一、GPU占用率(Occupancy)
一般接触过电脑的都会知道,如果电脑卡顿了,很有可能是CPU占用率太高了,导致任务无法及时处理过来。但可能很多人对显卡(GPU)的占用率并不敏感,毕竟大多数的应用场景对GPU的要求并不高。即使是要求很严格的游戏来说,大多也对主流的显卡支持的很好,普通人根本感觉不出来。
当然,对于更吃GPU存在的专业图形处理和视频处理,一般人也接触不到,所以GPU的占用率一般都是开发人员在进行大规模的并行开发时,才会有针对性的进行处理。
正如Windows上有任务管理器而Linux上有top,htop等命令来查看cpu的占用率,在实际的应用中,Windows和Linux上也提供了类似的工具。Windows上会集成到任务管理器,而Linux上则可以使用不同的厂商提供的相关命令如nvidia_smi、intel_gpu_top等等。
二、CUDA占用率
所谓CUDA占用率,其实就是在每个流多处理器(SM)上,实际活跃的线程束数量与该SM最大可支持的并发线程束数量的比值。理论上说,占用率高会提高GPU(物理)的利用率。这句话的意思是更多warp可以用来隐藏停滞的warp的延迟,不过这也有可能意味着CUDA线程间的竞争风险增加,导致性能下降。设计者和开发者一定要明白其中的道理,掌握一个平衡的点。
其实上面的话很好理解,在CPU中线程是时间片轮转的,只要进入就绪队列,就可以逐一执行线程。只不过在CPU中上下文的切换是有代价的,但在GPU中warp的切换是零成本的。所以当一个warp等待显存数据时,SM会无成本切换到另外就绪的warp中,从而将内存等待的时间隐藏。也就是说,只要有不断的有类似的情况出现,GPU的利用率始终是高效的,而内存的延迟访问与其它warp的运行并行,从而整体提高了效率。
而在CUDA中,提供了两种方式来进行CUDA占用率的处理:
- CUDA工具包提供的CUDA占用率计算器。它是一种理论上的占用率。
- NVIDIA分析器得到的GPU实际占用率即上面提到的流处理器上并发执行的warp的真实数量和最大可用warp(线程束)
一般来说,在Windows上不用专门进行设置即可产生相关的报告文档,位置在:
"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA<cuda-version>\tools\CUDA_Occupancy_Calculator.xls"
如果默认没有相关报告,可自行查找相关的资料配置一下即可,这里只说一下"CUDA c++ =>Device中设置Verbose PTXAS Output",这个选项用来处理编译过程中输出信息量的多少。可以简单理解为与gcc的-g有些类似的意思,如果选择YES则输出更详细的编译信息,否则只生成普通的信息。这些信息会体现在上面的文档中。其主要的内容为:
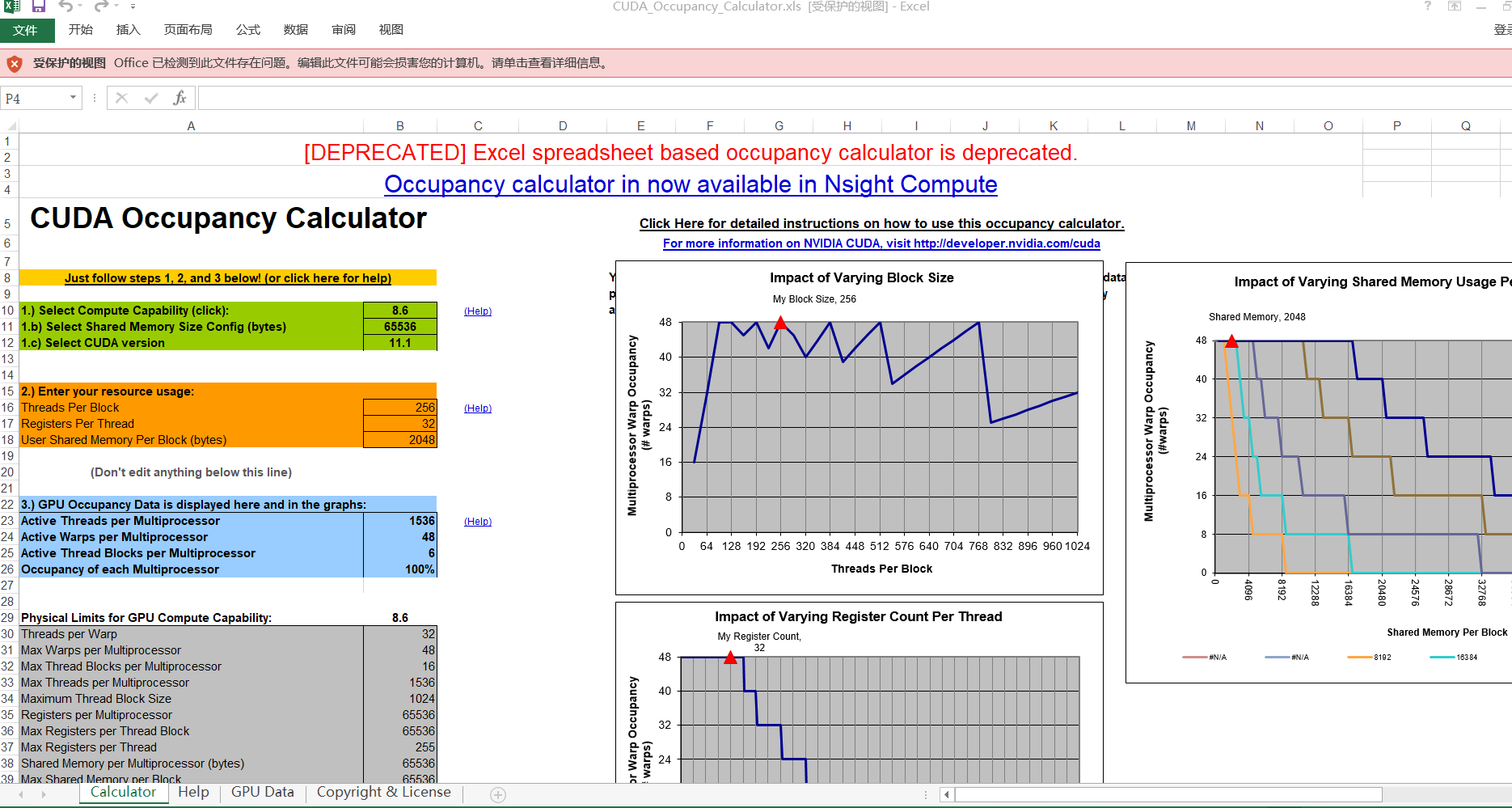
再简要说明一下文档的内容:
这个文档是一个Excel文档,可以理解为包含一个计算器。它主要有两部分:内核信息输入和占用信息输出。
- 输入的信息包括:
GPU 的计算能力------绿色表格部分
线程块资源信息------黄色表格部分,主要有三部分:
1)每个 CUDA 线程块的线程
2)每个 CUDA 线程的寄存器
3)每个块的共享内存 - 计算器在这里显示了 GPU 的占用信息:
GPU 占用数据------蓝色表格部分
GPU 的 GPU 计算能力的物理限制------灰色表格部分
每个块分配的资源------黄色表格部分
每个流多处理器的最大线程块------黄色、橙色和红色表格部分
以及由三个关键的占用资源(线程、寄存器和每个块的共享内存),绘制占用限制图------右个则图(图表上的红色三角形,显示当前的占用数据)
这个计算器可以进行相关的处理,可以在计算力的下拉框中选择不同内容进行自动计算,此处不再详述。请自行参看相关的操作和结果。
三、如何调整占用率
在CUDA中既然存在占用率,就一定会提供相关的调整的API,它有两种情况即Runtime和Driver。一般来说,复杂的算法和双精度类型数据处理时,CUDA中的寄存器占用有可能增加。从而有可能导致占用率会下降,这时,就可以人为的限制寄存器的使用来增加占用率(理论上),并可以执行状态来判断是否提高了相关的性能。
在CUDA中可以使用__launch_bound__限定符来限定内核中使用的流处理器的最大线程数(块)以及SM中最小线程块。它并不会直接限制寄存器的使用,主要是通过编译器反推出每个线程可用的寄存器的上限,并根据此进行编译策略的调整。
其基本的应用形式为:
c
__global__ void __launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
MyKernel(...) { ... }一般来说,编译器的处理会分为三种情况:
- 如果设置的参数(寄存器上限)没有超过上限资源并且指定最小块时,编译器则会进行寄存器的调整。最高到达指定制定。这种情况下可能会降低占用率来提高性能
- 如果设置参数未超上限资源,但未指定最大线程数,则编译器会进行正常的优化
- 设置超限,编译器会强制削减设置资源到当前寄存器数。
另外开发者还可以使用--maxrregcount在整体层面来限制寄存器的使用。它用来设置每线程寄存器数量的物理上限。可以理解为它是一种宏观的调控,它属于编译级别的,而__launch_bound__是CUDA指定内核本身的间接限制。它可由编译器进行自由的处理的。如果二都进行了设置,则后者会生效。
在老的CUDA版本(11)中,可以使用Visual Profie进行相关的状态监控(注意:如果在新版本中使用,则会报一个"I just recently installed CUDA 12.3 on Windows 11. However I wasn't able to launch nvvp. It gives the error "A java Runtime Environment (JRE) or Java Development Kit(JDK) must be available in order to run nvvp". "的错误。原因是Visual Profie与Java8绑定无法与更高的Java9等兼容,此为NVIDIA故意所为,请使用Nsight System),而在新的版本(12)推荐使用NVIDIA Nsight System。细节的使用以后会专门分析说明。可以前面的CUDA程序看分析结果:
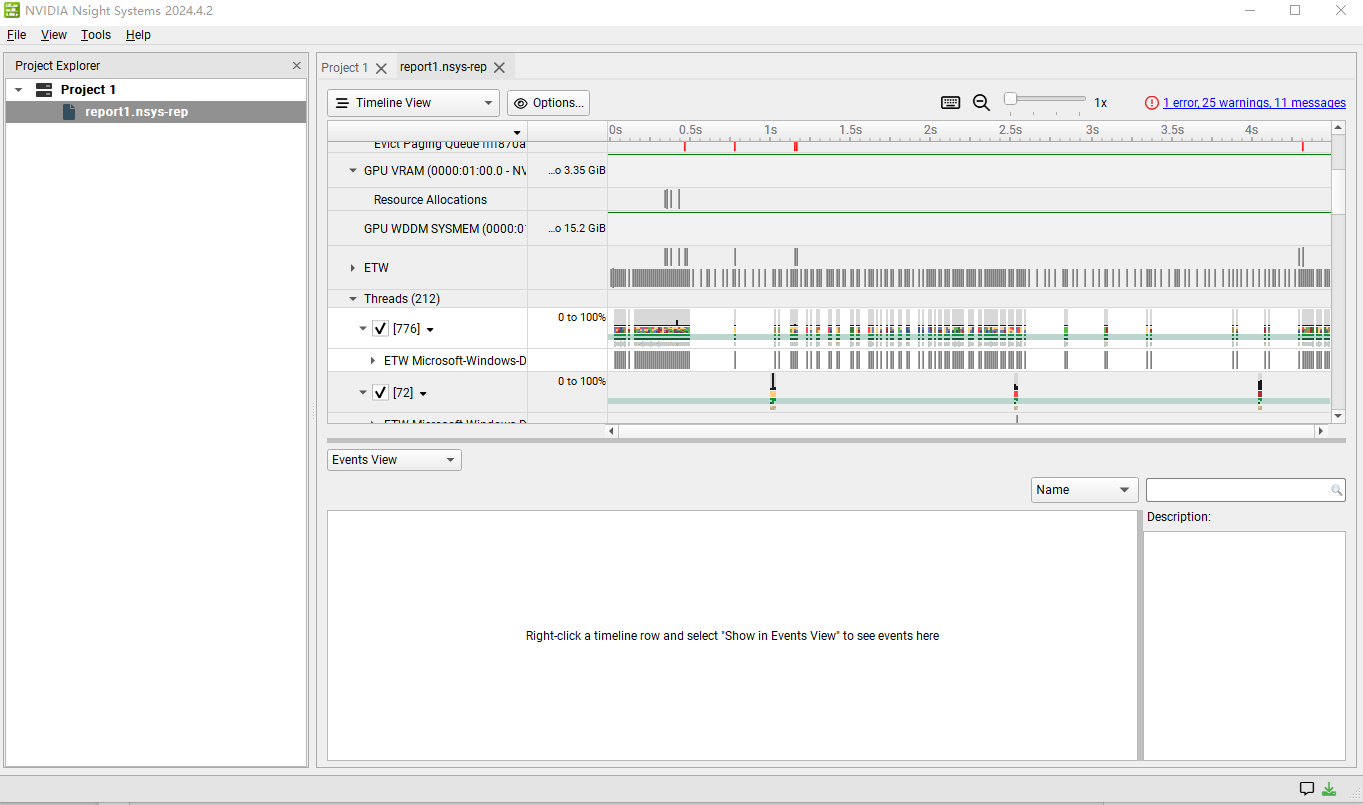
从上面的图中,可以CPU,GPU的状态,数据传输和CUDA相关的Kernels、内存以及流等情况。还可以进行数据的导入和导出。
四、总结
CUDA的占用率是用来指导开发者更好的适配程序与硬件的一个重要的指标。开发者要善于利用各方方法和手段,更要善于利用工具验证和实践自己的目标。效率始终是开发中的重中之重的一个基础要求。