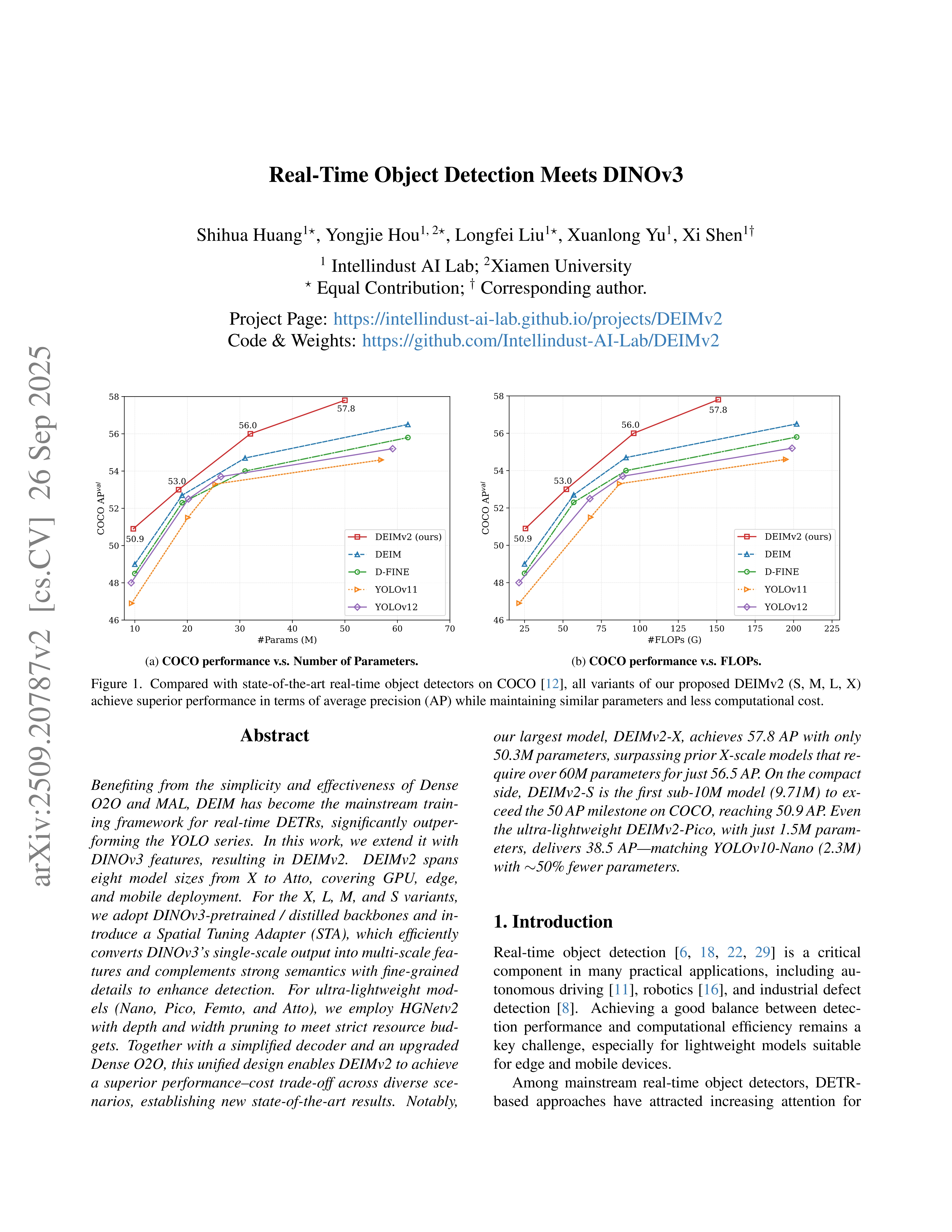
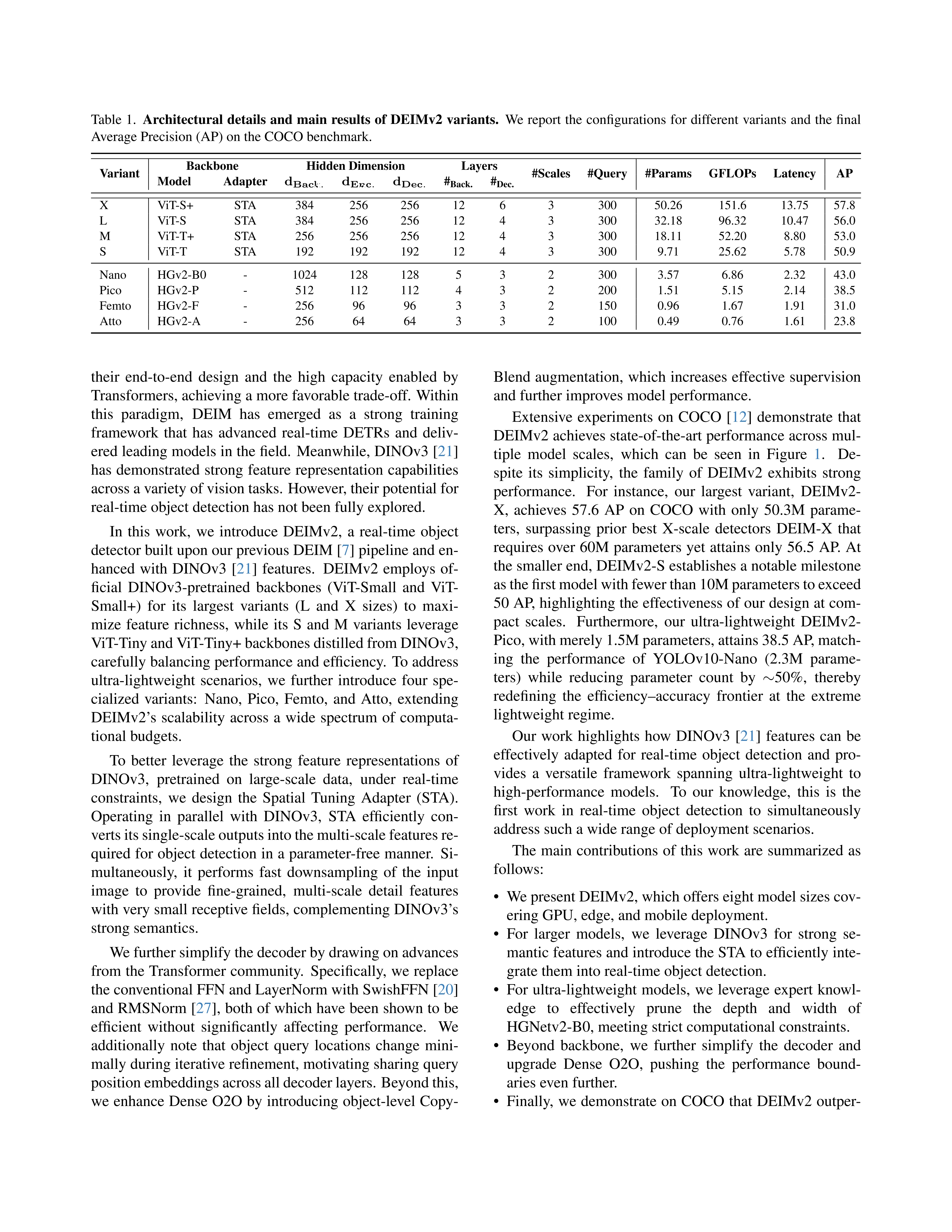
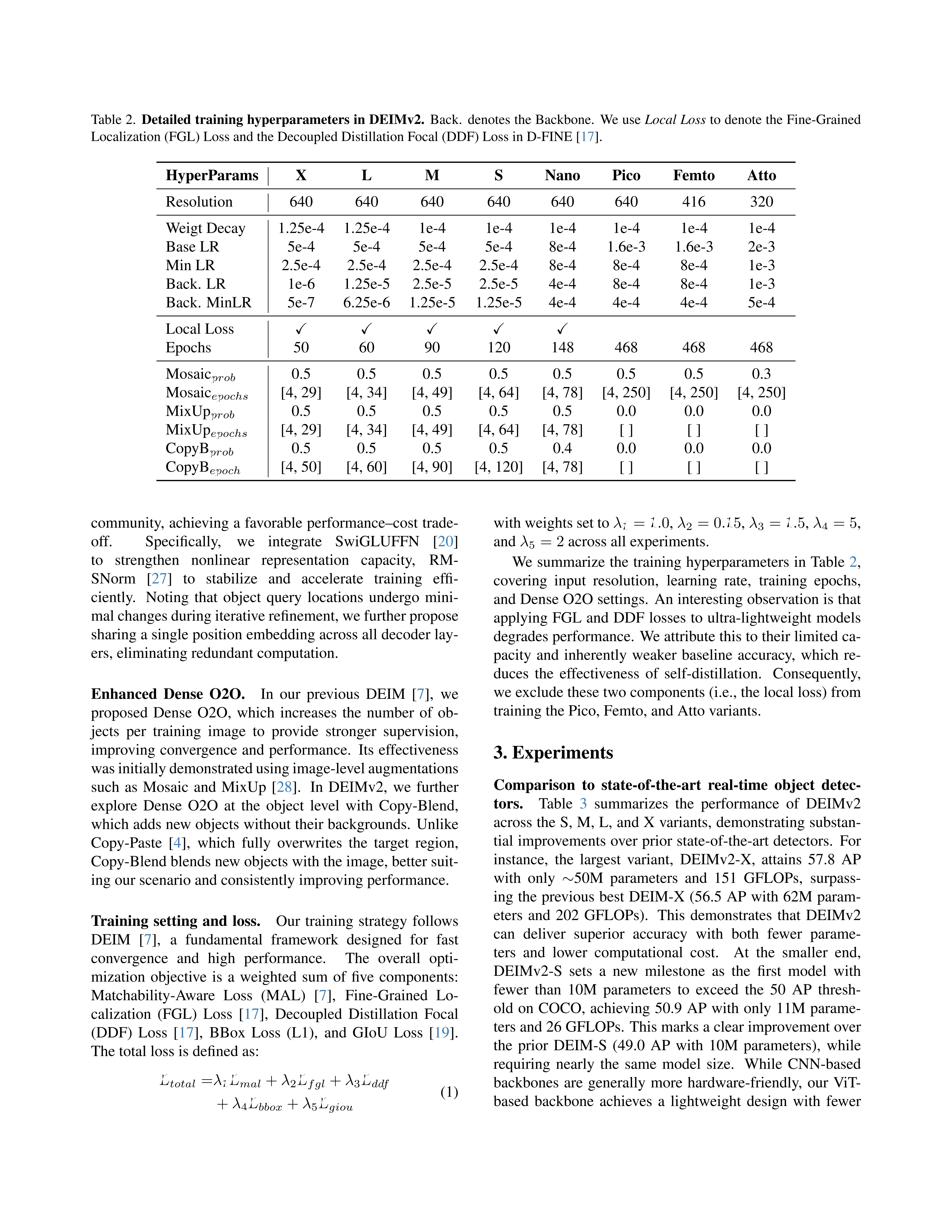
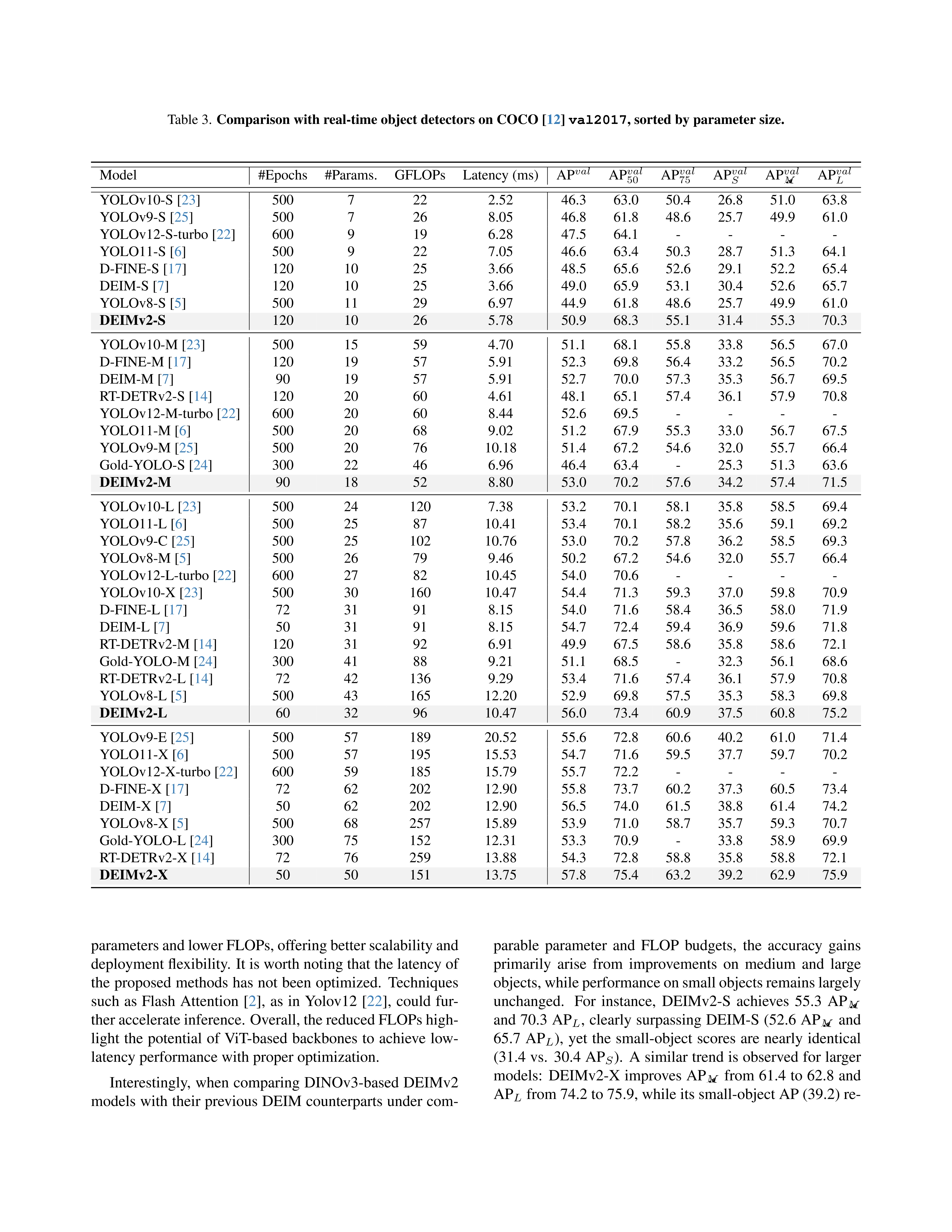
Real-Time Object Detection Meets DINOv3
Real-Time Object Detection Meets DINOv3 是 2025 年 CV 领域的重要方向,核心是将 Meta 最新自监督视觉基础模型DINOv3 的超强通用特征,与实时目标检测(如 DETR、YOLO)的高效推理架构深度融合,在参数量、精度、速度 三者间取得突破性平衡,尤其在边缘 / 端侧场景表现亮眼。Meta AI 2025 年 8 月发布,自监督视觉大模型,最大ViT-7B (70 亿参数),用17 亿图像 自监督预训练。无需微调即可在分类、检测、分割、深度估计 等多任务上逼近 / 刷新 SOTA;生成高质量密集特征图,适合下游检测 / 分割。