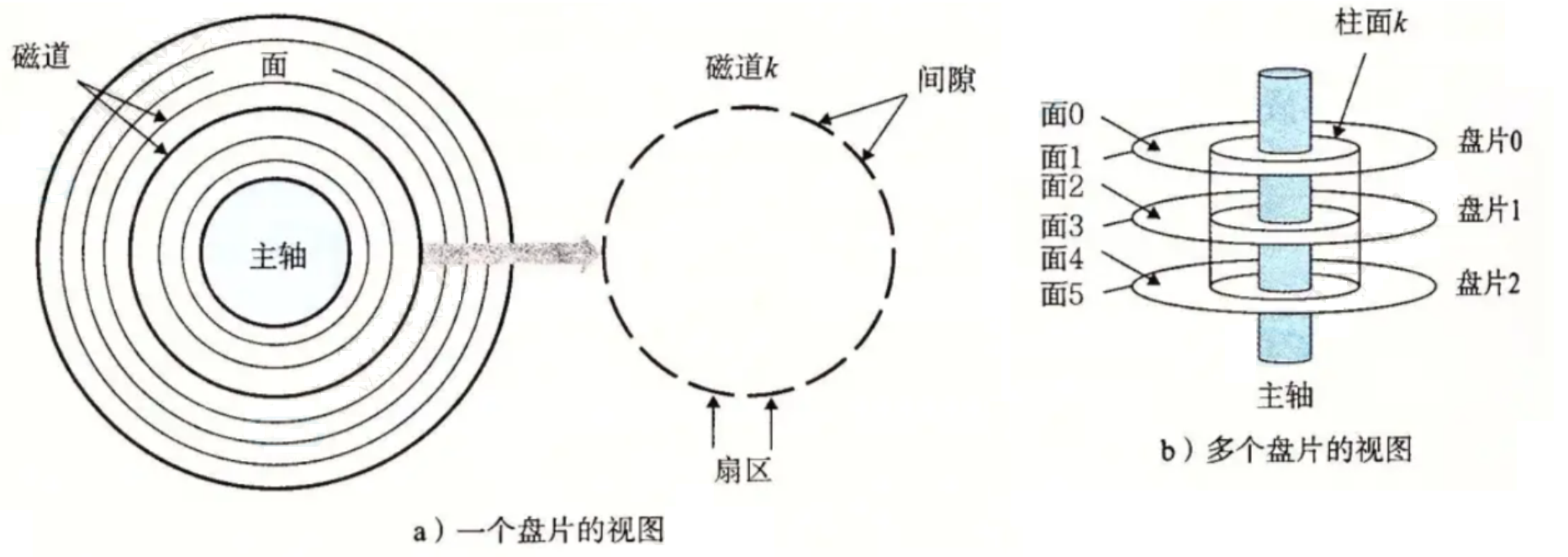
磁盘读写:
扇区是从磁盘读出和写入信息的最⼩单位,通常⼤⼩为 512 字节。
- 磁头(head)数:每个盘⽚⼀般有上下两⾯,分别对应1个磁头,共2个磁头
- 磁道(track)数:磁道是从盘⽚外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁头,不存储数据。
- 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数。
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同。 圆盘(platter)数:就是盘⽚的数量。
- 磁盘容量=磁头数×磁道(柱⾯)数×每道扇区数×每扇区字节数。
可以看出来扇区是磁盘存储的最小单位,那么怎么找到一个扇区呢?首先找到柱面,然后确定磁头,最后在定位扇区,即 CHS 寻址。
- 细节1:传动臂上的磁头是共进退的。
- 细节2:盘面是一个同心圆,所以不同磁道的周长是不同的,但是磁道上的扇区个数是相同的,本质是通过让外圈扇区的物理长度更大、内圈更小来实现。一定程度上造成了浪费,而现代有了ZBR技术,不同磁道扇区个数不同。但本文以早期磁道中扇区数量相同的情况为基础进行学习研究,最终目的是理解Linux文件系统的逻辑结构。
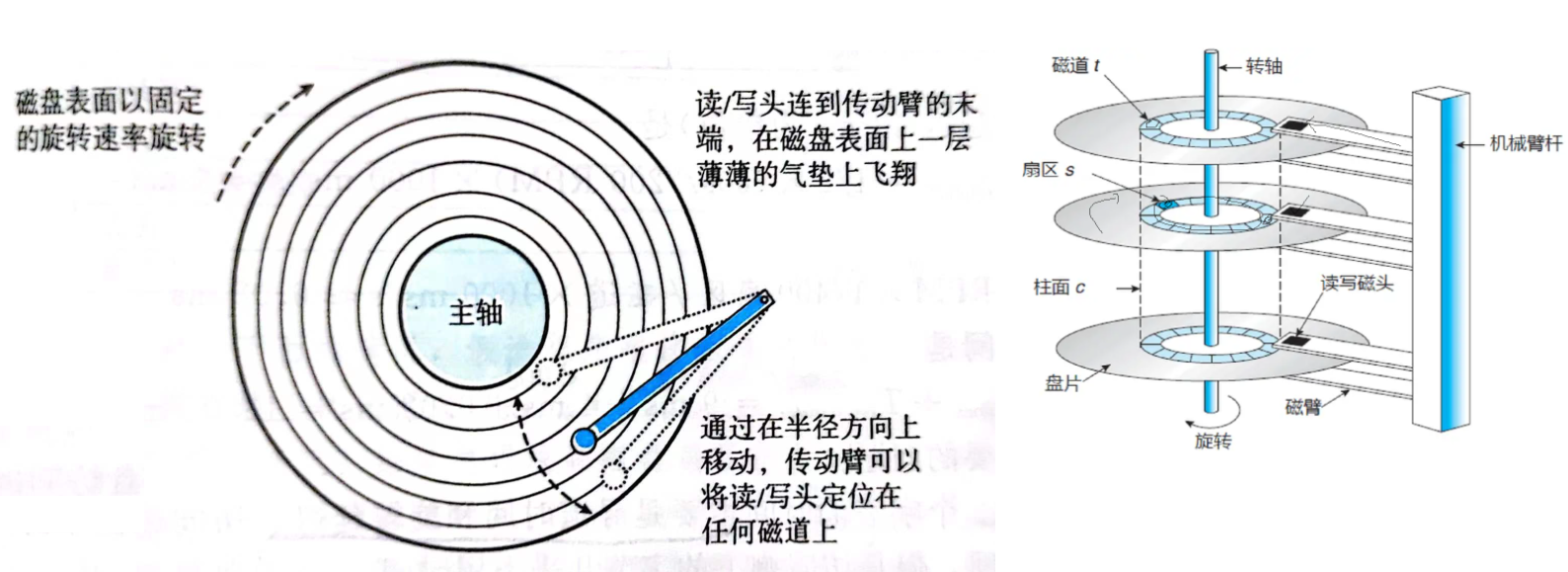
1.2 磁盘的逻辑结构

一个磁道可以看做事一个一维数组:

一个柱面就是一个二维数组:
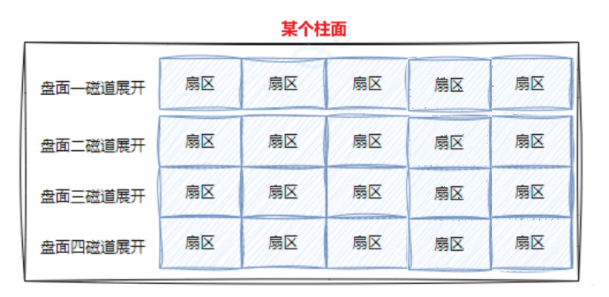
多个盘片就是三维数组:
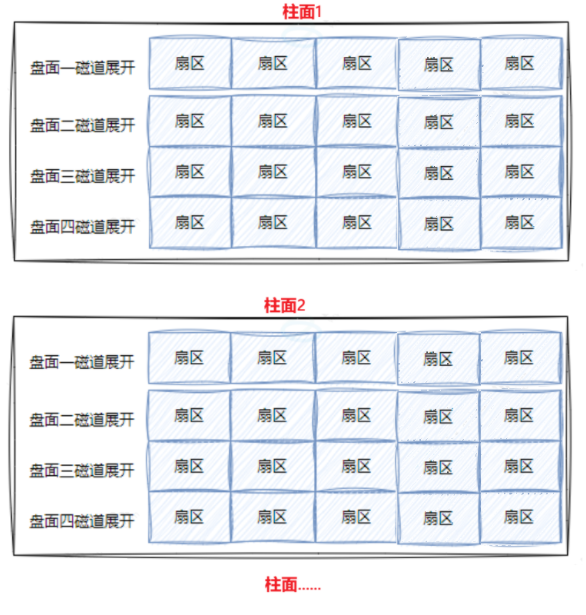
学过c语言都知道,无论是1维,2维,3维...数组,在底层本质就是一个一维数组,如下:

而每块扇区就都有自己的地址,这就是LBA地址,OS要对磁盘进行操作只需要知道LBA地址即可,那么CHS如何与LBA互相转换呢?
CHS转成LBA:
- 磁头数x每磁道扇区数=单个柱⾯的扇区总数
- LBA=柱⾯号Cx单个柱⾯的扇区总数+磁头号H*每磁道扇区数+扇区号S-1
- 即:LBA=柱⾯号Cx(磁头数x每磁道扇区数)+磁头号H*每磁道扇区数+扇区号S-1
- 扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的。
- 柱⾯和磁道都是从0开始编号的。
- 总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS:
- 柱⾯号C=LBA//(磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】。(注:"//"表⽰除取整)
- 磁头号H=(LBA%(磁头数*每磁道扇区数))//每磁道扇区数
- 扇区号S=(LBA%每磁道扇区数)+1
所以在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰转换。从现在开始,磁盘就是⼀个元素为扇区的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS就可以⽤⼀个数字访问磁盘扇区了。
二、Ext文件系统
2.1 文件属性与分区
操作系统在对磁盘操作时并不是以扇区为单位进行存取的,这样效率太低。而是以"块"为单位进行操作,一个"块"的⼤⼩是由格式化的时候确定的,并且不可以更改,最常⻅的是4KB(8x512),即连续⼋个扇区组成⼀个"块"。"块"是⽂件存取的最⼩单位。
-
注:使用块的第二点好处:让系统与磁盘硬件解耦,使得系统可以适配不同的配置硬件。
-
注:缓存意义还有硬件上的考量,没有缓存的话磁盘随机读写个数太多,IO效率太低。
-
块号=LBA/8;

文件信息获取:
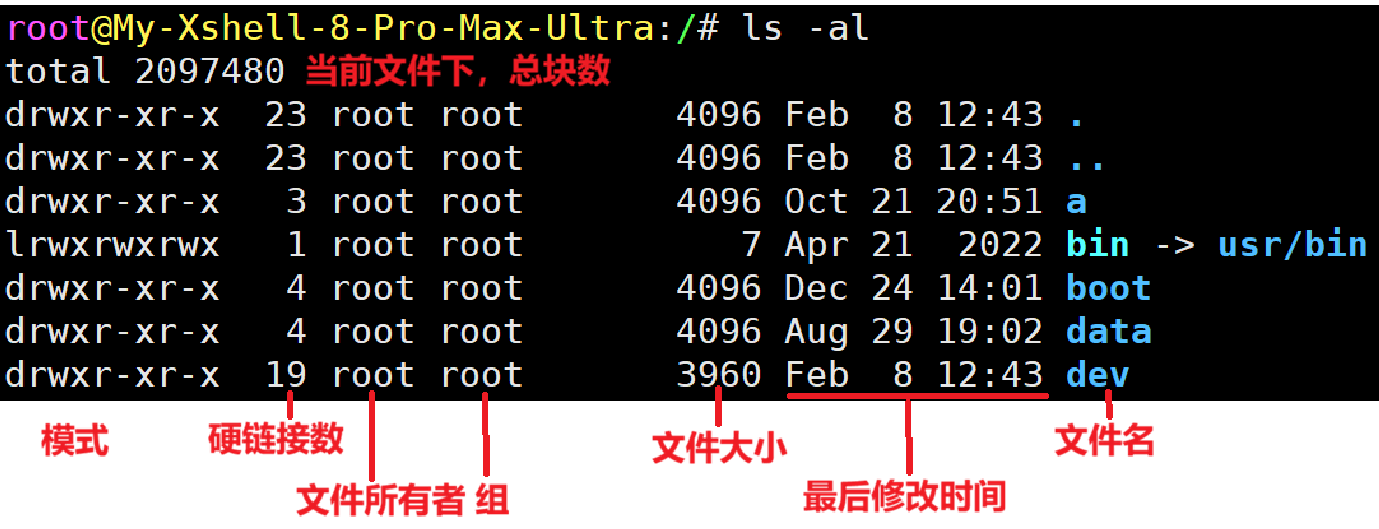
更详细的文件信息:
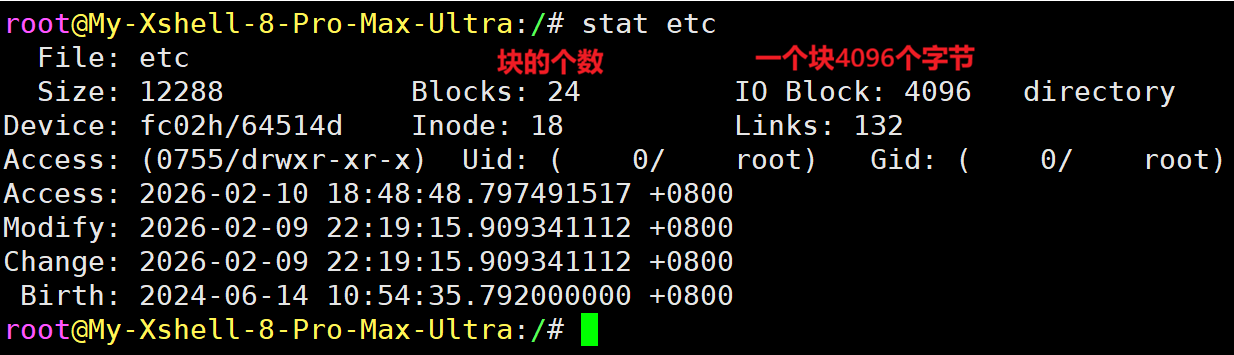
文件=属性+内容。属性也就是元信息,以上两个指令获取到的就是文件元信息。文件元信息和文件内容是分开存储的,而元信息里就有文件内容存储地址信息,所以通过找到元信息就能找到文件内容。
元信息的区域就叫做inode,中⽂译名为"索引节点"。每⼀个⽂件都有对应的inode,inode内有唯一的表示符inode号。
ls指令提交-i选项可以查看

- 注1:⽂件名属性并未纳⼊到inode数据结构内部。文件名是字符串,有大有小,会导致inode结构大小浮动不方便管理(把文件名保存字段空间设大一些会导致浪费),也有其他原因。关于文件名的保存在后文在谈。
- 注2:inode的⼤⼩⼀般是128字节256,我们后⾯统⼀128字节。
- 注3:任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的(Linux中任何时间都要有自己的属性集合)。
- 注4:文件属性本质是一个结构体,只要是结构体大小就是固定的(通常是128字节)。这个结构体是inode。
要在硬盘上储⽂件,必须先把硬盘格式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。在Linux系统中,其早期⽂件系统版本为ext2,后来⼜发展出ext3和ext4。ext3和ext4虽然对ext2进⾏了增强,但是其核⼼设计并没有发⽣变化,我们仍是以较⽼的ext2作为演⽰对象。
对磁盘的管理类似分治的思想,磁盘可以分为多个区,如Windows系统上的C、D、E盘等。从而实现逻辑上的隔离和解耦。linux系统上,柱面是最小的分区单位。(完成分区,分组,只需要存储其实记录起始块,结束块等。)
2.2 组管理字段
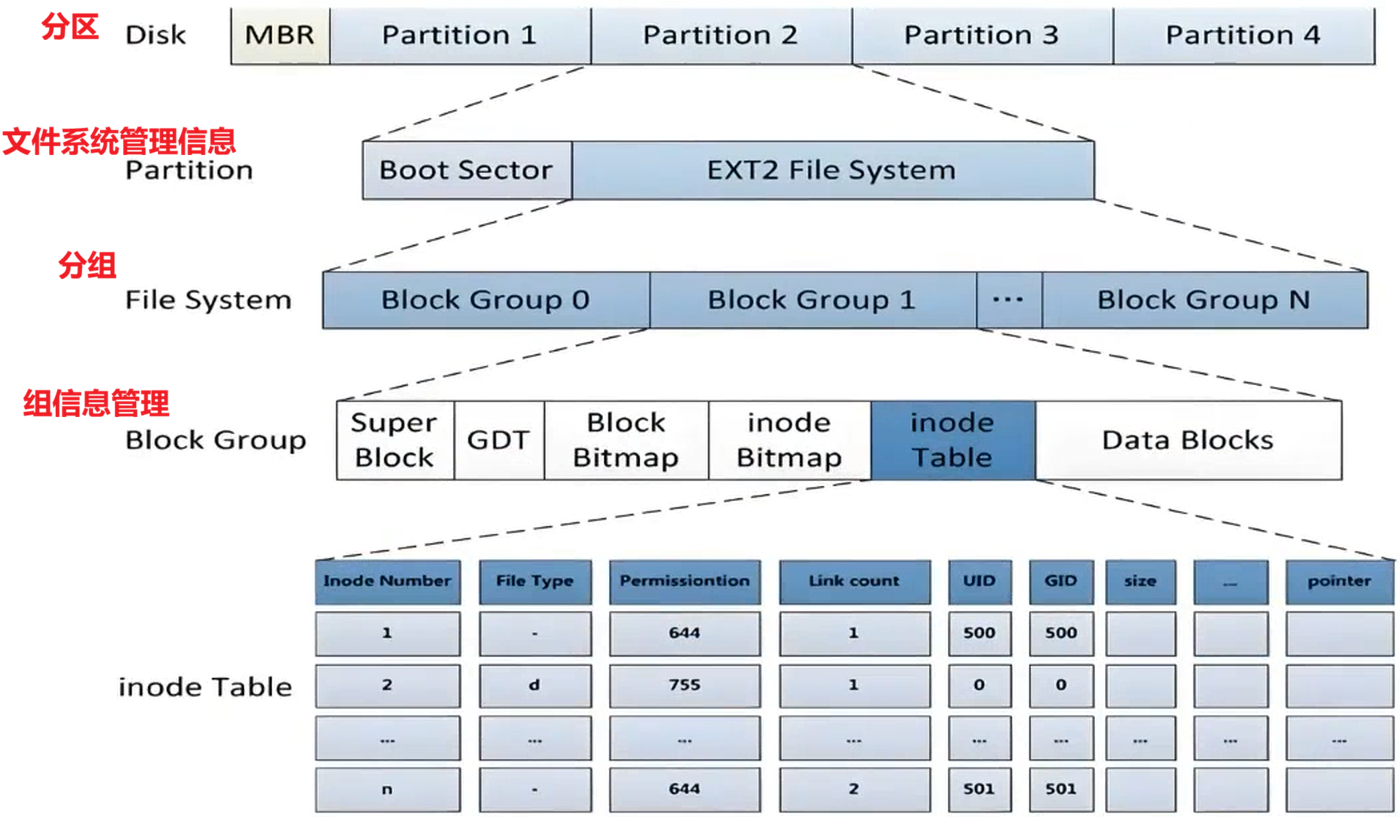
Data Blocks:无数个块组成,用来存放文件内容。inodeTable:里面存放文件属性,包括inode编号(inode Number)、文件类型(type)、权限信息(Permissions),大小(size)等等。
注:文件系统以分区为单位,不同的分区可以用不同的文件系统管理。
文件属性在inode Table中保存。同样是4KB的数据块,但inode通常只有128字节,那么一个数据块可以保存32个inode。那么OS交互是4KB为单位,所以获取一个文件属性时会它周围32个inode文件属性读到内存里,这样也是有一些好处的,根据局部原理,相近位置文件它们相关性大。
文件仅有内容+属性不够,还要管理,在存数据时总不能在Data Blocks里面一个一个区找没有被占用吧?
Block Bitmap:是一张位图,记录Data Blocks中的块是否被占用(1表示该块已经被用,0表示没有被用)。这里面的数据也是以块为单位的,1个比特位可以表示1个块的使用情况,1个字节就能表示8个块,那么1个块(4096字节)就能表示Data Blocks里32,768块的占情况。
同理的inode Bitmap也是一样的功能:
inode Bitmap:是一张位图,记录inode Table中各inode是否被使用。
我们在使用电脑时通常会发现下载一个文件特别慢,但删除特别快,还可以放在回收站然后恢复(或者用其他方式做数据恢复)。本质上删除文件不需要删属性和内容,只需要把位图清0,恢复本质也是把位图置1。如果把文件误删,其实短时间内在底层数据在,可以恢复。但如果在做各种操作可能原来位置数据会被覆盖,所以误删文件最好什么也不要做。
这一点类似c语言上的指针,将指针指向的内存释放,指针还指向原来地址,而且原来地址上的内容还在,只不过在后续操作中可能被其他信息覆盖,该指针也变成了野指针。其本质也是在修改内存区域把bit位置0。
一个组里inode Table有多大?Data Blocks有多大?两个位图分别有多大?哪块区域属于inode Table?哪块区域是Data Blocks...
GDT:是块组描述符,记录了各块区域的起始地址、结束地址等等。
我们怎么知道它是什么文件系统?怎么知道组的数量?总不能一个组一个组去找是否有空闲的inode和块吧...
Super Block:记录它是那种文件系统、文件系统版本号、总块数和inode数、空闲的块和inode数、inode起始地址、组数量等。Super Block字段的大小是固定的。
注意:每个组的相关信息都是有Super Block统一定义的。每个组内的块数,inode数,块大小都是相同且固定的。
格式化操作本质是将Super Block初始化,将所以位图清0,将管理信息写入每个组的相关字段里面。
注意:理论上一个分区或者说一个文件系统,只需要一个Super Block,但并不是只有一个,也不是所有组都有,只有个别结构组有Super Block字段(所有Super Block信息一模一样),它的起到一个备份的作用,Super Block坏了,这个文件系统就全废了。这样做的好处在于一个Super Block坏了用其他的恢复。
2.3 inode编号查询文件
组与组之间的inode编号会冲突吗?事实上,inode和数据块是跨组的。组之间inode编号不能重。但inode不能跨分区,分区已经是不同文件系统了。所以inode在分区内是唯一的。
怎么通过inode找到它的组,以及相关的inode Bitmap?通过Super可以知道组中inode的个数,比如为w(所有组的),那么组号=inode编号/w ,inode Bitmap(或确定在组里第几个inode)=inode编号%w。
注:计算机开机后就把磁盘上文件系统的Super和组相关管理信息加载到内存里。
怎么看待目录?文件名为什么不保存在文件属性里那么保存在哪?我们通常用的都是文件名找文件,怎么从来没有用过inode编号?
目录本质也是文件,和普通文件的保存是一样的,不同点在于目录文件的内容 是目录内部文件的文件名和它的inode编号的映射(互为键值)。所以我们在目录下通过文件名就能找到相关的文件内容。那么怎么找到目录呢?同理目录本质也是文件,它的文件名和inode编号映射关系存储在上级目录里。
所以要找到一个文件,就必须知道它的路径,为什么我们平时打开文件时没有写路径也能找到呢?我们在系统上每一个操作都是一个进程,文件的路径进程已经为我们提供,用户只需要提供文件名。
这里还有一个逻辑漏洞,我们知道怎么通过inode编号找到文件了,但首先得知道它在那个分区啊!
分区制作示例:
shell
dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分区
mkfs.ext4 disk.img # 格式化写⼊⽂件系统
mkdir /mnt/mydisk # 建⽴空⽬录
sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的⽬录
sudo umount /mnt/mydisk #卸载分区首先我们需要从磁盘获取一块空间然后将它格式化,此时还不能访问和直接使用分区,必须将它挂载到一个目录下才行。所以问题就迎刃而解了,所以访问这个目录就是在访问这个分区。其次dentry里面可以判断分区。
本质上磁盘上没目录结构,目录结构是内存级的,是操作系统为方便管理所做出的逻辑结构。
2.4 路径缓存(目录树)
所有文件都要从根目录上路径解析吗?路径解析本质做磁盘IO操作,效率会不会太低了?是的效率很低了!操作系统在做路径解析时,会把历史访问的目录逐步形成目录树(多叉树),即路径缓存。
验证方法:打开终端,在整个文件系统上搜索一个文件,比如查找test.c
bash
find / -name test.c第一次查找,非常慢,因为在做IO操作。
再次查找:
bash
find / -name test.c再次查找特别快,因为在第一次查找就在内存上构成了目录树,在能找到的前提下不用去访问磁盘了。
struct dentry 结构就是用来做路径缓存的,它既属于多叉树,又是淘汰链表,还是哈希。
注意:普通文件也要加载到树里面,即叶子节点。
linux-2.6.18版本内核源码:
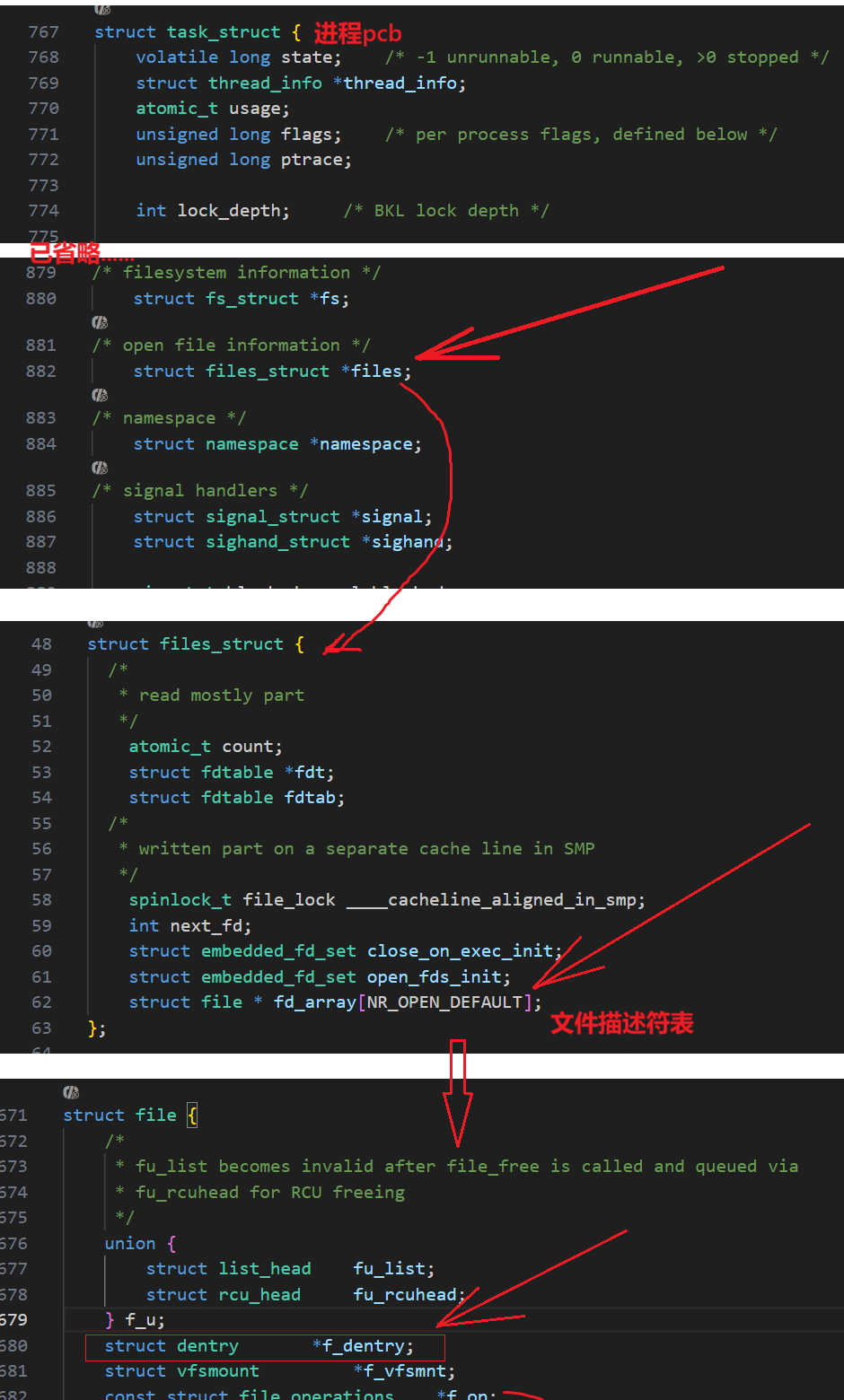
struct dentry结构源码:
c
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};struct hlist_node d_hash:哈希表用来快速查询struct list_head d_lru:淘汰链表,用于内存回收struct dentry *d_parent;// 指向父目录
struct list_head d_subdirs;// 子目录/文件链表头
union { struct list_head d_child; ... } d_u;
:多叉树,用来构建目录树。struct inode *d_inode:inode结构的地址。
struct inode部分源码:
c
struct inode {
struct hlist_node i_hash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
umode_t i_mode;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
unsigned int i_blkbits;
unsigned long i_blksize;
unsigned long i_version;
blkcnt_t i_blocks;
unsigned short i_bytes;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
struct mutex i_mutex;
struct rw_semaphore i_alloc_sem;
struct inode_operations *i_op;
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
//......
};2.5 inode与Data Blocks的映射
文件属性的inode结构里存储了一个数组,存储了文件内容相关的块地址:
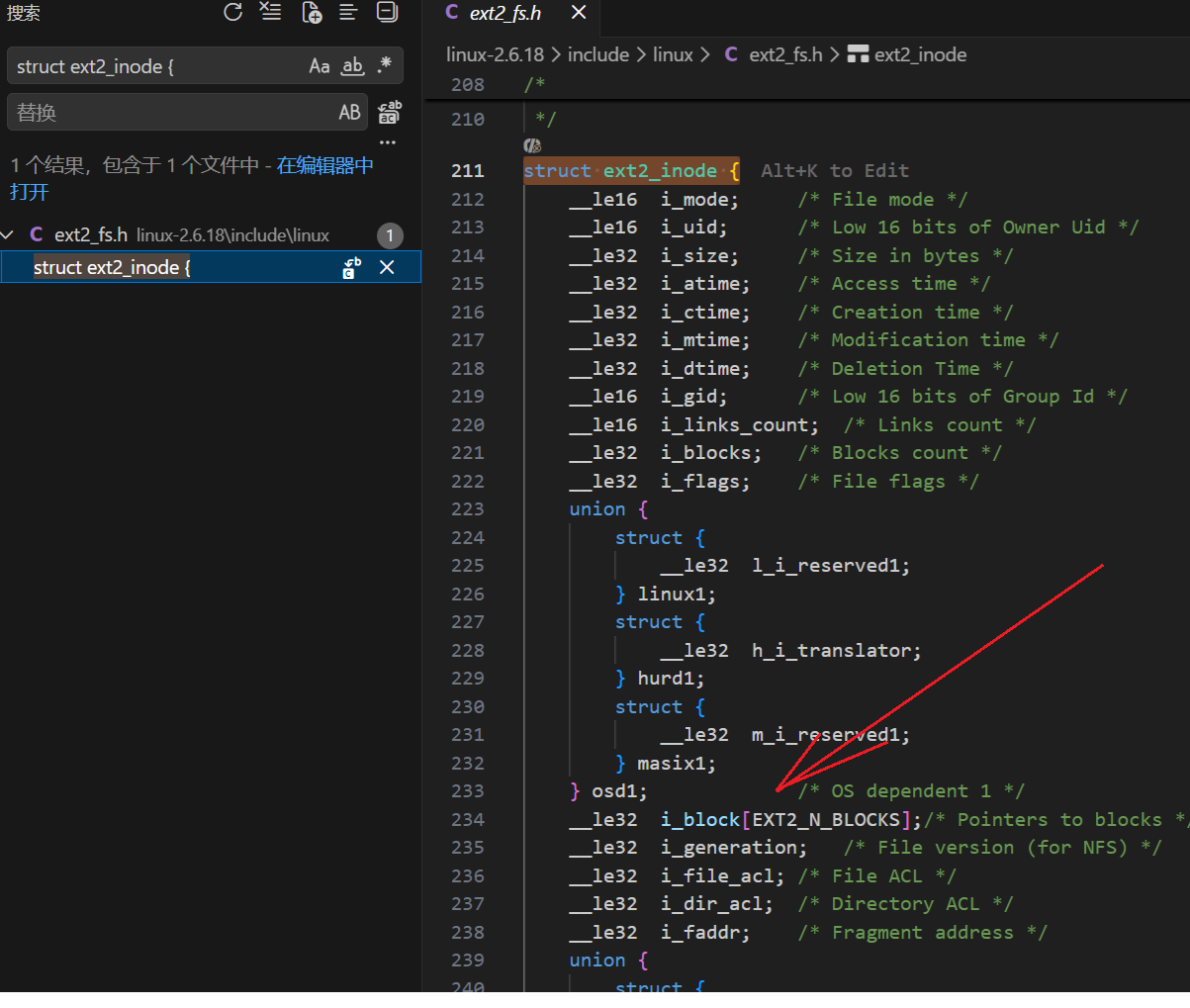
这里struct inode 是 VFS 层的通用 inode 结构,所有文件系统(ext4、xfs、btrfs 等)共用;struct ext2_inode 是 磁盘上 ext2/ext3/ext4 文件系统的原始 inode 格式,是磁盘数据结构;内核在内存中使用 struct inode,挂载时从磁盘读取 struct ext2_inode 并转换填充到 struct inode 中。
注:这里的EXT2_N_BLOCKS被#define定义为15
可以发现是15个元素是不是太少了怎么够存,其实内部存在分级索引 。前12直接索引,后面的是一级,二级、三级索引。而索引容量关键在于三级索引。
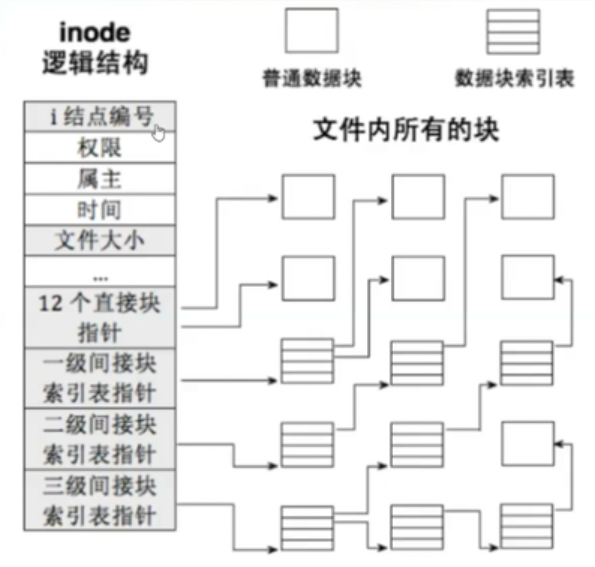
如果文件非常大,Data Block存不下该怎么办,文件内容可以跨组保存 。如果内容还是存不下可以分布式多主机存储。
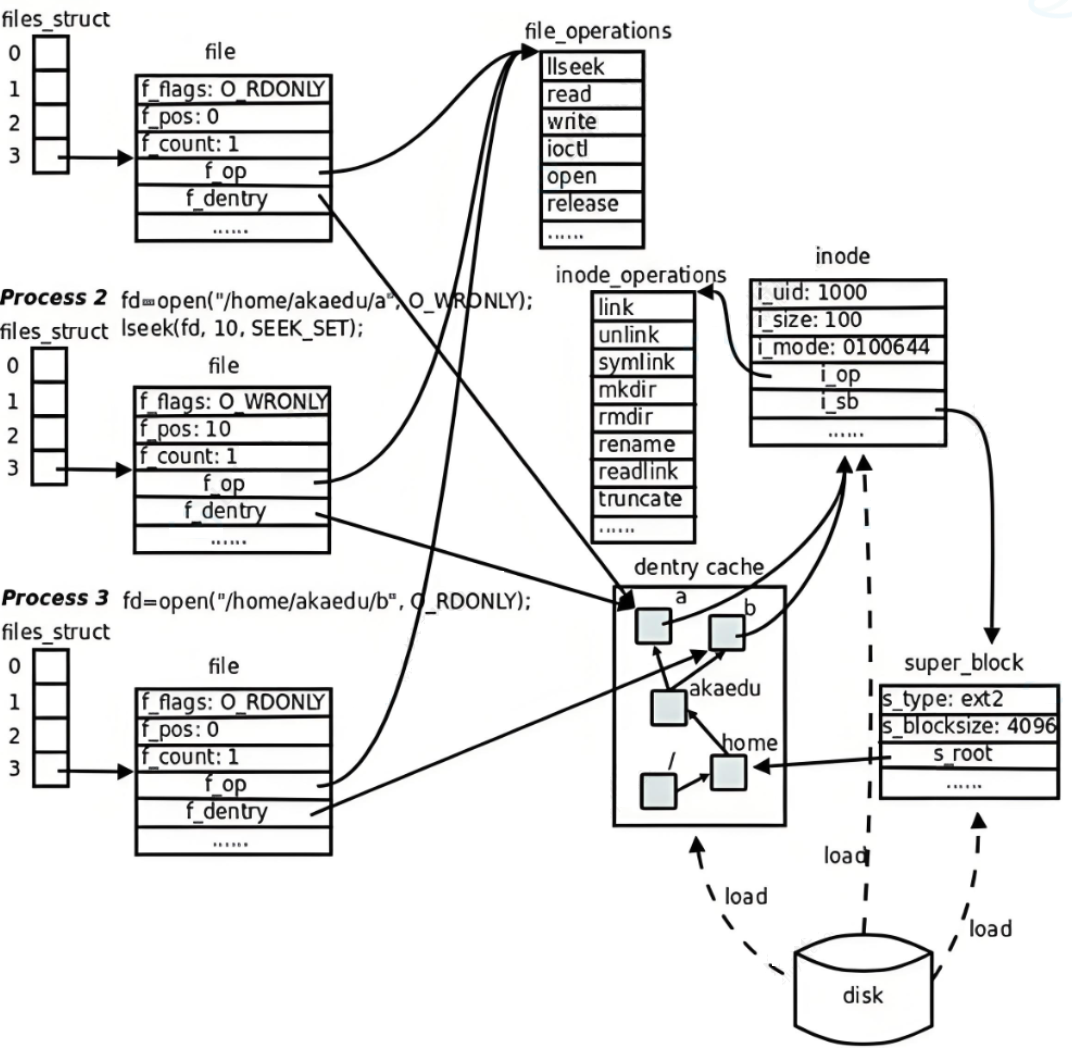
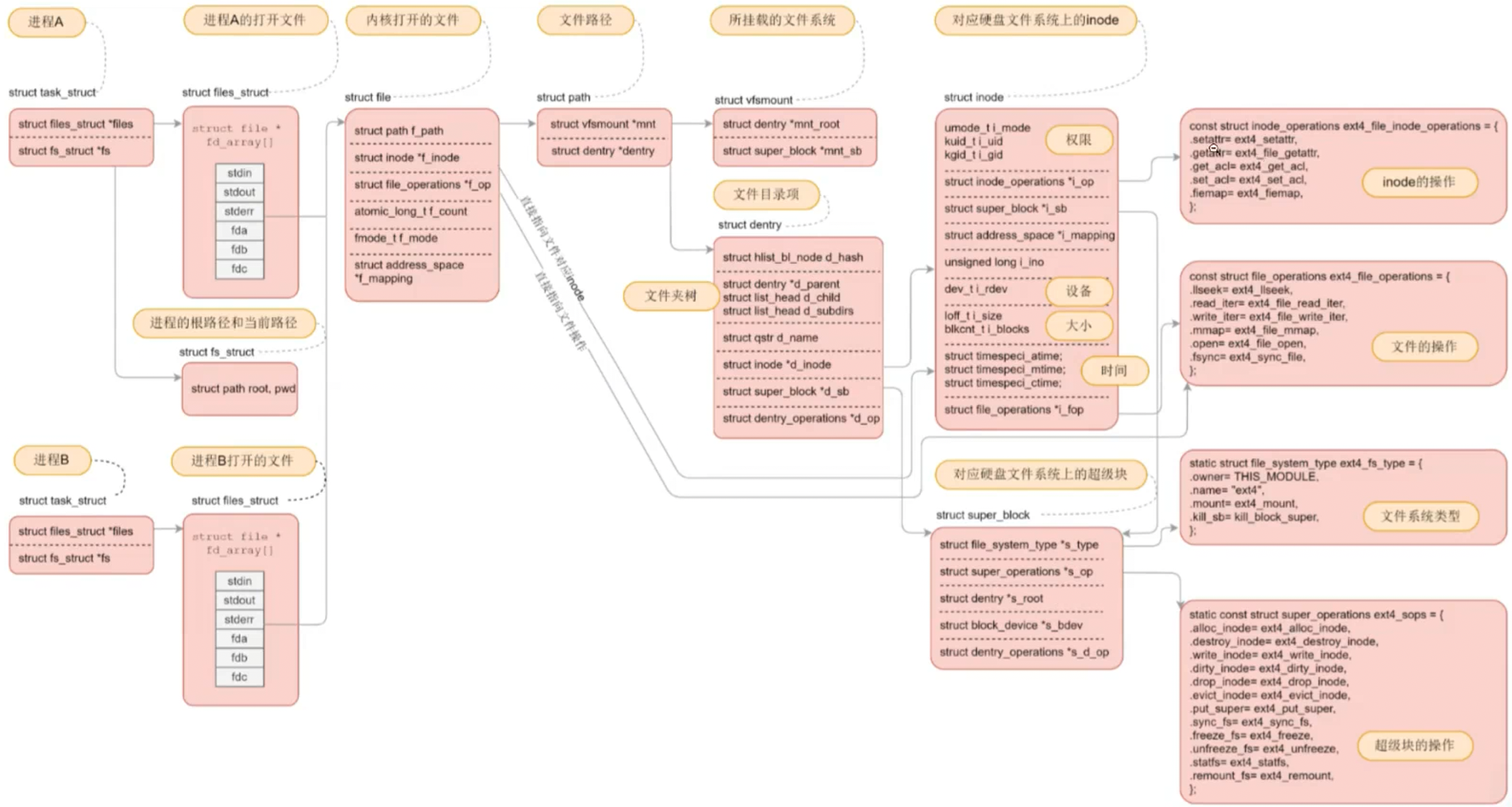
2.6 文件结构图解
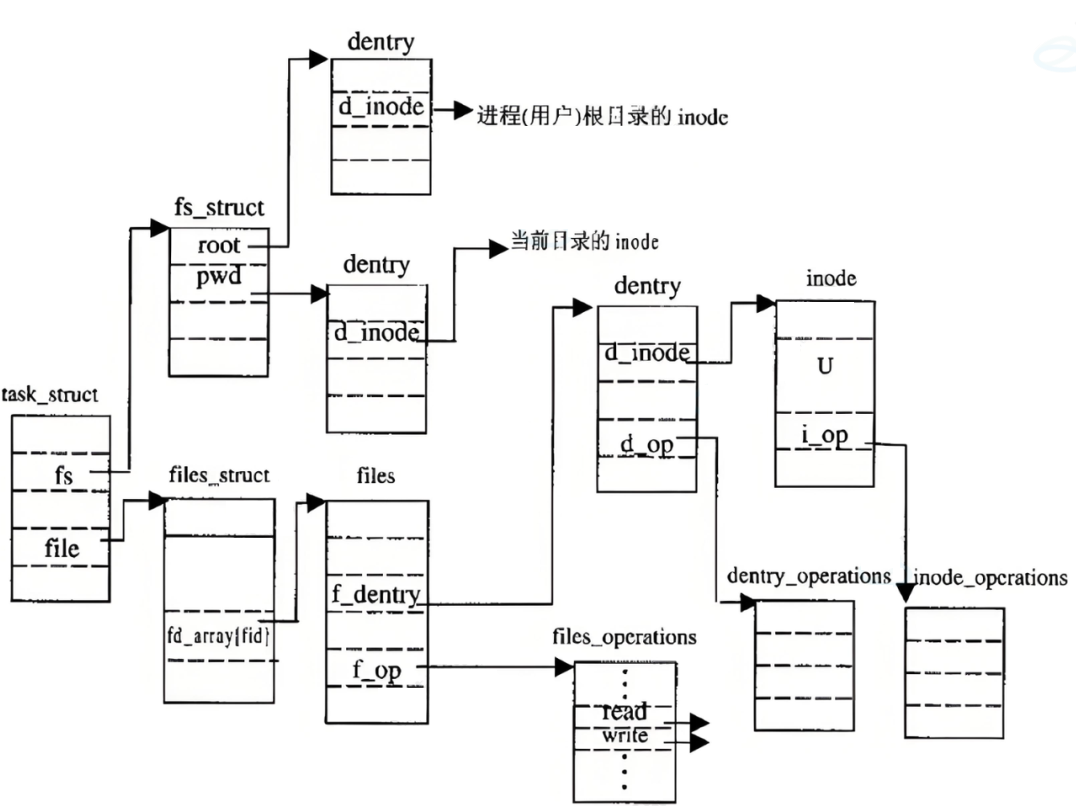
fs是"导航仪":告诉我"我在哪"(根目录、当前目录);files是"文件夹":告诉我"我打开了哪些文件"(fd 到 file 的映射)。
三、软硬连接原理
3.1 软连接
创建软连接:
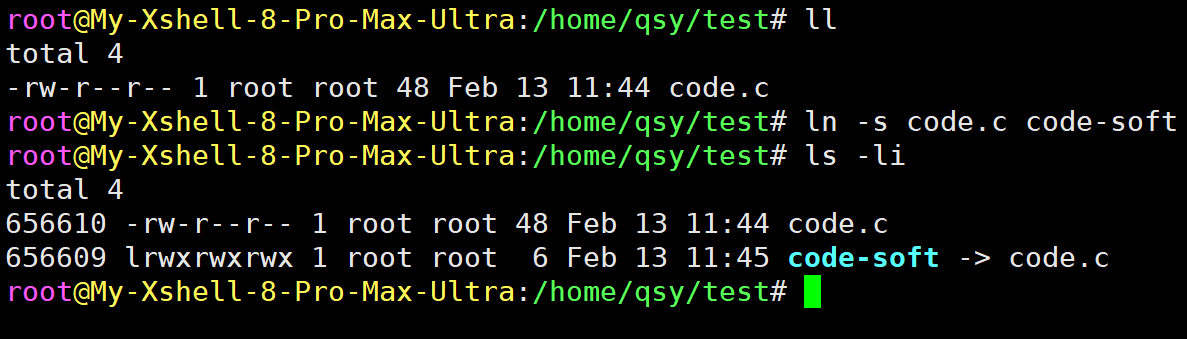
使用ln -s 原文件 目标文件创建软连接。
软连接是一个独立的文件,因为它有独立的inode number,而且他的属性从-变成了 l l l,它的内容存储的是一个原文件路径。如上打开code-soft就相当于打开code.c。
软连接能干什么,为什么要创建软链接?直接使用原文件不行吗?那你可被打脸了,其实你每天都在使用软连接,Windows系统下的快捷方式,就相当于软连接,因为原文件的存储路径比较深而且散乱,软连接就有了很大的作用。此外软连接还在动态库等地方有用处。
我们打开一个快捷方式的属性就能看到它的目标文件路径信息:
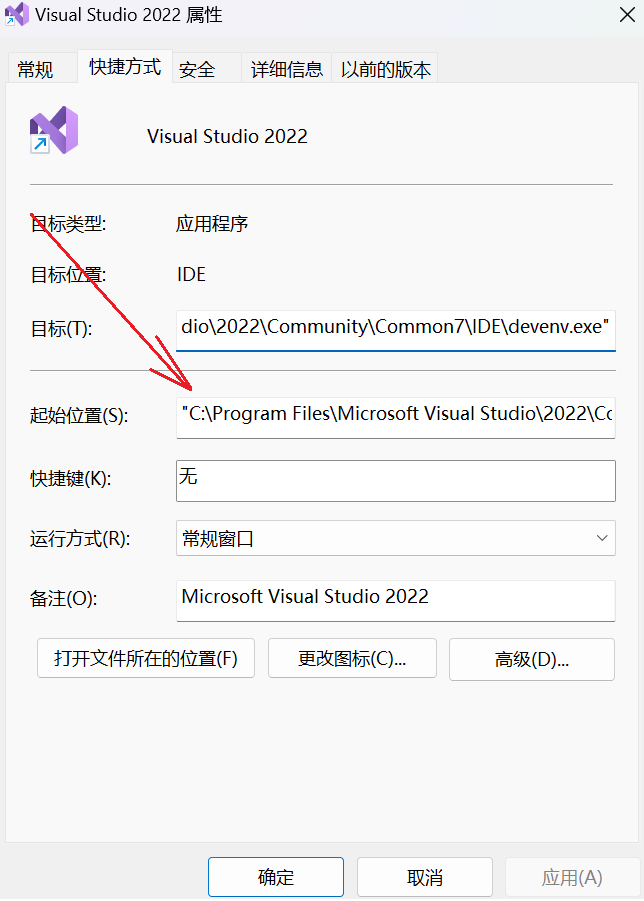
所以我们在桌面上删除软件,本质只删了快捷方式,对原文件没有任何影响。
3.2 硬链接
创建一个硬链接:
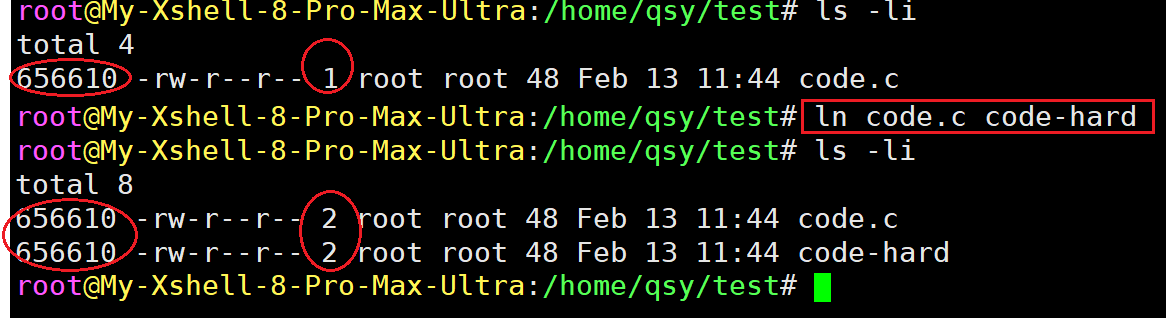
使用指令ln 原文件 目标文件创建硬链接。
可以发现硬链接的inode编号和原文件一样,表面上看跟新建一个文件没什么区别。其本质是在目录下新建一个文件名与inode编号的映射关系。
还有一处变化细节:这是计数器(硬链接数)从1变成了2,在文件inode属性信息里有引用计数。
硬链接又有什么作用?防止被删,当我们做了硬链接,删除文件时只会让计数器减1,不会让文件删除,除非计数器减到0才会被删。类似备份功能,但如果说出备份并不准确,因为一个硬链接或原文件指向的文件信息改变,其他相关到inode编号的文件也会改变。
功能2:注意到了没,为什么目录文件引用计数是2。有的是3、4等甚至跟多。因为.和..目录本质是硬链接,.是本文件的硬链接,..是父目录的硬链接,从目录计数可以看出该目录下有多少目录。验证:查它们的inode
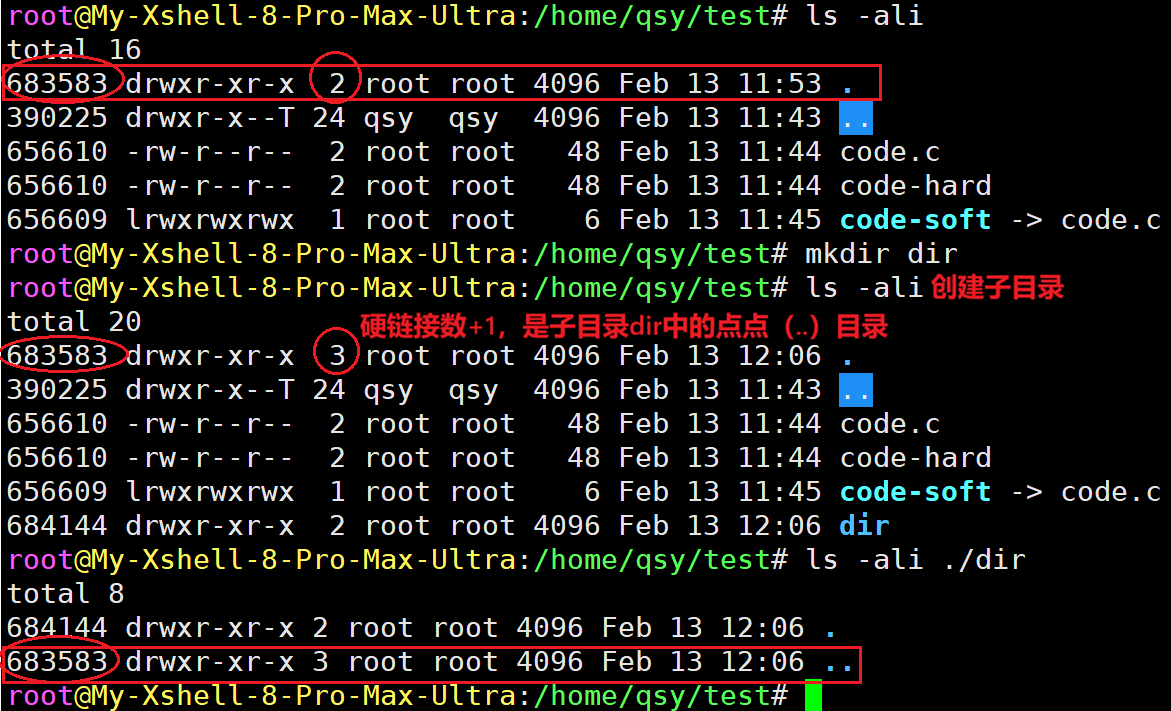
注意:硬链接只能给普通文件进行建立,Linux系统不支持给目录建立硬链接。但软连接没此限制。

但这就出现矛盾了,.和..就是对目录建立硬链接呀!其实系统自己会对目录设置硬链接,但不允许用户创建目录硬链接。为什么?为什么?试想一下我们自己创建目录硬链接,那么原理目录的多叉树结构,就会变成图结构,还可能生成环,那么这个文件系统的路径查找就瘫痪了。
那么矛盾又来了,.和..不就会使得目录树变成环吗,是的!所以操作系统才把目录硬链接做成这个特殊的符号,做特殊处理。
那么给目录建立软连接不也会生成环吗?系统为什么允许用户这样操作?事实上软连接的属性已经改变并做了标识,如下:

所以系统会把它当做普通文件处理,不会使路径搜索成死循环。
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!🎉