通用表表达式(CTE)非常适合清理代码。但递归 CTE 是完全不同的野兽。它们允许你在 CTE 自己的定义中引用 CTE 本身。
这听起来像是无限循环的领域(确实可能!),但一旦驯服,它就能解锁超能力,例如:
- 遍历组织图(谁向谁报告?)
- 生成日历日期以填补报告空白
- 在图数据中查找路径(航班连接、网络路由)
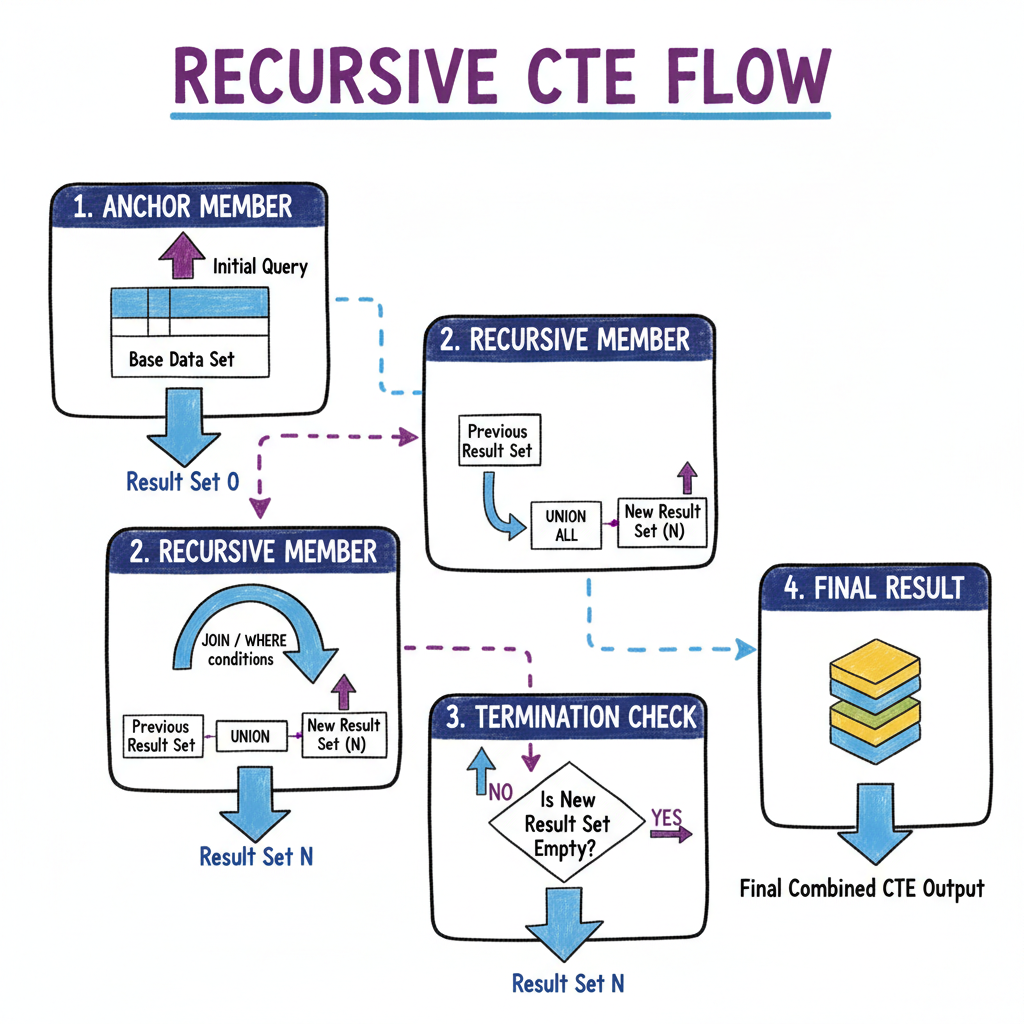
递归 CTE 流程图:展示从锚点成员到递归成员再到终止条件的完整流程
WITH RECURSIVE 的解剖
递归 CTE 始终包含三个部分:
- 锚点成员(Anchor Member):起点(非递归)
- 递归成员(Recursive Member):引用 CTE 名称的查询
- 终止条件(Termination Condition) :最终停止递归的
WHERE子句
基础语法示例:
sql
WITH RECURSIVE my_cte AS (
-- 1. 锚点成员
SELECT 1 AS n
UNION ALL
-- 2. 递归成员
SELECT n + 1
FROM my_cte
WHERE n < 10 -- 3. 终止条件
)
SELECT * FROM my_cte;查询结果:
| n |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
工作原理:
- 初始化 :锚点成员返回
n = 1 - 第一次迭代 :递归成员从
n = 1生成n = 2 - 第二次迭代 :从
n = 2生成n = 3 - 继续迭代 :直到
n = 10 - 终止 :当
n = 10时,WHERE n < 10不再满足,递归停止
用例 1:生成数据
有时你需要每个月的每一天都有一行,即使你的交易表缺少某些日期。递归 CTE 是在 PostgreSQL 和 SQLite 中执行此操作的标准方法。
示例:生成 2025 年 1 月的所有日期
sql
WITH RECURSIVE date_series AS (
-- 起始日期
SELECT '2025-01-01' AS seq_date
UNION ALL
-- 递归添加 1 天
SELECT DATE(seq_date, '+1 day')
FROM date_series
WHERE seq_date < '2025-01-31'
)
SELECT * FROM date_series;查询结果(部分显示):
| seq_date |
|---|
| 2025-01-01 |
| 2025-01-02 |
| 2025-01-03 |
| ... |
| 2025-01-29 |
| 2025-01-30 |
| 2025-01-31 |
实际应用场景:
- 填补报告空白:即使某些日期没有交易,也能显示完整的日期范围
- 时间序列分析:生成连续的时间点用于趋势分析
- 日历生成:创建日历表用于数据仓库
跨数据库支持:
| 数据库 | 日期递增语法 |
|---|---|
| SQLite | DATE(seq_date, '+1 day') |
| PostgreSQL | seq_date + INTERVAL '1 day' |
| MySQL | DATE_ADD(seq_date, INTERVAL 1 DAY) |
| SQL Server | DATEADD(day, 1, seq_date) |
用例 2:遍历层级结构(组织图)
这是经典的教科书示例。想象一个 employees 表,其中每个员工都有一个 manager_id。如何找到每个人的完整指挥链?
示例数据:employees 表
| id | name | manager_id |
|---|---|---|
| 1 | Big Boss | NULL |
| 2 | VP Sales | 1 |
| 3 | VP Eng | 1 |
| 4 | Sales Rep | 2 |
| 5 | Engineer | 3 |
递归查询:构建组织层级
sql
WITH RECURSIVE hierarchy AS (
-- 锚点:找到 CEO(没有经理的人)
SELECT
id,
name,
manager_id,
0 as level,
name as path
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归:找到直接下属
SELECT
e.id,
e.name,
e.manager_id,
h.level + 1,
h.path || ' > ' || e.name
FROM employees e
JOIN hierarchy h ON e.manager_id = h.id
)
SELECT * FROM hierarchy
ORDER BY level, name;查询结果:
| id | name | manager_id | level | path |
|---|---|---|---|---|
| 1 | Big Boss | NULL | 0 | Big Boss |
| 2 | VP Sales | 1 | 1 | Big Boss > VP Sales |
| 3 | VP Eng | 1 | 1 | Big Boss > VP Eng |
| 5 | Engineer | 3 | 2 | Big Boss > VP Eng > Engineer |
| 4 | Sales Rep | 2 | 2 | Big Boss > VP Sales > Sales Rep |
工作原理详解:
- 验证锚点 :找到 "Big Boss"(
manager_id IS NULL)。Level = 0 - 第一次迭代:将 "Big Boss"(ID 1)与他的直接下属(VP Sales, VP Eng)连接。Level = 1
- 第二次迭代:找到 VP 的下属(Engineer, Sales Rep)。Level = 2
- 停止:当没有更多员工可以连接时,递归停止
关键字段说明:
- level:员工在组织中的层级(0 = CEO,1 = VP,2 = 普通员工)
- path:从 CEO 到当前员工的完整路径,便于理解汇报关系
实际应用场景:
- 组织图可视化:生成公司的完整组织结构
- 权限管理:确定用户的管理范围
- 成本中心分析:计算每个部门的总人数和成本
- 职业发展路径:显示员工的晋升路径
避免的陷阱
无限循环
如果你忘记 WHERE 子句或你的逻辑创建了一个循环(A 管理 B,B 管理 A),查询将永远运行(或直到数据库终止它)。
危险示例(无终止条件):
sql
WITH RECURSIVE infinite AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1 FROM infinite -- 没有 WHERE 子句!
)
SELECT * FROM infinite;安全提示:你可以严格限制深度作为故障保护:
sql
WHERE n < 100 -- 硬性限制或者使用 level 限制:
sql
WHERE h.level < 10 -- 限制最大层级深度检测循环的方法:
sql
WITH RECURSIVE hierarchy AS (
SELECT
id,
name,
manager_id,
0 as level,
CAST(id AS TEXT) as id_path -- 记录访问过的 ID
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT
e.id,
e.name,
e.manager_id,
h.level + 1,
h.id_path || ',' || CAST(e.id AS TEXT)
FROM employees e
JOIN hierarchy h ON e.manager_id = h.id
WHERE h.id_path NOT LIKE '%' || CAST(e.id AS TEXT) || '%' -- 检测循环
AND h.level < 100 -- 安全限制
)
SELECT * FROM hierarchy;大型树的性能
递归 CTE 通常逐行或逐级处理。对于大规模图(数百万个节点),专门的图数据库可能更快。但对于大多数标准业务层级结构,它运行得非常完美。
性能优化建议:
- 添加索引:
sql
CREATE INDEX idx_employees_manager ON employees(manager_id);- 限制递归深度:
sql
WHERE level < 20 -- 大多数组织不会超过 20 层- 使用物化视图(对于静态层级):
sql
CREATE MATERIALIZED VIEW org_hierarchy AS
WITH RECURSIVE hierarchy AS (...)
SELECT * FROM hierarchy;- 分批处理:对于非常大的层级结构,考虑按部门分批处理
性能对比:
| 节点数 | 递归 CTE | 应用层循环 | 图数据库 |
|---|---|---|---|
| < 1,000 | 优秀 | 良好 | 过度设计 |
| 1,000 - 10,000 | 良好 | 较慢 | 良好 |
| 10,000 - 100,000 | 可接受 | 很慢 | 优秀 |
| > 100,000 | 较慢 | 不可行 | 优秀 |
更多实际应用场景
1. 生成斐波那契数列
sql
WITH RECURSIVE fibonacci AS (
SELECT 0 AS n, 0 AS fib, 1 AS next_fib
UNION ALL
SELECT
n + 1,
next_fib,
fib + next_fib
FROM fibonacci
WHERE n < 10
)
SELECT n, fib FROM fibonacci;2. 查找文件系统路径
sql
WITH RECURSIVE file_tree AS (
-- 根目录
SELECT id, name, parent_id, name as full_path
FROM files
WHERE parent_id IS NULL
UNION ALL
-- 子目录和文件
SELECT
f.id,
f.name,
f.parent_id,
ft.full_path || '/' || f.name
FROM files f
JOIN file_tree ft ON f.parent_id = ft.id
)
SELECT * FROM file_tree;3. 计算累计总和
sql
WITH RECURSIVE running_total AS (
-- 第一行
SELECT
date,
amount,
amount as cumulative,
1 as row_num
FROM transactions
ORDER BY date
LIMIT 1
UNION ALL
-- 累加后续行
SELECT
t.date,
t.amount,
rt.cumulative + t.amount,
rt.row_num + 1
FROM transactions t
JOIN running_total rt ON t.date > rt.date
WHERE rt.row_num = (SELECT MAX(row_num) FROM running_total)
LIMIT 1
)
SELECT * FROM running_total;4. 查找图中的所有路径
sql
WITH RECURSIVE paths AS (
-- 起点
SELECT
id as start_node,
id as current_node,
CAST(id AS TEXT) as path
FROM nodes
WHERE id = 1 -- 从节点 1 开始
UNION ALL
-- 遍历边
SELECT
p.start_node,
e.to_node,
p.path || ' -> ' || CAST(e.to_node AS TEXT)
FROM paths p
JOIN edges e ON p.current_node = e.from_node
WHERE p.path NOT LIKE '%' || CAST(e.to_node AS TEXT) || '%' -- 避免循环
)
SELECT * FROM paths;跨数据库支持
| 数据库 | 递归 CTE 支持 | 语法差异 |
|---|---|---|
| PostgreSQL | ✅ 完全支持 | WITH RECURSIVE |
| SQLite | ✅ 完全支持 | WITH RECURSIVE |
| MySQL 8.0+ | ✅ 完全支持 | WITH RECURSIVE |
| SQL Server | ✅ 完全支持 | WITH ... AS (不需要 RECURSIVE 关键字) |
| Oracle 11g+ | ✅ 完全支持 | WITH ... AS (不需要 RECURSIVE 关键字) |
| MariaDB 10.2+ | ✅ 完全支持 | WITH RECURSIVE |
SQL Server 示例(不需要 RECURSIVE 关键字):
sql
WITH hierarchy AS (
SELECT id, name, manager_id, 0 as level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id, h.level + 1
FROM employees e
JOIN hierarchy h ON e.manager_id = h.id
)
SELECT * FROM hierarchy;最佳实践
1. 始终包含终止条件
sql
-- ✅ 正确
WHERE level < 100
-- ❌ 错误(可能无限循环)
-- 没有 WHERE 子句2. 使用有意义的列名
sql
-- ✅ 正确
SELECT
id,
name,
level,
path
-- ❌ 不清晰
SELECT
c1,
c2,
c3,
c43. 添加注释说明逻辑
sql
WITH RECURSIVE hierarchy AS (
-- 锚点:找到根节点
SELECT ...
UNION ALL
-- 递归:遍历子节点
SELECT ...
WHERE level < 10 -- 限制深度防止无限循环
)4. 考虑性能影响
- 对大型数据集使用索引
- 限制递归深度
- 对于静态数据考虑物化视图
5. 测试边界情况
- 空表(没有根节点)
- 单节点树
- 循环引用
- 非常深的层级
结论
WITH RECURSIVE 是将 SQL 用户与 SQL 大师区分开来的功能之一。它将复杂的应用层逻辑(循环和树)转化为单个优雅的数据库查询。
关键要点:
- 递归 CTE 由三部分组成:锚点、递归和终止条件
- 适用于层级数据、日期序列、图遍历等场景
- 始终包含终止条件以避免无限循环
- 对于大型数据集,考虑性能优化
- 跨数据库支持良好,但语法略有差异
何时使用递归 CTE:
- ✅ 遍历组织图或层级结构
- ✅ 生成连续的日期或数字序列
- ✅ 查找图中的路径
- ✅ 计算累计值
- ❌ 简单的聚合(使用 GROUP BY)
- ❌ 超大规模图(考虑图数据库)
掌握递归 CTE,你就能用 SQL 解决以前需要应用层代码才能解决的复杂问题!
相关文章推荐
- Mastering CTEs: Writing Cleaner, Better SQL
- The Power of SQL LATERAL Joins (and CROSS APPLY)
- Solving the Gaps and Islands Problem in SQL
本文转载自 www.hisqlboy.com
原文标题:Mastering Recursive CTEs: The Inception of SQL
原文链接:https://www.hisqlboy.com/blog/mastering-recursive-ctes
原作者:SQL Boy Team
转载日期:2026-02-16