JVM 实战部署全指南:从 java -jar 到生产级高可用
作者 :Weisian
发布时间:2026年2月10日

你是否也曾这样启动过 Java 应用?
bash
java -jar myapp.jar简单、直接、无需思考。在开发或测试环境,这完全够用。
但当你把这段命令复制到生产服务器上,按下回车的那一刻------你其实已经将应用的命运交给了 JVM 的默认配置。
而默认配置,往往是最不适合生产环境的配置。
虽然以上命令简单快捷,但缺乏参数调优、运行监控和故障预警,在生产环境中极易出现内存溢出、GC 频繁卡顿、应用无响应等问题。

本文将以 一个普通 Java jar 包 为核心,让你从「只会启动 jar 包」进阶到「能稳定保障生产环境 JVM 运行」。
一、为什么不能直接 java -jar?
默认配置的三大致命缺陷
| 问题 | 后果 | 案例 |
|---|---|---|
| 堆内存无上限 | -Xmx 默认仅几百 MB(取决于物理内存),大流量下极易 OOM |
用户激增 → Eden 快速填满 → Full GC → OOM → 服务宕机 |
| 无 GC 日志 | 无法分析停顿原因,故障复盘靠猜 | 应用突然卡顿 5 秒,却找不到任何线索 |
| OOM 不留痕迹 | 进程直接退出,无堆转储文件,无法定位内存泄漏 | 内存泄漏导致每天凌晨重启,但无人知道根源 |
📌 核心原则 :
生产环境必须显式配置 JVM 参数,绝不能依赖默认值!

错误示范 vs 正确做法
bash
# 错误示范(依赖默认)
java -jar app.jar
# 正确做法:固定堆大小
java -Xms4g -Xmx4g -jar app.jar二、部署前准备:环境与参数规划
在正式部署前,充分的准备工作是保障应用稳定运行的第一步。
2.1 服务器环境检查清单
确保服务器环境符合要求:
bash
# 1. 检查操作系统版本和内核
cat /etc/os-release # CentOS/Ubuntu版本
uname -r # 内核版本
# 2. 检查内存和CPU
free -h # 内存总量及使用情况
lscpu # CPU核心数、架构
# 3. 检查Java版本
java -version
# 输出应包含:
# openjdk version "11.0.20" # 推荐JDK11+
# Java(TM) SE Runtime Environment
# Java HotSpot(TM) 64-Bit Server VM
# 4. 检查磁盘空间
df -h /opt /data # 应用部署目录和日志目录
# 5. 检查网络端口占用
netstat -tlnp | grep :8080 # 检查应用端口是否被占用生产环境最低要求:
- JDK版本:JDK 11+(LTS版本,推荐JDK 17/21)
- 内存:应用内存 × 1.5(预留GC和系统开销)
- 磁盘:至少保留20%空闲空间
- 系统:Linux(CentOS 7.6+/Ubuntu 20.04+)

2.2 应用信息收集
在部署前,先了解应用特性:
bash
# 1. 查看JAR包基础信息
unzip -l app.jar | grep -E "\.class$" | head -20 # 查看类文件结构
jar tf app.jar | grep -i "spring-boot" # 检查是否Spring Boot应用
# 2. 分析应用类型(核心)
# - Web服务(Tomcat/Undertow/Netty):低延迟优先
# - 批处理作业(定时任务):吞吐量优先
# - 微服务(Spring Cloud/Dubbo):均衡延迟与吞吐量
# - 大数据处理(Spark/Flink):大内存+高吞吐
# 3. 预估资源需求
# - QPS/平均响应时间(决定堆内存与GC策略)
# - 数据量/缓存大小(影响老年代配置)
# - 并发线程数(影响CPU与线程池配置)
三、启动参数配置:告别裸奔,给 jar 包加「防护甲」
直接使用 java -jar aa.jar 启动项目,JVM 会使用默认参数(如 JDK 11 中默认堆内存为物理内存的 1/4,默认 GC 为 G1),这些默认参数无法适配生产环境的需求,极易出现性能问题。我们需要手动配置启动参数,从「内存配置」「GC 配置」「诊断配置」三个维度,打造一套稳定的生产环境启动脚本。

3.1 核心参数分类:三大类参数覆盖生产需求
JVM 启动参数可分为「标准参数」(以 - 开头)、「非标准参数」(以 -X 开头)、「高级参数」(以 -XX 开头)。生产环境核心配置如下:
(1)内存配置参数(必配,避免内存溢出)
这是最基础也是最重要的参数,用于指定 JVM 各内存区域的大小。
| 参数 | 作用 | 生产环境配置示例 | 配置说明 |
|---|---|---|---|
-Xms |
堆初始内存大小 | -Xms4g |
与 -Xmx 设为相同值,避免 JVM 频繁扩容/缩容,减少性能开销 |
-Xmx |
堆最大内存大小 | -Xmx4g |
根据服务器物理内存配置(如 8GB 物理内存配 4GB) |
-Xmn |
新生代内存大小 | -Xmn2g |
占堆内存的 1/2(短生命周期对象多的场景,如接口服务,可适当增大) |
-XX:SurvivorRatio |
Eden 区与单个 Survivor 区的比例 | -XX:SurvivorRatio=8 |
默认 8:1,即 Eden:From:To = 8:1:1,无需频繁修改 |
-XX:MaxTenuringThreshold |
对象晋升老年代的年龄阈值 | -XX:MaxTenuringThreshold=10 |
比默认值 15 略低,让长期存活对象尽快晋升老年代,减少新生代压力 |
-XX:MetaspaceSize |
元空间初始容量 | -XX:MetaspaceSize=128m |
避免元空间频繁扩容(扩容时会触发 Full GC) |
-XX:MaxMetaspaceSize |
元空间最大容量 | -XX:MaxMetaspaceSize=512m |
限制元空间大小,防止元空间溢出耗尽系统内存 |
-XX:MaxDirectMemorySize |
堆外内存最大容量 | -XX:MaxDirectMemorySize=512m |
默认与 -Xmx 相等,手动限制避免堆外内存溢出 |
✅ 为什么
-Xms = -Xmx?
- 避免 JVM 在运行时动态扩容/缩容,减少内存抖动;
- 防止因内存不足触发 Full GC(扩容失败时会尝试 GC)。
如何确定堆大小?
- 总内存 ≤ 8GB :堆设为物理内存的 50%~70%(如 4G 机器 →
-Xmx3g); - 总内存 > 8GB:堆不超过 32GB(避免指针压缩失效),剩余内存留给 OS 缓存、堆外内存等;
- 容器化环境(Docker/K8s) :务必通过
-XX:MaxRAMPercentage=75.0动态分配。
💡 容器化特别提示 :
若使用 Docker,必须告知 JVM 容器内存限制,否则它会读取宿主机内存!
dockerfile# Dockerfile 示例 ENV JAVA_OPTS="-XX:MaxRAMPercentage=75.0" CMD ["sh", "-c", "java $JAVA_OPTS -jar app.jar"]

(2)GC 配置参数(必配,选择合适的垃圾回收器)
根据服务器堆内存大小选择合适的 GC 器,生产环境优先推荐 G1 GC(堆内存 4~16GB),若堆内存 >16GB 可选择 ZGC(JDK 11+)。
| 参数 | 作用 | 生产环境配置示例 | 配置说明 |
|---|---|---|---|
-XX:+UseG1GC |
启用 G1 垃圾回收器 | -XX:+UseG1GC |
大堆场景首选,支持可预测停顿时间,避免 Full GC 频繁触发 |
-XX:MaxGCPauseMillis |
G1 目标停顿时间 | -XX:MaxGCPauseMillis=200 |
目标停顿 200 毫秒(可根据业务需求调整,如延迟敏感场景设为 100 毫秒) |
-XX:+PrintGCDetails |
打印详细 GC 日志 | -XX:+PrintGCDetails |
用于排查 GC 问题,生产环境建议开启 |
-XX:+PrintGCTimeStamps |
打印 GC 发生的时间戳 | -XX:+PrintGCTimeStamps |
便于定位 GC 发生的具体时间 |
-Xloggc:/data/logs/aa/gc-%t.log |
指定 GC 日志输出路径 | -Xloggc:/data/logs/aa/gc-%t.log |
%t 为时间戳,避免日志文件过大 |
-XX:+UseGCLogFileRotation |
启用 GC 日志轮转 | -XX:+UseGCLogFileRotation |
避免单个 GC 日志文件过大 |
-XX:NumberOfGCLogFiles=10 |
GC 日志文件最大个数 | -XX:NumberOfGCLogFiles=10 |
最多保留 10 个 GC 日志文件 |
-XX:GCLogFileSize=100M |
单个 GC 日志文件大小 | -XX:GCLogFileSize=100M |
单个日志文件达到 100MB 时自动切割 |

(3)诊断配置参数(必配,便于故障排查)
这些参数用于在应用出现故障时,自动生成诊断文件,帮助我们定位问题根因。
| 参数 | 作用 | 生产环境配置示例 | 配置说明 |
|---|---|---|---|
-XX:+HeapDumpOnOutOfMemoryError |
OOM 时自动生成堆转储文件 | -XX:+HeapDumpOnOutOfMemoryError |
内存溢出时自动保存堆内存快照 |
-XX:HeapDumpPath=/data/logs/aa/heap-%t.hprof |
堆转储文件输出路径 | -XX:HeapDumpPath=/data/logs/aa/heap-%t.hprof |
保存到指定目录,%t 为时间戳 |
-XX:OnOutOfockError=/data/scripts/oom-alert.sh |
OOM 时执行自定义脚本 | -XX:OnOutOfMemoryError=/data/scripts/oom-alert.sh |
可编写 Shell 脚本实现邮件告警、钉钉告警,甚至自动重启应用(需谨慎) |
-Djava.awt.headless=true |
启用无桌面模式 | -Djava.awt.headless=true |
服务器无桌面环境时启用,避免 Java 应用尝试加载桌面组件导致异常 |
-Dfile.encoding=UTF-8 |
指定字符编码为 UTF-8 | -Dfile.encoding=UTF-8 |
避免中文乱码问题,统一应用字符编码 |
-Duser.timezone=Asia/Shanghai |
指定应用时区为北京时间 | -Duser.timezone=Asia/Shanghai |
避免时区不一致导致的时间数据错误 |

3.2 必须设置的参数(生产环境)
bash
# 1. 内存参数(避免动态调整)
-Xms4g -Xmx4g # 初始堆=最大堆,避免扩容开销
-Xmn2g # 新生代大小(堆的1/3~1/2)
# 2. GC日志(故障排查必备)
-Xlog:gc*,gc+age=trace,safepoint:file=/logs/gc.log:time,uptime,level,tags:filecount=10,filesize=100M
# 3. 故障诊断
-XX:+HeapDumpOnOutOfMemoryError # OOM时生成堆转储
-XX:HeapDumpPath=/logs/heap.hprof # 堆转储路径
-XX:ErrorFile=/logs/hs_err_pid%p.log # 错误日志
# 4. 编码与时区
-Dfile.encoding=UTF-8
-Duser.timezone=Asia/Shanghai3.3 根据应用类型选择GC器
(1)Web服务(低延迟优先)
bash
# G1 GC(JDK8+,堆内存4G~32G)
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200 # 目标停顿200ms
-XX:G1HeapRegionSize=4m # Region大小
-XX:InitiatingHeapOccupancyPercent=45 # 触发并发GC阈值
# ZGC(JDK11+,超低延迟要求)
-XX:+UseZGC
-XX:MaxGCPauseMillis=10 # 目标停顿10ms
-XX:+UseLargePages # 使用大页内存核心说明:G1下的分代模型与回收逻辑
G1 依然保留新生代、老年代的分代回收概念,但摒弃了传统固定大小的分代物理分区,而是基于 Region 实现了"逻辑分代",且新生代和老年代的垃圾回收全部由 G1 统一管理。
1. G1 对分代模型的改造
传统的 CMS、Parallel GC 是将堆内存划分为"固定大小"的新生代(Eden/S0/S1)和老年代物理区域;而 G1 把整个堆内存划分为多个大小相等的 Region(比如你配置的 4m),这些 Region 没有物理上的固定分代归属,而是通过"标记"动态分配为:
- 新生代 Region:包含 Eden、Survivor 区,用于存放新创建的对象;
- 老年代 Region:存放经过多次新生代回收后存活的对象;
- 还有少量特殊 Region(如 Humongous Region,存放大对象)。
2. G1 对新生代、老年代的回收方式
G1 会针对不同分代的 Region 执行不同的回收策略,但核心回收逻辑都由 G1 完成:
- 新生代回收(Young GC) :
当新生代 Region 占满时触发,属于 STW(Stop-The-World)回收,会把新生代存活对象复制到 Survivor 或老年代 Region,目标是快速清理新生代,停顿时间短。
这一步完全由 G1 控制,你配置的-XX:MaxGCPauseMillis=200也会约束 Young GC 的停顿时间。 - 混合回收(Mixed GC) :
当堆内存占用达到-XX:InitiatingHeapOccupancyPercent=45时触发,属于 G1 的核心回收逻辑。
它会先执行 Young GC,再挑选部分"垃圾多、回收收益高"的老年代 Region 一起回收(依然是 STW,但通过筛选 Region 控制停顿在目标值内)。 - Full GC :
若 G1 回收速度跟不上对象创建速度(比如内存碎片过多),会触发 Full GC(单线程标记-清除-整理),这是要尽量避免的,G1 配置的核心目标之一就是减少 Full GC。
3. 对比传统分代回收的核心差异
| 维度 | 传统分代 GC(如 CMS/Parallel) | G1 GC |
|---|---|---|
| 分代形式 | 物理固定分区 | 逻辑标记分区(Region 动态归属) |
| 回收主体 | 新生代/老年代各自独立回收 | G1 统一管理,混合回收新生代+老年代 |
| 停顿控制 | 无法精准控制 | 基于 -XX:MaxGCPauseMillis 精准控制 |
G1回收小结
- G1 保留新生代、老年代的逻辑分代(功能上和传统分代一致),但取消了固定物理分区,改用 Region 实现动态分代;
- 新生代(Young GC)和老年代(Mixed GC 中回收)的垃圾回收全部由 G1 统一执行,没有其他回收器参与;
-XX:MaxGCPauseMillis=200是 G1 控制所有 STW 回收(包括 Young GC、Mixed GC)停顿时间的核心参数,这也是 G1 适合低延迟 Web 服务的关键。
(2)批处理作业(吞吐量优先)
bash
# Parallel GC(计算密集型)
-XX:+UseParallelGC
-XX:+UseParallelOldGC
-XX:ParallelGCThreads=8 # GC线程数=CPU核心数
-XX:+UseAdaptiveSizePolicy # 自动调整各区大小(3)大数据/微服务(大内存场景)
bash
# G1 GC(大堆内存)
-XX:+UseG1GC
-XX:ConcGCThreads=4 # 并发GC线程数
-XX:G1ReservePercent=15 # 预留空间百分比
-XX:G1HeapWastePercent=5 # 可回收空间阈值3.4 内存区域调优参数
bash
# 新生代优化
-XX:SurvivorRatio=8 # Eden:Survivor=8:1:1
-XX:MaxTenuringThreshold=10 # 对象晋升年龄阈值
-XX:TargetSurvivorRatio=50 # Survivor区目标使用率
# 老年代优化
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=75 # CMS触发比例
# 元空间优化
-XX:MetaspaceSize=256m # 元空间初始大小
-XX:MaxMetaspaceSize=512m # 元空间最大大小3.5 Docker容器环境参数
bash
# JDK8u191+ 或 JDK10+ 支持
-XX:+UseContainerSupport # 启用容器支持
-XX:InitialRAMPercentage=75.0 # 初始内存占容器75%
-XX:MaxRAMPercentage=75.0 # 最大内存占容器75%
-XX:MinRAMPercentage=50.0 # 最小内存占容器50%
# 禁用实验性优化(容器环境可能不稳定)
-XX:-UseBiasedLocking # 禁用偏向锁
-XX:-UseCounterDecay # 禁用计数器衰减3.6 启动脚本示例(Shell脚本)
手动启动项目时,输入大量参数效率低下且易出错,我们可以编写标准化 Shell 脚本,整合所有核心 JVM 参数,实现一键启停,同时保证脚本的健壮性和可维护性。
(1)编写 start-aa.sh 启动脚本(带完整参数注释)
bash
#!/bin/bash
set -e # 脚本执行过程中遇到错误立即退出,避免后续无效操作
# ===================== 配置区(根据实际环境修改)=====================
# 项目名称(仅用于标识,建议与 jar 包名一致)
APP_NAME="aa.jar"
# JAR 包绝对路径(必填,示例:/data/app/aa/aa.jar)
APP_JAR_PATH="/data/app/aa/aa.jar"
# 日志根目录(GC 日志、堆转储、应用日志均存放于此)
LOG_ROOT_DIR="/data/logs/aa"
# OOM 告警脚本路径(可选,无则注释/留空)
OOM_ALERT_SCRIPT="/data/scripts/oom-alert.sh"
# ===================== JVM 参数配置区(核心)=====================
# JVM_OPTS 每行参数后加 \ 换行,最后一行不加
JVM_OPTS="\
# 1. 堆内存配置(生产必须显式指定,-Xms=-Xmx 避免内存动态扩容卡顿)
-Xms4g \ # 初始堆内存(4GB,与最大堆一致)
-Xmx4g \ # 最大堆内存(4GB,根据服务器配置调整,如 8g/16g)
-Xmn2g \ # 新生代内存(2GB,占堆 50%,G1 下可改用 -XX:NewRatio)
-XX:SurvivorRatio=8 \ # 新生代中 Eden/Survivor 比例(8:1,即 Eden=8份,S0/S1 各1份)
-XX:MaxTenuringThreshold=10 \ # 对象晋升老年代的最大年龄(10次YGC后进入老年代)
# 2. 元空间配置(存放类信息,避免元空间溢出)
-XX:MetaspaceSize=128m \ # 元空间初始大小(触发 Full GC 的阈值)
-XX:MaxMetaspaceSize=512m \ # 元空间最大大小(限制类加载上限,防止溢出)
# 3. 堆外内存配置(DirectBuffer,如 Netty/IO 场景必配)
-XX:MaxDirectMemorySize=512m \ # 堆外直接内存上限(512MB,避免堆外内存溢出)
# 4. GC 收集器配置(生产推荐 G1)
-XX:+UseG1GC \ # 使用 G1 垃圾收集器(低延迟、高吞吐,适合多核心服务器)
-XX:MaxGCPauseMillis=200 \ # G1 目标最大 GC 停顿时间(200ms,根据业务调整)
# 5. GC 日志配置(生产必须开启,排查 GC 问题核心依据)
-XX:+PrintGCDetails \ # 打印详细 GC 日志(包含内存区域变化)
-XX:+PrintGCTimeStamps \ # 打印 GC 发生的时间戳(相对于 JVM 启动)
-XX:+PrintGCDateStamps \ # 打印 GC 发生的具体日期时间(如 2026-02-09T10:00:00.123+0800)
-Xloggc:$LOG_ROOT_DIR/gc-%t.log \ # GC 日志路径,%t 自动填充时间戳(避免日志覆盖)
-XX:+UseGCLogFileRotation \ # 开启 GC 日志轮转(防止单文件过大)
-XX:NumberOfGCLogFiles=10 \ # 最多保留 10 个 GC 日志文件
-XX:GCLogFileSize=100M \ # 单个 GC 日志文件大小上限(100MB)
# 6. OOM 故障诊断配置(生产必须开启,定位内存泄漏核心)
-XX:+HeapDumpOnOutOfMemoryError \ # OOM 时自动生成堆转储文件(hprof)
-XX:HeapDumpPath=$LOG_ROOT_DIR/heap-%t.hprof \ # 堆转储文件路径,%t 避免覆盖
-XX:OnOutOfMemoryError=$OOM_ALERT_SCRIPT \ # OOM 时执行告警脚本(可选)
# 7. 通用基础配置(避免编码/时区/图形化问题)
-Djava.awt.headless=true \ # 禁用图形化界面(服务器无桌面,必开)
-Dfile.encoding=UTF-8 \ # 统一编码为 UTF-8,避免中文乱码
-Duser.timezone=Asia/Shanghai" # 时区设置为上海,避免时间/日志时区错乱
# ===================== 脚本执行逻辑 =====================
# 1. 检查日志目录,不存在则创建(含递归创建父目录)
mkdir -p "$LOG_ROOT_DIR" || { echo "错误:创建日志目录 $LOG_ROOT_DIR 失败!"; exit 1; }
# 2. 检查 JAR 包是否存在且可读
if [ ! -f "$APP_JAR_PATH" ] || [ ! -r "$APP_JAR_PATH" ]; then
echo "错误:JAR 包 $APP_JAR_PATH 不存在或无读取权限!"
exit 1
fi
# 3. 检查是否已有同名进程运行(避免重复启动)
PID=$(ps -ef | grep "$APP_JAR_PATH" | grep -v grep | awk '{print $2}')
if [ -n "$PID" ]; then
echo "错误:$APP_NAME 已在运行(进程 ID:$PID),请勿重复启动!"
exit 1
fi
# 4. 启动应用(后台运行,统一日志输出)
echo "正在启动 $APP_NAME ..."
# nohup 核心作用:脱离终端运行;2>&1:将错误输出重定向到标准输出;&:后台运行
nohup java $JVM_OPTS -jar "$APP_JAR_PATH" > "$LOG_ROOT_DIR/app.log" 2>&1 &
# 获取启动后的进程 ID
NEW_PID=$!
# 验证进程是否启动成功(延迟 2 秒检查)
sleep 2
if ps -p "$NEW_PID" > /dev/null; then
echo "✅ $APP_NAME 启动成功!"
echo "进程 ID:$NEW_PID"
echo "应用日志:$LOG_ROOT_DIR/app.log"
echo "GC 日志:$LOG_ROOT_DIR/gc-*.log"
echo "堆转储文件:$LOG_ROOT_DIR/heap-*.hprof(OOM 时生成)"
# 将 PID 写入文件,方便停止脚本读取
echo "$NEW_PID" > "$LOG_ROOT_DIR/app.pid"
else
echo "❌ $APP_NAME 启动失败!请查看日志:$LOG_ROOT_DIR/app.log"
exit 1
fi(2)编写 stop-aa.sh 停止脚本(强化优雅停机)
bash
#!/bin/bash
set -e
# ===================== 配置区(与启动脚本保持一致)=====================
APP_JAR_PATH="/data/app/aa/aa.jar"
LOG_ROOT_DIR="/data/logs/aa"
PID_FILE="$LOG_ROOT_DIR/app.pid" # 启动脚本生成的 PID 文件路径
# ===================== 脚本执行逻辑 =====================
# 1. 获取进程 ID(优先从 PID 文件读取,兜底用 ps 查找)
if [ -f "$PID_FILE" ]; then
PID=$(cat "$PID_FILE")
# 验证 PID 文件中的进程是否有效
if ! ps -p "$PID" > /dev/null; then
echo "警告:PID 文件 $PID_FILE 中的进程 $PID 已不存在,清理无效 PID 文件..."
rm -f "$PID_FILE"
PID=""
fi
fi
# 兜底查找进程(防止 PID 文件丢失)
if [ -z "$PID" ]; then
PID=$(ps -ef | grep "$APP_JAR_PATH" | grep -v grep | awk '{print $2}')
fi
# 2. 停止进程
if [ -n "$PID" ]; then
echo "正在优雅停止应用(进程 ID:$PID)..."
# 第一步:发送 SIGTERM(15)信号,触发优雅停机(应用可执行资源释放、连接关闭)
kill -15 "$PID"
# 等待 10 秒,检查进程是否已停止(可根据业务调整等待时间)
WAIT_TIME=0
while ps -p "$PID" > /dev/null && [ $WAIT_TIME -lt 10 ]; do
echo "等待进程停止...(已等待 $WAIT_TIME 秒)"
sleep 1
WAIT_TIME=$((WAIT_TIME + 1))
done
# 第二步:若仍未停止,强制杀死进程(SIGKILL 9,无优雅停机)
if ps -p "$PID" > /dev/null; then
echo "警告:优雅停止超时,强制杀死进程 $PID ..."
kill -9 "$PID"
sleep 2
fi
# 验证最终状态
if ! ps -p "$PID" > /dev/null; then
echo "✅ 应用已成功停止!"
rm -f "$PID_FILE" # 清理 PID 文件
else
echo "❌ 进程 $PID 停止失败!"
exit 1
fi
else
echo "提示:$APP_JAR_PATH 对应的应用未运行!"
fi(3)脚本完整使用步骤
步骤 1:上传脚本到服务器
将 start-aa.sh 和 stop-aa.sh 上传到服务器的统一脚本目录(示例:/data/scripts)。
步骤 2:修改配置(关键)
编辑两个脚本的「配置区」,替换为实际环境的路径:
APP_JAR_PATH:填写 JAR 包的绝对路径(如/data/app/aa/aa.jar);LOG_ROOT_DIR:填写日志存放目录(如/data/logs/aa);- 若无需 OOM 告警,将
OOM_ALERT_SCRIPT注释(加#)或留空。
步骤 3:赋予脚本执行权限
执行以下命令,给脚本添加可执行权限(必须):
bash
chmod +x /data/scripts/start-aa.sh /data/scripts/stop-aa.sh步骤 4:启动应用
bash
# 切换到脚本目录(可选,也可直接用绝对路径)
cd /data/scripts
# 执行启动脚本
./start-aa.sh
# 或直接用绝对路径执行(推荐,避免目录切换问题)
/data/scripts/start-aa.sh启动成功输出示例:
正在启动 aa.jar ...
✅ aa.jar 启动成功!
进程 ID:12345
应用日志:/data/logs/aa/app.log
GC 日志:/data/logs/aa/gc-*.log
堆转储文件:/data/logs/aa/heap-*.hprof(OOM 时生成)步骤 5:停止应用
bash
# 绝对路径执行停止脚本
/data/scripts/stop-aa.sh停止成功输出示例:
正在优雅停止应用(进程 ID:12345)...
等待进程停止...(已等待 0 秒)
✅ 应用已成功停止!步骤 6:开机自启配置(生产推荐)
相比 /etc/rc.local,systemd 更稳定可靠,配置步骤如下:
-
创建
systemd服务文件:bashvi /etc/systemd/system/aa.service -
写入以下内容(替换路径为实际值):
ini[Unit] Description=AA Application Service After=network.target [Service] Type=simple User=appuser # 推荐使用非 root 用户运行(需提前创建) Group=appuser ExecStart=/data/scripts/start-aa.sh ExecStop=/data/scripts/stop-aa.sh Restart=on-failure # 进程异常退出时自动重启 RestartSec=5 # 重启间隔 5 秒 TimeoutStopSec=15 # 停止超时时间 15 秒 [Install] WantedBy=multi-user.target -
重新加载
systemd并设置开机自启:bash# 重新加载配置 systemctl daemon-reload # 设置开机自启 systemctl enable aa.service # 启动服务(替代手动执行 start-aa.sh) systemctl start aa.service # 查看服务状态 systemctl status aa.service # 停止服务(替代手动执行 stop-aa.sh) systemctl stop aa.service
(4)避坑提醒与补充说明
-
JVM 参数核心避坑:
-Xms必须等于-Xmx:避免 JVM 运行中动态扩容堆内存,导致卡顿;- G1 收集器下,
-Xmn可替换为-XX:NewRatio=2(新生代占堆 1/3),更适配 G1 的动态分区; HeapDumpPath目录必须有写入权限:否则 OOM 时无法生成堆转储文件,失去排查依据;- 禁止生产环境开启
XX:+PrintCommandLineFlags等调试参数,避免泄露配置。
-
脚本健壮性补充:
- 启动脚本增加
set -e:遇到错误立即退出,避免「JAR 包不存在仍执行启动」的无效操作; - 增加进程重复启动检查:防止同一应用多实例运行导致端口冲突;
- PID 文件机制:启动时写入 PID,停止时优先读取,避免
ps命令误匹配其他进程。
- 启动脚本增加
-
日志管理补充:
- 应用日志
app.log会持续增大,建议配合logrotate做日志轮转(每日切割、保留 7 天); - GC 日志已开启轮转,无需额外配置,但需定期清理老旧日志(避免磁盘占满)。
- 应用日志
-
权限安全补充:
-
禁止用
root用户运行 Java 进程:创建专用用户(如appuser),并赋予APP_JAR_PATH、LOG_ROOT_DIR的读写权限; -
执行命令示例(创建用户并授权):
bash# 创建用户 useradd -m appuser # 授权目录权限 chown -R appuser:appuser /data/app/aa /data/logs/aa /data/scripts
-
小结
- JVM 参数核心 :堆内存(
-Xms/-Xmx)、GC 收集器(G1)、故障诊断(GC 日志/OOM 堆转储)是生产环境必配项,每个参数都对应明确的解决场景; - 脚本使用关键 :先修改配置区路径 → 赋予执行权限 → 用绝对路径执行启动/停止命令,生产推荐配置
systemd实现开机自启和异常重启; - 健壮性保障:脚本增加进程检查、PID 文件、权限校验,避免重复启动、误杀进程、日志目录无权限等常见问题。
四、运行时监控:实时掌握 JVM 运行状态
应用启动后,我们需要实时监控 JVM 的运行状态,及时发现潜在问题。
4.1 命令行工具:轻量高效,服务器直接使用

(1)jps:查找 Java 进程 ID
jps 用于查找 Java 进程的 PID,是后续所有 JVM 工具的基础。
bash
# 查看所有 Java 进程(PID + 主类名/ jar 包名)
jps -l
# 查看详细信息(PID + 主类名 + JVM 启动参数)
jps -v(2)jstat:实时监控 JVM 内存与 GC 状态
jstat 用于实时监控 JVM 的内存使用率、GC 次数、GC 耗时等指标。
bash
# 监控 GC 状态,每 1000 毫秒采样一次,共采样 10 次
jstat -gc 12345 1000 10
# 监控 GC 详细状态(含各内存区域使用率)
jstat -gcutil 12345 1000 10🔍 解释说明:
12345 是 Java 进程的 PID(Process ID),即目标 JVM 应用在操作系统中的进程编号。
当你在服务器上运行一个 Java 程序(例如通过 java -jar app.jar 启动),操作系统会为该进程分配一个唯一的数字标识符,这就是 PID。
jstat 是 JDK 自带的命令行监控工具,它需要知道 要监控哪个 Java 进程,因此必须传入该进程的 PID。
✅ 如何获取 PID?
使用 jps 命令(JDK 自带)是最简单的方式:
bash
$ jps -l
12345 /data/app/aa.jar
12346 org.apache.catalina.startup.Bootstrap
12347 sun.tools.jps.Jps
- 第一列(如
12345)就是 PID; - 第二列是主类或 JAR 文件路径。
你也可以用系统命令:
bash
# Linux/macOS
ps -ef | grep aa.jar
# 或
pgrep -f aa.jar📌 示例:完整操作流程
bash
# 1. 查找 Java 进程 PID
$ jps -l
12345 /data/app/aa.jar
# 2. 使用 jstat 监控该进程的 GC 情况(每秒一次,共5次)
$ jstat -gcutil 12345 1000 5输出示例:

1. 列名含义速查表
| 列名 | 全称 | 含义 |
|---|---|---|
| S0 | Survivor 0 区使用率 | 0.00%,说明当前没有对象在 S0 |
| S1 | Survivor 1 区使用率 | 76.52%,S1 区大部分被占用 |
| E | Eden 区使用率 | 64.44%,新生代 Eden 区已用近 2/3 |
| O | 老年代使用率 | 62.17%,老年代占用超过一半 |
| M | 元空间使用率 | 99.36%,元空间几乎占满,这是一个关键风险点 |
| CCS | 压缩类空间使用率 | 96.97%,压缩类空间也接近饱和 |
| YGC | 新生代 GC 次数 | 37 次,Young GC 执行了 37 轮 |
| YGCT | 新生代 GC 总耗时 | 0.141 秒,所有 Young GC 加起来才 141ms |
| FGC | Full GC 次数 | 0 次,还没有发生过 Full GC,这是好事 |
| FGCT | Full GC 总耗时 | 0.000 秒,无 Full GC 耗时 |
| CGC | 并发 GC 次数 | 20 次,G1 的并发标记/混合回收执行了 20 轮 |
| CGCT | 并发 GC 总耗时 | 0.034 秒,并发 GC 总耗时仅 34ms |
| GCT | GC 总耗时 | 0.175 秒,所有 GC 加起来总耗时 175ms |
2. 关键信息解读
- 元空间(M)和压缩类空间(CCS)严重占用
- M 达到 99.36%,CCS 达到 96.97%,这是最需要关注的信号。
- 元空间用于存放类的元数据(如类定义、方法、常量池等),如果持续高占用,可能触发 Full GC 来尝试回收,甚至导致
OutOfMemoryError: Metaspace。 - 可能原因:动态生成类过多(如反射、代理、ASM)、类加载器泄漏、元空间初始值设置过小等。
说明一下,示例未配置元空间大小,JDK默认是21M,所以使用率会达到99%以上。
查看当前JVM的元空间相关参数(42388为进程ID)
bash
jinfo -flag MetaspaceSize 42388 # 元空间初始触发GC的阈值(默认约21MB)
jinfo -flag MaxMetaspaceSize 42388 # 元空间最大限制(默认无上限,受物理内存限制)
jinfo -flag MinMetaspaceFreeRatio 42388 # 最小空闲比例(默认40)
jinfo -flag MaxMetaspaceFreeRatio 42388 # 最大空闲比例(默认70)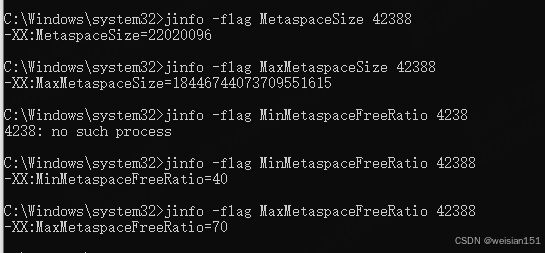
实际在生产中建议配置到128M或256M,如果内存够大,可以继续追加。如:
bash
# 针对JDK8+(G1 GC场景)的元空间调优参数
-XX:MetaspaceSize=128m # 初始触发GC的阈值(默认21M,调大减少初始GC次数)
-XX:MaxMetaspaceSize=512m # 元空间最大上限(根据服务器内存调整,建议256m~1024m)
-XX:MinMetaspaceFreeRatio=50 # 空闲比例低于50%时,扩容元空间
-XX:MaxMetaspaceFreeRatio=80 # 空闲比例高于80%时,收缩元空间
-XX:+CMSClassUnloadingEnabled # 允许卸载无用的类(G1下也生效,JDK8需显式开启)
-XX:+ExplicitGCInvokesConcurrent # 让System.gc()触发并发GC,而非Full GC-
老年代(O)占用 62.17%
- 老年代占用超过 60%,说明有不少长期存活的对象。
- 结合 G1 的并发 GC(CGC=20 次)来看,G1 正在积极地通过并发标记和混合回收来管理老年代,目前还没有触发 Full GC,说明回收策略暂时有效,但需要持续监控。
-
GC 性能表现良好
- 无 Full GC(FGC=0):这是非常理想的状态,避免了长时间的 STW。
- 总 GC 耗时极低:GCT=0.175 秒,说明 GC 对应用性能的影响非常小。
- Young GC 高效:37 次 Young GC 总耗时仅 0.141 秒,平均每次约 3.8ms,符合低延迟要求。
-
G1 并发回收活跃
- CGC=20 次,说明 G1 已经执行了 20 轮并发回收周期,这是 G1 正常工作的表现,它在后台并发地标记和回收老年代的垃圾,以避免 Full GC。
3. 综合结论与建议
当前状态:
- GC 性能整体健康,没有 Full GC,总停顿时间很短。
- 最大的风险点在于 元空间(Metaspace)严重不足,这是未来可能触发 Full GC 甚至 OOM 的隐患。
建议行动:
- 立即监控元空间 :持续观察 M 和 CCS 的使用率变化。如果持续走高,需要:
- 检查是否有动态类生成或类加载器泄漏的问题。
- 适当调大元空间的最大容量,例如添加 JVM 参数
-XX:MaxMetaspaceSize=512m。
- 关注老年代增长:如果老年代占用率持续上升,需要分析长期存活对象,排查内存泄漏。
- 保持当前 GC 配置:目前 G1 的表现良好,没有必要调整 Young GC 或并发回收的阈值,除非元空间问题导致了 Full GC。
说明:
💡 注意:
jstat只能监控 本地 的 Java 进程,且要求当前用户对目标进程有访问权限(通常是同一用户启动的)。
⚠️ 常见错误
12345 not found:PID 不存在(进程已退出);Could not attach to 12345:权限不足(如用 root 启动的 Java 进程,普通用户无法 attach);jstat: command not found:未正确配置 JDK 环境变量(确保JAVA_HOME/bin在PATH中)。
(3)jmap:查看 JVM 内存详情与生成堆转储文件
jmap 用于查看 JVM 内存配置、对象分布情况,以及手动生成堆转储文件。
bash
# 查看 JVM 堆内存配置与当前使用情况
jmap -heap 12345
# 查看堆中对象统计信息
jmap -histo 12345
# 手动生成堆转储文件
jmap -dump:format=b,file=/path/to/heap.hprof 12345(4)jstack:查看 Java 线程状态,排查线程死锁与卡顿
jstack 用于查看 Java 线程的堆栈信息,排查线程死锁、线程阻塞等问题。
bash
# 查看所有线程的堆栈信息
jstack 12345 > thread.log
# 查找线程死锁
jstack -l 12345 > thread-deadlock.log(5)自动化监控脚本
编写 monitor.sh 实现多维度自动监控,替代人工频繁执行命令:
bash
#!/bin/bash
# monitor.sh - JVM应用监控脚本
APP_NAME=$1
PID_FILE="/var/run/${APP_NAME}.pid"
LOG_DIR="/data/logs/${APP_NAME}"
INTERVAL=5 # 监控刷新间隔(秒)
# 前置检查
if [ ! -f "${PID_FILE}" ]; then
echo "错误:PID文件不存在 ${PID_FILE}"
exit 1
fi
PID=$(cat "${PID_FILE}")
# 监控主逻辑
echo "开始监控应用: ${APP_NAME} (PID: ${PID})"
echo "按 Ctrl+C 停止监控"
echo "======================================"
while true; do
clear
# 1. 进程存活检查
if ! ps -p ${PID} > /dev/null 2>&1; then
echo "错误:进程 ${PID} 不存在"
exit 1
fi
# 2. 系统资源占用
echo "=== 系统资源 ==="
top -b -n 1 -p ${PID} | tail -2
# 3. JVM内存状态
echo -e "\n=== JVM内存使用 ==="
jstat -gc ${PID} 1000 1 2>/dev/null || echo "jstat不可用"
# 4. 堆内存Top10对象
echo -e "\n=== 堆内存Top10对象 ==="
jmap -histo:live ${PID} 2>/dev/null | head -15 | tail -10 || echo "jmap不可用"
# 5. 线程状态分布
echo -e "\n=== 线程状态 ==="
jstack ${PID} 2>/dev/null | grep -E "java.lang.Thread.State" | sort | uniq -c | sort -rn || echo "jstack不可用"
# 6. 最近GC记录
if [ -d "${LOG_DIR}" ]; then
echo -e "\n=== 最近GC记录 ==="
gc_file=$(ls -t ${LOG_DIR}/gc_*.log 2>/dev/null | head -1)
if [ -f "${gc_file}" ]; then
grep -E "GC\(|Full GC" "${gc_file}" | tail -3
fi
fi
# 7. 应用错误日志
echo -e "\n=== 最近错误日志 ==="
log_file=$(ls -t ${LOG_DIR}/app_*.log 2>/dev/null | head -1)
if [ -f "${log_file}" ]; then
grep -i "error\|exception" "${log_file}" | tail -3
fi
# 输出监控时间
echo -e "\n======================================"
echo "监控时间: $(date '+%Y-%m-%d %H:%M:%S')"
echo "下次刷新: ${INTERVAL}秒后"
sleep ${INTERVAL}
done4.2 可视化工具:直观高效,适合深度分析(企业级实操版)
可视化工具是生产环境排查 JVM 问题的核心手段,不同工具适配不同场景,以下是「从安装到分析」的完整实操指南:

(1)MAT(Memory Analyzer Tool):内存泄漏排查神器(免费、开源)
MAT 是 Eclipse 基金会出品的堆转储分析工具,核心优势是内存泄漏定位精准、分析效率高 ,适合离线分析 OOM 生成的 .hprof 文件。
① 下载与安装
- 下载地址:https://www.eclipse.org/mat/downloads.php(选择对应系统版本)
- 环境要求:JDK 8+,建议分配 MAT 自身 2GB+ 内存(分析大堆转储文件需调整)
- 调整 MAT 内存:编辑
MAT安装目录/MemoryAnalyzer.ini,修改-Xmx4g(根据堆转储文件大小调整,如分析 8GB 堆转储需设-Xmx8g)
- 调整 MAT 内存:编辑
② 核心实操步骤(排查内存泄漏)
- 准备堆转储文件 :确保 OOM 生成的
.hprof文件完整(启动脚本中已配置-XX:+HeapDumpOnOutOfMemoryError); - 导入文件 :
- 打开 MAT →
File→Open Heap Dump→ 选择.hprof文件 → 等待解析(大文件需几分钟); - 首次导入会提示「Leak Suspects Report」,直接选择生成(核心泄漏分析报告);
- 打开 MAT →
- 核心分析流程 :
- 第一步:查看「Leak Suspects」报告(自动标注泄漏疑点)
- 报告顶部会显示「Problem Suspect 1/2」,标注疑似泄漏的对象占比(如「90% 内存被 ArrayList 占用」);
- 重点关注「Accumulated Size」(累计占用内存)和「Description」(泄漏原因描述);
- 第二步:分析「Dominator Tree」(支配树,看最大内存占用对象)
- 左侧面板 →
Dominator Tree→ 按「Retained Heap」(保留堆,即对象被回收后可释放的内存)降序排列; - 找到占用内存最大的对象(如
com.xxx.service.DataService),展开查看引用链;
- 左侧面板 →
- 第三步:追踪「Path to GC Roots」(GC 根引用链,定位泄漏根源)
- 右键可疑对象 →
Path to GC Roots→ 选择exclude weak references(排除弱引用,只看强引用); - 最终会显示对象被哪些根节点(如静态变量、线程、连接池)引用,导致无法被 GC 回收;
- 右键可疑对象 →
- 第四步:辅助分析「Histogram」(直方图,统计对象数量/大小)
- 左侧面板 →
Histogram→ 按类名筛选(如搜索String/List),查看异常多的对象; - 结合业务代码,定位「对象创建过多、未释放」的逻辑(如批量查询未分页、缓存未设置过期)。
- 左侧面板 →
- 第一步:查看「Leak Suspects」报告(自动标注泄漏疑点)
③ 避坑要点
- 分析大堆转储文件(>4GB)时,需提前调整 MAT 自身内存(
MemoryAnalyzer.ini中-Xmx),否则会内存溢出; - 导入
.hprof时选择「Parse heap dump in chunks」(分块解析),避免卡顿; - 优先分析「Retained Heap」而非「Shallow Heap」(Shallow Heap 仅对象自身大小,Retained Heap 包含引用对象)。

(2)JProfiler:全能型 JVM 监控分析工具(商业级)
JProfiler 是付费工具(支持 14 天试用),核心优势是实时监控+离线分析一体化,适合排查「内存泄漏、线程死锁、方法耗时、GC 异常」等复杂问题。
① 下载与安装
- 下载地址:https://www.ej-technologies.com/products/jprofiler/overview.html
- 安装后需激活(试用版可直接生成激活码),支持 Windows/Linux/Mac 全平台。
② 核心实操场景
场景1:实时监控生产环境 JVM(远程连接)
-
服务器端配置 JVM 参数(启动脚本中添加):
bash# JProfiler 远程监控参数(替换为实际 JProfiler 版本和端口) -agentpath:/opt/jprofiler13/bin/linux-x64/libjprofilerti.so=port=8849 -Xmx4g -Xms4g # 保留原有 JVM 参数 -
客户端连接:
- 打开 JProfiler →
New Session→Remote Attach→ 填写服务器 IP + 端口(8849)→ 连接; - 成功后可查看实时指标:
- 内存面板:堆/非堆内存使用趋势、新生代/老年代占比、对象创建速率;
- GC 面板:YGC/FGC 次数/耗时、GC 暂停时间、内存回收量;
- 线程面板:线程数量趋势、线程状态(RUNNABLE/BLOCKED/WAITING)、死锁检测(自动标注死锁线程);
- 方法调用面板:热点方法(CPU 耗时Top10)、方法调用栈、参数传递。
- 打开 JProfiler →
场景2:离线分析堆转储/线程快照
- 生成快照:
- 实时监控时 →
Snapshot→Take Heap Snapshot/Take Thread Snapshot; - 或直接导入 MAT 生成的
.hprof文件;
- 实时监控时 →
- 分析线程死锁:
- 线程面板 →
Deadlocks→ 自动显示死锁线程名称、锁资源、等待链; - 示例:线程 A 持有锁
Lock1,等待锁Lock2;线程 B 持有锁Lock2,等待锁Lock1→ 定位死锁代码行。
- 线程面板 →
场景3:方法耗时分析(性能瓶颈排查)
- 打开「Call Tree」面板 → 按「Total Time」降序排列 → 找到耗时最长的方法(如
com.xxx.dao.UserDao.queryAll); - 右键方法 →
Show Call Graph→ 查看方法调用链路,定位「慢 SQL、循环次数过多」等问题; - 结合「CPU Profiler」面板,查看方法的 CPU 占用率,区分「CPU 密集型」和「IO 密集型」瓶颈。
③ 生产环境使用建议
- 非紧急问题优先用「离线分析」(避免实时监控占用服务器资源);
- 远程监控时,服务器需开放端口(8849),且仅允许内网访问(避免安全风险);
- 试用版到期后,可选择「仅离线分析」(无需激活),或采购企业版(支持多实例监控)。
(3)Prometheus + Grafana:企业级JVM监控告警体系(开源、可扩展)
这是目前企业最主流的 JVM 监控方案,核心是「指标采集→存储→可视化→告警」全链路自动化,适合大规模集群监控。
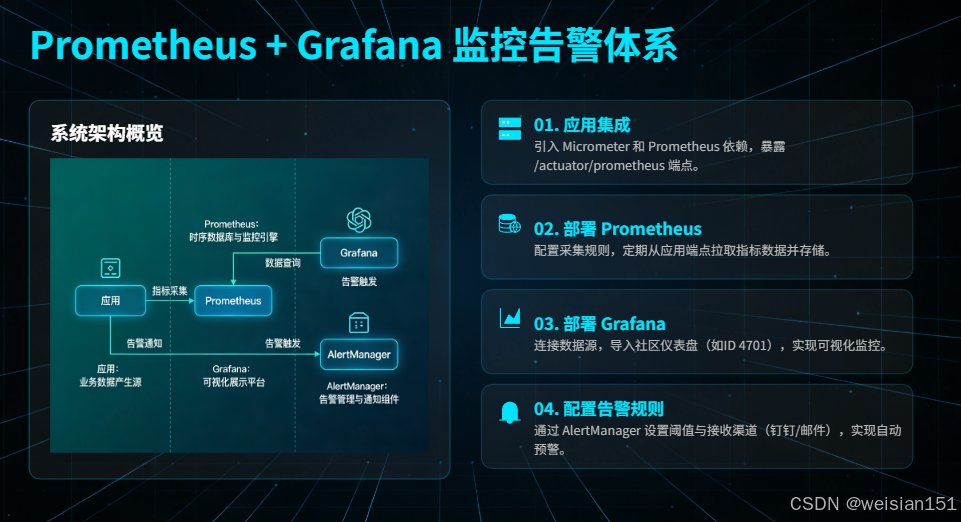
① 完整部署步骤(从集成到可视化)
步骤1:应用集成 Micrometer(暴露 JVM 指标)
Micrometer 是指标收集门面,支持对接 Prometheus,Spring Boot 2.x+ 已内置集成:
-
添加依赖(Maven):
xml<!-- Spring Boot Actuator(暴露监控端点) --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!-- Micrometer Prometheus 适配 --> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency> -
配置
application.yml(暴露 Prometheus 端点):yamlserver: port: 8080 management: endpoints: web: exposure: include: health,info,prometheus,metrics # 暴露核心端点 base-path: /actuator # 端点前缀,默认 /actuator metrics: tags: application: aa-app # 标记应用名称,方便多实例区分 export: prometheus: enabled: true # 开启 Prometheus 指标导出 endpoint: health: show-details: always # 健康检查显示详细信息 probes: enabled: true # 支持 Kubernetes 健康检查 -
验证端点:启动应用后访问
http://<服务器IP>:8080/actuator/prometheus,能看到大量 JVM 指标(如jvm_memory_used_bytes)即为成功。
步骤2:部署 Prometheus(采集指标)
-
下载 Prometheus:https://prometheus.io/download/(选择对应系统版本);
-
编写 Prometheus 配置文件
prometheus.yml:yamlglobal: scrape_interval: 15s # 采集间隔(生产建议 10s) evaluation_interval: 15s # 规则评估间隔 scrape_configs: # 采集 JVM 指标 - job_name: 'jvm-aa-app' metrics_path: '/actuator/prometheus' static_configs: - targets: ['<应用服务器IP>:8080'] # 替换为应用实际 IP:端口 # 标签追加,方便 Grafana 筛选 relabel_configs: - source_labels: [__address__] target_label: instance replacement: 'aa-app-01' # 实例名称,如 aa-app-01/aa-app-02 # 采集 Prometheus 自身指标(可选) - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] -
启动 Prometheus:
bash# 后台启动,指定配置文件 nohup ./prometheus --config.file=prometheus.yml --web.listen-address=:9090 > prometheus.log 2>&1 & -
验证采集:访问
http://<Prometheus IP>:9090/targets,查看jvm-aa-app状态为UP即为成功。
步骤3:部署 Grafana(可视化指标)
-
下载 Grafana:https://grafana.com/grafana/download(推荐安装 LTS 版本);
-
启动 Grafana(Linux 示例):
bash# 安装后启动 systemctl start grafana-server # 设置开机自启 systemctl enable grafana-server -
访问 Grafana:
http://<Grafana IP>:3000(默认账号/密码:admin/admin,首次登录需修改); -
添加 Prometheus 数据源:
- 左侧菜单 →
Connections→Data sources→Add data source→ 选择Prometheus; - 填写 Prometheus 地址(如
http://<Prometheus IP>:9090)→Save & test,提示「Data source is working」即为成功;
- 左侧菜单 →
-
导入 JVM 监控仪表盘:
- 左侧菜单 →
Dashboards→New→Import; - 输入官方推荐的 JVM 仪表盘 ID:
4701(Spring Boot 2.x JVM 监控)或8563(通用 JVM 监控)→Load; - 选择已添加的 Prometheus 数据源 →
Import,即可看到完整的 JVM 可视化面板(内存、GC、线程、CPU 等)。
- 左侧菜单 →
步骤4:配置 AlertManager(阈值告警)
-
编写告警规则文件
alert_rules.yml:yamlgroups: - name: jvm-alert-rules rules: # 堆内存使用率告警 - alert: JvmHeapMemoryHigh expr: jvm_memory_used_bytes{area="heap"} / jvm_memory_max_bytes{area="heap"} * 100 > 85 for: 5m # 持续 5 分钟触发告警 labels: severity: warning application: aa-app annotations: summary: "JVM 堆内存使用率过高" description: "实例 {{ $labels.instance }} 堆内存使用率 {{ $value | humanizePercentage }},超过 85% 阈值" # Full GC 频率告警 - alert: JvmFullGCFrequent expr: increase(jvm_gc_collection_seconds_count{gc="Full GC"}[1h]) > 1 for: 10m labels: severity: critical application: aa-app annotations: summary: "Full GC 频率过高" description: "实例 {{ $labels.instance }} 1 小时内 Full GC 次数 {{ $value }} 次,超过 1 次/小时阈值" -
在
prometheus.yml中引入告警规则:yamlrule_files: - "alert_rules.yml" alerting: alertmanagers: - static_configs: - targets: ['<AlertManager IP>:9093'] # AlertManager 地址 -
配置 AlertManager(对接钉钉/企业微信):
- 编写
alertmanager.yml,配置告警接收渠道(如钉钉机器人); - 启动 AlertManager:
./alertmanager --config.file=alertmanager.yml; - 验证:手动触发阈值(如堆内存使用率>85%),5 分钟后可收到钉钉告警。
- 编写
4.3 监控指标阈值:企业级告警标准(附调整依据)
以下阈值为通用行业标准,需根据业务特性调整(如低延迟业务需降低 GC 耗时阈值,大数据业务可放宽内存阈值):
| 监控指标 | 指标含义 | 正常范围 | 告警阈值(warning) | 严重告警阈值(critical) | 调整依据 |
|---|---|---|---|---|---|
| 堆内存使用率 | 已使用堆内存/最大堆内存 | < 70% | > 85%(持续5分钟) | > 95%(持续1分钟) | 低延迟业务可设为 80%/90%;批处理业务可放宽至 90%/98% |
| 老年代使用率 | 老年代已使用/老年代最大值 | < 70% | > 85%(持续5分钟) | > 95%(持续1分钟) | 老年代占比过高易触发 Full GC,需严格监控 |
| 元空间使用率 | 元空间已使用/元空间最大值 | < 70% | > 85%(持续5分钟) | > 95%(持续1分钟) | 元空间溢出会直接导致 OOM,建议阈值不超过 80% |
| Minor GC(YGC)频率 | 每分钟 YGC 次数 | < 1 次/分钟 | > 5 次/分钟(持续10分钟) | > 10 次/分钟(持续5分钟) | YGC 频繁说明新生代内存过小或对象创建过快 |
| Full GC(FGC)频率 | 每小时 FGC 次数 | < 1 次/天 | > 1 次/小时(持续10分钟) | > 5 次/小时(持续5分钟) | FGC 会导致应用卡顿,生产环境应尽量避免 |
| 单次 Full GC 耗时 | 单次 FGC 暂停时间 | < 100ms | > 200ms(单次) | > 500ms(单次) | 低延迟业务(如支付)需设为 <50ms/100ms/200ms |
| GC 总耗时占比 | GC 总耗时/应用运行总时间 | < 10% | > 20%(持续5分钟) | > 30%(持续1分钟) | 占比过高说明 GC 消耗过多资源,应用吞吐量下降 |
| 线程数 | 活跃线程总数 | 业务峰值的 80% 以内 | > 业务峰值 120% | > 业务峰值 150% | 需先压测确定业务峰值线程数,避免线程池耗尽 |
| 死锁线程数 | 检测到的死锁线程数 | 0 | ≥1(立即触发) | ≥5(立即触发) | 死锁会导致线程永久阻塞,需立即处理 |
4.4 高级监控配置(生产级安全&性能优化)
(1)JMX 远程监控(安全加固版)
JMX 可实现 JVM 实时监控,但生产环境必须严格配置认证和加密,避免安全漏洞:
① 完整 JVM 参数配置(启动脚本中添加)
bash
# JMX 基础配置
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=9090 # JMX 监听端口(仅内网开放)
-Dcom.sun.management.jmxremote.rmi.port=9091 # RMI 端口(必须与 jmxremote.port 一致或单独配置)
-Djava.rmi.server.hostname=<服务器内网IP> # 指定 RMI 绑定的 IP,避免绑定 0.0.0.0
# 安全配置(生产必须开启)
-Dcom.sun.management.jmxremote.authenticate=true # 开启密码认证
-Dcom.sun.management.jmxremote.ssl=true # 开启 SSL 加密
-Dcom.sun.management.jmxremote.ssl.need.client.auth=false # 无需客户端证书(按需调整)
-Dcom.sun.management.jmxremote.password.file=/etc/jmx/jmx.password # 密码文件路径
-Dcom.sun.management.jmxremote.access.file=/etc/jmx/jmx.access # 权限文件路径
# 防暴力破解(可选)
-Dcom.sun.management.jmxremote.login.config=jmxremote # 自定义登录配置② 配置密码&权限文件(核心安全步骤)
-
创建 JMX 配置目录(仅 root 可读写):
bashmkdir -p /etc/jmx chmod 700 /etc/jmx # 仅属主可访问 -
编写权限文件
jmx.access:# 格式:用户名 权限(readonly/readonly + readwrite) monitorRole readonly # 只读用户(用于监控) controlRole readwrite # 读写用户(仅运维人员使用) -
编写密码文件
jmx.password:# 格式:用户名 密码(建议使用强密码) monitorRole Monitor@123456 controlRole Control@789012 -
设置文件权限(关键!否则 JVM 启动失败):
bashchmod 600 /etc/jmx/jmx.password # 仅属主可读写 chmod 644 /etc/jmx/jmx.access chown root:root /etc/jmx/* # 仅 root 用户可修改 -
防火墙配置:仅允许监控服务器 IP 访问 9090/9091 端口(以 iptables 为例):
bashiptables -A INPUT -p tcp --dport 9090 -s <监控服务器IP> -j ACCEPT iptables -A INPUT -p tcp --dport 9091 -s <监控服务器IP> -j ACCEPT iptables -A INPUT -p tcp --dport 9090 -j DROP iptables -A INPUT -p tcp --dport 9091 -j DROP
③ 客户端连接(以 JVisualVM 为例)
- 打开 JVisualVM →
远程→添加远程主机→ 输入服务器内网 IP; - 右键远程主机 →
添加 JMX 连接→ 输入端口 9090; - 勾选「使用安全连接 (SSL)」→ 输入用户名/密码(如 monitorRole/Monitor@123456)→ 连接成功。
(2)Prometheus + Grafana 监控进阶优化
① 指标标签优化(方便多实例/多环境管理)
在 application.yml 中添加环境/集群标签:
yaml
management:
metrics:
tags:
application: aa-app
env: prod # 环境:prod/test/dev
cluster: cluster-01 # 集群名称② 自定义 JVM 指标(补充默认指标不足)
编写配置类,添加业务相关 JVM 指标:
java
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryPoolMXBean;
@Configuration
public class CustomJvmMetricsConfig {
@Autowired
private MeterRegistry meterRegistry;
@PostConstruct
public void registerCustomMetrics() {
// 监控 Eden 区使用率
ManagementFactory.getMemoryPoolMXBeans().stream()
.filter(bean -> bean.getName().contains("Eden"))
.forEach(bean -> {
meterRegistry.gauge("jvm_eden_used_bytes", bean, MemoryPoolMXBean::getUsage, u -> u.getUsed());
meterRegistry.gauge("jvm_eden_max_bytes", bean, MemoryPoolMXBean::getUsage, u -> u.getMax());
});
}
}③ Grafana 面板优化
- 自定义变量:添加
application/env/cluster变量,支持一键筛选不同实例; - 告警可视化:在面板中添加「告警状态」卡片,直观展示当前告警;
- 数据归档:配置 Grafana 数据来源为 Mimir(Prometheus 集群版),实现指标长期存储(如 1 年)。
(3)APM 工具监控(SkyWalking/Arthas):生产级在线诊断
① SkyWalking(全链路追踪+JVM监控)
SkyWalking 是开源 APM 工具,支持「分布式追踪+JVM 监控+应用性能分析」一体化,适合微服务架构。
完整部署步骤:
-
部署 SkyWalking OAP 服务(后端)和 UI:
- 下载地址:https://skywalking.apache.org/downloads/
- 启动 OAP:
./bin/oapService.sh start - 启动 UI:
./bin/webappService.sh start(访问http://<OAP IP>:8080);
-
应用集成 SkyWalking Agent(启动脚本中添加):
bash# SkyWalking Agent 核心参数 SKYWALKING_AGENT_OPTS="\ -javaagent:/opt/skywalking/agent/skywalking-agent.jar \ -Dskywalking.agent.service_name=aa-app \ -Dskywalking.collector.backend_service=<OAP IP>:11800 \ -Dskywalking.logging.level=INFO \ -Dskywalking.agent.instance_name=aa-app-01" # 实例名称 # 启动应用(整合原有 JVM 参数) nohup java $SKYWALKING_AGENT_OPTS $JVM_OPTS -jar aa.jar > app.log 2>&1 & -
查看监控:
- SkyWalking UI →
JVM 监控:查看堆内存、GC、线程、CPU 等指标; 链路追踪:定位慢请求对应的 JVM 资源消耗(如慢请求触发大量 YGC);告警:配置 JVM 阈值告警,对接钉钉/邮件。
- SkyWalking UI →
② Arthas(阿里开源在线诊断工具)
Arthas 无需修改代码、无需重启应用,可在线排查 JVM 问题,适合生产环境紧急故障定位。
核心使用场景&命令:
-
安装启动:
bash# 下载 Arthas curl -O https://arthas.aliyun.com/arthas-boot.jar # 启动并选择要诊断的进程(输入进程 ID 回车) java -jar arthas-boot.jar -
常用诊断命令(生产高频):
- 查看 JVM 信息:
dashboard(实时面板,显示内存、线程、GC、CPU 等); - 查看 GC 情况:
gc(打印详细 GC 统计); - 线程诊断:
thread:查看线程总数、状态;thread -b:定位阻塞其他线程的死锁线程;thread <线程ID>:查看线程堆栈;
- 内存诊断:
heapdump /tmp/arthas-heap.hprof:在线生成堆转储文件(无需 OOM);jvm:查看完整 JVM 参数、内存配置;
- 方法耗时分析:
trace com.xxx.service.UserService queryUser:追踪方法调用链路和耗时;monitor -c 5 com.xxx.service.UserService queryUser:每 5 秒监控方法执行次数/成功率/耗时;
- 热更新代码(紧急修复):
redefine /tmp/UserService.class(替换类文件,无需重启)。
- 查看 JVM 信息:
生产使用建议:
- 仅在故障排查时启动 Arthas,排查完成后立即退出(
stop),避免占用资源; - 禁止在生产环境使用
redefine热更新核心业务类(风险高),仅用于紧急修复配置类/工具类; - 开启 Arthas 日志:
logger set root INFO,记录诊断过程,便于后续复盘。
可视化小结
- 可视化工具选择:离线分析内存泄漏用 MAT,实时监控+多维度分析用 JProfiler,企业级集群监控用 Prometheus+Grafana;
- 告警阈值核心:通用阈值需结合业务调整(低延迟业务更严格),告警需设置「持续时间」避免误报;
- 高级监控配置:JMX 必须开启认证+SSL,Prometheus 需优化标签和自定义指标,APM 工具(SkyWalking/Arthas)是生产故障排查的核心手段;
- 生产避坑:实时监控工具(JProfiler/Arthas)仅在排查问题时使用,避免长期占用服务器资源;所有远程监控端口仅开放内网访问,防止安全漏洞。
五、故障排查:常见问题的定位与解决
即使做好了参数配置和运行时监控,应用在生产环境中仍可能出现故障。本节针对三大常见问题给出标准化排查流程。
5.1 内存溢出(OutOfMemoryError)
内存溢出核心分为「堆内存溢出」「元空间溢出」「堆外内存溢出」三种。
(1)堆内存溢出(Java heap space)
排查流程:
- 获取堆转储文件 :从配置的
HeapDumpPath下载或手动生成。 - 使用 MAT 分析:查看「Leak Suspects」报告和「Dominator Tree」。
- 定位根因:区分是「内存泄漏」还是「内存配置不足」。
- 解决方案:修复代码清理无用引用,或增大堆内存。
(2)元空间溢出(Metaspace)
排查流程:
- 监控元空间使用率 :
jstat -gcutil查看M字段。 - 定位根因:类频繁加载或元空间配置不足。
- 解决方案 :缓存动态代理类或增大
-XX:MaxMetaspaceSize。
(3)堆外内存溢出(Direct buffer memory)
排查流程:
- 查看代码 :确认是否大量使用
ByteBuffer.allocateDirect()。 - 监控堆外内存 :通过 JProfiler 或
jmap -heap。 - 解决方案 :手动释放堆外内存或增大
-XX:MaxDirectMemorySize。

5.2 GC 频繁卡顿
排查流程:
- 获取 GC 日志:从配置的日志目录下载。
- 分析 GC 日志:使用 GCViewer 或 GCEasy 等工具。
- 定位根因:Minor GC 频繁、Full GC 频繁或单次 GC 耗时过长。
- 解决方案:调整新生代/老年代大小、修复内存泄漏、替换 GC 器。

5.3 线程死锁
排查流程:
- 获取线程堆栈 :
jstack -l <pid> > thread.log。 - 分析堆栈文件 :查找
Found one Java-level deadlock关键字。 - 定位根因:锁顺序不当、锁未释放或锁持有时间过长。
- 解决方案:统一锁顺序、在 finally 块中释放锁、减少锁持有时间。

5.4 CPU 100%
排查流程:
top找到高CPU的Java进程;ps -mp <PID> -o THREAD找到高CPU线程;- 线程ID转16进制(
printf "%x\n" <TID>); jstack <PID> | grep <16进制TID>查看线程堆栈;- 定位死循环/频繁GC/锁竞争代码。
bash
# 1. 找到CPU高的Java进程
top -c
# 记录PID
# 2. 找到CPU高的线程
ps -mp <pid> -o THREAD,tid,time | sort -rn | head -10
# 3. 将线程ID转为16进制
printf "%x\n" <tid>
# 4. 查看线程堆栈
jstack <pid> | grep -A20 -B5 "nid=0x<hex>"
# 5. 分析代码问题(常见原因):
# - 死循环
# - 频繁GC
# - 锁竞争
# - 无限递归
5.5 内存泄漏排查
bash
# 1. 观察内存增长
jstat -gcutil <pid> 1000 10
# 2. 生成堆转储
jmap -dump:live,format=b,file=heap.hprof <pid>
# 3. 使用MAT分析(下载Memory Analyzer Tool)
# - 打开heap.hprof
# - 查看Leak Suspects报告
# - 查看Dominator Tree找到大对象
# 4. 或者使用命令行初步分析
jmap -histo:live <pid> | head -205.6 应用启动失败
bash
# 1. 查看启动日志
tail -100 /logs/app_*.log
# 2. 常见启动问题:
# - 端口占用:netstat -tlnp | grep :8080
# - 内存不足:java -Xmx4g(调整内存)
# - 类冲突:NoSuchMethodError/ClassNotFoundException
# - 配置错误:application.yml语法错误
# 3. 使用verbose参数诊断
java -verbose:class -jar app.jar 2>&1 | grep -i "error"
java -XX:+PrintFlagsFinal -version | grep -i heap六、性能调优:从稳定运行到高效运行
JVM 性能调优是一个「循序渐进、反复验证」的过程,核心遵循「监控 -> 分析 -> 调优 -> 验证」的闭环流程。
6.1 调优原则
- 先优化代码,再调优JVM(代码优化收益远高于参数调优);
- 单一变量原则(每次仅调整一个参数,便于验证效果);
- 压测验证(用JMeter/Gatling对比调优前后指标);
- 不追求极致调优(平衡吞吐量与延迟)。
6.2 核心调优方向
(1)内存调优
- 合理配置堆内存大小。
- 优化新生代与老年代比例。
- 优化元空间与堆外内存配置。
- 减少内存碎片(使用 G1/ZGC)。
(2)GC 调优
- 选择合适的 GC 器 :
- 堆内存 < 4GB:Serial/Parallel GC。
- 堆内存 4~16GB:G1 GC。
- 堆内存 > 16GB:ZGC/Shenandoah GC。
- 优化 GC 器参数。
- 减少 Full GC 触发。
(3)代码调优
- 减少临时对象创建 :使用
StringBuilder,复用对象,使用基本类型。 - 优化锁使用:减少锁持有时间,优先使用非阻塞锁。
- 优化集合使用:选择合适集合,设置初始容量,及时清理。
- 优化 I/O 操作:优先使用 NIO,使用堆外内存,关闭无用流。
(4)服务器调优
- 增加 CPU 核心数。
- 增大物理内存。
- 使用 SSD 磁盘。
- 关闭无用进程。
6.3 调优闭环
- 监控:收集JVM性能数据(GC频率、内存使用率、响应时间);
- 分析:定位性能瓶颈(如Minor GC频繁);
- 调优:调整参数/优化代码(如增大新生代);
- 验证:压测对比调优前后指标;
- 迭代:未达目标则重复上述步骤。

七、自动化运维:长期稳定保障体系
生产环境长期稳定依赖自动化运维,减少人工干预,提升故障响应效率。
7.1 日志管理规范
- 日志切割:使用
logrotate自动切割日志,避免单个文件过大; - 日志分级:生产环境仅输出INFO/WARN/ERROR,减少日志量;
- 日志存储:ELK栈统一收集日志,便于检索和分析。
7.2 自动化预警
- 核心预警指标:堆内存>90%、Full GC>1次/小时、GC耗时>200ms;
- 预警渠道:钉钉/企业微信(实时)、邮件(归档)、短信(紧急);
- 预警工具:Prometheus AlertManager/自研Shell脚本。
7.3 应用进程管理
- Systemd配置:将应用注册为系统服务,实现开机自启/异常重启;
- 部署示例(
/etc/systemd/system/myapp.service):
ini
[Unit]
Description=My Java Application
After=network.target
[Service]
Type=simple
User=appuser
WorkingDirectory=/data/apps/myapp
ExecStart=/data/scripts/start-aa.sh
ExecStop=/data/scripts/stop-aa.sh
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target
7.4 Docker化部署
dockerfile
# Dockerfile
FROM openjdk:11-jre-slim
# 基础配置
RUN groupadd -r appuser && useradd -r -g appuser appuser
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
RUN mkdir -p /app /logs && chown -R appuser:appuser /app /logs
# 复制应用
WORKDIR /app
COPY target/aa.jar app.jar
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
# 环境变量
ENV JAVA_OPTS="-Xms2g -Xmx2g -XX:+UseG1GC"
ENV SPRING_PROFILES_ACTIVE="prod"
# 健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8080/actuator/health || exit 1
# 启动应用
USER appuser
EXPOSE 8080
ENTRYPOINT ["/entrypoint.sh"]
八、生产环境最佳实践
8.1 部署清单
- 服务器资源充足(CPU、内存、磁盘)
- JDK版本符合要求(LTS版本)
- 防火墙配置正确(开放必要端口)
- 日志目录有足够权限
- 备份旧版本和数据
- 准备好回滚方案
8.2 启动顺序
bash
# 1. 上传JAR包和配置
scp app.jar user@server:/data/apps/
scp config/ user@server:/data/configs/
# 2. 停止旧服务
ssh user@server "systemctl stop myapp"
# 3. 备份旧版本
ssh user@server "cp /data/apps/app.jar /data/backup/app_$(date +%Y%m%d).jar"
# 4. 启动新服务
ssh user@server "/opt/scripts/deploy_prod.sh"
# 5. 健康检查
curl -f http://server:8080/actuator/health
curl http://server:8080/actuator/info
# 6. 流量切换(如有负载均衡)
# 在LB上逐步将流量切换到新实例3. 集成 systemd(Linux 服务管理)
让应用像 Nginx 一样被系统管理:
(1)创建服务文件 /etc/systemd/system/myapp.service
ini
[Unit]
Description=MyApp Service
After=network.target
[Service]
Type=simple
User=myapp
WorkingDirectory=/opt/apps
ExecStart=/opt/apps/start.sh
ExecStop=/opt/apps/stop.sh
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target(2)启用并启动服务
bash
# 重载 systemd 配置
sudo systemctl daemon-reload
# 开机自启
sudo systemctl enable myapp
# 启动服务
sudo systemctl start myapp
# 查看状态
sudo systemctl status myapp
# 查看日志
sudo journalctl -u myapp -f🌟 好处:
- 自动重启崩溃进程;
- 统一日志管理;
- 标准化启停命令。
4. Docker部署方案
dockerfile
# Dockerfile
FROM openjdk:11-jre-slim
# 创建非root用户
RUN groupadd -r appuser && useradd -r -g appuser appuser
# 设置时区
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 创建目录
RUN mkdir -p /app /logs
WORKDIR /app
# 复制JAR包
COPY target/app.jar app.jar
COPY entrypoint.sh /entrypoint.sh
# 设置权限
RUN chown -R appuser:appuser /app /logs
RUN chmod +x /entrypoint.sh
USER appuser
# JVM参数(可通过环境变量覆盖)
ENV JAVA_OPTS="-Xms512m -Xmx512m -XX:+UseG1GC"
ENV SPRING_PROFILES_ACTIVE="prod"
# 健康检查
HEALTHCHECK --interval=30s --timeout=3s --start-period=60s --retries=3 \
CMD curl -f http://localhost:8080/actuator/health || exit 1
EXPOSE 8080
ENTRYPOINT ["/entrypoint.sh"]
bash
# entrypoint.sh
#!/bin/bash
set -e
# 允许通过环境变量覆盖JVM参数
JAVA_OPTS=${JAVA_OPTS:-"-Xms512m -Xmx512m"}
# 启动应用
exec java ${JAVA_OPTS} \
-Djava.security.egd=file:/dev/./urandom \
-Dspring.profiles.active=${SPRING_PROFILES_ACTIVE} \
-jar app.jar "$@"构建和运行:
bash
# 构建镜像
docker build -t myapp:1.0.0 .
# 运行容器
docker run -d \
--name myapp \
-p 8080:8080 \
-v /data/logs/myapp:/logs \
-e JAVA_OPTS="-Xms2g -Xmx2g" \
-e SPRING_PROFILES_ACTIVE="prod" \
--memory="4g" \
--cpus="2" \
myapp:1.0.0
# 查看日志
docker logs -f myapp九、监控告警与日志管理
1. 监控告警配置
创建告警脚本 check_health.sh:
bash
#!/bin/bash
APP_URL="http://localhost:8080/actuator/health"
PID_FILE="/var/run/myapp.pid"
# 检查1:进程是否存在
if [ ! -f "${PID_FILE}" ]; then
echo "CRITICAL: PID文件不存在"
exit 2
fi
PID=$(cat "${PID_FILE}")
if ! ps -p ${PID} > /dev/null; then
echo "CRITICAL: 进程不存在"
exit 2
fi
# 检查2:端口是否监听
if ! netstat -tln | grep ":8080 " > /dev/null; then
echo "CRITICAL: 端口未监听"
exit 2
fi
# 检查3:健康检查接口
HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" -m 5 "${APP_URL}")
if [ "${HTTP_CODE}" != "200" ]; then
echo "CRITICAL: 健康检查失败 HTTP ${HTTP_CODE}"
exit 2
fi
# 检查4:GC是否频繁(最近1分钟Full GC次数)
if [ -f "/logs/gc.log" ]; then
FULL_GC_COUNT=$(tail -1000 /logs/gc.log | grep "Full GC" | wc -l)
if [ ${FULL_GC_COUNT} -gt 3 ]; then
echo "WARNING: 频繁Full GC"
exit 1
fi
fi
echo "OK: 应用正常"
exit 0
# 配置cron定时检查
*/2 * * * * /opt/scripts/check_health.sh >> /var/log/health_check.log 2>&12. 日志管理规范
bash
# 日志切割配置(logrotate)
# /etc/logrotate.d/myapp
/data/logs/myapp/*.log {
daily
rotate 30
compress
delaycompress
missingok
notifempty
create 644 appuser appuser
postrotate
# 发送信号给应用重新打开日志文件
kill -USR1 $(cat /var/run/myapp.pid) 2>/dev/null || true
endscript
}
# 日志级别配置(Spring Boot示例)
# application-prod.yml
logging:
level:
root: WARN
com.myapp: INFO
org.springframework.web: WARN
org.hibernate: ERROR
file:
path: /data/logs/myapp
max-size: 100MB
max-history: 30
logback:
rollingpolicy:
max-file-size: 100MB
total-size-cap: 10GB十、上线 Checklist(必备!)
在每次上线前,逐项确认:
- 堆内存已显式设置(
-Xms = -Xmx) - GC 日志已开启并轮转
- OOM 堆转储路径可写
- 时区、编码等系统属性已配置
- 启动脚本支持平滑启停
- systemd 服务已配置(或等效进程管理)
- 监控告警已覆盖关键指标
- 压测验证 GC 表现符合预期
📌 黄金法则 :
没有监控的上线 = 盲目上线。

十一、常见陷阱与避坑指南
❌ 陷阱1:在容器中不设置内存限制
- 现象:JVM 读取宿主机内存,但容器只分配 4GB → OOMKill。
- 解决 :使用
-XX:MaxRAMPercentage=75.0。
❌ 陷阱2:GC 日志写入根分区
- 现象 :GC 日志撑爆
/分区,导致系统瘫痪。 - 解决 :日志必须写入独立挂载的大容量分区(如
/data/logs)。
❌ 陷阱3:忽略元空间溢出
- 现象 :应用运行一周后突然
Metaspace OOM。 - 解决 :设置
-XX:MaxMetaspaceSize=256m(避免无限增长)。
❌ 陷阱4:频繁 Full GC 未告警
- 现象:用户反馈"系统变慢",但无人发现是 GC 问题。
- 解决 :监控
jstat中的FGC字段,设置阈值告警。

十二、结语:从"能跑"到"跑得稳"
java -jar 是起点,但绝不是终点。
真正的生产级部署,是一套包含参数配置、日志诊断、进程管理、监控告警的完整体系。
当你为应用加上 -Xmx4g、开启 GC 日志、配置 systemd 服务、设置 OOM 告警的那一刻------你已经从"能跑就行"的初级阶段,迈入了"稳定可靠"的专业领域。
"优秀的工程师,不仅让程序跑起来,更让它跑得稳、看得清、修得快。"

下一次,当你部署一个 JAR 包时,请记住:
你配置的每一个 JVM 参数,都是对线上用户的一份承诺。
附录:完整启动命令示例(G1 + 监控 + 安全)
bash
java \
-server \
-Xms4g \
-Xmx4g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:G1HeapRegionSize=16m \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/data/dumps/ \
-Xlog:gc*:file=/data/logs/gc.log:time,tags:filecount=5,filesize=100M \
-XX:MaxMetaspaceSize=256m \
-Dfile.encoding=UTF-8 \
-Duser.timezone=Asia/Shanghai \
-jar myapp.jar互动话题 :
你在生产环境中踩过哪些 JVM 部署的坑?是如何解决的?欢迎在评论区分享你的"血泪教训"!