目录
[2.1 继承的定义格式](#2.1 继承的定义格式)
[2.2 三大继承方式与访问限定符](#2.2 三大继承方式与访问限定符)
[3.1 合法的赋值转换](#3.1 合法的赋值转换)
[3.2 非法的赋值转换](#3.2 非法的赋值转换)
[3.3 强制类型转换的注意事项(了解)](#3.3 强制类型转换的注意事项(了解))
[4.1 成员变量的隐藏](#4.1 成员变量的隐藏)
[4.2 成员函数的隐藏](#4.2 成员函数的隐藏)
[5.1 核心规则](#5.1 核心规则)
[5.2 代码演示](#5.2 代码演示)
[6.1 继承与友元](#6.1 继承与友元)
[6.2 继承与静态成员](#6.2 继承与静态成员)
[7.1 菱形继承的问题(重点)](#7.1 菱形继承的问题(重点))
[7.2 菱形虚拟继承(重点)](#7.2 菱形虚拟继承(重点))
[问题 1:菱形虚拟继承为啥用虚基表存储偏移量?](#问题 1:菱形虚拟继承为啥用虚基表存储偏移量?)
[问题 2:什么时候需要用偏移量访问共享数据?](#问题 2:什么时候需要用偏移量访问共享数据?)
[问题 3:菱形虚拟继承是否解决了数据冗余问题?](#问题 3:菱形虚拟继承是否解决了数据冗余问题?)
[8.1 对 C++ 多继承的客观认知](#8.1 对 C++ 多继承的客观认知)
[8.2 继承与组合的区别](#8.2 继承与组合的区别)
一、继承的概念
在 C++ 中,继承 (inheritance) 允许程序员在保持原有类(基类 / 父类)特性的基础上,扩展功能生成新的类(派生类 / 子类),是区别于函数复用的类设计层次复用,完美契合了从简单到复杂的认知逻辑。
简单来说,继承让派生类天然拥有基类的所有成员(成员变量 + 成员函数),无需重复编写代码,极大提升了开发效率和代码可维护性。比如定义表示 "人" 的Person类,再通过继承派生出Student和Teacher类,二者可直接复用Person的姓名、年龄等属性和打印方法,只需新增各自的特有属性(学号、工号)即可。
示例代码:
cpp
#include <iostream>
#include <string>
using namespace std;
// 基类/父类:Person
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "peter"; // 姓名
int _age = 18; // 年龄
};
// 派生类/子类:Student 公有继承 Person
class Student : public Person
{
protected:
int _stuid; // 学号(特有属性)
};
// 派生类/子类:Teacher 公有继承 Person
class Teacher : public Person
{
protected:
int _jobid; // 工号(特有属性)
};
int main()
{
Student s;
Teacher t;
s.Print(); // 复用基类Print方法
t.Print(); // 复用基类Print方法
return 0;
}从代码中能清晰看到,Student和Teacher未定义Print方法,却能直接调用,这就是继承带来的代码复用效果。
二、继承的基本定义
要灵活使用继承,首先要掌握其定义格式和核心的访问限定规则,这是避免继承中成员访问错误的基础。
2.1 继承的定义格式
派生类的定义遵循固定格式,核心是派生类 + 继承方式 + 基类,其中继承方式和基类的访问限定符共同决定了基类成员在派生类中的访问权限。
cpp
class 派生类名 : 继承方式 基类名
{
// 派生类的成员
};示例中class Student : public Person就是标准格式,public为继承方式,Person为基类。
2.2 三大继承方式与访问限定符
C++ 提供三种继承方式:public(公有继承)、protected(保护继承)、private(私有继承);类成员的访问限定符同样有这三种,二者组合后,基类成员在派生类中的访问权限遵循严格的规则。
| 基类成员 / 继承方式 | public 继承 | protected 继承 | private 继承 |
|---|---|---|---|
| 基类 public 成员 | 派生类 public | 派生类 protected | 派生类 private |
| 基类 protected 成员 | 派生类 protected | 派生类 protected | 派生类 private |
| 基类 private 成员 | 不可见 | 不可见 | 不可见 |
基类 private 成员始终不可见:基类的私有成员会被继承到派生类对象中,但语法上限制派生类无论在类内还是类外都无法访问,这是封装性的体现。
protected 的专属价值 :若基类成员不想被类外访问,但需要让派生类访问,就定义为protected------保护成员限定符是因继承而诞生的。
权限取最小值 :基类非私有成员在派生类中的访问权限 = Min(成员在基类的访问限定符, 继承方式),权限优先级:public > protected > private。
默认继承方式 :使用class定义类时,默认继承方式为private;使用struct时,默认继承方式为public,建议显式写出继承方式,提升代码可读性。
实战首选公有继承 :实际开发中几乎只使用public继承,protected/private继承会让派生类的成员仅能在类内使用,扩展和维护性极差,不推荐使用。
三、基类与派生类的对象赋值转换
继承体系中,基类和派生类的对象、指针、引用之间存在特定的赋值转换规则,核心被称为切片(切割) ------ 将派生类中属于基类的那部分成员 "切下来" 赋值给基类对象,具体规则如下,这是面试高频考点。
3.1 合法的赋值转换
派生类对象可以直接赋值给基类的对象、基类的指针、基类的引用,这是编译器自动完成的隐式转换,本质就是切片。
cpp
class Person
{
protected:
string _name;
string _sex;
int _age;
};
class Student : public Person
{
public:
int _No; // 学号
};
void Test()
{
Student sobj;
// 合法:子类对象赋值给父类对象/指针/引用(切片)
Person pobj = sobj;
Person* pp = &sobj;
Person& rp = sobj;
}
对象切片:把派生类对象里属于基类的成员,拷贝赋值给新的基类对象(派生类特有成员被丢弃);
指针 / 引用切片:基类指针(引用)直接指向(绑定)到派生类对象中属于基类的那部分内存,并非新建对象,只是只能访问基类成员。
小tip:子类对象赋值给父类对象不会产生临时变量
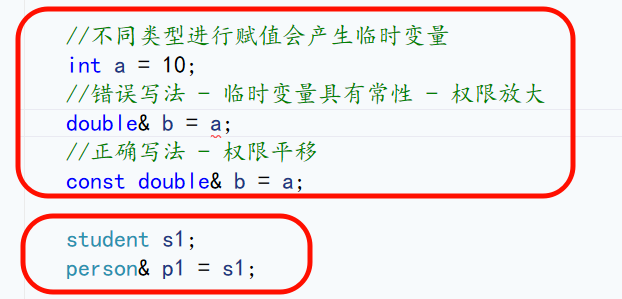
3.2 非法的赋值转换
基类对象不能直接赋值给派生类对象,因为基类对象缺少派生类的特有成员,无法完成完整的赋值。

3.3 强制类型转换的注意事项(了解)
基类的指针 / 引用可以通过强制类型转换 赋值给派生类的指针 / 引用,但仅当基类指针 / 引用指向派生类对象时才安全,否则会导致越界访问。
cpp
void Test()
{
Student sobj;
Person pobj;
Person* pp = &sobj;
// 安全:基类指针指向派生类对象,强制转换后可访问派生类成员
Student* ps1 = (Student*)pp;
ps1->_No = 10;
pp = &pobj;
// 危险:基类指针指向基类对象,强制转换后访问派生类成员会越界
Student* ps2 = (Student*)pp;
ps2->_No = 10; // 未定义行为
}若基类是多态类型,可使用dynamic_cast进行安全的类型转换(依赖 RTTI 运行时类型识别),后续讲解多态时会详细说明。
四、继承中的作用域
继承体系中,基类和派生类拥有相互独立的作用域 ,这是理解成员隐藏的关键。当子类和父类出现同名成员时,会触发隐藏(重定义) 规则,这是继承中最容易踩坑的点之一。
4.1 成员变量的隐藏
子类和父类的同名成员变量,子类成员会屏蔽父类对同名成员的直接访问,若想在子类中访问父类的同名成员,需通过基类::基类成员显式指定。
cpp
class Person
{
protected:
string _name = "小李子";
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << "姓名:" << _name << endl;
cout << "身份证号:" << Person::_num << endl; // 显式访问父类同名成员
cout << "学号:" << _num << endl; // 访问子类自身成员
}
protected:
int _num = 999; // 学号:与父类_num同名,触发隐藏
};
void Test()
{
Student s1;
s1.Print(); // 输出:小李子 111 999
}4.2 成员函数的隐藏
成员函数的隐藏只需函数名相同即可触发,与函数的参数列表、返回值无关,这一点与函数重载(同一作用域、函数名相同 + 参数列表不同)有本质区别。
cpp
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
// 函数名相同,触发隐藏,与参数无关
void fun(int i)
{
A::fun(); // 显式调用父类同名函数
cout << "func(int i)->" << i << endl;
}
};
void Test()
{
B b;
b.fun(10); // 调用子类的fun(int)
// b.fun(); // 编译错误:父类fun被隐藏,需显式调用A::fun()
}小tip:
在继承体系中,尽量不要定义同名的成员,无论是成员变量还是成员函数,都会增加代码的混淆度,提升调试难度。
五、派生类的默认成员函数
C++ 中每个类都有六个默认成员函数(构造、拷贝构造、赋值重载、析构、取地址重载、const 取地址重载),若程序员不写,编译器会自动生成。在继承体系中,派生类的默认成员函数并非完全独立生成,而是需要调用基类的对应成员函数,完成基类部分的初始化和清理,核心规则共 7 条,是继承的核心重点。
5.1 核心规则
①. 基类无默认构造函数时,派生类必须在初始化列表显式调用基类构造函数。
②. 派生类的拷贝构造函数必须调用基类的拷贝构造,完成基类成员的拷贝初始化。
③. 派生类的
operator=必须调用基类的operator=,完成基类成员的赋值。④. 派生类的析构函数执行完毕后,编译器会自动调用基类的析构函数,保证先清理派生类成员、再清理基类成员的顺序。
⑤. 派生类对象的初始化顺序:先调用基类构造,再调用派生类构造。
⑥. 派生类对象的析构顺序:先调用派生类析构,再调用基类析构(与构造顺序相反)。
⑦. 析构函数的隐藏:编译器会将所有析构函数名统一处理为
destructor(),因此父类析构函数不加virtual时(后续多态会进行讲解),子类析构函数与父类析构函数构成隐藏。
**总结一下:**基类负责初始化和清理自己的成员,派生类负责初始化和清理自己新增的成员,两者分工明确,互不越界。
5.2 代码演示
cpp
class Person
{
public:
// 基类构造函数
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
// 基类拷贝构造
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
// 基类赋值重载
Person& operator=(const Person& p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
// 基类析构函数
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name;
};
class Student : public Person
{
public:
// 派生类构造:初始化列表显式调用基类构造
Student(const char* name, int num)
: Person(name)
, _num(num)
{
cout << "Student()" << endl;
}
// 派生类拷贝构造:初始化列表显式调用基类拷贝构造
Student(const Student& s)
: Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
// 派生类赋值重载:显式调用基类赋值重载
Student& operator=(const Student& s)
{
cout << "Student& operator=(const Student& s)" << endl;
if (this != &s)
{
Person::operator=(s); // 调用基类赋值重载
_num = s._num;
}
return *this;
}
// 派生类析构:编译器自动调用基类析构
~Student()
{
cout << "~Student()" << endl;
}
protected:
int _num;
};小tips:
取地址重载和const取地址重载在继承中无特殊规则,编译器自动生成的版本即可满足需求,实战中几乎无需自定义实现。
问题:为何析构函数的调用顺序是:派生类、基类?
cpp
class Parent {
public:
char* buf; // 父类动态资源
Parent() { buf = new char[1]; }
~Parent() { delete[] buf; buf = nullptr; cout << "父类析构:buf已释放" << endl; }
};
class Child : public Parent {
public:
~Child() {
// 子类析构使用父类已释放的buf → 野指针访问
buf[0] = 'x';
cout << "子类析构:使用父类buf(野指针)" << endl;
}
};继承体系中,派生类析构可能使用基类动态资源,若先析构基类会释放资源产生野指针导致崩溃;而基类析构不会使用派生类资源,因此必须先析构派生类、再析构基类,确保资源安全释放。
六、继承的特殊场景:友元与静态成员
6.1 继承与友元
基类的友元可以访问基类的私有和保护成员,但无法访问派生类的私有和保护成员 ,即友元关系不具有传递性。
cpp
class Student;
class Person
{
public:
friend void Display(const Person& p, const Student& s); // 友元函数
protected:
string _name;
};
class Student : public Person
{
protected:
int _stuNum; // 派生类保护成员
};
// 友元函数可访问基类_name,但无法直接访问派生类_stuNum(编译错误)
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
// cout << s._stuNum << endl; // 错误:友元关系不能继承
}6.2 继承与静态成员
基类中定义的static静态成员,在整个继承体系中只有一份实例,无论派生出多少个子类,所有类的对象共享这一个静态成员。
cpp
class Person
{
public:
Person() { ++_count; }
static int _count; // 静态成员:统计人数
protected:
string _name;
};
int Person::_count = 0; // 静态成员类外初始化
class Student : public Person
{
protected:
int _stuNum;
};
class Graduate : public Student
{
protected:
string _seminarCourse;
};
void TestPerson()
{
Student s1, s2, s3;
Graduate s4;
cout << "人数:" << Person::_count << endl; // 输出:4(所有对象共享_count)
Student::_count = 0;
cout << "人数:" << Person::_count << endl; // 输出:0(修改子类静态成员,基类也会变化)
}静态成员的访问方式:基类::静态成员 或**派生类::静态成员**,本质访问的是同一个实例。
七、菱形继承
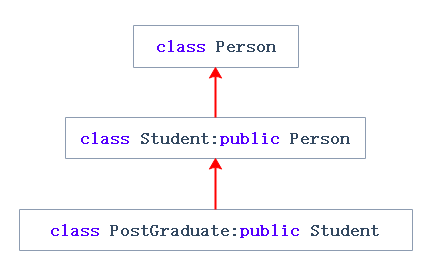
**单继承:**一个子类只有一个直接父类时称这个继承关系为单继承
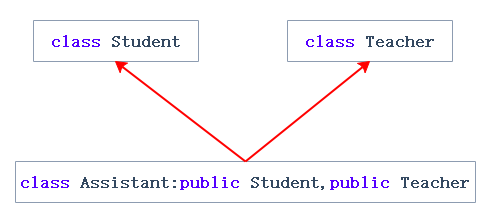
**多继承:**一个子类有两个或以上直接父类时称这个继承关系为多继承
**菱形继承:**菱形继承是多继承的一种特殊情况
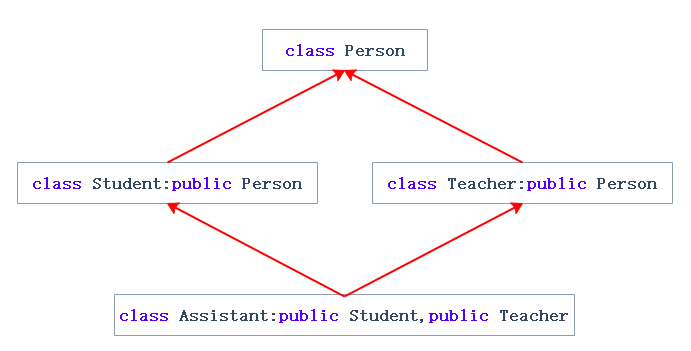
7.1 菱形继承的问题(重点)
菱形继承的底层问题是数据冗余 和二义性,即派生类对象中会包含多份基类成员,导致访问基类成员时无法确定具体访问哪一份。
cpp
class A
{
public:
int _a;
};
class B : public A
{
public:
int _b;
};
class C : public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};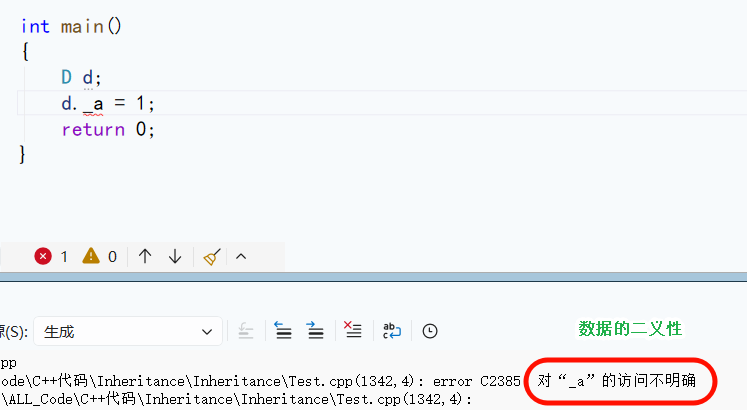

用域作用限定符解决了二义性问题,但是没有解决数据冗余问题
7.2 菱形虚拟继承(重点)
虚拟继承 是 C++ 专门为解决菱形继承问题设计的特性,在菱形继承的中间层子类(B、C)继承基类(A)时,添加virtual关键字,即可让最终的派生类(D)只保留一份基类成员,同时解决二义性和数据冗余。
cpp
class A
{
public:
int _a;
};
class B : virtual public A
{
public:
int _b;
};
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};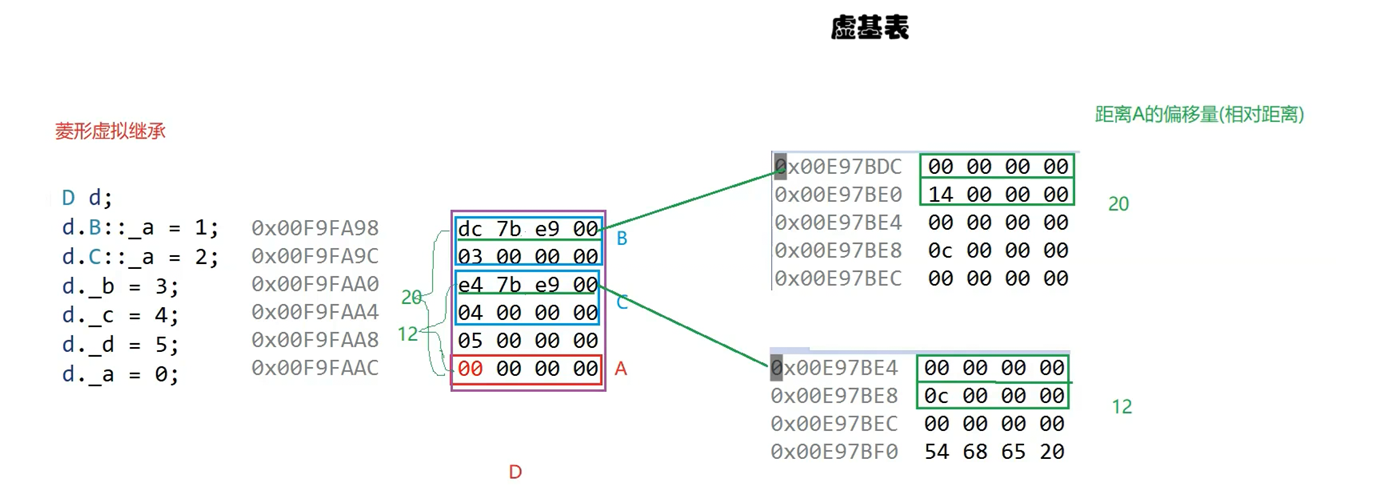
虚拟继承的底层通过虚基表指针 和虚基表实现:
在虚拟继承的中间层子类(如 B、C)对象中,会增加一个虚基表指针,指向对应的虚基表。
虚基表中存储的是虚基类成员在派生类对象中的偏移量,中间层子类通过该偏移量,即可在运行时定位到唯一的基类成员实例。
在最终的派生类(D)对象中,虚基类(A)的成员会被放置在对象内存布局的最底部,由所有中间层子类共享,从而保证整个继承体系中仅存在一份基类实例,避免了数据冗余与二义性。
注意:虚拟继承的设计初衷是解决菱形继承问题,不应在其他场景随意使用,其底层的虚基表与偏移量查找机制会带来一定的性能开销。
问题 1:菱形虚拟继承为啥用虚基表存储偏移量?
当有多个虚基类时,会产生多个偏移量。如果直接将这些偏移量存在对象中,创建大量对象时会重复存储相同数据,造成内存浪费。而将偏移量统一存到类级别的虚基表中,每个对象只需用一个指针指向该表,即可共享所有偏移量,大幅节省内存,同时保证在不同继承场景下都能正确定位虚基类。
在只有单个虚基类的场景下,两种方式的内存占用几乎无差别,此时虚基表的核心价值在于通用性:同一个中间层类(B)在不同的继承环境(如独立的 B 对象或派生类 D 中),到虚基类 A 的偏移量不同,通过虚基表指针可动态查表,保证在任何继承场景下都能正确定位虚基类。
问题 2:什么时候需要用偏移量访问共享数据?
1. 直接访问(无需偏移量)
当你用最终派生类对象(如 D d)直接访问虚基类成员时:
cpp
D d1;
d1._a = 1;此时,虚基类 A 的位置在编译期就已确定,编译器可以直接计算出 _a 的地址,不需要在运行时通过虚基表动态查找偏移量来计算。
2. 切片访问(必须用偏移量)
当你用基类指针(如 B* pb)指向派生类对象(如 D d),并通过该指针访问虚基类成员时:
cpp
D d;
B* pb = &d;
pb->_a = 1;独立 B 对象 :编译期就能确定 B→A 的固定偏移量,直接用这个偏移量访问 A;
D 中切片的 B 子对象 :编译期不知道 该用哪个偏移量(因为不知道 pb 指向的是独立 B 还是 D 中的 B),所以只能在运行时通过虚基表查 "当前场景下的正确偏移量",再用这个偏移量访问 A。
| 类型 | 偏移量特点 | 访问方式 |
|---|---|---|
| 编译期确定偏移量 | 偏移量在编译时就已固定 | 直接使用该偏移量,无需运行时动态查询 |
| 运行时动态查偏移量 | 偏移量在编译期无法确定 | 必须在运行时通过虚基表等机制查询后才能访问 |
问题 3:菱形虚拟继承是否解决了数据冗余问题?

虽然虚拟继承会引入虚基表指针(图中每个指针占 4 字节),看起来多了一点内存开销,但当虚基类 A 的成员越多、体积越大时,这份指针的开销就越微不足道,整体来看内存效率反而更高。
问题 4:菱形虚继承中构造函数的调用顺序
cpp
class A
{
public:
A(const char* s) { cout << s << endl; }
~A() {}
};
class B :virtual public A
{
public:
B(const char* sa, const char* sb) :A(sa) { cout << sb << endl; }
};
class C :virtual public A
{
public:
C(const char* sa, const char* sb) :A(sa) { cout << sb << endl; }
};
class D :public B, public C
{
public:
D(const char* sa, const char* sb, const char* sc, const char* sd)
:B(sa, sb), C(sa, sc), A(sa)
{
cout << sd << endl;
}
};
int main()
{
D* p = new D("class A", "class B", "class C", "class D");
delete p;
return 0;
}
对于菱形虚拟继承来说,虚基类 A 会被整个继承体系共享,不再属于 B 和 C 各自私有,因此在构造最底层的 D 对象时, A 只会被构造一次。至于调用顺序是 A → B → C → D,这是因为:
1、虚基类 A 总是最先被构造。
2、非虚基类 B 和 C 的顺序,取决于 D 类的继承声明顺序(public B, public C),而非构造函数初始化列表的顺序。
3、最后才会执行派生类 D 自身的构造函数。
至于为啥基类先构造,是因为派生类的构造函数可能会使用基类的成员。如果先构造派生类,就会出现使用未初始化基类成员的风险,从而导致程序错误
八、继承和组合
掌握了继承的所有语法规则后,更重要的是理解继承的设计原则------ 何时该用继承,何时该用更优的组合?这是体现 C++ 设计思维的关键。
8.1 对 C++ 多继承的客观认知
多继承是 C++ 语法复杂的重要体现,菱形继承和菱形虚拟继承的底层实现繁琐,易引发问题,实际开发中应尽量避免设计多继承,坚决避免菱形继承。
多继承被认为是 C++ 的缺陷之一,后续的面向对象语言(如 Java、C#)都取消了多继承,仅保留单继承 + 接口的方式,规避了菱形继承的问题。
8.2 继承与组合的区别
类之间的关系主要分为两种,对应两种复用方式:继承(is-a) 和组合(has-a),二者的设计思想和适用场景有本质区别。

| 特性 | 继承(is-a 关系) | 组合(has-a 关系) |
|---|---|---|
| 关系描述 | 每个派生类对象都是一个基类对象 | 假设 B 组合了A,每个 B 对象中都有一个 A 对象 |
| 复用类型 | 白箱复用:基类内部细节对子类可见 | 黑箱复用:被组合类内部细节对组合类不可见 |
| 封装性 | 破坏基类封装,基类修改会影响派生类 | 保持封装,被组合类修改对组合类影响极小 |
| 耦合度 | 高耦合:派生类与基类强依赖 | 低耦合:组合类与被组合类弱依赖 |
| 扩展性 | 派生类受基类限制,扩展性差 | 基于接口组合,扩展性强 |
九、经典面试题
1、什么是菱形继承?
菱形继承是 C++ 多继承中的一种特殊场景,比如有一个基类 A,类 B 和 C 都继承自 A,然后类 D 又同时继承 B 和 C,整个继承结构画出来就像一个菱形。
2、菱形继承的问题是什么?
它主要会带来两个核心问题:
数据冗余:基类 A 的成员会在 D 里存两份,一份来自 B,一份来自 C,这会浪费内存。
二义性:当你在 D 中访问 A 的成员时,编译器不知道该用 B 分支的还是 C 分支的,直接编译报错。
而且这种结构会让代码耦合度变高,后续维护起来也很麻烦。
3、什么是菱形虚拟继承?它是如何解决数据冗余和二义性的?
菱形虚拟继承就是在 B 和 C 继承 A 时加上 virtual 关键字,让 A 成为整个继承体系的虚基类。这样,在最底层的 D 中,A 就只会存在一份实例,彻底解决了数据冗余。
同时,因为只有一份 A,访问时也就不存在二义性了。需要注意的是,虚基类 A 是由最底层的 D 来直接初始化的,而不是由 B 或 C 初始化。
4、继承和组合的区别是什么?
最核心的区别在于它们的语义和复用方式:
继承(is-a 关系):代表 "是一种" 的关系,比如 Student 是一种 Person。它是白盒复用,子类可以直接访问父类的 public 和 protected 成员,好处是复用代码很直接,但坏处是耦合度高,父类的改动可能会影响到子类。
组合(has-a 关系):代表 "包含一个" 的关系,比如 Car 包含一个 Engine。它是黑盒复用,外部类只能通过成员对象的 public 接口来使用,看不到内部实现,好处是耦合度低,代码更稳定、灵活。
5、什么时候用继承?什么时候用组合?
用继承的场景:当类之间有明确的 is-a 关系,并且满足里氏替换原则(子类可以完全替代父类)时。比如 Square 继承 Shape,因为正方形确实是一种形状,而且可以在任何需要 Shape 的地方用 Square 代替。
用组合的场景:当类之间是 has-a 的包含关系,或者你想降低耦合、保持代码灵活性时。比如 Computer 组合 CPU,电脑包含 CPU,但它们不是 "是一种" 的关系。组合也是实现依赖倒置原则的常用手段,能让代码更容易扩展。
当然也有这样的经验法则:在一个场景中,如果既可以用组合也可以用继承,那就优先选择组合,因为组合的耦合度更低,扩展性更好;如果场景中只能用继承(比如必须复用基类接口并满足 is-a 关系),那就只能选择继承。