ArrayList、LinkedList与Vector的区别?
这三个都是List接口的主要实现,
- ArrayList底层实现是数组,当超过原有大小的时候会按照原长度的1.5倍进行扩容,查询性能比较高
- LinkedList底层实现是双向链表,理论上可以无限长度,再增加和删除的场景中性能比较好,但是查询性能不高
- Vector底层实现和ArrayList类似,但是是线程安全的,原因就是里面的大部分方法都使用了synchronized进行修饰,此外就是扩容机制也不同,它是按照2倍进行扩容的
然后要注意LinkedList其实还实现了Deque(其内部又继承了Queue),所以比较全能一点,方法比较多
在使用上一般就是查找较多的场景以ArrayList为主,修改较多的场景通过LinkedList,而Vector是比较早期的,现阶段一般用JUC包下的集合进行替代
对ArrayList的扩容机制了解吗?
了解,在进行初始化的时候如果指定了合法的大小就是按照指定的大小创建数组,否则就是按照默认,默认大小是10
java
private static final int DEFAULT_CAPACITY = 10;然后扩容的机制就是在执行add的时候,判断到当前个数已经等于当前数组的长度,就会触发扩容,扩容就是按原来的1.5倍进行扩容
java
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}扩容的具体逻辑就是先申请一个1.5倍大小的数组,将原数组进行复制,然后再将旧引用指向成新数组
java
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}ArrayList的subList方法有什么需要注意的地方吗?
subList() 方法其实就是用来对指定范围内的元素进行截取映射出来
java
public class Main {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>(1);
for (int i = 0; i < 100; i ++) list.add(i);
List<Integer> subList = list.subList(2, 7);
subList.add(1);
System.out.println(subList); // [2, 3, 4, 5, 6, 1]
}
}但是需要注意的就是底层其实并没有创建一个新的ArrayList,而是直接创建一个内部的SubList对象,可以理解为就是创建了一个视图出来
SubList 是ArrayList的一个内部类,不能转化成ArrayList或是其它的,否则报错
java
private static class SubList<E> extends AbstractList<E> implements RandomAccess {
private final ArrayList<E> root;
private final SubList<E> parent;
private final int offset;
private int size;
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList<>(this, fromIndex, toIndex);
}
}结构化修改:新增/删除元素
非结构化修改:不改变数量,只改变原有元素的值
三个指标:
- 无论是对原来的ArrayList集合或是你subList进行非结构化修改,都会影响到另外一个
- 对subList进行结构化修改是可以的,且会影响到原来的ArrayList,但是反过来对原来的ArrayList进行结构化修改就不行,会直接报错
此外就是你对subList视图进行结构化修改会映射到原来的ArrayList,但是对原来的ArrayList修改则会报错
java
public class Main {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>(1);
for (int i = 0; i < 100; i ++) list.add(i);
List<Integer> subList = list.subList(2, 7);
subList.remove(1);
// 可以发现3没了
System.out.println(subList); // [2, 4, 5, 6]
System.out.println(list); // [0, 1, 2, 4, 5, 6, 7, 8, 9, 10......]
}
}
java
public class Main {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>(1);
for (int i = 0; i < 100; i ++) list.add(i);
List<Integer> subList = list.subList(2, 7);
list.add(1);
System.out.println(subList);
}
}
Exception in thread "main" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1415)
at java.base/java.util.ArrayList$SubList.listIterator(ArrayList.java:1284)如果指向修改SubList,但是不想改变原有的list的话,就只能对SubList进行拷贝一份新的再去操作
结论:需要注意的地方主要是,SubList是ArrayList的一个内部类,调用subList()方法时其实是创建了一个SubList对象给我们,底层并没有创建新的ArrayList对象,而是直接复用,可以理解为给我们开了一个新的视图,但是要注意无论是对这个视图还是原来的ArrayList对象进行非结构化操作(不改变元素数量,只改变原有的值)或是对subList进行结构化操作(修改元素数量)都会影响到彼此,而对原来的ArrayList进行结构化操作会直接报错
注意:是视图,不是副本
ArrayList的序列化是怎么实现的?
首先ArrayList其实是一个动态Object数组,并且实现了Serializable接口,如果是按照这个来看似乎是直接使用jdk默认的序列化机制,但是实际上不是
java
transient Object[] elementData; // non-private to simplify nested class access可以看到它的这个动态数组其实是被transient修饰了,这个关键字的作用就是忽略序列化,也就是有这个关键字,jdk的默认序列化方式就不会去序列化这个字段
此外,ArrayList重写了Object的writeObject()和readObject(),这两个方法就是Object默认序列化和反序列化时调用的方法,ArrayList重写之后做了自己的序列化和反序列化逻辑
java
@java.io.Serial
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
@java.io.Serial
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// like clone(), allocate array based upon size not capacity
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
// Read in all elements in the proper order.
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}那有一个问题:为什么ArrayList要大费周章的把这个元素数组标识成transient,然后自己控制序列化和反序列化的过程?
答案就是为了适配ArrayList的扩容机制,或者说ArrayList数组是不是每次申请的时候都是往大了申请,然后写满之后再申请更大的,然后数组又是声明为Object类型,那么没写的空间就直接为null,要是使用默认序列化方式,假设数组大小是100,但是真实元素只有1个,这时候不就序列化了99个null,所以它自己控制序列化和反序列化的时候就是按照这个真实元素个数来进行序列化,避免造成资源浪费
总结一下:ArrayList的序列化方式就是先把真实存储数据的数组声明成transient,然后自己重写序列化和反序列化方法实现对序列化流程的控制,序列化和反序列化的时候只处理真正的元素,而不是整个数组
ConcurrentHashMap是如何保证fail-safe的?
这两种方式是并发过程中解决问题的策略
- fail-safe:安全失败,迭代的时候遇到修改操作不会抛出异常,而是返回一个快照版本,可能会导致拿到的快照和实际有一定的不一致,例如ConcurrentHashMap
- fail-fast:快速失败,迭代的时候遇到修改操作会直接抛出异常,例如ArrayList
那接下来我们就探讨一下ConcurrentHashMap是如何实现安全失败的,主要是两个角度
- 移除来了HashMap的modCount比较,不会出现说modCount和期望的值不同的时候出现报错的情况
- 此外就是table数组被volatile修饰了,并且当执行修改操作的时候底层是通过synchronized + CAS进行修改的,也就是说当执行put或是remove操作的时候首先会获取一份最新的table数据,然后在自己的线程私有内存中进行修改,修改完成就同步到主内存,然后因为加了volatile,所以当它发生修改时,正在读取的线程也能获取到最新的数据
特点:可能读取到修改前的数据,也可能读取到修改后的数据,但是不会读取到修改一半的数据
还有一个比较特殊的场景:要是是遍历的时候刚好遇到扩容呢?
遍历的时候如果遇到扩容,ConcurrentHashMap会在扩容之后桶如果发生迁移会用特殊的节点ForwardingNode进行标记
java
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null);
this.nextTable = tab;
}
}它里面会记录新数组的位置,然后跳转到新数组进行遍历
遍历的具体逻辑
java
final Node<K,V> advance() {
Node<K,V> e;
if ((e = next) != null)
e = e.next;
for (;;) {
Node<K,V>[] t; int i, n; // must use locals in checks
if (e != null)
return next = e;
if (baseIndex >= baseLimit || (t = tab) == null ||
(n = t.length) <= (i = index) || i < 0)
return next = null;
if ((e = tabAt(t, i)) != null && e.hash < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
e = null;
pushState(t, i, n);
continue;
}
else if (e instanceof TreeBin)
e = ((TreeBin<K,V>)e).first;
else
e = null;
}
if (stack != null)
recoverState(n);
else if ((index = i + baseSize) >= n)
index = ++baseIndex; // visit upper slots if present
}
}ConcurrentHashMap是如何保证线程安全的?
要回答这个问题得看jdk的版本,
如果是jdk1.7的话,存储结构是数组+链表,主要使用的Segment分段锁技术
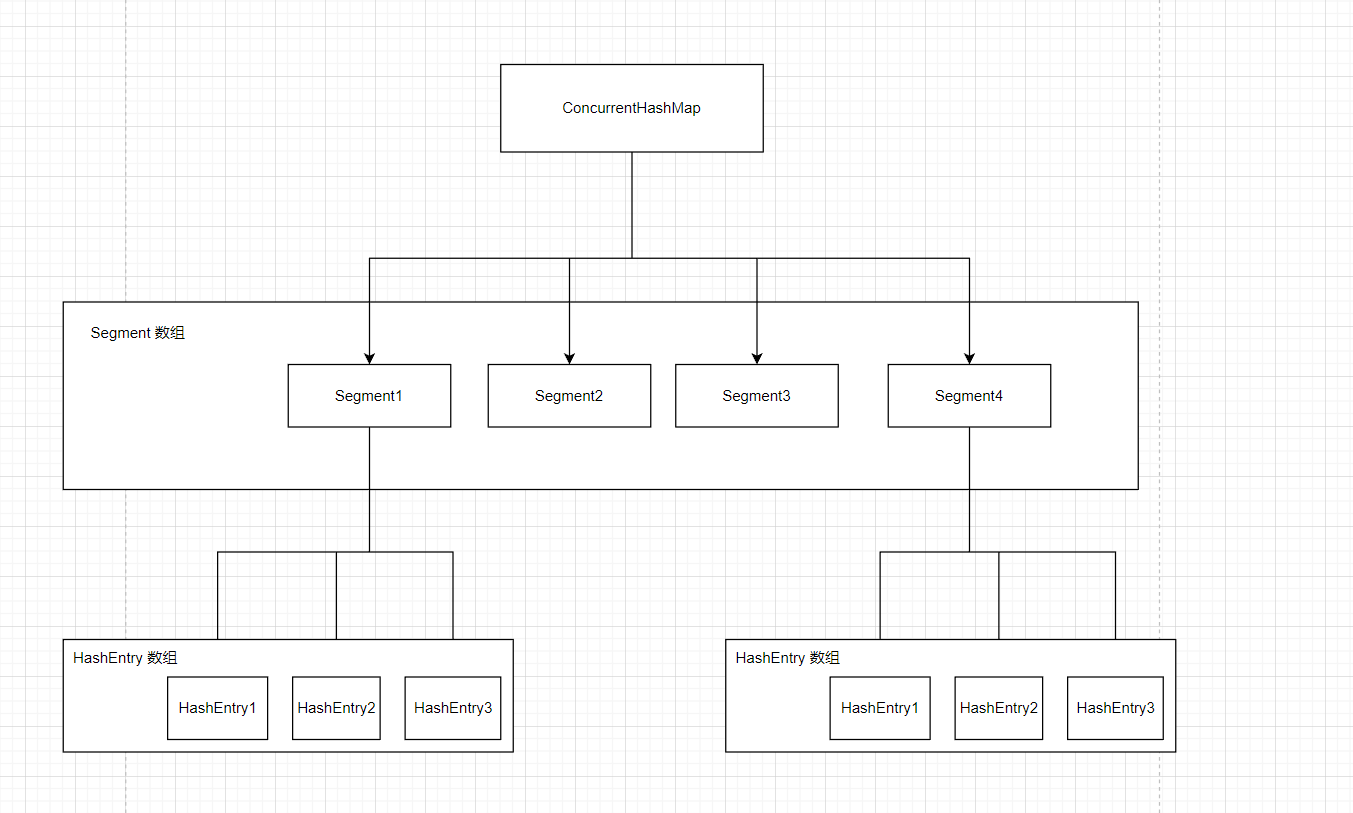
这里的HashEntry就是一个一个的槽,每个槽存的就是一条链表(因为哈希冲突使用拉链法),然后引进了Segment的概念,就是规定哪几个元素或是那一段元素属于哪一个Segment,就这样一个数组分成好几段,每一段都用一个Segment进行管理,然后每次锁的时候就是锁一个Segment,也就是锁一小段
jdk8开始就改了,首先是存储结构变成了数组+链表+红黑树,同时也去掉了Segment的概念,直接对着每一个hash槽进行操作
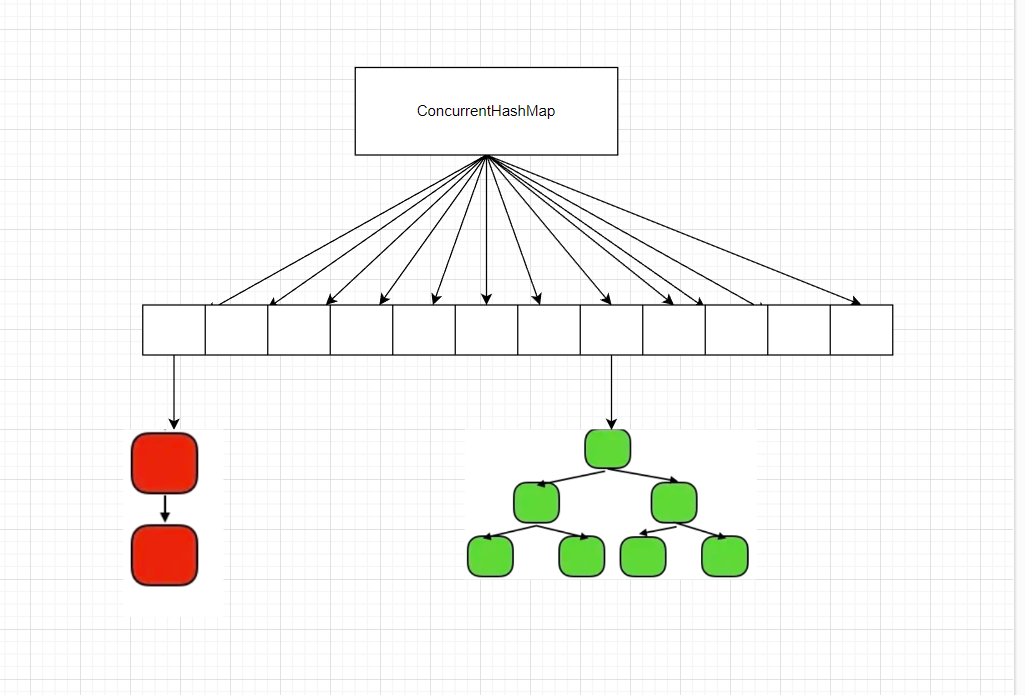
由于现在改成要操作的时候直接操作哪一个槽就锁哪一个,所以性能会大大提升,并发度也大大提高
然后它锁的实现就是使用CAS+synchronized,具体什么时候用哪一种是分情况的
可以看源码:
首先就是执行put操作的时候
java
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}具体的逻辑可以总结一下:
首先就是看一下ConcurrentHashMap数组(容器)是否为null,
- 如果为null的话就使用tab = initTable();去进行初始化
- 不为null就根据要put的key计算出来的hash值去找对应的槽,判断槽中是否已经有数据
-
- 没有数据就说明当前操作的竞争不是很高,使用CAS去添加
- 有数据说明竞争比较激烈,使用synchronized去进行添加,添加的过程就是遍历整个槽位的链表,判断执行新增操作或覆盖操作;最后就是判断一下是否要进行转化成红黑数,转换的条件就是链表长度已经大于等于8且hash槽个数已经大于等于64个
还有一点要补充的:上面其实大家都看到当(fh = f.hash) == MOVED时说明这一个槽位正在扩容中,会调用helpTransfer() 方法协助扩容操作
CAS的具体逻辑
java
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetReference(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
public final native boolean compareAndSetReference(Object o, long offset,
Object expected,
Object x);其实进去会发现是一个native本地方法,这一块更多是系统底层来帮我们实现
cas其实可以认为就是一个循环,它不加锁,但是会不断的进行比较,有点像你要买一件衣服,然后钱不够,你就可以不停的问店员降价了吗,直到降价到钱够买的时候就买下
缺点就是需要多次比较,且失败率会比较高
ConcurrentHashMap为什么在JDK1.8中废弃分段锁?
说白了就是jdk7的分段锁粒度还是太大了,分段锁说白了不就是锁着一个哈希表(小哈希表)吗,那可能有一种情况就是这一个哈希表里面就只有一个元素热点比较高,那它会导致这一段一直锁着,造成其他同段节点没法处理
所以jdk8直接把锁的粒度减少到哈希槽级别的,就是每次只锁一个槽,最多就这个槽的链表上其他节点没办法操作,粒度大大降低
此外jdk8中对synchronized进行了底层的优化,让它在性能上不输ReentrantLock,且是自动释放的更加安全,可以说synchronized+CAS的性能和安全性都要更好
所以总结一下更换的原因,主要是从锁粒度以及性能和安全性出发考虑的最终结果
ConcurrentHashMap为什么在JDK1.8中使用synchronized而不是ReentrantLock?
首先就是synchronized早在jdk1.6中就已经被优化了,不再是简单的锁全部,而是有升级的过程,其实看源码也可以看到因为已经分成多个槽位,所以并发压力并不高,锁升级也不会很频繁,性能和ReentrantLock差不多
此外就是synchronized能自动释放资源并且不需要唤醒等操作,实现起来也是比较方便清晰
而且synchronized的内存占用是比ReentrantLock低的
这几点放在并发编程里面再进行解释