redis持久化概念
为了保证速度快,数据肯定还是得存在内存中。但是为了数据持久,数据还要想办法存储到硬盘上。
Redis决定,内存存数据,硬盘中也存一份数据,这两份数据理论上是完全相同的,但实际上有小概率存在差异(取决于我们具体是怎样进行持久化的)。
写入 :当要插入一个新的数据时,就需要把数据同时写入内存和硬盘。(说是两边都写,但实际上具体怎么写入硬盘还有不同的策略------还是可以保证整体的效率足够高的)
读取:当查询某个数据时,直接从内存读取。
硬盘的数据只是在redis重启时,用来恢复内存中的数据的。
Redis实现持久化的时候,具体是按照什么样的策略来实现的?
-
RDB (Redis DataBase)定期备份的策略
-
AOF (Append Only FIle)实时备份的策略
RDB策略
RDB定期的把我们Redis中的数据,都写入硬盘,生成一个快照。
定期具体来说,又有两种方式:
-
手动触发
程序员通过redis客户端,执行特定的命令,来触发生成快照。
-
自动触发
在redis配置文件中,设置一下,让redis定期自动触发。
手动触发
⼿动触发分别对应 save 和 bgsave 命令:
-
save :执行save的时候,redis就会全力以赴的进行"快照生成"操作,此时就会阻塞redis的其他客户端的命令(一般不建议使用save)
-
bgsave :bg(background),放到后台执行 ,不会影响redis服务器处理其他客户端的请求和命令。
redis服务器是单线程模型 ,如何并发执行?此处redis使用的是多进程 的方式,来完成并发编程,来完成bgsave的实现。
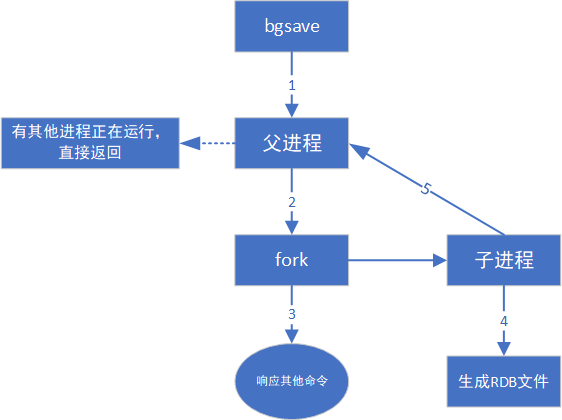
1.判断当前是否已经存在其他正在工作的子进程。
比如现在已经有一个子进程正在执行bgsave,此时就直接把当前的bgsave返回
2.如果没有其他的工作子进程,就通过fork这样的系统调用 ,创建出一个子进程来
复制出来的这个子进程的内存中的数据和父进程是一样的。接下来安排子进程去执行"持久化"操作,也就相当于把父进程本体这里的数据给持久化了。
3.子进程负责写文件,生成快照的过程。父进程继续接收客户端的请求,继续正常提供服务。
4.子进程生成RDB文件
5.子进程完成整体的持久化过程之后,就会通知父进程,父进程就会更新一些统计信息,子进程就可以结束销毁了。
bgsave执行流程
子进程 :创建子进程,子进程完成持久化。
文件替换 :持久化会把数据写入到新的文件中,然后使用新的文件替换旧的文件。
当执行生成rdb镜像操作时,此时就会把要生成的快照数据先保存到一个临时文件中,当这个快照生成完毕之后,再删除之前的rdb文件,把新生成的临时的rdb文件名字改成刚才的文件名 ------dump.rdb。
就是说,每次生成的rdb镜像文件是不同的,而不是说在原有文件的基础上进行修改的。
save执行流程
若直接使用save命令,此时不会触发子进程&文件替换 逻辑,直接在当前进程 中,向刚才同一个文件中写入数据。
关于rdb镜像文件
redis生成的rdb文件,是存放在redis的工作目录中的。这个目录在redis的配置文件中可以进行修改。
bash
#配置文件中的选项
# Note that you must specify a directory here, not a file name
dir /var/lib/redis
# The filename where to dump the DB
dbfilename dump.rdbrdb镜像文件的路径
bash
root@VM-8-5-ubuntu:~# ll /var/lib/redis/
total 12
drwxr-x--- 2 redis redis 4096 Feb 11 02:09 ./
drwxr-xr-x 62 root root 4096 Feb 8 00:01 ../
-rw-rw---- 1 redis redis 89 Feb 11 02:09 dump.rdb # rdb机制产生的镜像文件redis服务器默认就是开启了rdb的。
二进制文件,把内存中的数据,以压缩形式,保存到这个二进制文件中。
后续redis服务器重新启动,就会尝试加载这个rdb文件,如果人为修改dump.rdb文件导致格式错误,就会加载数据失败。哪怕我们不主动去修改它,也可能会出现一些意外问题,一旦通过一些操作(比如:网络传输)引起这个文件被破坏,此时redis服务器就无法正常启动。
如何解决?redis提供了rdb文件的检测工具
rdb文件的检测工具
bash
root@VM-8-5-ubuntu:~# ll /usr/bin/redis-check-rdb
-rwxr-xr-x 1 root root 2624600 Oct 13 23:22 redis-check-rdb* #redis提供的rdb文件的检测工具在redis 5.0版本中,检测工具和redis服务器本质上是同一个可执行程序 ,可以在运行时加入不同选项 ,从而使用不同功能。
用法:redis-check-rdb rdb文件
bash
root@VM-8-5-ubuntu:~# redis-check-rdb dump.rdb
[offset 0] Checking RDB file dump.rdbredis日志
当redis服务器挂了的时候,可以看看redis日志,了解发生了什么
bash
root@VM-8-5-ubuntu:~# ll /var/log/redis/
total 16
drwxr-s--- 2 redis adm 4096 Feb 8 00:01 ./
drwxr-xr-x 13 root syslog 4096 Feb 8 00:01 ../
-rw-rw---- 1 redis adm 6031 Feb 11 23:54 redis-server.log #日志文件例子:手动执行save & bgsave 触发一次生成快照
bash
127.0.0.1:6379> bgsave
Background saving started数据比较少的情况下,执行bgsave瞬间完成,立即查看dump.rdb文件是有结果的。
数据比较多的情况下,执行bgsave就有可能需要消耗一定的时间。
通过上述操作,就可以看到redis服务器重启时,加载了rdb文件的内容,恢复了内存中之前的状态。
自动触发
自动触发的配置
bash
# Save the DB to disk.
#
# save <seconds> <changes> [<seconds> <changes> ...]
#
# Redis will save the DB if the given number of seconds elapsed and it
# surpassed the given number of write operations against the DB.
#
# Snapshotting can be completely disabled with a single empty string argument
# as in following example:
#
# save ""
#
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 change was performed
# * After 300 seconds (5 minutes) if at least 100 changes were performed
# * After 60 seconds if at least 10000 changes were performed
#
# You can set these explicitly by uncommenting the following line.
#
save 3600 1 300 100 60 10000
# 或者如下配置
# save 3600 1
# save 300 100
# save 60 10000save 执行M时间内 且 修改N次------就会生成一次快照。
修改的基本原则:生成一次rdb快照的成本是比较高的,不能让这个操作执行的太频繁。
正式因为rdb生成的不能太频繁,这就导致快照里的数据和当前实时的数据会有所偏差。
bash
save "" #关闭自动生成快照例子:插入新的key,不手动执行bgsave,重新启动redis服务器。
没有执行bgsave,结果新插入的key在重启之后仍然存在。
结论 :redis生成快照的操作,不仅仅是手动执行命令才触发,也可以自动触发。
- 通过修改配置文件中save。
- 通过shutdown命令(redis中的一个命令)关闭redis服务器,也会触发。(正常重启)
- redis进行主从复制的时候,主节点也会生成rdb快照,然后把rdb快照文件内容传输给从节点。
注意 :
如果是正常流程重新启动 reids服务器,此时redis服务器会在退出的时候,自动触发生成rdb操作
但如果是异常重启(kill -9 或者 服务器掉电)此时redis服务器来不及生成rdb,内存中尚未保存到快照中的数据,就会随着重启而丢失。
AOF策略
类似与mysql的bin log,会把用户的每个操作都记录到文件中。
当redis重新启动的时候,就会读取这个aof文件的内容,重新恢复数据。
开启AOF策略
在/etc/redis/redis.conf中修改配置文件,使redis支持AOF策略(rdb策略是redis默认开启的)
bash
appendonly no #yes:开启aof策略
# The name of the append only file
appendfilename "appendonly.aof" # aof 文件名
bash
root@VM-8-5-ubuntu:/var/lib/redis# ll
total 16
drwxr-x--- 3 redis redis 4096 Feb 12 00:59 ./
drwxr-xr-x 62 root root 4096 Feb 8 00:01 ../
drwxr-x--- 2 redis redis 4096 Feb 12 00:59 appendonly.aof
-rw-rw---- 1 redis redis 89 Feb 12 00:59 dump.rdbAOF是一个文本文件。
每次进行操作,都会被记录到文本文件中。
如下是AOF文件的内容(例子)
bash
# appendonly.aof 内容举例
*2
$6
SELECT
$1
0
*3
$3
SET
$4
name
$5
Alice
*3
$3
SET
$3
age
$2
25
*5
$4
MSET
$4
city
$5
Beijing
$6
gender
$1
F
*4
$5
SETEX
$8
vericode
$2
60
$6
887766通过一些特殊的符号作为分割符,来对命令的细节做出区分。
引入AOF策略后,需要实时备份,是否影响到了redis的性能?实际上,是没有的。
- AOF是每次把新的操作写入原有文件的末尾,属于顺序写入。(硬盘上读写数据,顺序读写的速度是比较快的,而随机访问是比较慢的)
- AOF机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一波后,再统一写入硬盘中。
注:在高版本的redisaof文件有所变化
bashroot@VM-8-5-ubuntu:/var/lib/redis# ll total 16 drwxr-x--- 3 redis redis 4096 Feb 12 00:59 ./ drwxr-xr-x 62 root root 4096 Feb 12:00:01 ../ drwxr-x--- 2 redis redis 4096 Feb 12 00:59 appendonlydir/ -rw-rw---- 1 redis redis 89 Feb 12 00:59 dump.rdb root@VM-8-5-ubuntu:/var/lib/redis/appendonlydir# ll total 16 drwxr-x--- 2 redis redis 4096 Feb 12 00:59 ./ drwxr-x--- 3 redis redis 4096 Feb 12 00:59 ../ -rw-rw---- 1 redis redis 89 Feb 12 00:59 appendonly.aof.1.base.rdb -rw-r----- 1 redis redis 0 Feb 12 00:59 appendonly.aof.1.incr.aof -rw-r----- 1 redis redis 88 Feb 12 00:59 appendonly.aof.manifest
AOF缓冲区刷新策略
如果把数据写入缓冲区 里,本质还是在内存中 啊,这个时候,突然进程挂了,怎么办?缓冲区数据是不是丢了?
是的,缓冲区中没有来的及写入硬盘的数据是会丢的。
保持数据完整性(实时更新)与redis性能是矛盾的,需要做出一些取舍。
redis给出一些选项,让程序员根据实际情况决定怎么取舍------这就是缓冲区的刷新策略。
- 刷新频率越高,性能影响就越大,同时数据可靠性就越高。
- 刷新频率越低,性能影响就越小,同时数据可靠性就越低。
redis提供了多种AOF缓冲区同步⽂件策略,由参数 appendfsync 控制
| 可配置值 | 说明 | 比较 |
|---|---|---|
| always | 命令写入 aof_buf 后调用 fsync 同步,完成后返回 | 频率最高,数据可靠性最高,性能最低 |
| everysec | 命令写入 aof_buf 后只执行 write 操作,不进行 fsync。每秒由同步线程进行 fsync。 | 频率低一点,数据可靠性降低,性能提高 |
| no | 命令写入 aof_buf 后只执行 write 操作,由 OS 控制 fsync 频率。 | 频率最低,数据可靠性最低,性能最高 |
bash
#配置文件中默认是everysec
# appendfsync always
appendfsync everysec
# appendfsync noAOF重写机制
随着AOF文件持续增长,体积越来越大,会影响到redis下次的启动时间。(redis启动的时候要读取AOF文件的内容)
AOF重写机制的核心是压缩 AOF 文件体积 ,解决因 "追加式写入" 导致的文件膨胀问题,节省磁盘空间。
次要但关键的价值是提升 Redis 重启时的数据恢复速度,保证服务可用性。
实际上上述的aof文件中,有一些内容是冗余的。
例子:
lpush key 111 + lpush key 222 + lpush key 333 → lpush key 111 222 333
set key 111 + set key 222 + set key 333 → set key 333
set key 111 + del key → 什么都不做
因此,redis 存在一个机制,能够针对 aof 文件进行整理操作。这个整理就是能够剔除其中冗余操作,合并一些操作,达到给 aof 文件进行瘦身的操作。
AOF重写过程可以手动触发和自动触发:
- ⼿动触发:调⽤
bgrewriteaof命令。 - ⾃动触发:根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定⾃动触发时
机。- auto-aof-rewrite-min-size:表⽰触发重写时 AOF 的最⼩⽂件⼤⼩,默认为 64MB。
- auto-aof-rewrite-percentage:代表当前 AOF 占⽤⼤⼩相⽐较上次重写时增加的⽐例。
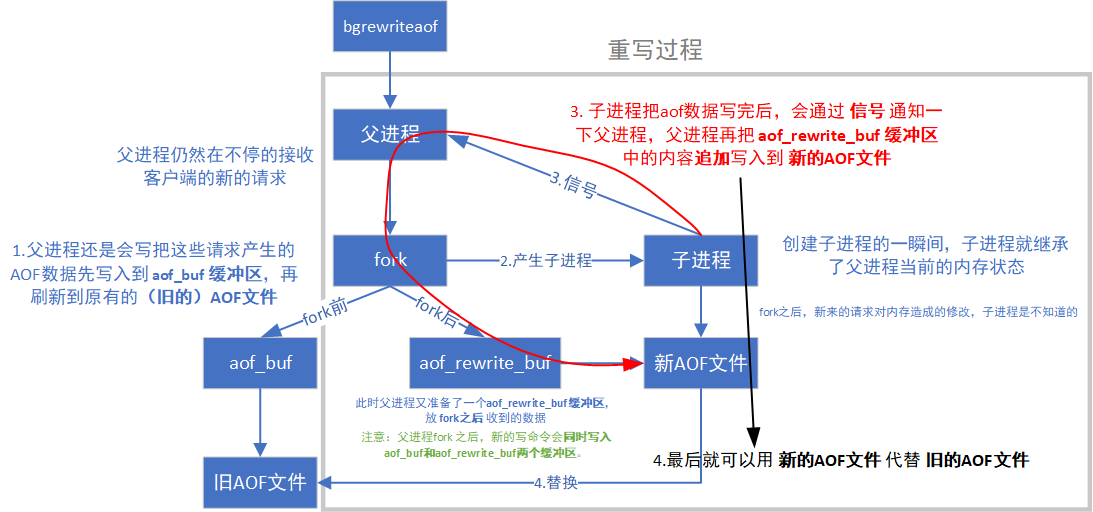
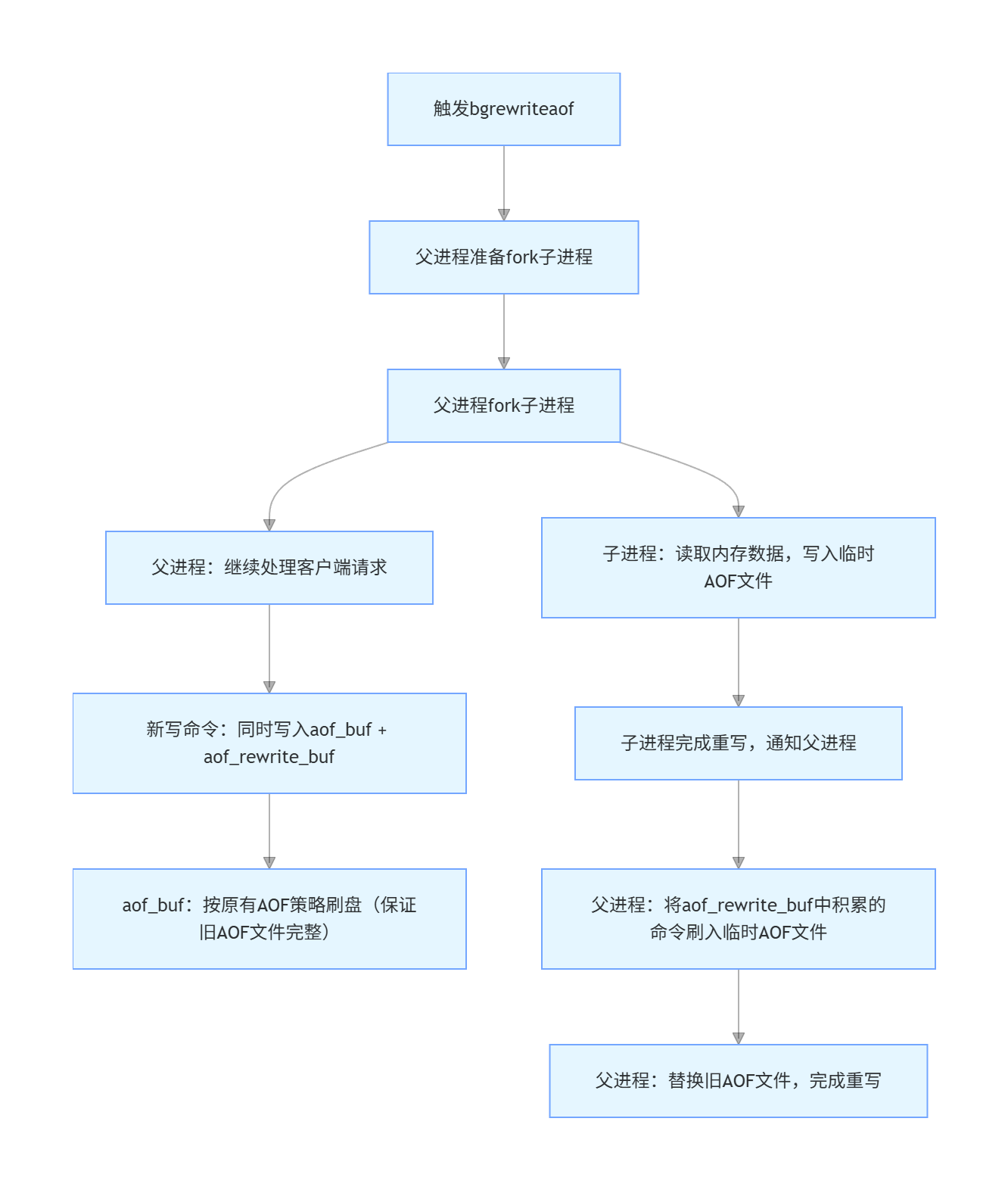
AOF重写流程
fork创建子进程
- 父进程仍然负责接收请求
- 子进程负责针对aof文件进行重写
注意:重写的时候,不关心aof文件中原来有什么内容,只是关心内存中最终的数据
子进程只需要把内存中当前的数据获取出来,以AOF格式写入到一个新的AOF文件中 ------重写的核心原理
内存中的数据的状态,就已经相当于是把AOF文件结果整理后的模样了。
此处子进程写数据的过程,非常类似于RDB生成一个镜像快照。
唯一区别:
- RDB是按照二进制的方式生成的
- AOF重写,则是按照AOF中要求的文本格式生成的
共同点 :都是为了把当前内存中的所有数据状态记录到文件中
问题:如果在执行bgrewriteaof的时候,当前redis已经正在进行aof重写了,会咋样?
答:不会再次aof重写,直接返回了。
问题:如果在执行bgrewriteaof的时候,发现当前redis在生成rdb文件的快照,会咋样?
答:aof重写操作会进行等待,等rdb快照生成完毕之后,在进行aof重写操作。
问题:最后新的AOF文件要替代旧的AOF文件,那父进程在fork后继续写旧的AOF文件是否还有意义?
答:有意义,这是 Redis 为了保证 AOF 重写过程中在极端情况下数据不丢失 的核心设计。
例子:再重写期间,子进程还在重写新的aof文件 ,服务器突然断电,新的aof文件是不完整的文件,只能依靠父进程写入的旧的aof文件,若父进程在重写期间没有在旧aof文件中写入,那将丢失重写期间所有的数据。
突然挂机的具体场景
场景1 :父进程 fork 后,继续写旧 AOF 文件(Redis 实际实现)
假设执行 bgrewriteaof 的完整时间线:
0 秒 :触发bgrewriteaof,父进程 fork 子进程,此时内存数据是 100 条命令,旧 AOF 文件包含这 100 条。
10 秒 :子进程还在重写临时 AOF 文件(刚写到 80 条),父进程处理了 20 条新命令,这些命令同时写入aof_buf(刷入旧 AOF)和aof_rewrite_buf,旧 AOF 文件现在有 120 条命令,aof_rewrite_buf缓存了 20 条。
11 秒:Redis 服务器突然断电挂机。
恢复过程 :
重启 Redis 时,因为重写还没完成,临时 AOF 文件不会被使用,Redis 会加载旧 AOF 文件(包含 120 条命令),最终仅丢失 "11 秒挂机瞬间可能还没刷盘的极少量命令"(由appendfsync策略决定,如 everysec 最多丢 1 秒数据),核心数据 120 条全部恢复。
场景 2 :父进程 fork 后,停止写旧 AOF 文件(反例)
同样的时间线:
0 秒 :fork 子进程,旧 AOF 文件有 100 条命令。
10 秒 :子进程还在重写(写到 80 条),父进程处理 20 条新命令,只写入aof_rewrite_buf,旧 AOF 文件仍停留在 100 条。
11 秒:服务器断电挂机。
恢复过程:
- 临时 AOF 文件只写到 80 条(不完整),且没合并aof_rewrite_buf的 20 条,无法用;
- 旧 AOF 文件只有 100 条,丢失了 10 秒内的 20 条新命令;
- 最终 Redis 只能恢复 100 条命令,20 条新数据永久丢失。
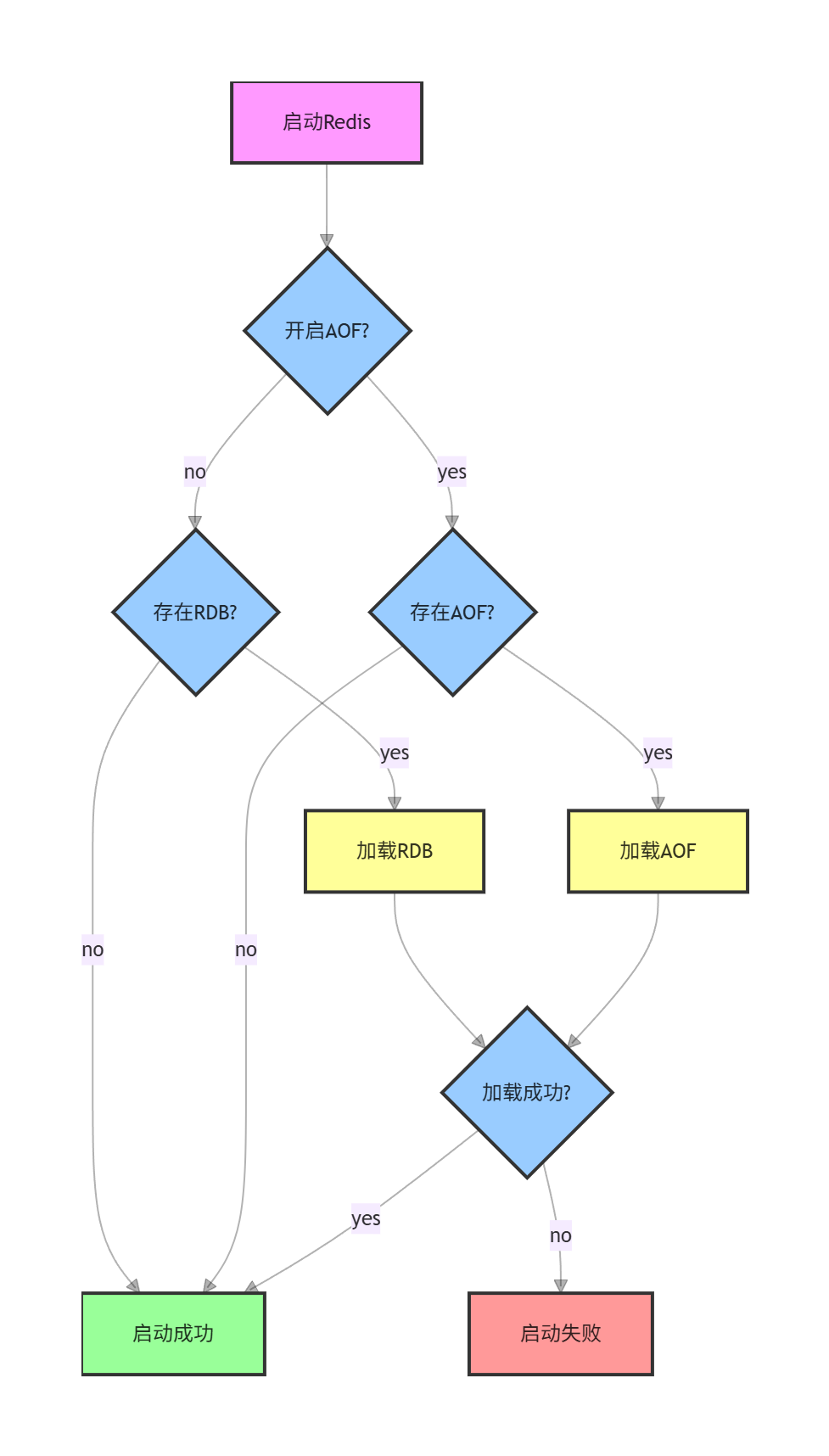
AOF文件与RDB文件同时存在的情况
当redis上同时存在aof文件和rdb快照时,此时以谁为主?
**以aof为主,rdb就直接被忽略了。**因为aof比rdb数据更全啊。
混合持久化
AOF本来是按照文本的方式来写入文件的,但是文本的方式写文件,后续加载成本是比较高的。
redis就引入了"混合持久化"的方式,结合了rdb与aof的特点。
- 按照aof的方式,每个请求/操作,都记录到文件。
- 在触发aof重写后,会把当前内存的状态按照rdb的二进制格式写入到新的aof文件中。
- 后续在进行的操作,仍然是按照aof文本的方式追加到文件后面。
配置文件中的选项
bash
# Redis can create append-only base files in either RDB or AOF formats. Using
# the RDB format is always faster and more efficient, and disabling it is only
# supported for backward compatibility purposes.
aof-use-rdb-preamble yes #yes表示开启混合持久化问题:同一个AOF文件里既存二进制又存文本,为什么不冲突?
这其实是Redis对文件格式的巧妙设计------混合持久化的AOF文件是"分段式"的,不同段有明确的格式标识,Redis能精准识别并解析。
混合持久化的AOF文件结构
混合持久化的AOF文件并不是"混乱地混合二进制和文本",而是有严格的格式划分,整体结构如下:
[AOF文件头部标识] + [RDB二进制数据段] + [AOF文本命令段]第三步的文本追加,是追加在RDB二进制段的后面,且两段之间有明确的分隔标记,Redis读取时能清晰区分,完全不冲突。
AOF文件的实际内容示例(简化版):
# 以下是RDB二进制数据段(不可读的二进制)
52 45 44 49 53 30 30 31 31 ...(二进制字节)
# 以下是Redis内置的分隔标记
[AOF段开始标记]
# 以下是文本格式的AOF命令(可读)
*3\r\n$3\r\nSET\r\n$1\r\na\r\n$3\r\n123\r\n
*3\r\n$3\r\nHSET\r\n$4\r\nuser\r\n$4\r\nname\r\n$8\r\nzhangsan\r\n当Redis重启恢复数据时,会按"先RDB、后AOF"的顺序解析:
- 先读取文件开头的RDB二进制段,快速加载全量基础数据(RDB的优势:加载速度快);
- 遇到分隔标记后,切换到AOF解析模式,逐条执行后面的文本命令,恢复重写后的增量数据(AOF的优势:数据完整性高)。
这样做的优势:
- RDB二进制段:负责全量数据,加载速度极快(解决纯AOF恢复慢的问题);
- AOF文本段:负责增量数据,记录每一条操作(解决纯RDB数据丢失多的问题);
举个例子
假设你操作Redis的流程:
- 写入
SET a 1、SET b 2、INCR a(此时内存中a=2,b=2); - 触发混合持久化重写,子进程把a=2、b=2以RDB二进制写入临时AOF文件;
- 接着你又写入
SET c 3、HSET user age 20; - 这两条新命令以文本形式追加到临时AOF文件的RDB段后面;
- 重写完成,临时文件替换旧AOF文件。
最终AOF文件内容:
[RDB二进制:记录a=2、b=2]
[分隔标记]
SET c 3(文本)
HSET user age 20(文本)Redis重启时:
- 先通过RDB段快速加载a=2、b=2;
- 再执行后面的文本命令,得到c=3、user:age=20;
- 最终恢复所有数据,既快又完整。
总结
- 混合持久化的AOF文件是"分段式"结构,RDB二进制段在前、AOF文本段在后,有明确的分隔标记,Redis能精准识别,完全不冲突;
- 文本追加,是追加在RDB段的后面,而非混合在RDB段中;
- 这种设计结合了RDB"加载快"和AOF"数据全"的优势,是对纯AOF、纯RDB的最优折中。