以前我觉得开源模型大多是玩具,真要干活、写复杂逻辑,还得老老实实给闭源大厂交 API 的保护费。GLM-5 的发布,不是一次简单的版本号 +1,而是直接把开源模型从玩具拉到了员工的级别。

跑完测试后,我发现,以前得雇人或者自己熬夜干的活,现在这个模型真的能接手了。
为什么说 GLM-5 让我的认知崩塌了?
参数量 744B(激活 40B),预训练数据 28.5T tokens,AI一般都有2个问题,脑子不够用和记性太差,这也是用 AI 开发的痛点,而 GLM-5就没有这个烦恼。
1. 它不再是小镇做题家
以前评测模型,大家喜欢看它做奥数题。但说实话,谁家好人在工作中用到奥数呀,我它帮我规划任务。
这次 GLM-5 在 Vending Bench 2 上的表现就很厉害了,要知道这个测试很变态的,要求模型在模拟环境里经营一家自动售货机公司,周期长达一年。
- 大多数开源模型:落地成盒,开局就寄,根本搞不清库存和资金流。
- GLM-5:不仅活下来了,最后账户余额还剩 4,432 美元。
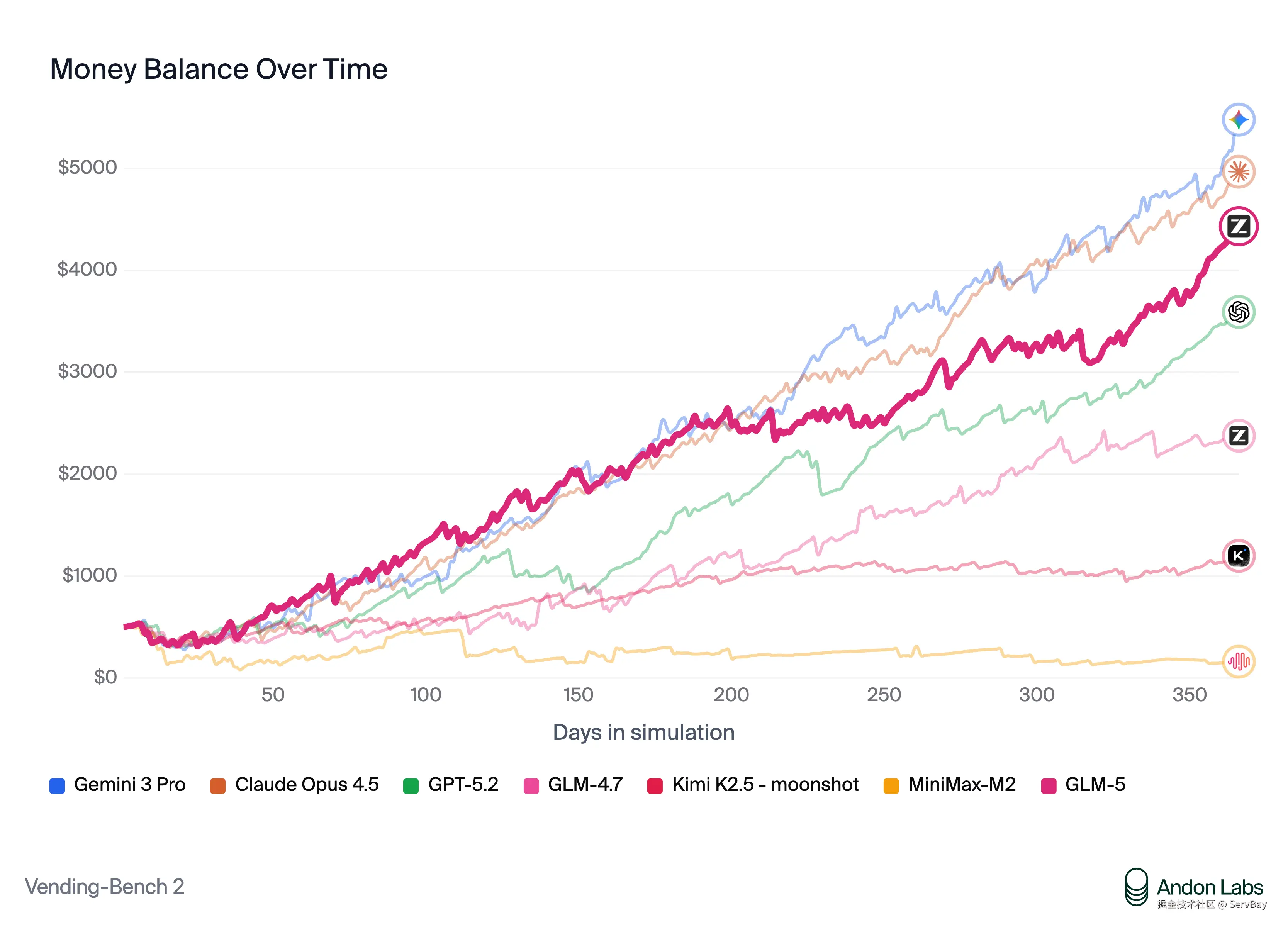
这个成绩在开源界是断层第一,直逼闭源的 Claude Opus 4.5。就是说,如果你把 GLM-5 接入业务流,它真的具备长期规划和资源管理的能力。
2. 从生成文字到交付工作
大家以前用模型最烦的是什么?它给你吐出一堆 Markdown 格式的文本,你还得自己复制粘贴去排版。
GLM-5 这次最让我惊喜的是它对办公场景的理解。它能把那些复杂的推理结果,直接生成 .docx、.pdf 甚至 .xlsx 文件。
-
写 PRD?它直接给你一个格式完美的 Word 文档。
-
做财报分析?它直接扔给你一个带公式的 Excel 表格。
这才是真正的生产力工具。它省掉那些最没技术含量的格式调整和文档整理时间。
3. 技术上的降本增效
我也好奇,这么大的参数量,跑起来会不会慢得像蜗牛?
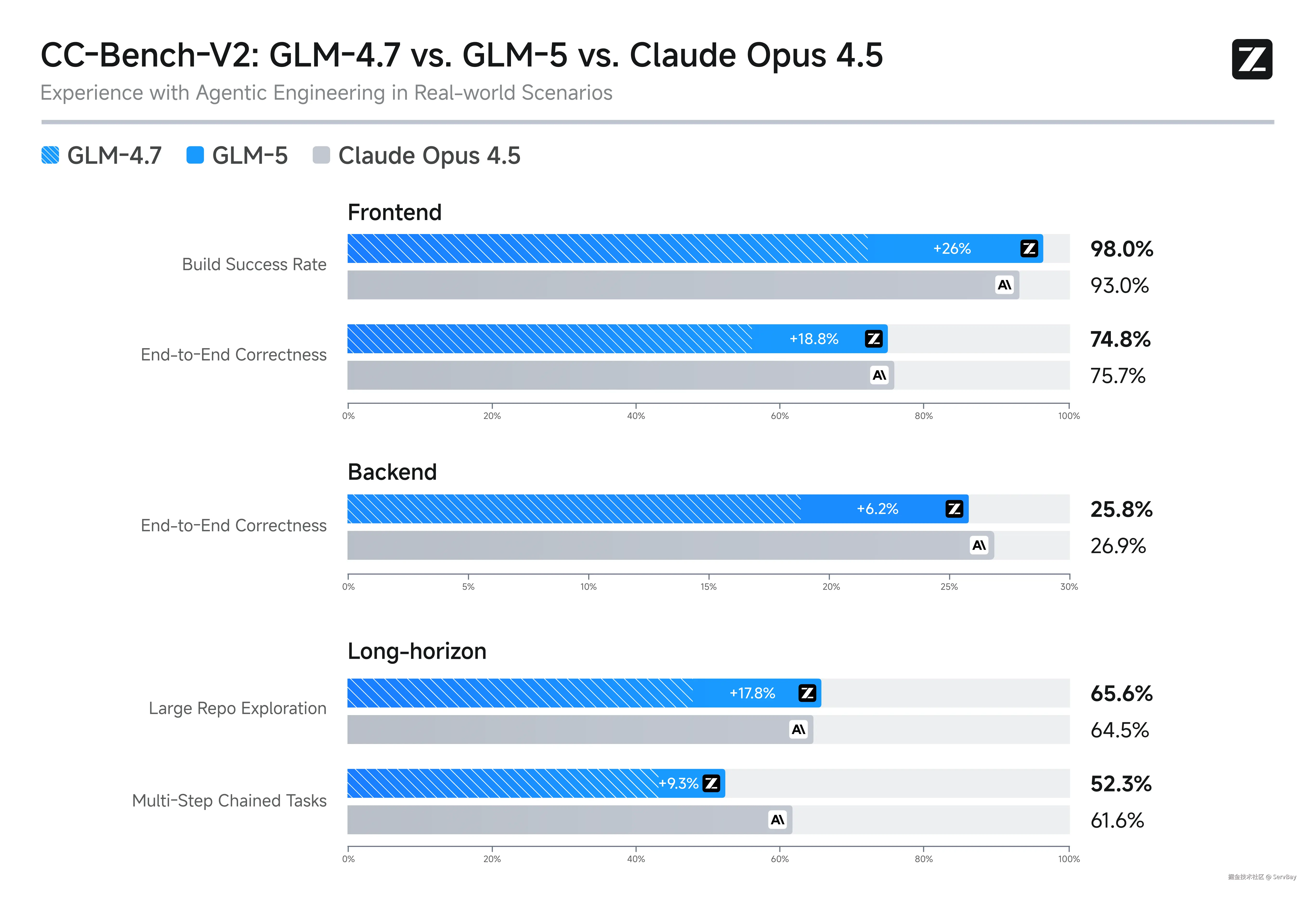
GLM-5 用了 DeepSeek Sparse Attention (DSA) 的技术,让模型只关注该关注的信息,把算力用在刀刃上。再加上 slime 的强化学习架构,解决了大模型越训越傻的问题。
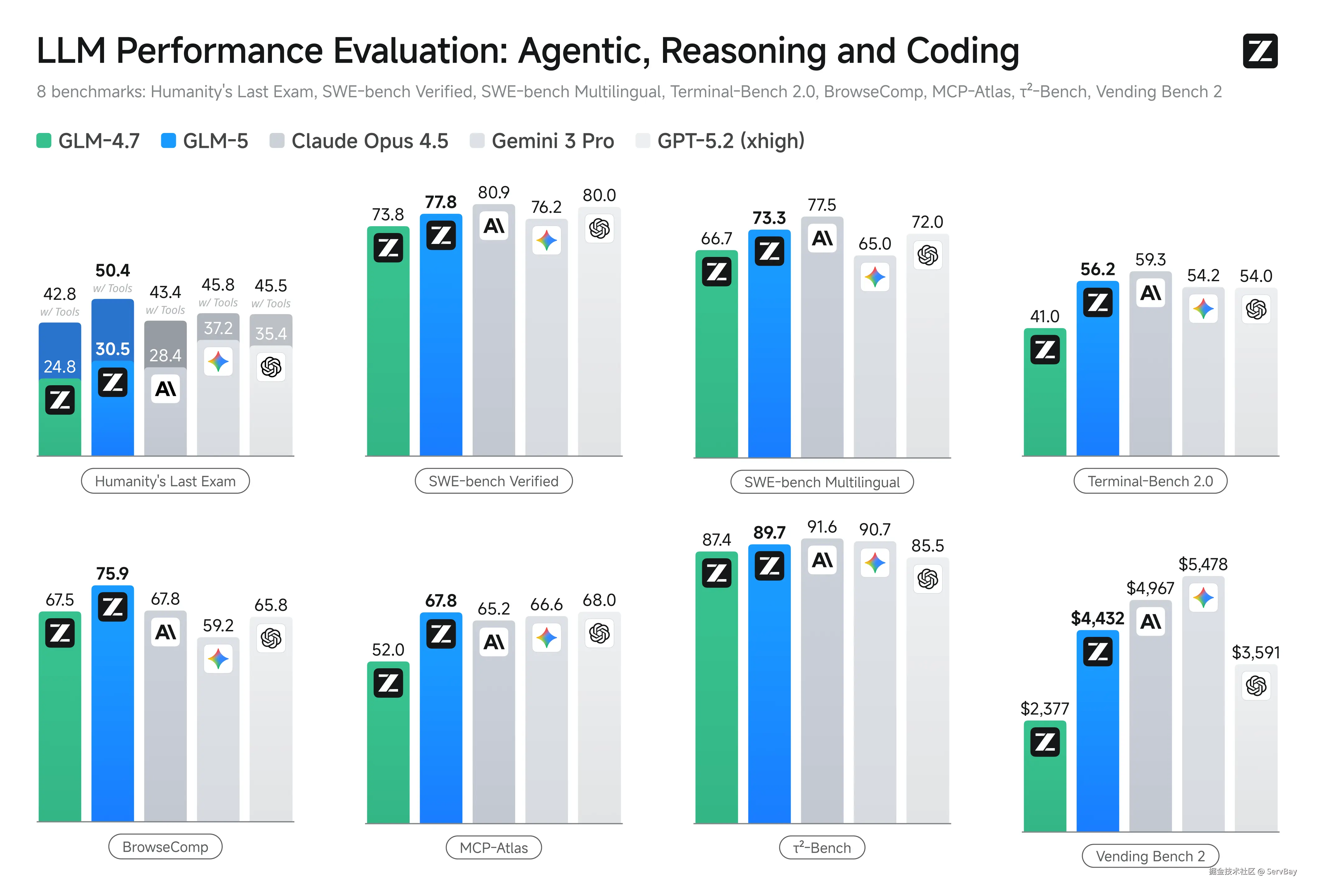
所以它的逻辑密度高,废话少。
本地部署
说到这,很多人可能跃跃欲试想在本地跑一下。毕竟是开源模型,数据握在自己手里才踏实。
GLM-5 这种量级的模型,对 Python 环境、依赖库有要求。我之前为了跑一个大模型,光是解决 Python 依赖冲突就花了一整天,最后心态崩了模型还没跑起来。
所以这次为了不重蹈覆辙,直接上 ServBay。如果以前你觉得这种工具是给新手用的,那就错了,这是给想省时间的人用的。
你想跑 GLM-5,得装特定版本的 Python,还得配 vLLM 或者 SGLang,原生环境里搞,很容易把之前的项目环境搞挂。用 ServBay,点击下载Python, 它直接给我弄了一个隔离的、干净的 Python 3.10+ 环境。
就这么简单。在这个干净的沙盒里,再运行安装命令:
bash
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly没有报错,没有红字,一次通过。
这一步省下来的时间,足够我把 GLM-5 的 API 文档看两遍了。
最后
如果你看看未来的工作方式长什么样,可以试试 GLM-5。
它不是那种让你"哇"一声然后就关掉的玩具,它是那种你用了一次,就会把招聘助手的计划推迟的工具。
值得试试。