1**、** Graph 的相关概念
**一、**StateGraph
LangGraph 的核心是将Agent,WorkFlow建模为图。您可以使用三个关键组件来定义一个Graph:
- State: 表示应用程序当前快照的共享数据结构。它可以是任何 Python 类型,但通常是 TypedDict 或 Pydantic BaseModel。
- Nodes: 编码代理逻辑的 Python 函数。它们接收当前的 State 作为输入,执行一些计算或副作用,并返回更新后的 State。
- Edges: 根据当前 State 决定接下来执行哪个 Node 的 Python 函数。它们可以是条件分支或固定转换。
通过组合 Nodes 和 Edges,您可以创建复杂的、循环的工作流,这些工作流会随着时间推移演进 State。需要强调的是:Nodes 和 Edges 仅仅是 Python 函数------它们可以包含 LLM 或仅是普通的 Python 代码。
要构建图,您首先定义 状态,然后添加 节点和 边,最后进行编译。
|-------------------------------------------|
| Python graph = graph_builder.compile(...) |
**二、**State 状态
定义图时,您要做的第一件事是定义图的 State。State 由图的 schema 以及指定如何将更新应用到状态的reducer函数组成。State 的 schema 将作为图中所有 Nodes 和 Edges 的输入 schema,可以是 TypedDict 或 Pydantic 模型。所有 Nodes 将发出对 State 的更新,然后使用指定的 reducer 函数应用这些更新。
|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from langgraph.graph.message import add_messages class State(TypedDict): messages: Annotatedlist\[AnyMessage, add_messages] extra_field: int |
Reducer 函数
理解节点更新如何应用于 State,Reducer 是关键。State 中的每个键都有其独立的 reducer 函数。如果未明确指定 reducer 函数,则假定对该键的所有更新都应覆盖它。Reducer 有几种不同类型,从默认类型的 reducer 开始:
实例A
|--------------------------------------------------------------------------------------------------|
| Python from typing_extensions import TypedDict class State(TypedDict): foo: int bar: liststr |
在此示例中,未为任何键指定 reducer 函数。假设图的输入是 {"foo": 1, "bar": "hi"}。然后假设第一个 Node 返回 {"foo": 2}。这被视为对状态的更新。请注意,Node 不需要返回整个 State schema,而只需返回一个更新。应用此更新后,State 将变为 {"foo": 2, "bar": "hi"}。如果第二个节点返回 {"bar": "bye"},则 State 将变为 {"foo": 2, "bar": "bye"}。
实例B
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from typing import Annotated from typing_extensions import TypedDict from operator import add class State(TypedDict): foo: int bar: Annotatedlist\[str, add] |
在此示例中,我们使用 Annotated 类型为第二个键 (bar) 指定了一个 reducer 函数 (operator.add)。请注意,第一个键保持不变。假设图的输入是 {"foo": 1, "bar": "hi"}。然后假设第一个 Node 返回 {"foo": 2}。这被视为对状态的更新。请注意,Node 不需要返回整个 State schema,而只需返回一个更新。应用此更新后,State 将变为 {"foo": 2, "bar": "hi"}。如果第二个节点返回 {"bar": "bye"},则 State 将变为 {"foo": 2, "bar": "hi", "bye"}。请注意,这里的 bar 键是通过将两个列表相加来更新的。
operator.add 和 LangGraph.add_messages 区别
在许多情况下,将之前的对话历史记录作为消息列表存储在图状态中会很有帮助。为此,我们可以在图状态中添加一个键(通道),用于存储 Message 对象列表,并使用 reducer 函数对其进行注释(参见下面示例中的 messages 键)。reducer 函数对于告诉图如何通过每次状态更新(例如,当节点发送更新时)来更新状态中的 Message 对象列表至关重要。如果您不指定 reducer,每次状态更新都将用最新提供的值覆盖消息列表。如果您只想将消息简单地附加到现有列表中,可以使用 operator.add 作为 reducer。
但是,您可能还需要手动更新图状态中的消息(例如,人机协作)。如果您使用 operator.add,您发送给图的手动状态更新将被附加到现有消息列表,而不是更新现有消息。为避免这种情况,您需要一个能够跟踪消息 ID 并在更新时覆盖现有消息的 reducer。为此,您可以使用预构建的 add_messages 函数。对于新消息,它只会简单地附加到现有列表,但它也会正确处理现有消息的更新。除了跟踪消息 ID,add_messages 函数还会在 messages 通道上收到状态更新时尝试将消息反序列化为 LangChain Message 对象。
MessagesState
由于在状态中包含消息列表非常常见,因此存在一个预构建的状态 MessagesState,它使得使用消息变得容易。MessagesState 定义了一个单一的 messages 键,它是一个 AnyMessage 对象列表,并使用 add_messages reducer。通常,需要跟踪的状态不仅仅是消息,因此我们看到人们会对此状态进行子类化并添加更多字段,例如:
|----------------------------------------------------------------------------------------------------------------|
| Python from langgraph.graph import MessagesState class State(MessagesState): documents: liststr # 额外增加的key |
三、节点****Node
在 LangGraph 中,节点通常是 Python 函数(同步或异步),其中第一个 位置参数是状态,(可选地)第二个 位置参数是"config",包含可选的可配置参数(例如 thread_id)。
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from typing_extensions import TypedDict from langchain_core.runnables import RunnableConfig from langgraph.graph import StateGraph class State(TypedDict): input: str results: str builder = StateGraph(State) def my_node(state: State, config: RunnableConfig): print("In node: ", config"configurable""user_id") return {"results": f"Hello, {state'input'}!"} # The second argument is optional def my_other_node(state: State): return state builder.add_node("my_node", my_node) builder.add_node("other_node", my_other_node) ... |
START 节点
START 节点是一个特殊节点,它代表将用户输入发送到图的节点。引用此节点的主要目的是确定应首先调用哪些节点。
END 节点
END 节点是一个特殊节点,代表一个终止节点。当您想表示哪些边在完成后没有后续操作时,会引用此节点。
四、边****Edge
边定义了逻辑如何路由以及图如何决定停止。这是代理工作方式以及不同节点之间如何通信的重要组成部分。有几种关键类型的边:
- 普通边:直接从一个节点到下一个节点。
- 条件边:调用函数以确定接下来要转向哪些节点。
一个节点可以有多个出边。如果一个节点有多个出边,则所有这些目标节点将在下一个超级步骤中并行执行。
普通边
如果您总是 想从节点 A 转到节点 B,可以直接使用 add_edge 方法。
条件边
如果您想可选地 路由到一条或多条边(或可选地终止),可以使用 add_conditional_edges 方法。此方法接受一个节点名称和一个在该节点执行后调用的"路由函数":
|----------------------------------------------------------------|
| Python graph.add_conditional_edges("node_a", routing_function) |
与节点类似,routing_function 接受图的当前 state 并返回一个值。
默认情况下,routing_function 的返回值用作下一个要发送状态的节点(或节点列表)的名称。所有这些节点都将在下一个超级步骤中并行运行。
您可以选择提供一个字典,将 routing_function 的输出映射到下一个节点的名称。
|---------------------------------------------------------------------------------------------------|
| Python graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"}) |
routing_function就必须返回:Ture和False。
2**、第一个案例:评估器**
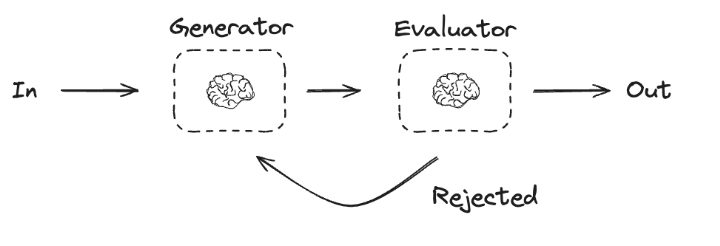
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python python from typing import Literal, TypedDict from pydantic import BaseModel, Field from langgraph.graph import StateGraph, END, START from agent.my_llm import llm # 定义图状态结构(使用TypedDict实现类型安全) class State(TypedDict): joke: str # 生成的冷笑话内容 topic: str # 用户指定的主题 feedback: str # 改进建议 funny_or_not: str # 幽默评级 # 结构化输出模型(用于LLM评估反馈) class Feedback(BaseModel): """使用此工具来结构化你的响应""" grade: Literal["funny", "not funny"] = Field( description="判断笑话是否幽默", examples=["funny", "not funny"] ) feedback: str = Field( description="若不幽默,提供改进建议", example="可以加入双关语或意外结局" ) # # 配置LLM结构化输出(需提前初始化llm对象) # evaluator = llm.with_structured_output(Feedback) # 节点定义 def llm_call_generator(state: State) -> dict: """LLM生成笑话节点(带反馈优化机制)""" prompt = ( f"根据反馈改进笑话:{state['feedback']}\n主题:{state['topic']}" if state.get("feedback") else f"创作一个关于{state['topic']}的笑话" ) response = llm.invoke(prompt) return {"joke": response.content} def llm_call_evaluator(state: State) -> dict: """LLM笑话评估节点(结构化输出)""" evaluator = llm.bind_tools([Feedback]) evaluation = evaluator.invoke( f"评估此笑话的幽默程度:\n{state['joke']}\n" "注意:幽默应包含意外性或巧妙措辞" ) evaluation = evaluation.tool_calls[-1]['args'] return { "funny_or_not": evaluation['grade'], "feedback": evaluation['feedback'] } # 条件路由函数 def route_joke(state: State) -> str: """动态路由决策(基于评估结果)""" return ( "Accepted" if state["funny_or_not"] == "funny" else "Rejected + Feedback" ) # 构建工作流(使用StateGraph) optimizer_builder = StateGraph(State) # 添加节点(可替换为MCP工具[5](@ref)) optimizer_builder.add_node("generator", llm_call_generator) # 对应@mcp.tool() optimizer_builder.add_node("evaluator", llm_call_evaluator) # 构建连接关系 optimizer_builder.add_edge(START, "generator") optimizer_builder.add_edge("generator", "evaluator") optimizer_builder.add_conditional_edges( "evaluator", route_joke, { "Accepted": END, # 合格则结束 "Rejected + Feedback": "generator" # 不合格则循环优化 } ) # 编译工作流(可导出为MCP服务[6](@ref)) optimizer_workflow = optimizer_builder.compile() # 执行示例(主题可动态替换) # result = optimizer_workflow.invoke({"topic": "程序员"}) # print(f"最终笑话:{result['joke']}") |