本文基于一套完整的 Redis 学习笔记与课堂板书整理而成,目标不是"记命令",而是真正理解 Redis 为什么这样设计、每种机制解决什么问题、在真实生产环境中该如何选择与配置。
一、Redis 在系统架构中的定位
1. Redis 是什么
Redis(Remote Dictionary Server)是一个基于内存的 Key-Value 数据库,同时支持将数据持久化到磁盘。它以高性能著称,单机即可支撑十万级 QPS,因此在现代互联网系统中被广泛使用。
Redis 并不是传统意义上的数据库替代品,而是一种以内存为核心的数据存储系统,其设计目标是:
-
极低的访问延迟
-
极高的并发能力
-
简单的数据模型
2. Redis 与 MySQL 的分工关系
在实际系统中,Redis 几乎总是与 MySQL 等关系型数据库配合使用:
-
MySQL
-
数据存储在磁盘
-
强一致性
-
适合长期、完整的数据存储
-
并发能力受限于磁盘 IO
-
-
Redis
-
数据存储在内存
-
访问速度极快
-
非强一致(默认)
-
适合热点数据与高频访问场景
-
结论:
Redis 是 MySQL 的前置层,用来扛并发;MySQL 是最终的数据兜底。
3. 为什么 Redis 不能只当"纯缓存"
很多初学者会认为 Redis 只是一个"缓存工具",但在真实业务中这是不成立的:
-
Redis 中常常存放的是:
-
高频访问的核心业务数据
-
用户状态、会话信息
-
计算成本极高的数据结果
-
如果 Redis 进程崩溃或机器断电:
-
纯缓存思维 → 可以接受全部数据丢失
-
实际业务 → 代价极高,甚至不可接受
因此,Redis 必须具备数据恢复能力,这就引出了持久化机制。
二、Redis 为什么一定要做持久化
1. Redis 的先天问题
Redis 的性能优势来源于:
- 所有数据都在内存中
但内存的缺点同样明显:
-
进程退出 → 数据丢失
-
机器断电 → 数据清空
如果 Redis 没有持久化机制,那么它只能作为一个"易失性缓存"。
2. Redis 的设计选择
Redis 给出的答案是:
把内存中的数据,按照一定策略,写入磁盘文件中。
为此,Redis 提供了两种持久化方案:
-
RDB(Redis DataBase):全量快照
-
AOF(Append Only File):追加日志
这两种机制解决问题的思路完全不同。
三、RDB 持久化机制详解
1. 什么是 RDB
RDB 的核心思想非常直观:
在某一个时间点,把 Redis 内存中的全部数据状态保存成一个快照文件。
该文件通常名为:dump.rdb
你可以将 RDB 理解为:
-
一次"全量备份"
-
一个数据世界的"时间切片"
2. RDB 的触发方式
Redis 提供了三种触发 RDB 的方式。
(1)save 命令
-
同步执行
-
Redis 主线程会被阻塞
-
执行期间无法处理任何客户端请求
因此:
save 几乎不在生产环境中使用。
(2)bgsave 命令(重点)
-
后台执行
-
不阻塞 Redis 主线程
-
实际生产中最常用的方式
bgsave 的本质是:
让 Redis 在后台生成 RDB 文件,而前台仍然正常服务。
(3)自动触发(配置触发)
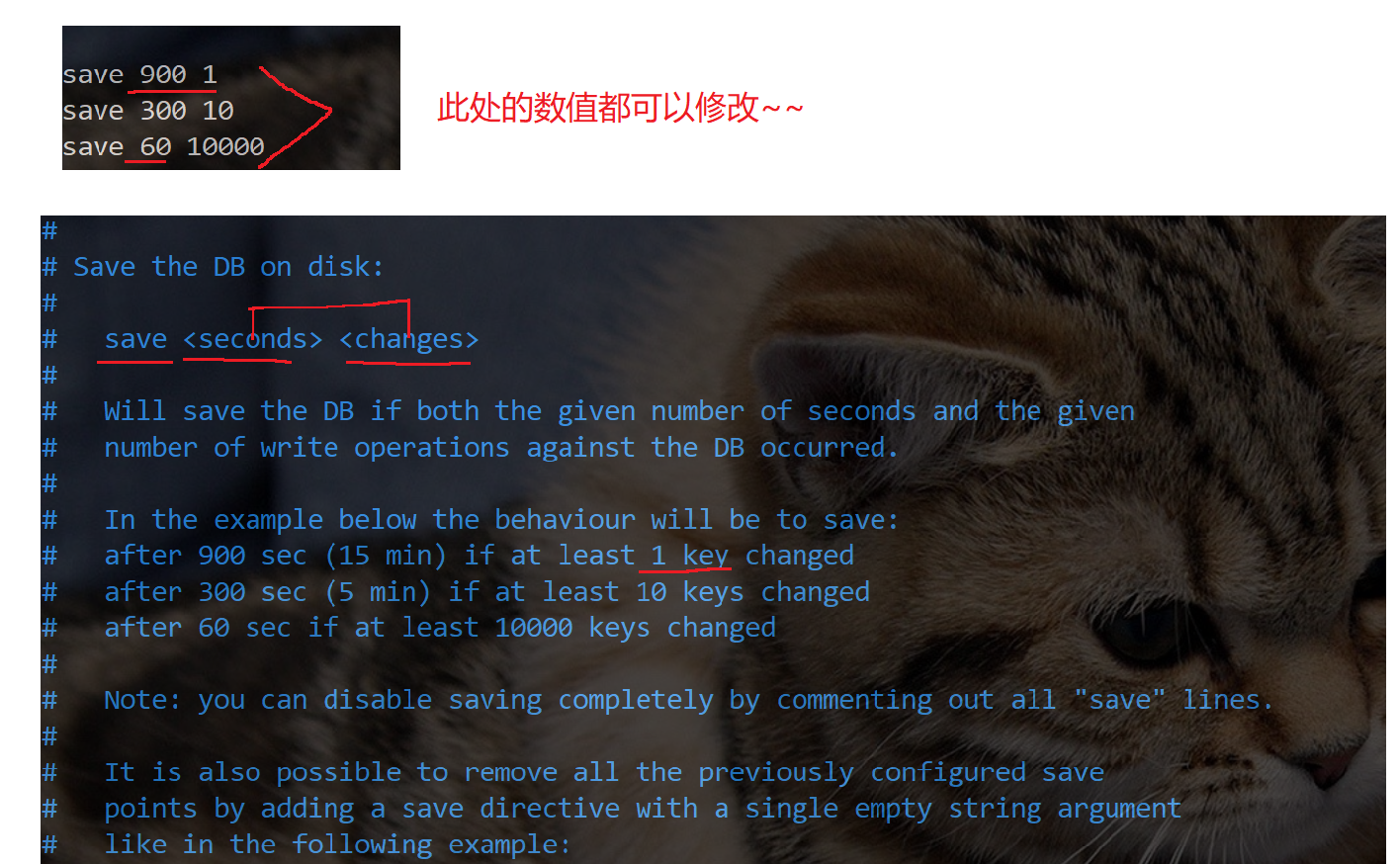
Redis 可以通过配置文件自动触发 RDB:

bash
save 900 1
save 300 10
save 60 10000含义是:
-
在 900 秒内发生 1 次写操作 → 触发 bgsave
-
在 300 秒内发生 10 次写操作 → 触发 bgsave
-
在 60 秒内发生 10000 次写操作 → 触发 bgsave
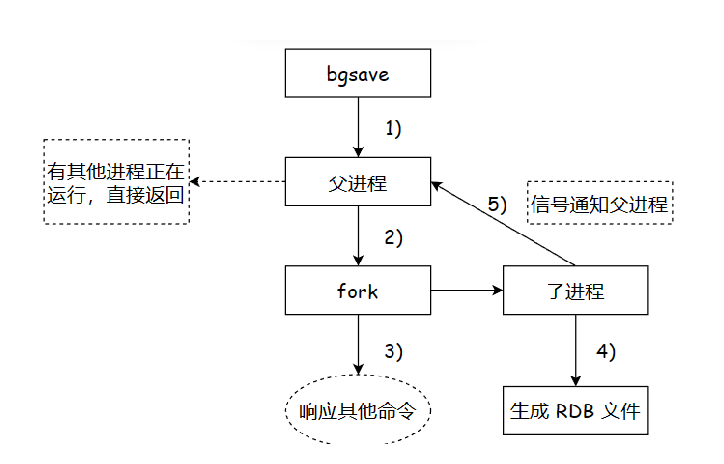
3. bgsave 的底层原理:fork
bgsave 的关键并不在于 Redis 本身,而在于操作系统。
执行流程如下:
-
Redis 主进程调用
fork() -
操作系统创建一个子进程
-
子进程负责将内存数据写入 RDB 文件
-
父进程继续处理客户端请求
4. 写时复制(Copy On Write)机制
一个常见疑问是:
fork 一个进程,内存不会被复制一整份吗?
答案是:不会。
操作系统采用的是 写时复制(Copy On Write, COW):
-
fork 时:父子进程共享物理内存
-
只有在某一块内存被修改时:
- 才会复制该内存页
影响:
-
bgsave 执行速度快
-
bgsave 期间内存占用可能上升
5. RDB 文件生成的安全性设计
Redis 在生成 RDB 文件时并不会直接覆盖旧文件,而是:
-
先生成临时文件
-
完成写入后
-
使用
rename()原子性替换旧文件
这样可以保证:
-
不会出现"写了一半的 RDB 文件"
-
即使 Redis 异常退出,也不会破坏原有数据
6. RDB 的优缺点总结
优点:
-
文件体积小
-
数据恢复速度快
-
非常适合做冷备份
缺点:
-
两次快照之间的数据可能丢失
-
不适合对数据安全性要求极高的场景
四、Linux 文件系统补充知识(理解 RDB 的关键)
1. Linux 中文件的组成
-
文件名
-
inode(元数据)
-
数据块
inode 记录了文件的大小、权限、数据块指针等信息。
2. RDB 与 inode 的关系
Redis 使用 rename() 替换文件名,而不是直接修改原文件:
-
inode 保持不变
-
数据块指向新的内容
这是一种非常典型、也非常安全的文件更新策略。
五、AOF 持久化机制详解
1. 什么是 AOF
AOF 的设计思路与 RDB 完全不同:
不保存数据结果,而是保存"写命令本身"。
例如:
bash
SET k1 v1
SET k2 v2
DEL k12. AOF 的工作流程
-
客户端发送写命令
-
Redis 执行命令
-
将命令追加到 AOF 文件
-
根据刷盘策略写入磁盘
3. AOF 的刷盘策略
Redis 提供三种策略:
-
appendfsync always-
每条命令都刷盘
-
最安全,性能最差
-
-
appendfsync everysec(默认)-
每秒刷盘一次
-
性能与安全性的折中
-
-
appendfsync no-
由操作系统决定
-
性能最好,安全性最低
-
4. AOF 文件膨胀问题
由于 AOF 记录的是命令:
-
同一个 key 多次修改
-
会产生大量冗余日志
文件会不断变大,影响恢复速度。
5. AOF Rewrite(重写机制)
Redis 通过 AOF 重写 解决该问题:
-
基于当前内存中的数据状态
-
生成一份"最简命令集合"的 AOF
-
去除历史冗余操作
六、RDB 与 AOF 的对比总结
|-------|-------|------|
| 维度 | RDB | AOF |
| 数据完整性 | 可能丢数据 | 更安全 |
| 恢复速度 | 快 | 较慢 |
| 文件体积 | 小 | 大 |
| 适用场景 | 备份 | 数据安全 |
七、生产环境的常见实践
-
同时开启 RDB 与 AOF
-
AOF 使用
everysec -
RDB 用于冷备份与快速恢复
Redis 重启时:
-
如果存在 AOF → 优先加载 AOF
-
否则 → 加载 RDB
八、总结
Redis 的持久化设计并不是"为了完美",而是:
-
在性能、数据安全、系统复杂度之间
-
做出的高度工程化权衡
理解 RDB 与 AOF 的本质,才能真正理解 Redis 的设计哲学。