作者:昇腾实战派
知识地图链接: 【强化学习】知识地图-CSDN博客
背景概述
在大模型训练过程中,如何高效利用NPU硬件资源并保证训练稳定性是开发者面临的重要挑战。本文基于实际项目经验,分享了在NPU环境下使用VLLM+FSDP后端进行Qwen3-30B模型DAPO训练的完整实践方案。通过详细的版本配置、核心参数调优和部署指导,为开发者提供了一套可复现的高效训练方案。
一、版本信息
硬件平台:Atlas 800T A2
软件版本信息:
| 组件名称 | 版本号 | 备注 |
|---|---|---|
| HDK | 25.0.rc1 | |
| Python | 3.11 | |
| CANN | 8.3.RC1 | Q3商发版本 |
| torch | 2.7.1 | |
| torch_npu | 2.7.1 | Q3商发版本 |
| vllm | v0.11.0 | https://github.com/vllm-project/vllm/tree/v0.11.0 |
| vllm-ascend | v0.11.0rc1 | https://github.com/vllm-project/vllm-ascend/tree/v0.11.0rc1 |
| verl | main | commit: 7d44f22f1a2d30ec1c405f2c6216bf1e1477cc60 |
二、核心参数
本文以VLLM+FSDP后端为例,启动脚本参考:verl-recipe/dapo/run_dapo_qwen3_moe_30b_base_fsdp_npu.sh at main · verl-project/verl-recipe
根据verl官方仓库的脚本,2机32卡可直接拉起训练,下面介绍一些核心参数
2.1 数据配置
data.val_files="${TEST_FILE}" \
data.prompt_key=prompt \
data.max_prompt_length=2048 \
data.max_response_length=20480 \
data.gen_batch_size=1536 \
data.train_batch_size=512 \参数说明:
- 指定数据集路径和关键字段
- 限制prompt和response的最大长度
- 设置推理和训练的batch size
2.2 并行配置
2.2.1 Actor并行配置
python
actor_rollout_ref.actor.ulysses_sequence_parallel_size=8 \
actor_rollout_ref.actor.fsdp_config.fsdp_size=-1 \
actor_rollout_ref.actor.fsdp_config.param_offload=True \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \配置要点:
- 采用FSDP全分片 + Ulysses序列并行
- SP建议设置为8或16,有助于负载均衡
- offload功能将actor的权重、梯度和优化器状态卸载到CPU
2.2.2 Rollout并行配置
rollout使用TP并行
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \三、数据集准备
使用dapo-math数据集,执行以下命令进行数据准备:
bash recipe/dapo/prepare_dapo_data.sh四、部署指导
4.1 安装torch & torch_npu
pip install torch==2.7.1
pip install torch-npu==2.7.14.2 安装vllm & vllm-ascend
# Install vLLM
git clone --depth 1 --branch v0.11.0 https://github.com/vllm-project/vllm
cd vllm
VLLM_TARGET_DEVICE=empty pip install -v -e .
# Install vLLM Ascend
git clone --depth 1 --branch v0.11.0rc1 https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
pip install -v -e .4.3 安装verl
git clone https://github.com/volcengine/verl.git
cd verl
pip install -r requirements-npu.txt
pip install -e .4.4 启动训练
在Ray集群的head节点上执行启动脚本:
bash recipe/dapo/run_dapo_qwen3_moe_30b_base_fsdp_npu.sh五、复现结果样例
5.1 精度数据
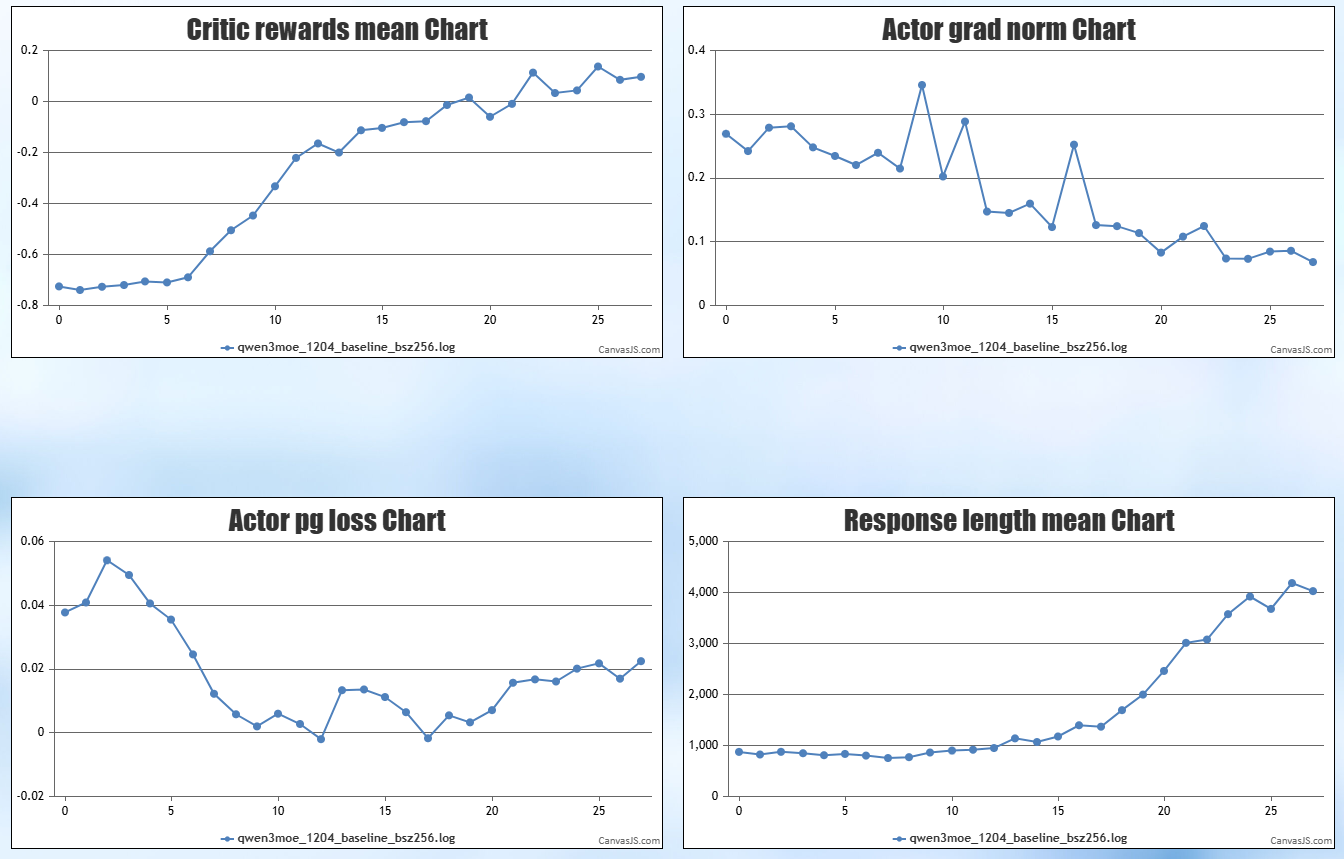
5.2 性能数据