自然语言理解、摘要生成、代码编写、逻辑推理,OpenAI 等厂商的模型把这些事情做得相当好。但是只有一个问题,那就是 "贵".尤其是在应用上了规模之后,API 调用费用的增长速度会让人心跳加速。
Prompt 缓存是应对这个问题最直接也最容易被忽视的手段。本文会从原理讲到实践,覆盖四种不同层级的缓存策略,配有代码示例和架构图。
LLM 的成本为什么涨得这么快
LLM API 的定价模型就三个维度:输入 Token 数(也就是 Prompt 长度)、输出 Token 数(响应长度)、调用次数。
比如FAQ 机器人、聊天式新人引导助手、内部开发者工具、AI 仪表板------这些应用有一个共同特征:大量重复或高度相似的 Prompt 被反复发送,而期望得到的回答几乎一样。
如果不做缓存的话,每次调用都要按量计费,那费用肯定就爆炸了。
Prompt 缓存是什么
一句话概括:
当相同或等价的 Prompt 再次出现时,直接复用之前的 LLM 响应,而不是重新调用 API。
先查缓存,命中就直接返回;没命中再去调 LLM,拿到结果后存入缓存。
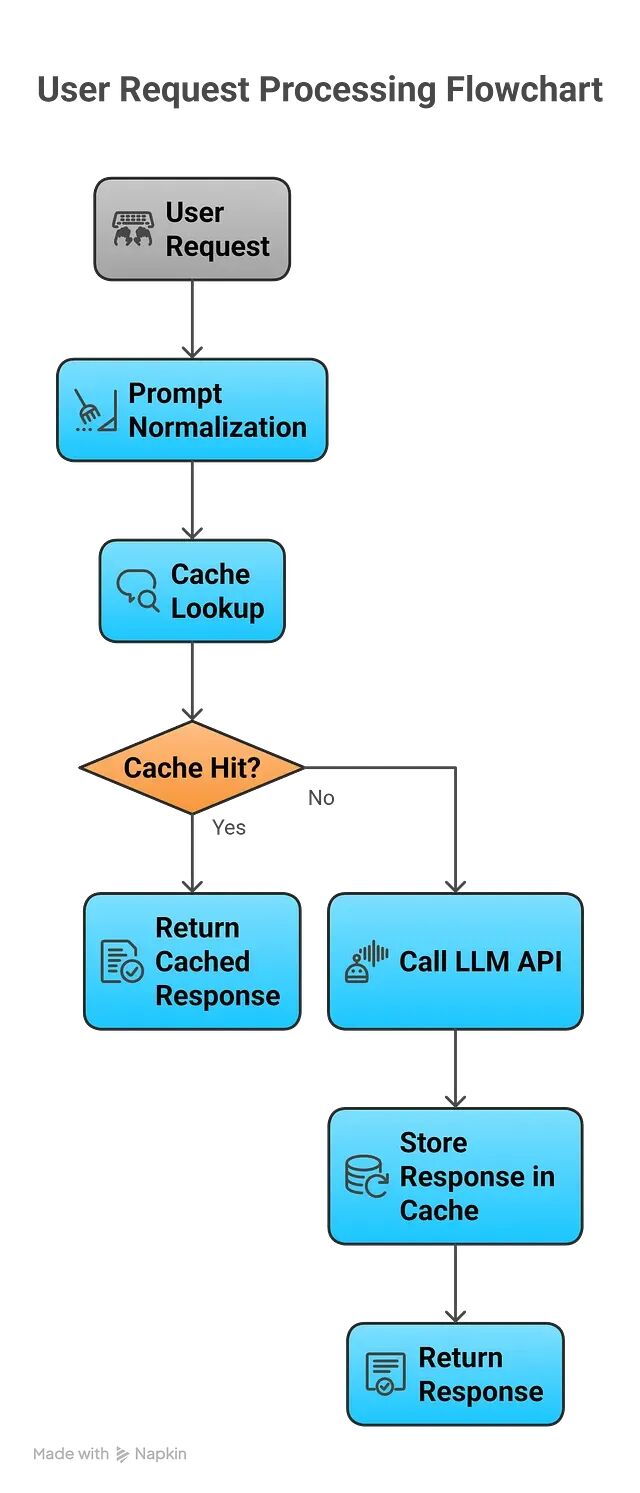
就这一个改动,成本就能降低 30%--90%,具体数字取决于工作负载的重复程度。
策略 1:精确匹配缓存
这是最基础的方案。逻辑非常简单:完全相同的 Prompt 字符串出现时,直接返回缓存结果。
适用场景包括静态 FAQ、政策说明文档、"解释 X"这一类 Prompt,以及聊天机器人中反复出现的 system prompt。
下面是 Node.js 的实现:
import crypto from "crypto";
const cache = new Map();
function hashPrompt(prompt) {
return crypto.createHash("sha256").update(prompt).digest("hex");
}
async function getLLMResponse(prompt) {
const key = hashPrompt(prompt);
// Step 1: Cache lookup
if (cache.has(key)) {
return cache.get(key);
}
// Step 2: Call LLM API
const response = await callLLM(prompt);
// Step 3: Store in cache
cache.set(key, response);
return response;
}为什么要对 Prompt 做哈希?因为 Prompt 本身可能很长,哈希之后得到固定长度的 key,查找速度快,SHA-256 的碰撞概率也低到可以忽略。
内存缓存的优点是极快,单实例或小规模系统用起来非常合适。但是这样做也进程重启缓存就没了,多实例之间也无法共享。
策略 2:规范化缓存
精确匹配有一个很容易遇到的问题:Prompt 里多一个空格、少一个换行、大小写不同,就被当成不同的 key 了。实际上这些差异对语义毫无影响。
解决办法是在缓存前先做规范化处理。举个例子:
规范化之前:
"Explain REST APIs"
"Explain REST APIs "
"Explain REST APIs"规范化之后全部变成:
"explain rest apis"代码实现:
function normalizePrompt(prompt) {
return prompt
.toLowerCase()
.replace(/\s+/g, " ")
.trim();
}
function getCacheKey(prompt) {
return hashPrompt(normalizePrompt(prompt));
}不必要的 cache miss 减少了,命中率明显上升,同时整个过程依然是确定性的、安全的。
策略 3:语义缓存
"What is REST?" 和 "Explain REST architecture" 说的其实是同一件事,但无论精确匹配还是规范化匹配都会把它们当作两个完全不同的请求。
所以思路是引入向量嵌入。把 Prompt 编码成向量,通过余弦相似度之类的指标判断两个 Prompt 是否"足够接近"。如果相似度超过阈值,直接返回缓存结果。
语义缓存流程
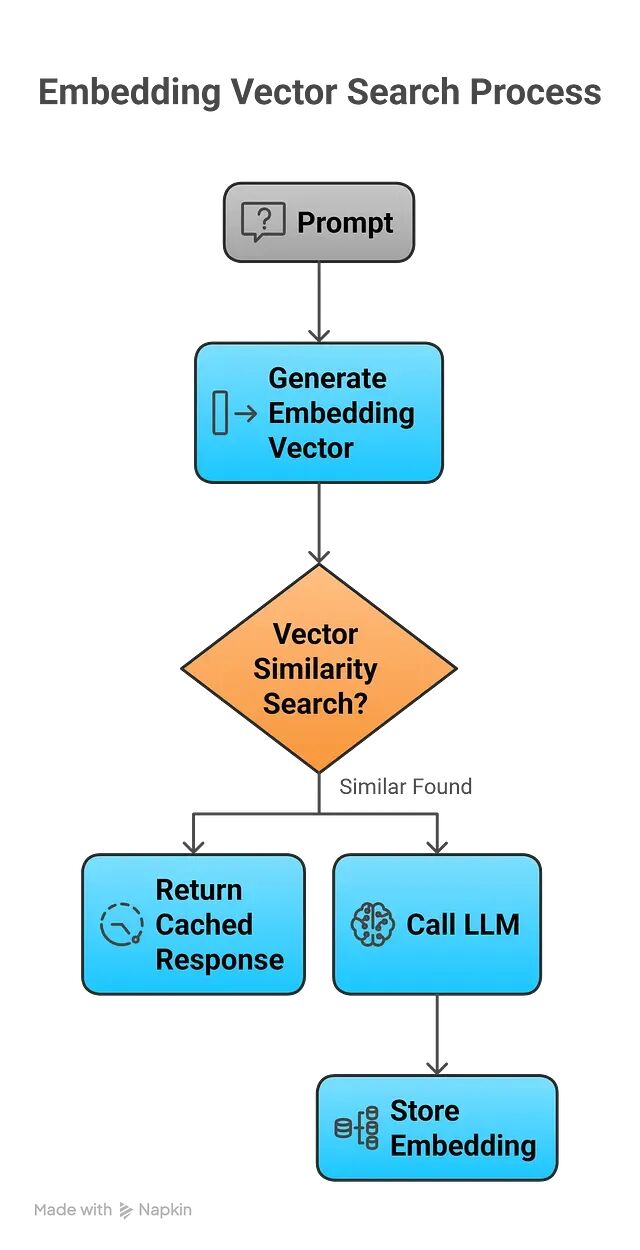
工具选型方面,Embedding 可以用 OpenAI 的接口,向量存储可以选 Pinecone、Weaviate 这类专门的向量数据库,小规模场景下在内存里做相似度搜索也够用。
伪代码如下:
const SIMILARITY_THRESHOLD = 0.90;
async function getSemanticResponse(prompt) {
const embedding = await getEmbedding(prompt);
const match = await vectorDB.findClosest(embedding);
if (match && match.score > SIMILARITY_THRESHOLD) {
return match.response;
}
const response = await callLLM(prompt);
await vectorDB.store({
embedding,
response
});
return response;
}语义缓存的风险
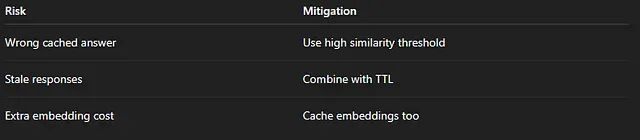
语义缓存的核心风险在于阈值设定。设得太低会把不相关的 Prompt 混为一谈,返回错误结果;设得太高又和精确匹配没什么区别。0.90 是一个比较常见的起步值,具体数字需要根据业务场景调优。
策略 4:分层缓存架构
生产环境一般不会只用单一缓存策略,而是按层级组合。典型的三层架构长这样:
L1 Cache (In-memory, per instance)
|
L2 Cache (Redis / Shared Cache)
|
L3 Semantic Cache (Vector DB)
|
LLM Provider每一层的定位不同。L1 是进程内存缓存,速度最快但作用域最小;L2 一般用 Redis,多个实例可以共享同一份缓存;L3 是语义缓存层,处理那些文本不同但意思相近的 Prompt。只有三层都没命中的情况下,请求才会打到 LLM Provider。
缓存过期与失效
Prompt 缓存不能"设了就忘"。以下几种情况必须主动失效:模型版本升级了,Prompt 模板改了,或者缓存的内容涉及时效性信息。
最简单的做法是设 TTL:
cache.set(key, response, {
ttl: 60*60*24// 24 hours
});成本影响
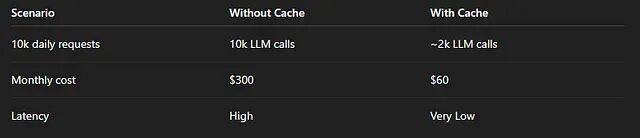
缓存带来的收益是双重的------成本下降,延迟也降低了。对于重复率高的工作负载,这两个指标的改善都非常可观。
总结
在 LLM 系统的各种优化手段中,Prompt 缓存的投入产出比可能是最高的。入手门槛低,可以渐进式迭代,而且到了一定规模之后几乎是刚需。
可以先从精确缓存做起,这是成本最低、风险最小的方案。规范化处理应该尽早加上,代码量很小但效果明显。语义缓存只在业务确实需要时才引入,因为它带来了额外的复杂度和向量计算开销。TTL 和版本控制是必须配套的机制。最后缓存命中率要持续监控,因为这是判断缓存策略是否有效的核心指标。
如果正在生产环境跑 AI 系统却没做 Prompt 缓存,可以试试上面的方法,肯定会为你省钱。
https://avoid.overfit.cn/post/10623b71c58d425dae471f5333a54e4c
作者: Vasanthan K