分布式系统有一个关键问题:单点问题------如果一个服务器程序只用一个物理服务器来部署,那么这个机器挂了,服务就没了。在性能上还很有限
所以我们就希望用多个服务器来部署redis,redis的部署方式有以下几种:
1.主从复制
2.主从+哨兵
3.集群
一则小故事初步认识主从复制(师傅带学徒)
1. 师徒关系的确立 :Master 和 Slave 在厨房里,主厨(Master)负责掌勺、研发新菜谱(处理写操作)。徒弟(Slave)的任务是看师父怎么做,并记下笔记。当客人多的时候,徒弟可以帮忙把做好的菜端给客人看(处理读操作)。这样主厨就能专心炒菜,厨房的效率也更高。
2. 第一次见面 :全量同步 新徒弟刚来时,脑子里一片空白。主厨会把压箱底的"完整菜谱大全"(RDB 快照文件)直接塞给徒弟。徒弟拿到后,会先把以前零碎的记忆清空,然后废寝忘食地背诵这本大谱。背完之后,徒弟的水平就和师父刚给书的时候一模一样了。
3. 师父的身份证 :replid 每个主厨都有一个唯一的身份证号,叫 replid。徒弟拜师的时候,会记住这个 replid。如果有一天,徒弟发现带自己的师父身份证号变了,或者自己从来没见过这个号,徒弟就会意识到:这可能不是我原来的师父,或者是师父失忆重启了。这时候,徒弟会为了安全起见,要求重新进行一次"全量同步"。
4. 笔记的页码 :offset 主厨每教一个新动作(每发一个字节的数据),都会在一个计步器上累加数字,这就是 offset(偏移量)。徒弟手里也有个计步器,记录自己学到了哪一步。 比如主厨现在的进度是 1000,徒弟说:"师父,我学到 950 了。"主厨一看,差距不大,就不用给大菜谱了,直接把 951 到 1000 之间的这 50 个动作演示一遍给徒弟看。这就是增量同步。
5. 门口的小黑板 :复制积压缓冲区(Backlog) 主厨在演示新动作时,怕徒弟偶尔走神(比如网络闪断),专门在门口放了一个循环擦写的小黑板。主厨最近教的动作都会顺手写在黑板上。如果徒弟只是走神了一会儿,回来一看黑板,把漏掉的动作补上就行了(增量同步)。但如果徒弟走神太久,主厨把黑板都写满并擦掉重新写了好几轮了,徒弟回来发现黑板上的内容已经衔接不上了,那主厨只能摇摇头,让徒弟去重新背那本"完整菜谱大全"(全量同步)。
6. 实时教学:命令传播 当徒弟基本出师(完成了初始同步)后,主厨每做一个新动作(写操作),都会立刻回头对徒弟喊一声:"记住了,加一勺盐!" 徒弟听到后赶紧在自己的小本本上也写下"加一勺盐"。通过这种方式,徒弟能时刻保持和师父的步调一致,确保师徒俩掌握的信息是实时同步的。
一、主从复制
1.主从复制简单机制
在redis节点中,有主节点和从节点
主节点有读写权限
从节点只有读权限
从节点的数据是主节点的副本,主节点上每一处数据的修改都要同步到从节点上。
2.主从节点数据传输
主从节点间通过网络来传输数据(TCP)
TCP内部支持nagle算法,开启了就会增加传输延迟,节省带宽。关闭了可以减少延迟,增加带宽
3.主从拓扑结构
核心就是,主读写,从只读,从可根据主复制。
一些简单拓扑:
这个就是一个主节点,从节点之和主节点相连,这种结构随着从节点增加,主节点每修改一个数据,就要把所有数据给更多从节点,传输次数多
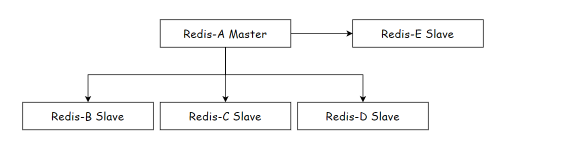
这个是树形拓扑,从节点也能连从节点,这下主节点不用把一份数据发多次了,但是发一次数据的时间长了 。
4.主从复制流程图
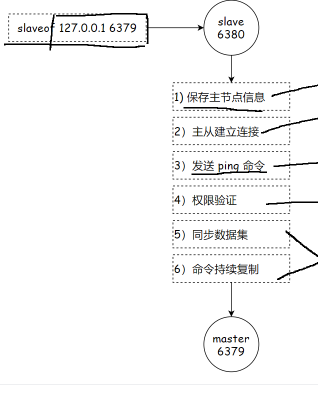
1)保存主节点(Master)的信息
开始配置主从同步关系之后:
- 从节点只会保存主节点的地址信息
- 此时复制流程还没有真正开始
在从节点(如 6380)执行:
info replication
可以看到类似信息:
java
master_host: 127.0.0.1
master_port: 6379
master_link_status: down说明:
- 主节点 IP 和端口已经保存
- 但主节点连接状态
master_link_status仍然是down - 此时主从还未建立实际连接
2)定时任务尝试建立 TCP 连接
从节点内部有一个:
每秒执行一次的定时任务
该定时任务负责维护复制逻辑:
- 发现存在新的主节点
- 尝试与主节点建立 TCP 网络连接
如果连接失败:
- 定时任务会无限重试
- 直到连接成功
- 或用户停止主从复制
3)发送 PING 命令检测主节点状态
当 TCP 连接建立成功后:
- 从节点发送
PING命令 - 检查主节点在应用层是否工作正常
如果:
- 主节点返回
PONG- 说明主节点正常
- 超时未返回
- 从节点断开 TCP 连接
- 等待下次定时任务重新连接
4)权限验证
如果主节点设置了:requirepass
则需要认证。
从节点需要在配置文件中设置:masterauth
流程:
- 从节点向主节点发送 AUTH 命令
- 进行身份验证
如果验证失败:
- 主从复制停止
- 不会进入数据同步阶段
5)同步数据集
当认证成功后,开始同步数据。
对于首次建立复制的情况:
- 主节点会把当前所有数据发送给从节点
- 这一步通常是整个复制过程中耗时最长的
数据同步分为两种情况:
(1)全量同步
- 发送完整 RDB 数据
- 适用于首次复制或无法进行增量同步的情况
(2)部分同步
- 只同步缺失的数据
- 依赖 offset 和 backlog 机制
- 用于断线重连场景
6)命令持续复制
当从节点完成数据同步后:
- 主从进入命令传播阶段
流程:
- 主节点执行写命令
- 主节点将写命令发送给从节点
- 从节点执行相同命令
- 保证数据最终一致
此阶段是持续进行的,直到主从关系解除。
5.数据同步 psync
Redis 使用psync 命令完成主从数据同步,同步过程分为:全量复制和部分复制。
- 全量复制:⼀般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据⼀次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点。因为补发的数据远小于全量数据,可以有效避免全量复制的过高开销。
5.1 replicationid/replid
主节点的复制 id .
主节点重新启动, 或者从节点晋级成主节点, 都会生成⼀个 replicationid. (同⼀个节点, 每次重启, 生成的 replicationid 也会变化).
从节点在和主节点建立连接之后, 就会获取到主节点的 replicationid
每个节点需要记录两组 master_replid .
这个设定解决的问题场景是这样的:
比如当前有两个节点 A 和 B, A 为master, B 为 slave. 此时 B 就会记录 A 的 master_replid. 如果⽹络出现抖动, B 以为 A 挂了, B自己就会成为主节点. 于是 B 给自己分配了新的 master_replid. 此时就会使用 master_replid2 来保存之前 A
的 master_replid.
- 后续如果网络恢复了, B 就可以根据 master_replid2 找回之前的主节点.
- 后续如果网络没有恢复, B 就按照新的 master_replid 自成⼀派, 继续处理后续的数据.
5.2 offset
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 master_repl_offset 指标中。
说白了就是标记主节点数据加到哪了,从节点复制到哪了。主从节点根据各自偏移量判断数据同步情况。
5.3 psync运行流程
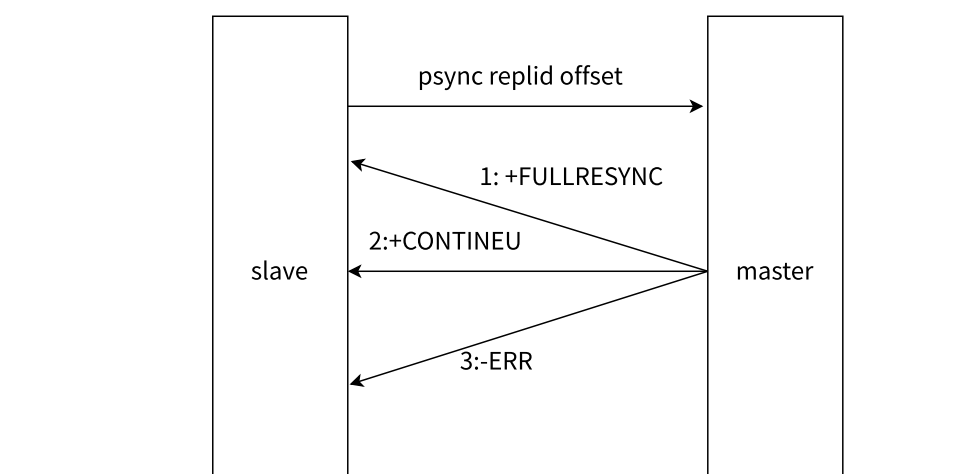
PSYNC 复制流程说明:
从节点向主节点发送 PSYNC 命令。
其中:
replid默认值为?offset默认值为-1
示例(首次复制时):
PSYNC ? -1
主节点响应决策
主节点根据接收到的 PSYNC 参数以及自身复制积压缓冲区(backlog)情况,决定响应结果。
情况一:全量复制
如果主节点回复:
+FULLRESYNC replid offset
说明:
- 从节点需要执行 全量复制
- 主节点会生成 RDB 文件并发送给从节点
- 后续再发送缓冲区中的写命令
情况二:部分复制
如果主节点回复:
+CONTINUE
说明:
- 可以进行 部分复制
- 主节点只发送从节点缺失的命令数据
- 适用于断线重连场景
情况三:版本过低
如果主节点回复:
-ERR
说明:
- 主节点版本过低
- 不支持
PSYNC命令 - 从节点会退化为使用
SYNC命令进行全量复制
PSYNC 与 SYNC 的区别
🔹 PSYNC
- 支持部分复制
- 不会阻塞 Redis 服务器处理其他请求
- 是 Redis 2.8 及以后版本的复制方式
- 主从模式下自动执行,无需手动调用
🔹 SYNC
- 只支持全量复制
- 会阻塞 Redis 服务器处理其他请求
- 属于早期版本复制机制
5.4全量复制
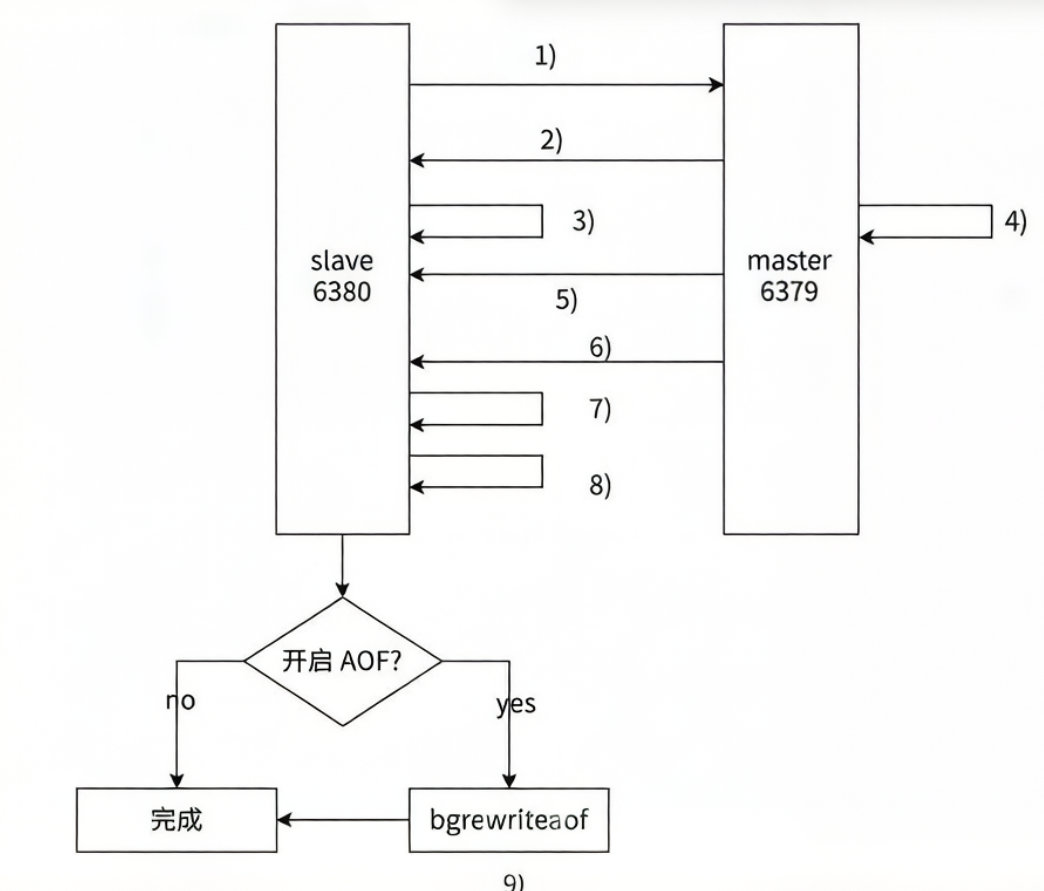
-
发送 psync 命令
从节点发送 psync 命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的运行 ID 和复制偏移量,所以发送 psync ? -1。
-
主节点响应全量复制
主节点根据命令,解析出要进行全量复制,回复 +FULLRESYNC 响应。
-
从节点保存主节点信息
从节点接收主节点的运行信息并进行保存。
-
主节点执行 bgsave
主节点执行 bgsave 进行 RDB 文件的持久化。
-
传输 RDB 文件
主节点发送 RDB 文件给从节点,从节点保存 RDB 数据到本地硬盘。
-
缓冲区数据补发
主节点将从生成 RDB 到接收完成期间执行的写命令写入缓冲区中,等从节点保存完 RDB 文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照 RDB 的二进制格式追加写入到收到的 RDB 文件中,保持主从一致性。
-
从节点清空旧数据
从节点清空自身原有旧数据。
-
从节点加载 RDB 文件
从节点加载 RDB 文件,得到与主节点一致的数据。
-
AOF 重写处理
如果从节点加载 RDB 完成之后,并且开启了 AOF 持久化功能,它会进行 bgrewriteaof 操作,得到最新的 AOF 文件。
5.5 部分复制
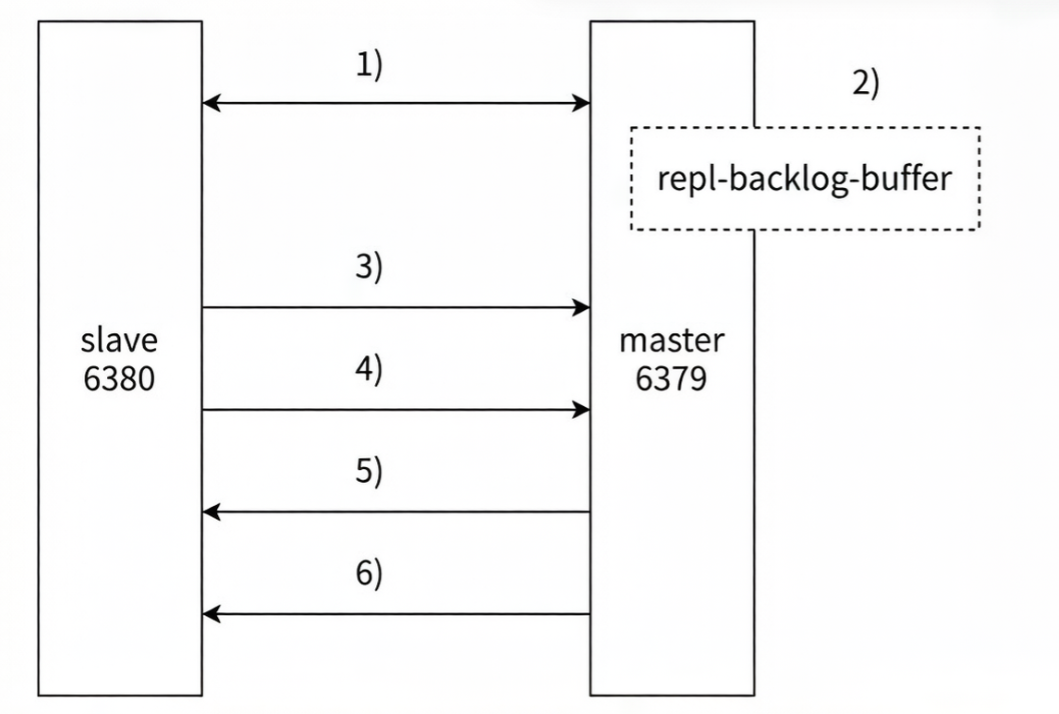
-
检测网络超时
当主从节点之间出现网络中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并中断复制连接。
-
命令暂存缓冲区
主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中。
-
网络恢复重连
当主从节点网络恢复后,从节点再次连上主节点。
-
发送 psync 请求
从节点将之前保存的 replicationId 和复制偏移量作为 psync 的参数发送给主节点,请求进行部分复制。
-
主节点验证与响应
主节点接到 psync 请求后,进行必要的验证。随后根据偏移量去复制积压缓冲区查找合适的数据,并响应 +CONTINUE 给从节点。
-
数据补发完成同步
主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
5.6 实时复制
主从节点在建立复制连接后,主节点会把自己收到的修改操作,通过 TCP 长连接的方式,源源不断地传输给从节点。从节点就会根据这些请求来同时修改自身的数据,从而保持和主节点数据的一致性。
另外,这样的长连接需要通过心跳包的方式来维护连接状态(这里的心跳是指应用层自己实现的心跳,而不是 TCP 自带的心跳)。
-
双向心跳检测机制
主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信。
-
主节点心跳检测
主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态。
-
从节点心跳上报
从节点默认每隔 1 秒向主节点发送 replconf ack {offset} 命令,给主节点上报自身当前的复制偏移量。
-
超时下线与恢复
如果主节点发现从节点通信延迟超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线,断开复制客户端连接。从节点恢复连接后,心跳机制继续进行。
5.7 复制积压缓冲区
复制积压缓冲区是保存在主节点上的⼀个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区
如果当前从节点需要的数据, 已经超出了主节点的积压缓冲区的范围, 则无法进行部分复制, 只能全量复制了.
哨兵机制小故事(资本家压榨的主厨)
既然有了"厨师与徒弟"的故事背景,那哨兵 (Sentinel)的出现,就是为了解决一个终极问题:如果主厨(Master)突然晕倒了,厨房该怎么办?
在没有哨兵的情况下,厨房会陷入瘫痪,直到老板手动找个新主厨。而有了哨兵,这一切都变成了自动化。
- 厨房监察员:哨兵(Sentinel) 为了保证厨房不关门,老板请了几位监察员(Sentinel)。他们的办公室就在厨房旁边,不干活,只负责盯着主厨看。 为什么要多个监察员?
防止一个监察员老眼昏花看错了。通常会有 3 个或 5 个监察员一起盯着。- 探头探脑:监控(Monitoring) 监察员们每隔一秒就会捅一下主厨:"喂,主厨,你还清醒吗?"(发送 PING)。 如果主厨正常回答(PONG),监察员就继续喝茶。 如果主厨没动静,监察员就开始拿小本子记录了。
- 我觉得他晕了:主观下线(SDOWN) 其中一个监察员发现主厨 30 秒没说话了,他会在心里嘀咕:"完蛋,主厨可能晕倒了。" 这时在监察员 A 的眼里,主厨处于**"主观下线"**状态。但他还没权力换人,万一只是主厨去厕所了呢?
- 大家都说他晕了:客观下线(ODOWN) 监察员 A 赶紧通过对讲机问其他同事:"喂,你们看主厨是不是晕了?" 其他监察员也凑过来观察。如果有超过半数(这个数字叫
Quorum/法定人数)的监察员都觉得主厨晕了,大家就会正式达成共识:"主厨确实没救了,准备换人!" 这就是**"客观下线"**。- 选出带头大哥:选举 Leader 既然要换人,监察员们得先选出一个"执行组长"。大家投个票,选出一个监察员来负责接下来的"提拔仪式"。这个组长会全权负责把哪个徒弟升为主厨。
- 提拔新主厨:故障转移(Failover) 监察员组长开始在徒弟(Slave)堆里挑人,他有几个筛选标准: 看忠诚度:如果某个徒弟经常跟主厨断开联系,说明他不靠谱,Pass。 看等级:如果老板给徒弟设过"优先级",谁高谁上。
看学识(重点:offset):谁的计步器数字最大?offset 最大的徒弟说明他掌握了主厨最新的菜谱,学得最全。就选他了!
看颜值(runID):如果大家都差不多,就选那个身份证号(runID)最小的。
选定后,监察员会对这个徒弟大喊一声:"从现在起,你就是主厨了!"(执行 slaveof no one)。- 昭告天下:通知(Notification) 新主厨上任后,监察员会做两件事: 通知徒弟:对剩下的徒弟喊:"别跟着老主厨了,现在这位是你们的新师父!"(让剩下的 Slave 追随新的 Master)。
通知客人(客户端):告诉来吃饭的客人们:"主厨换人了,以后下单请往这边走。"- 老主厨醒了怎么办? 如果过了一会儿,老主厨(旧 Master)醒了,灰头土脸地回到厨房。监察员会拦住他:"不好意思,现在已经有新主厨了,你现在只能从徒弟做起。"
于是,老主厨拿起了小本本,开始看新主厨的身份证号(replid),并对比自己的页码(offset),开始乖乖同步数据。
二、哨兵机制
上面谈到主从复制,如果主节点挂了得需要人工修复,配置各种参数保持主从关系还是太麻烦了,那有什么简单的方法吗?有的兄弟有的,我们可以新增一个节点,让它去监督主从节点情况,如果挂了,就自动帮节点恢复。
1. Redis Sentinel 架构
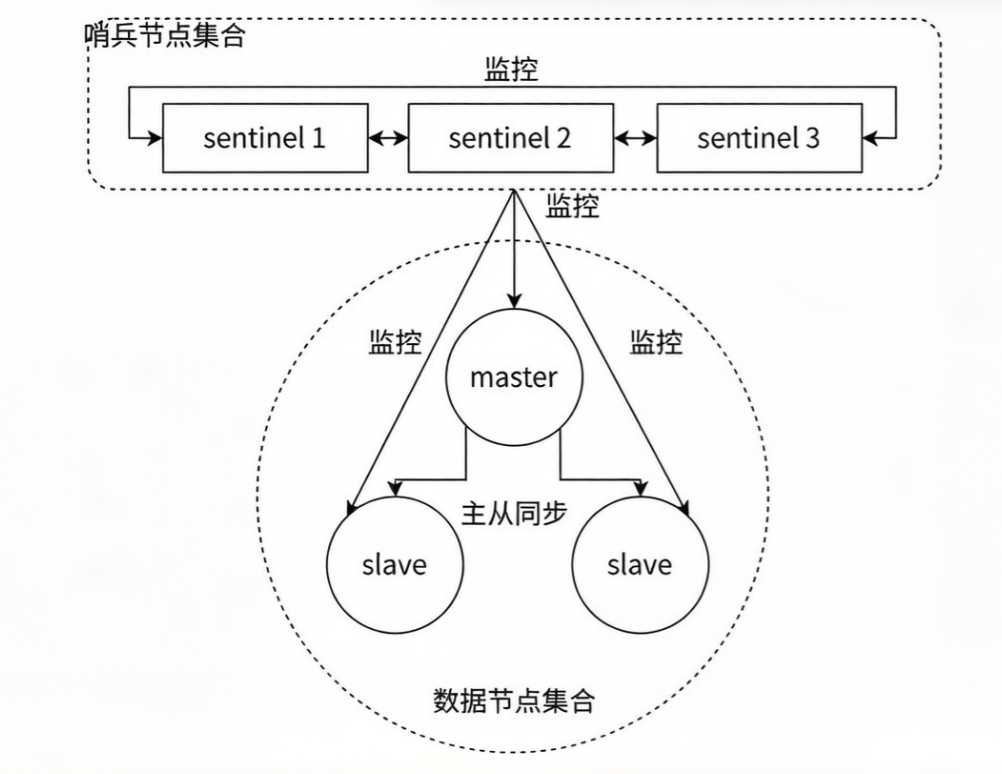
Redis Sentinel 相比于主从复制模式,是多了若干(建议保持奇数)Sentinel 节点用于实现监控数据节点。哨兵节点会定期监控所有节点(包含数据节点和其他哨兵节点)。针对主节点故障的情况,故障转移流程大致如下:
-
主节点故障
主节点故障,从节点同步连接中断,主从复制停止。
-
哨兵监控与协商
哨兵节点通过定期监控发现主节点出现故障。哨兵节点与其他哨兵节点进行协商,达成多数认同主节点故障的共识。这一步主要是防止该情况:出故障的不是主节点,而是发现故障的哨兵节点,该情况经常发生于哨兵节点的网络被孤立的场景下。
-
选举领导者
哨兵节点之间使用 Raft 算法选举出一个领导者角色,由该节点负责后续的故障转移工作。
-
执行故障转移
哨兵领导者开始执行故障转移:
从节点中选择一个作为新主节点
让其他从节点同步新主节点
通知应用层转移到新主节点
不难看出Redis Sentinel有如下功能:监控,故障转移,通知。
2.重新选举
选举流程:
1.主观下线:哨兵感觉主节点没心跳了,判定为主观下线。(此时还可能是哨兵问题)
2.客观下线:所有哨兵节点对主节点故障投票,当投票数>=既定票数(系统配置)那就是真挂了
3.选出leader:这个leader 指的是要干活的哨兵
选举过程是Raft算法:假定一共三个哨兵节点,S1,S2,S3
-
每个哨兵节点都给其他所有哨兵节点,发起一个"拉票请求"。(S1 -> S2,S1 -> S3,S2 -> S1,S2 -> S3,S3 -> S1,S3 -> S2)
-
收到拉票请求的节点,会回复一个"投票响应"。响应的结果有两种可能,投 or 不投。
比如 S1 给 S2 发了个投票请求,S2 就会给 S1 返回投票响应。
到底 S2 是否要投 S1 呢?取决于 S2 是否给别人投过票了。(每个哨兵只有一票 )。
如果 S2 没有给别人投过票,换言之,S1 是第一个向 S2 拉票的,那么 S2 就会投 S1。否则则不投。
-
一轮投票完成之后,发现得票超过半数的节点,自动成为 leader。
如果出现平票的情况(S1 投 S2,S2 投 S3,S3 投 S1,每人一票),就重新再投一次即可。
这也是为啥建议哨兵节点设置成奇数个的原因。如果是偶数个,则增大了平票的概率,带来不必要的开销。 -
leader 节点负责挑选一个 slave 成为新的 master。当其他的 sentinel 发现新的 master 出现了,就说明选举结束了。
简而言之, Raft 算法的核心就是 "先下手为强". 谁率先发出了拉票请求, 谁就有更大的概率成为leader.
4.leader 挑选出合适的 slave 成为新的 master
比较优先级 。优先级高(数值小的)的上位。优先级是配置文件中的配置项(slave-priority 或者 replica-priority)。
比较 replication offset ,谁复制的数据多,高的上位。
比较 run id,谁的 id 小,谁上位。