坦白说,AI的RAG和LLM的文章和总结看了不少,但是就没搞明白如何协作,所以自己动手先编程,运行成功后,再输出这篇总结!都是自己的原创总结。
依旧是我的风格,先上结论和重点!!!
难点&关键点:RAG的入库、分解、组织关联、匹配;
最基础原始的就是分词存储,查找like,这个太low了;
**这个点才是RAG的关键、关键、关键!检索不全、检索不准,LLM就判断不准。**之前的总结文档说的都不清楚!
RAG是本地数据库,把专业知识都放在本地数据库里;
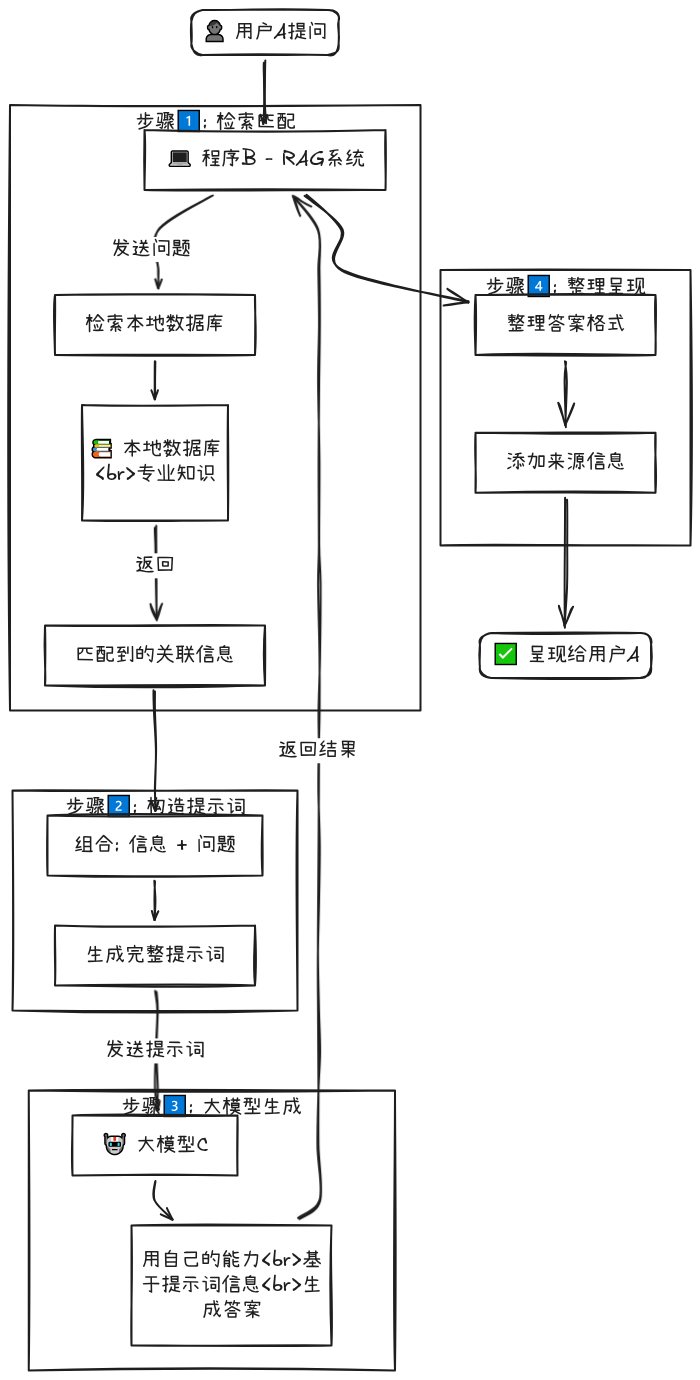
1、用户A提问后,发给程序B:
2、程序B拿问题去本地数据库里检索匹配关联信息
3、程序B把信息和问题结合构成提示词,发给大模型
4、大模型C用自己的能力,用提示词的信息来回答问题,把结果发给程序B
5、程序B整理后呈现给用户A
大模型没有专业知识库,只提供能力;我们把知识信息、问题一起给它,让它用能力回答问题

第一步:检索 - 大海捞针,精准定位
-
做什么:当用户提出一个问题(Query)时,系统首先不是让大模型直接回答,而是在一个预先构建好的"知识库"(通常是公司内部文档、手册、网页等)中,寻找与问题最相关的信息片段。
-
技术要点 :这通常通过向量搜索引擎实现。先将问题和所有文档都转换成数学向量(一组数字),然后计算它们之间的相似度,找到最相似的几个片段。这比传统的关键字匹配更智能,能理解语义。
第二步:增强 - 巧设舞台,提供剧本
-
做什么 :将上一步检索到的零散信息片段(
relevant_docs)和用户的原始问题组合成一个新的、内容丰富的"提示词",交给大模型。 -
为何重要 :这是 RAG 的灵魂。它限制了模型的"信口开河",命令它:"请严格按照我给你的这些资料来回答"。这极大地提高了答案的准确性和可靠性。
第三步:生成 - 专家出场,撰写答案
-
做什么 :将精心构造的 Prompt 发送给大语言模型。LLM 的角色不再是无所不知的通才,而是一位仔细阅读了你所提供的参考资料后,进行总结和表达的专家。
-
结果:模型会生成一个流畅、自然且基于事实的答案。代码最后还将答案和来源一同返回,显得非常专业。
RAG 的巨大优势
-
解决"幻觉"问题:模型回答有所依据,大大减少了胡编乱造的可能。
-
知识实时更新:想要模型了解最新信息?只需要更新知识库文档即可,无需耗费巨资重新训练模型。
-
溯源可查:可以像代码中展示的那样,告知用户答案来源于哪些资料,增强信任感。
-
低成本高效率:相比于为特定领域训练一个专用大模型,搭建 RAG 系统的成本和门槛要低得多。
总结
通过上面的流程图和分解,我们可以看到,RAG 并非神秘莫测的技术。它本质上是一种系统工程思路,巧妙地将高效的检索系统与强大的生成模型相结合,取长补短。
你的代码完美地体现了这一思路:
-
SimpleRAG基类(来自rag.py)负责知识库管理和检索(第一、二步)。 -
call_qianfan_api 方法负责调用生成模型(第三步)。
-
answer_with_llm方法则是整个流程的总控制器,将它们串联起来。
simple_rag_with_llm.py
import requests
import json
from rag import SimpleRAG
class SimpleRAGWithLLM(SimpleRAG):
def init(self, api_key=None):
super().init()
self.api_key = api_key
def call_qianfan_api(self, prompt):
"""调用百度千帆免费API"""
百度千帆有免费额度
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_bot_turbo"
如果没有API Key,返回简单拼接
if not self.api_key:
print("no api key!")
return None
headers = {'Content-Type': 'application/json'}
params = {'access_token': self.api_key}
data = {
"messages": {"role": "user", "content": prompt},
"temperature": 0.1
}
try:
response = requests.post(url, headers=headers, params=params, json=data)
print("LLM RESULT:")
print(response.json())
print("LLM RESULT END")
return response.json()'result'
except:
return None
def call_local_llm(self, prompt):
"""调用本地部署的模型(如果有)"""
假设你本地部署了ChatGLM或Qwen
url = "http://localhost:8000/v1/chat/completions"
try:
response = requests.post(url, json={
"model": "chatglm",
"messages": {"role": "user", "content": prompt},
"temperature": 0.1
})
return response.json()'choices'0'message''content'
except:
return None
def answer_with_llm(self, query):
"""使用LLM生成答案"""
1. 先检索相关文档
relevant_docs = self.search(query, top_k=3)
if not relevant_docs:
return "❌ 知识库中没有相关信息"
2. 构造prompt
context = "\n".join(doc\['content' for doc in relevant_docs])
prompt = f"""基于以下信息回答问题:
相关信息:
{context}
问题:{query}
请给出准确、简洁的回答:"""
print(prompt)
3. 调用LLM
#llm_response = self.call_local_llm(prompt) or self.call_qianfan_api(prompt)
llm_response = self.call_qianfan_api(prompt)
if llm_response:
return f"🤖 AI回答:\n{llm_response}\n\n📚 信息来源:知识库检索"
else:
降级到简单拼接
return f"📚 相关信息:\n{context:500}..."
高级用法示例
if name == "main":
如果有API Key
rag = SimpleRAGWithLLM(api_key="")
没有API Key就用基础版
rag = SimpleRAGWithLLM()
批量导入企业文档
rag.load_documents_from_folder('docs')
测试不同类型的查询
test_queries = [
"年假政策是什么?",
"新员工有多少天年假?",
"报销流程怎么走?",
"差旅费多久能报销到账?"
]
print("🧪 测试查询:\n")
for q in test_queries:
print(f"Q: {q}")
print(f"A: {rag.answer_with_llm(q)}\n")
print("-" * 50)