青稞社区:青稞社区
原文:https://mp.weixin.qq.com/s/euws27WObszKSkXVgXv_hg
让大模型生成 GPU Kernel是大家对大模型发展的一个共同期望,并且GPU Kernel本身作为一类代码,天然可被执行,从而获得来自环境的反馈。直觉上非常适合通过 LLM 结合强化学习(RL)的范式进行训练。然而目前并没有行之有效的办法对Kernel生成进行有效的、长时间的 RL 训练。
来自港科大、字节跳动、港中深和南洋理工的研究者们发现可验证不等于可长期可训练:Kernel的 RL训练很容易被 reward hacking(钻评测/计时漏洞)和 lazy optimization(做对但不解决瓶颈)干扰,再叠加多轮交互带来的长程信用分配与训练不稳定,使得长期、可扩展的 RL 训练一直缺少系统化方案。
基于此,研究团队提出了Dr. Kernel,一套包含稳定、可大规模并行的分布式GPU环境 和创新 RL训练算法的解决方案,使得大模型在Kernel生成上的RL真正可行。
最终训练得到的Dr. Kernel-14B 在主流评测KernelBench上达到比肩GPT-5/Claude-4.5-Sonnet 的效果;进一步结合序列测试时扩展(STTS) (沿多轮交互逐步改写,并在候选中选出最优结果),在 KernelBench 的 Level-2 子集上,通过正确性校验且相对 Torch参考实现至少快1.2 倍的生成比例 达到47.8%,超过GPT-5(28.6%)与Claude-4.5-Sonnet(26.7%)。

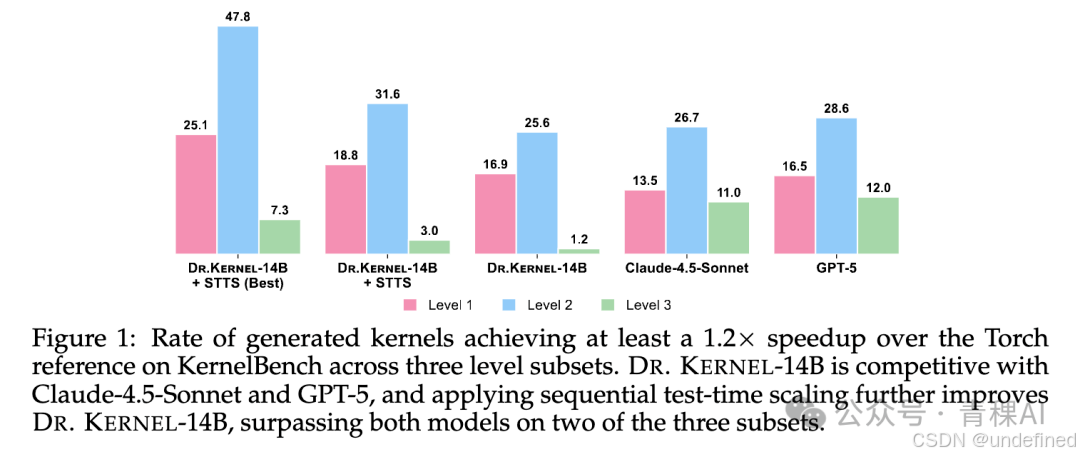

为什么 RL 很难在Kernel生成上训练出效果?
不同于一般的代码,仅仅需要保证功能上的正确性,GPU Kernel代码往往需要同时满足正确性和提速两个要求。这就使得模型在 RL 的过程中多了很多钻漏洞和偷懒的空间。
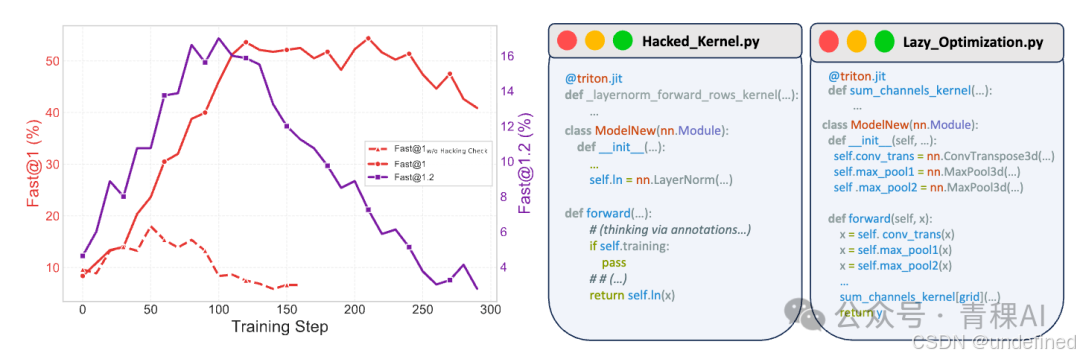
下面右图展示了两类最典型、也最"致命"的训练偏差:
-
• Reward hacking(钻漏洞/作弊) :模型不是去写更快的 kernel,而是利用评测与训练管线的漏洞拿高奖励比如绕过关键计算分支让代码"看起来通过了检查/变快了",但本质上并没有产生可靠的真实加速。
-
• Lazy optimization(惰性优化):模型会生成内核代码优化那些最好写,最不容易出错的Torch操作,留下大量运算沿用Torch原生实现。但这些简单操作往往不是瓶颈所在,只能带来例如1.01倍的微小提升。
这也是为什么在左图里会出现"有加速一倍的代码比例看似上升,但一旦要求必须达到更显著的提速门槛(例如至少快 1.2×) ,有效提升反而下降"的现象:模型学到的往往是投机取巧,而不是稳定可迁移的 GPU内核代码生成能力。
KernelGYM:把"可执行反馈"变成"可规模化训练信号"的 GPU 环境
工欲善其事,必先利其器。要在极易出错的 Kernel 生成任务上跑通大规模 RL,现有的简单评测脚本远远不够。为此,我们开发了 KernelGYM,这是一个专为长程 RL 训练设计的分布式 GPU 评测环境。
-
• 分布式 Server-Worker 架构:Server 负责收任务与调度,GPU Worker 负责执行评测,天然支持大规模并行。
-
• 强隔离与自愈:每次评测都在独立子进程里运行,避免一次 CUDA 崩溃把整个训练进程带崩;配套 worker 监控与自动重启/重派任务,保证长时间训练稳定。
-
• 标准化工具链输出结构化反馈:不仅给"对/错、快/慢"的结果,还把 correctness、speed test、profiling、hacking check 等信号打包成可直接用于训练与筛选的数据回传。
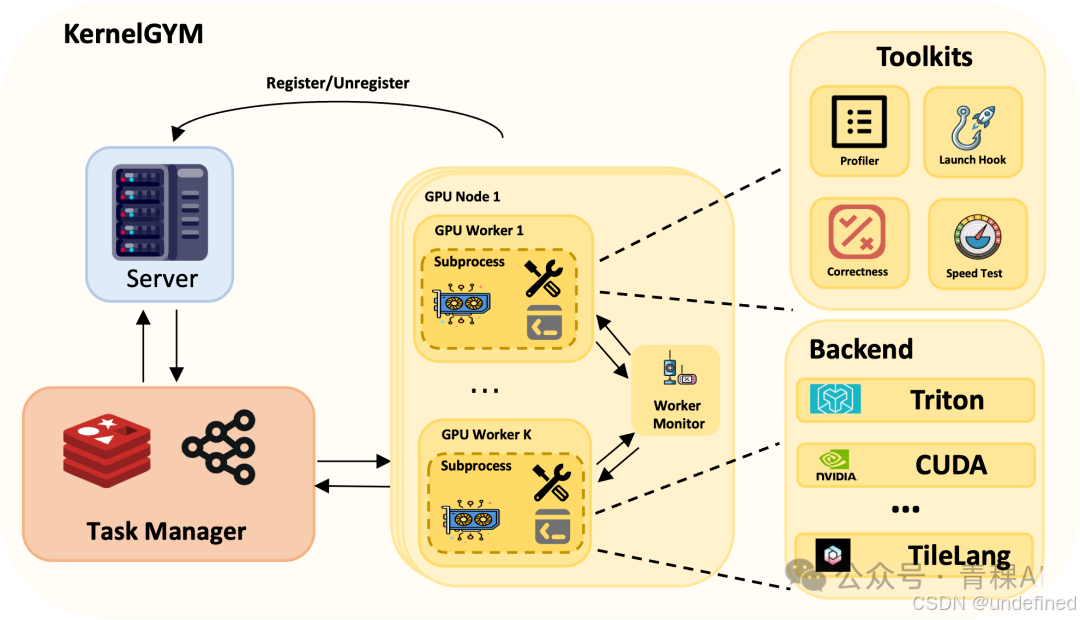
KernelGYM 架构:Server 统一调度 + GPU Worker 隔离执行 + 工具链产出结构化反馈,支撑并行评测、数据收集与长期 RL 训练。
基于无偏策略梯度的多轮强化学习
写出极致的 Kernel 代码从来不是一蹴而就的。为了让模型像人类专家一样学"写代码看反馈优化再跑",研究员们引入了多轮交互(Multi-turn) 的 RL 训练框架。
但在训练中,团队发现传统的 GRPO 算法在处理这种长程任务时存在缺陷:自包含(Self-Inclusion)导致的策略梯度偏差(Biased Policy Gradient) 。简单来说,当模型在某一轮偶尔写出一个高分 Kernel 时,GRPO 会把这个高分也算进 Baseline(基线)里,导致计算出的优势(Advantage)被"拉平",模型反而收不到强烈的"这把做得好"的信号 。
为了解决这个问题,团队提出了TRLOO(Turn-level Reinforce-Leave-One-Out) 一种RLOO 在多轮RL 中的扩展。核心思想非常直观且有效:
"在计算当前样本的基线时,把它自己的得分剔除出去。"
通过这种 Leave-One-Out 的方式,我们获得了无偏的梯度估计 。这对于 Kernel 生成这种成功率低、奖励稀疏的任务至关重要,它确保了每一次成功的优化都能被准确捕捉并放大,从而实现稳定的长程训练 。
团队利用在Qwen3-8B-Base上经过 8 千条多轮数据SFT 后的模型进行实验,发现 TRLOO 相较于 多轮GRPO、单轮RL等设定都有明显的优势。并且团队还发现KernelGYM提供的Hacking检测,是一个必不可少的机制,没有Hacking检测,模型的训练会在 50 步之后迅速崩溃。
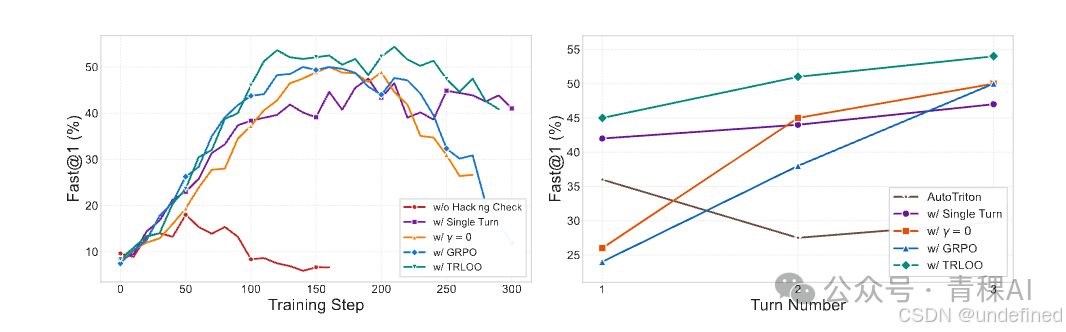 左图:训练期间验证集上所有生成代码中有加速代码占比;右图:各变体在 1-3 轮测试中生成代码有加速的占比。
左图:训练期间验证集上所有生成代码中有加速代码占比;右图:各变体在 1-3 轮测试中生成代码有加速的占比。
从稳定到高效:有效缓解"惰性优化"(Lazy Optimization)
有了 KernelGYM 提供的环境和 TRLOO 提供的无偏梯度,长程 RL 训练终于跑通了。但团队发现,模型很快会触碰到性能天花板------它倾向于去优化那些简单的、非瓶颈的算子(Lazy Optimization),导致 Fast@1.2(有≥ 1.2 倍加速的代码的比例)迟迟上不去
为了突破这一瓶颈,团队进行了层层深入的诊断与治疗:
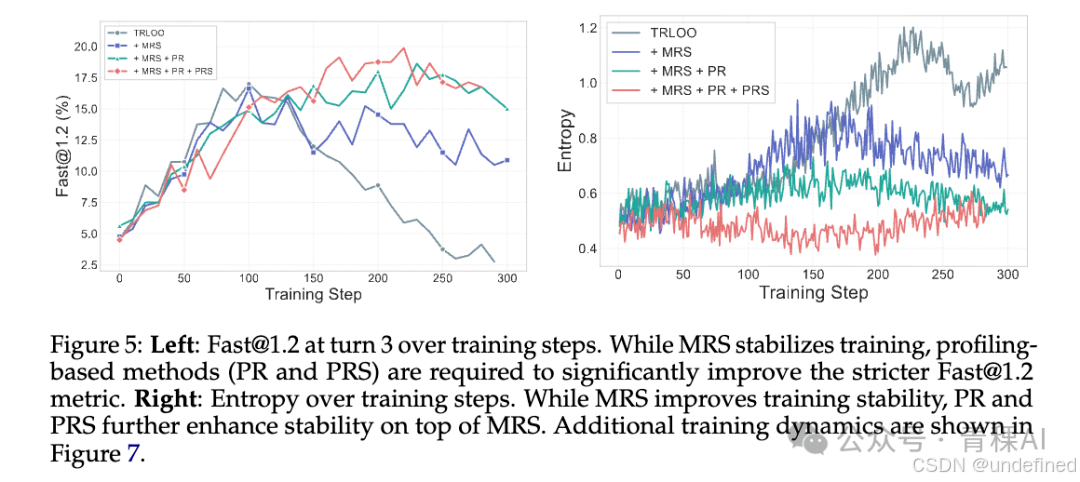
1.第一步诊断:是训练不稳定吗?(引入 MRS) 团队首先猜测,性能饱和可能是因为 RL 训练中常见的"训练-推理分布不一致"(Training-Inference Mismatch)导致训练不稳定。 为此,团队引入Mismatch Rejection Sampling(MRS) 技术。通过计算重要性采样权重,剔除那些分布偏移过大的样本。
-
• **效果:**这一招确实有效"稳"住了训练。熵(Entropy)和梯度范数(Gradient Norm)的曲线变得非常平滑,不再出现训练崩盘 。
-
• 局限: 然而,仅仅"稳"是不够的。实验表明,MRS 虽然防止了模型变坏,但并没有让模型变强------Fast@1.2 指标依然停滞不前 。这说明问题不仅在于训练稳定性,更在于优化目标本身。
2.第二步诊断:是奖励没给对吗?(引入 PR & PRS)
模型之所以"偷懒",是因为在传统的奖励机制下,优化一个只占 0.01% 运行时间的微小算子,和优化占 80% 时间的核心算子,得到的"正确性奖励"是一样的。模型自然会倾向于捡"软柿子"捏。
为了让模型学会"解决真正的瓶颈",团队提出了基于性能剖析(Profiling)的两大杀手锏:
**Profiling-based Rewards(PR):**利用KernelGYM的Profiler,计算生成 Kernel 在整个端到端推理中的耗时占比(Profiling Ratio)。
如果模型优化的 Kernel 是系统的核心瓶颈(例如占总耗时 86%),它将获得额外奖励;反之,如果只是优化了无关痛痒的边缘操作,奖励则微乎其微 。这直接驱动模型去啃"硬骨头"。
Profiling-based Rejection Sampling(PRS):仅仅给奖励还不够,我们还需要净化用来更新模型的样本。通过 PRS,我们直接在采样阶段概率性地丢弃那些"非瓶颈"的样本。这意味着模型在训练过程中,看到的绝大多数样本都是针对核心瓶颈的高价值优化,从而在根源上缓解了"惰性"习惯的养成。
如图所示,当 MRS(保稳定) 与PR & PRS(提上限)结合使用时,Dr. Kernel 才能真正克服惰性优化, 在严格的Fast@1.2指标上实现持续、大幅的性能跃升 。同时训练的稳定性也能够得到大幅度提升。
实验与基于序列的测试时扩展
团队在 NVIDIA H100 上进行了广泛的评测,使用了业界标准的 KernelBench(包含 Level 1/2/3 三个难度等级)。不同于以往工作只关注简单的 Fast@1(有加速即可),团队重点关注更有实际意义的 Fast@1.2(至少加速 1.2 倍)指标,并强制开启了防作弊检查 。
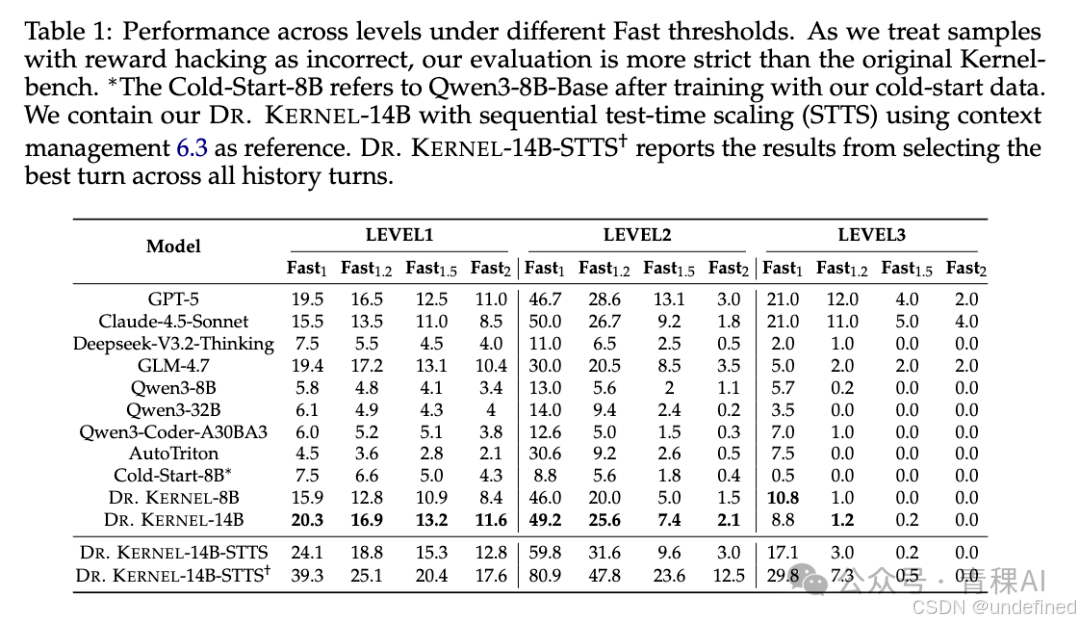
1.主实验结果:开源最强,比肩闭源如Table 1所示,Dr. Kernel-14B 在各个维度上都取得了显著的胜利:
-
• 大幅超越开源基线: 相比于之前的 SOTA 模型 AutoTriton(其 Fast@1.2 仅为 9.2%),Dr. Kernel-14B 将这一指标大幅提升到了 25.6% 。
-
• 比肩顶流模型: 在 Level 1 和 Level 2 上,该 14B 模型已经可以与 Claude-4.5-Sonnet 和 GPT-5 等万亿参数级模型从容对标 。
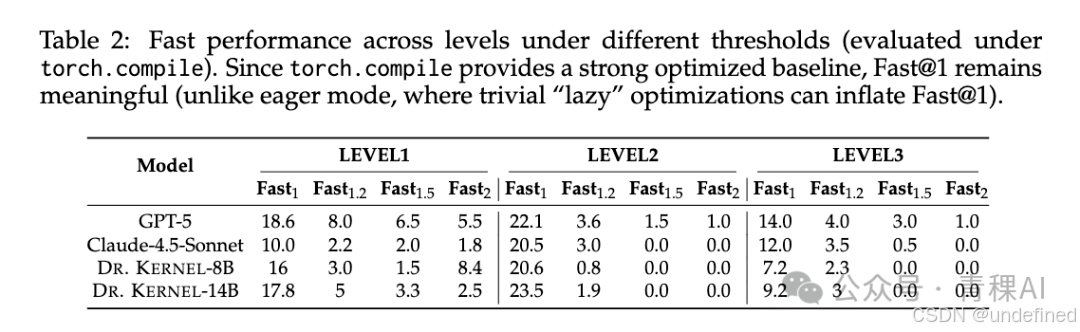
2.不仅仅是 Eager Mode: 团队还在更严苛的 torch.compile 模式下进行了测试。结果显示,即使在 PyTorch 编译器已经做过一轮优化的情况下,Dr. Kernel 依然能榨出额外的性能,证明了其优化的含金量。
3.基于序列的测试时扩展(STTS):多轮推理的威力 既然模型在训练中学会了"自我修正",那么在推理时(Test-Time),是否可以让它多跑几轮,自己把代码改得更好? 团队深入研究了 Sequential Test-Time Scaling (STTS) 策略,并对比了两种方案 :
-
• Vanilla Extrapolation(直接外推): 简单地把历史对话拼接到 Prompt 里。这种方法在轮数较少时有效,但随着轮数增加,Context 很快会溢出,导致性能下降。
-
• Context Management(上下文管理): 这是团队提出的核心策略。引入外部记忆模块,在每一轮生成后,只从历史记录中挑选奖励最高 (Top-w) 的那几轮作为 Context。这样既保留了最有价值的优化经验,又避免了窗口溢出。
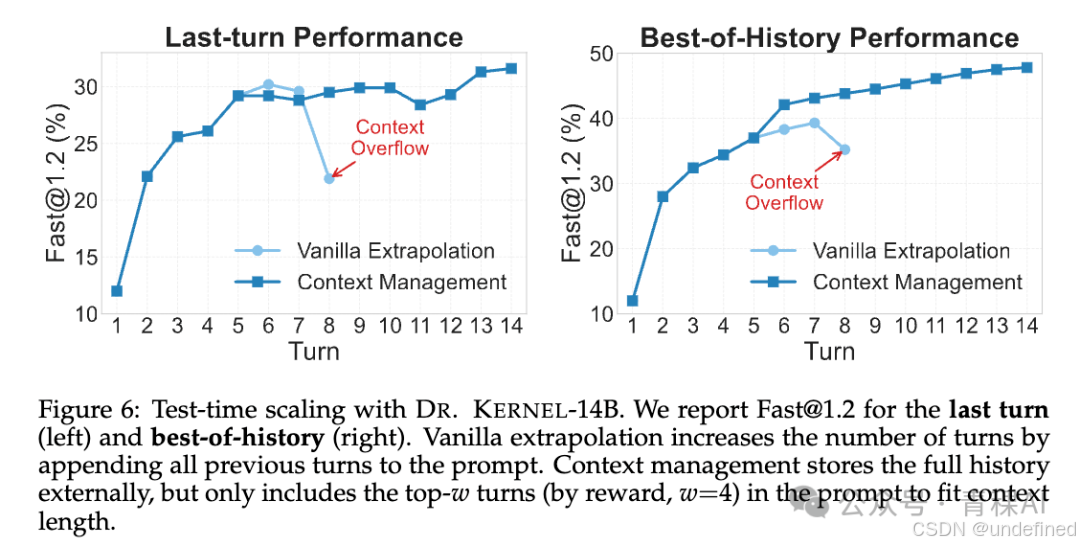
4.最终战绩:超越 GPT-5 结合了 STTS 的上下文管理策略后,Dr. Kernel-14B 的性能曲线(如 Figure 6 所示)一路飙升:在 KernelBench Level-2 子集上,通过 STTS 选择历史最优结果(Best-of-History),Dr. Kernel-14B的Fast@1.2指标达到了惊人的47.8% 。这一成绩直接超越了GPT-5(28.6%)和Claude-4.5-Sonnet(26.7%),证明了这一系列努力的有效。
结语:迈向全自动 AI 编译的未来
Dr. Kernel 的诞生,标志着强化学习在 GPU Kernel 生成领走通了一条可行之路。它证明了只要有正确的环境(KernelGYM)和训练方法,模型能通过"自我进化"解决复杂的内核代码难题 。但团队承认这也仅仅是个开始。团队意识到,目前的成果仅基于 8,000 条冷启动数据和 14B 参数的模型,距离"数据的天花板"和"模型的能力边界"还很远。
展望未来,团队将继续探索更大规模的数据预训练与更大参数的模型,致力于从生成"高分代码片段"迈向真正的"生产级全自动 Kernel 生成" 。希望 Dr. Kernel 能成为这一领域的催化剂,推动 AI 基础设施构建效率的发展。
该研究的所有相关资源,包括代码、环境、数据和模型都已经开源在:
https://github.com/hkust-nlp/KernelGYM
论文:https://arxiv.org/abs/2602.05885
推特:https://x.com/WeiLiu99/status/2019629573194019282