集群
- 引言
- [一、啥是 Redis 集群?](#一、啥是 Redis 集群?)
- 二、集群的核心机制:数据分片
- 三、集群的节点管理:扩容与缩容
- 四、故障处理与高可用维护
- 五、监控与性能优化
- 总结
引言
在上一篇文章中,我们深入探讨了 Redis Sentinel(哨兵)机制 。我们了解到,通过哨兵集群,我们可以实现自动故障转移(Failover),即使主节点挂了,从节点也能迅速顶上,保证服务不中断。这解决了 "高可用性" 的问题。
但是,哨兵机制有一个无法回避的局限:它本质上还是"单机"存储。
- 容量瓶颈: 无论哨兵多么智能,数据最终还是存在某一台物理机器的内存里。如果业务数据量激增(比如从几十GB涨到几TB),单台机器的内存总有装不下的那一天。
- 性能瓶颈: 虽然 Redis 是内存数据库,速度极快,但单台机器的 CPU 和网络带宽也是有限的。如果并发请求量巨大,单台 Redis 也会出现性能瓶颈,响应变慢。
怎么办? 既然一台机器不够用,那就用 多台机器 一起来扛!
这就引出了我们今天的主角------Redis Cluster(Redis 集群)。
一、啥是 Redis 集群?
简单来说,Redis 集群(Cluster)就是将数据分散存储在多台机器上。
- 核心思想: 分而治之(Sharding)。不再把所有的鸡蛋放在同一个篮子里,而是把篮子打碎,鸡蛋分开放。
- 架构特点: 集群中的每个节点(Node)都是一个独立的 Redis 实例。它们彼此通过 Gossip 协议(流言协议)互相通信,交换状态信息。
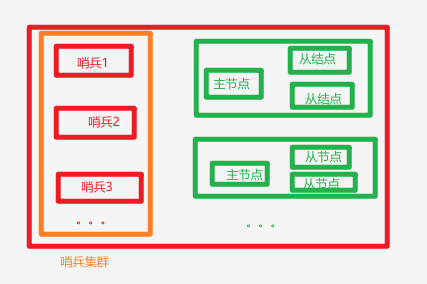
- 常见架构: 如图为多主多从架构
二、集群的核心机制:数据分片
集群最核心的机制就是数据分片。它是如何决定一条数据存到哪台机器上的呢?
这里引入一个关键概念:哈希槽(Hash Slot)。
Redis 集群并没有采用简单的"取模"算法(比如 key % N),而是引入了 16384 个哈希槽。所有的键都会通过 CRC16 算法计算出一个哈希值,然后映射到这 16384 个槽中的某一个。
- 分配规则: 集群启动时,这些哈希槽会被均匀地分配给集群中的各个节点。
- 例如,你有 3 个节点:Node A 分配槽 0-5500,Node B 分配槽 5501-11000,Node C 分配槽 11001-16383。
- 存取逻辑:
- 客户端想要存入键
user:1001。 - 集群计算
CRC16(user:1001) % 16384,得到结果是1200。 - 节点 A 负责槽 0-5500,所以
user:1001会被存放到 Node A 上。
- 客户端想要存入键
为什么要用哈希槽?
相比直接对节点取模,哈希槽提供了一种更灵活的扩容和缩容机制。当需要增加新节点时,我们只需要把一部分哈希槽从旧节点"迁移"到新节点即可,而不需要像取模算法那样进行大规模的数据重排。
那么如何优雅地进行扩容、缩容 ?如何处理节点故障?如何监控集群的健康状态?
三、集群的节点管理:扩容与缩容
集群最大的优势就是弹性,但"动"集群是有风险的,必须小心翼翼。
1. 扩容:给集群"加人"
当数据量增长,单个节点存不下时,我们需要加入新的节点。
- 步骤简述:
- 启动新节点: 启动一个全新的 Redis 实例,配置为集群模式。
- 加入集群: 使用
CLUSTER MEET <新节点IP> <新节点端口>命令,让新节点加入现有集群。 - 重新分片: 这是最关键的一步。使用
redis-trib.rb reshard(或redis-cli --cluster reshard)工具,从旧节点迁移一部分哈希槽(Slot)到新节点。 - 数据迁移: Redis 会自动将这些槽对应的数据从旧节点复制到新节点。迁移过程中,集群对外服务不中断(在线迁移)。
- 核心要点: 迁移过程会对网络和磁盘 IO 造成压力,建议在业务低峰期操作,并监控集群延迟。
2. 缩容:给集群"减人"
当业务量下降,或者需要下线旧机器时,我们需要移除节点。
- 步骤简述:
- 迁移数据: 必须先将该节点上所有的哈希槽(Slot)和数据迁移到 其他存活节点上(同样是用
reshard命令)。 - 节点下线: 确保该节点的槽位数为 0 后,使用
CLUSTER FORGET <节点ID>命令,让集群其他节点"忘记"它。 - 安全停机: 最后,安全地停止该节点的 Redis 进程。
- 迁移数据: 必须先将该节点上所有的哈希槽(Slot)和数据迁移到 其他存活节点上(同样是用
- 核心要点: 绝对不能直接停机! 强制停机未清空数据的节点,会导致集群出现"槽位缺失",集群状态变为
fail,服务不可用。
四、故障处理与高可用维护
1. 故障自动转移(Failover)
当集群中的某个主节点宕机时,其从节点会自动发起选举,晋升为新的主节点。这是集群的自动机制。
- 运维视角: 需要关注的是故障转移的时间。如果从节点数据同步滞后太多,或者网络分区(脑裂),可能导致故障转移失败或数据丢失。
- 关键参数:
cluster-node-timeout:节点超时时间。如果一个节点在该时间内没有响应,会被标记为"疑似下线"(PFAIL)。这个值设置得太小会导致误判,太大则故障转移太慢。
2. 手动故障转移
当需要对主节点进行维护(如升级、重启)时,不能直接停机,否则会触发一次不必要的自动故障转移,且可能有数据丢失风险。
- 操作: 使用
CLUSTER FAILOVER命令。这会优雅地让主节点和从节点"商量"一下,让从节点平滑地接替主节点,而主节点在切换完成后会自动变成从节点。 - 优势: 避免了直接杀进程带来的风险,且可以控制切换时机。
3. 网络分区(脑裂)的处理
这是集群运维中最危险的场景之一。当集群网络发生故障,导致部分节点无法通信时,集群可能会分裂成两个"小集群"。
- 风险: 如果两个"小集群"都选举了主节点,就会出现"脑裂",数据会不一致。
- Redis 的防御:
- 多数派原则: 只有拥有半数以上主节点的"小集群"才能对外提供服务。另一半会被自动下线。
- 从节点投票: 从节点会拒绝向没有获得多数派支持的主节点进行故障转移。
- 运维建议: 尽量避免跨机房部署集群,或使用强一致性的网络环境,以减少脑裂风险。
五、监控与性能优化
运维不仅要"救火",更要"防火"。
1. 关键监控指标
- 集群状态:
CLUSTER INFO命令中的cluster_state: ok。如果变成fail,说明有槽位未分配或节点失联。 - 节点角色:
INFO replication查看节点是主还是从,以及从节点的延迟(lag)。 - 内存使用率: 监控每个节点的内存,避免 OOM(内存溢出)。
- 连接数:
connected_clients,过高可能意味着连接泄漏。 - 网络流量: 集群内部的 Gossip 消息和数据迁移都会占用带宽。
2. 参数优化建议
cluster-node-timeout:根据你的网络环境调整。通常建议设置为 15-30 秒。太短容易误判,太长影响故障恢复速度。maxmemory和maxmemory-policy:必须为每个节点设置合理的内存上限和淘汰策略,防止内存溢出。tcp-keepalive:开启 TCP 保活,及时发现断开的连接。
总结
通过 Redis 集群,我们成功实现了两个目标:
- 突破容量限制: 数据分片让我们可以横向扩展,利用多台机器的内存。
- 突破性能限制: 读写请求被分散到多台机器上,分担了单机压力。
- 高可用: 内置的主从复制和故障转移机制,保证了服务的稳定性。
至此,我们的 Redis 架构已经从"单机"进化到了"分布式集群"。