一、分布式 ID 核心需求
1. ID 本身要求
- 全局唯一性:最基础要求,分布式场景下绝对不能重复
- 有序性:趋势递增 / 单调递增,保证数据库 B + 树索引写入性能
- 信息安全:部分场景(如订单 ID)要求无规则,防止竞对推算业务数据
- 存储友好:长度适中,适配数据库主键设计(MySQL 推荐短主键)
2. 生成系统要求
- 高性能:平均延迟、TP999 延迟极低,支撑高 QPS
- 高可用:可用性达到 5 个 9(99.999%),核心业务强依赖
- 可扩展:支持集群部署,水平扩容无瓶颈
二、分布式 ID 常见实现方案
2.1 UUID
核心信息
- 标准格式:32 个 16 进制数,分 5 段(8-4-4-4-12),共 36 字符,示例:
550e8400-e29b-41d4-a716-446655440000 - Java 实现:JDK 自带
java.util.UUID,可通过replaceAll("-", "")去除中划线
优缺点
| 优点 | 缺点 |
|---|---|
| 本地生成,无网络消耗,性能极高 | 16 字节 128 位,存储 / 传输成本高 |
| 实现简单,无需依赖中间件 | 基于 MAC 地址的算法可能泄露 MAC |
| - | 无序性:MySQL InnoDB 聚集索引下,频繁引起数据页分裂,严重影响写入性能 |
| - | 不符合 MySQL 官方短主键建议 |
面试常问
Q:为什么分布式场景下不推荐 UUID 作为数据库主键?
A:①UUID 过长,违反 MySQL 短主键设计原则;②无序性导致 InnoDB B + 树索引频繁分裂,写入性能急剧下降;③部分算法存在 MAC 地址泄露风险。
2.2 雪花算法(Snowflake)
Twitter 开源的 64 位分布式 ID 生成算法,是分布式 ID 的核心考察点。
核心结构(64 位 Long 型)
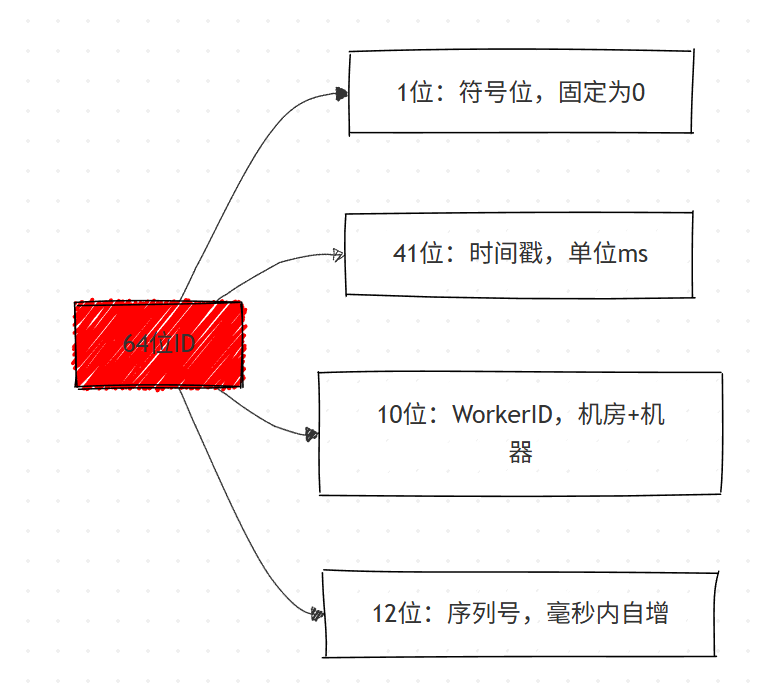
字段详解
- 1 位符号位:固定为 0,标识正数,无实际意义
- 41 位时间戳 :可支撑
2^41毫秒(约 69 年),需指定起始时间戳(epoch) - 10 位 WorkerID:默认分 5 位机房 ID+5 位机器 ID,支持 32 个机房 ×32 台机器 = 1024 个节点
- 12 位序列号 :毫秒内自增,最大值
2^12-1=4095,单机器单毫秒最多生成 4096 个 ID
性能指标
理论 QPS:1000毫秒 × 4096个/毫秒 = 409.6w/s,满足绝大多数高并发场景
优缺点
| 优点 | 缺点 |
|---|---|
| 趋势递增,适配数据库索引写入 | 强依赖机器时钟,时钟回拨会导致 ID 重复 / 服务不可用 |
| 本地生成,性能高,无中间件依赖 | 需手动维护 WorkerID,集群扩容时配置成本高 |
| 可自定义 bit 位分配,适配业务场景 | 无内置容灾,节点故障需手动处理 |
| 64 位 Long 型,存储友好 | - |
衍生实现
- 美团 Leaf-snowflake
- 百度 UidGenerator(2018 年后停止维护)
- Seata 内置
io.seata.common.util.IdWorker
面试常问
Q1:雪花算法时钟回拨问题如何解决?
A:①启动时校验节点时间,与集群平均时间对比,偏移超阈值则启动失败;②运行时检测时钟回拨,小偏移(如≤5ms)等待时钟追上,大偏移直接返回异常;③本机缓存 WorkerID,弱依赖注册中心;④时钟回拨时触发报警,自动摘除异常节点。
Q2:雪花算法的 WorkerID 如何分配?
A:①小型集群:手动配置;②大型集群:基于 Zookeeper 持久顺序节点自动生成,节点启动时注册 ZK 并获取唯一顺序号作为 WorkerID。
Q3:为什么雪花算法是趋势递增 而非单调递增?
A:不同机器的时钟存在微小偏差,跨机器的 ID 可能出现时间戳逆序,因此整体是趋势递增,单机器内是单调递增。
2.3 数据库生成方案
基础方案(单库单表)
-
建表语句:创建自增主键表,
stub字段为占位符CREATE TABLE
sequence_id(
idbigint(20) unsigned NOT NULL AUTO_INCREMENT,
stubchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (id),
UNIQUE KEYstub(stub)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -
获取 ID:通过
REPLACE INTO+LAST_INSERT_ID()实现原子获取BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
优化方案(Flickr 方案)
- 核心思路:多机部署,每台机器设置不同初始值 + 相同步长(步长 = 机器数)
- 示例:2 台机器,步长 = 2,机器 1 初始值 = 1(1,3,5...),机器 2 初始值 = 2(2,4,6...)
优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单,依赖 DBA 专业维护 | 单库存在单点问题,集群扩容复杂度高 |
| ID 单调递增,存储友好 | 并发量低,每次获取 ID 需访问数据库,压力大 |
| 无额外中间件依赖 | ID 无业务含义,连续 ID 存在信息泄露风险 |
| - | 水平扩容复杂,机器数变更需重新配置初始值 / 步长 |
面试常问
Q:
REPLACE INTO和INSERT INTO的区别?为什么数据库生成 ID 用REPLACE INTO?A:
INSERT INTO遇主键 / 唯一索引冲突会报错;REPLACE INTO遇冲突会先删除原有记录,再插入新记录,保证原子性获取自增 ID,避免插入失败。
2.4 Redis 生成方案
核心原理
通过 Redis 的incr/incrby命令实现原子性的 ID 自增,天然支持分布式场景。
基础使用
127.0.0.1:6379> incr sequence_id_order # 订单ID自增
(integer) 1
127.0.0.1:6379> incrby sequence_id_user 100 # 批量生成,步长100
(integer) 101优化方案
- 高可用:部署 Redis Cluster,避免单点问题
- 高性能:结合 incrby 实现批量获取,减少网络请求
- 持久化:开启 RDB+AOF 混合持久化,降低数据丢失风险
优缺点
| 优点 | 缺点 |
|---|---|
| 性能高,支持高 QPS,原子性保证 | 持久化仍存在数据丢失风险,可能导致 ID 重复 |
| ID 有序递增,适配数据库索引 | 依赖 Redis 中间件,增加系统复杂度 |
| 支持批量生成,灵活配置步长 | 需处理 Redis 集群的主从同步延迟问题 |
面试常问
Q:Redis 生成 ID 时,持久化导致的数据丢失会引发什么问题?如何缓解?
A:Redis 宕机重启后,若持久化数据未同步,incr 命令会从初始值重新开始,导致 ID 重复。缓解方案:①开启 RDB+AOF 混合持久化,降低数据丢失概率;②结合本地缓存,批量获取 ID 并缓存,减少 Redis 访问;③使用 Redis Cluster 的主从复制 + 哨兵模式,提高可用性。
三、美团 Leaf 分布式 ID 框架
Leaf 是美团开源的分布式 ID 生成框架,结合数据库号段 和雪花算法 实现,解决了传统方案的痛点,是面试中企业实战场景的高频考点。
3.1 Leaf 核心设计理念
名称源自莱布尼茨名言:There are no two identical leaves in the world (世界上没有两片相同的树叶),核心目标:高性能、高可用、可扩展、适配多业务场景。
3.2 Leaf-segment(数据库号段方案)
对传统数据库方案的核心优化:批量获取 ID,减少数据库访问。
核心原理

数据库表设计
| 字段名 | 类型 | 长度 | 说明 |
|---|---|---|---|
| biz_tag | varchar | 128 | 业务标识,隔离不同业务的 ID 生成 |
| max_id | bigint | - | 该业务当前分配的号段最大值 |
| step | int | - | 每次分配的号段长度 |
| description | varchar | 256 | 业务描述 |
| update_time | timestamp | - | 号段更新时间 |
号段获取流程
- 业务服务向 Leaf 服务请求 ID
- Leaf 服务从本地号段缓存中分配 ID
- 当号段消耗完时,执行 SQL 更新号段:
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx - 重新查询新号段并加载到本地缓存
双 Buffer 优化(解决 TP999 波动问题)
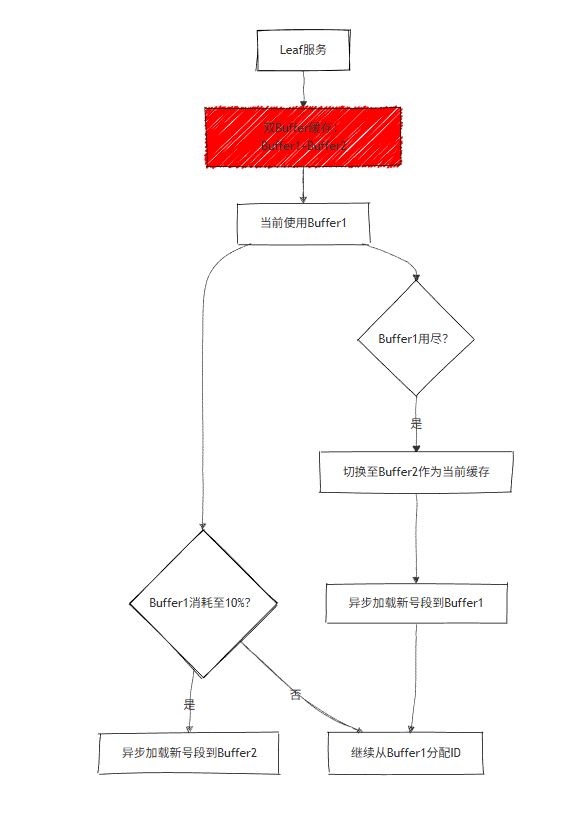
- 核心思路:当当前号段消耗至10% 时,异步加载下一个号段到备用 Buffer
- 解决问题:避免号段用尽时同步访问数据库导致的线程阻塞,降低 TP999 延迟
- 推荐配置:号段长度 = 服务高峰期 QPS×600(支撑 10 分钟无数据库访问)
高可用容灾
- 数据库部署:一主两从 + 分机房部署,主从半同步复制
- 中间件:使用 Atlas/DBProxy 实现主从自动切换
- 强一致方案:MySQL Group Replication(类 Paxos 算法),运维成本较高
优缺点
| 优点 | 缺点 |
|---|---|
| 线性扩展,性能支撑大多数业务 | ID 号段连续,存在信息泄露风险,不适用于订单 ID |
| 本地缓存号段,DB 宕机仍能短时间提供服务 | TP999 仍存在微小波动(号段切换时) |
| 支持自定义 max_id,便于业务迁移 | 依赖数据库,数据库完全宕机后无法获取新号段 |
| 按 biz_tag 隔离业务,无相互影响 | - |
3.3 Leaf-snowflake(雪花算法方案)
基于原生雪花算法优化,解决WorkerID 自动分配 和时钟回拨 问题,适用于ID 无规则的场景(如订单 ID)。
核心优化点
- WorkerID 自动分配:基于 Zookeeper 持久顺序节点,节点启动时自动注册并获取唯一 WorkerID
- 弱依赖 Zookeeper:本机文件系统缓存 WorkerID,ZK 宕机时仍能启动服务
- 时钟回拨解决:启动时校验集群时间、运行时检测时钟偏移、小偏移等待、大偏移返回异常并报警
- 集群时间同步:节点定期上报时间到 ZK,运行时对比集群平均时间
启动流程

3.4 Leaf 性能指标
- 机器配置:4C8G
- 压测 QPS:近 5 万 /s
- TP999 延迟:1ms
- 日常调用:每天亿数量级,支撑美团金融、支付、外卖、猫眼等核心业务
四、电商项目实战:tulingmall-unqid(基于 Leaf 改造)
4.1 改造背景
电商系统无 Zookeeper 部署,且无需考虑 ID 信息安全,因此移除 Leaf-snowflake 模块,仅保留 Leaf-segment 核心功能。
4.2 核心改造点:批量获取 ID
业务痛点
订单生成时,需同时生成订单主表 ID 和订单详情表多个 ID,若单次获取一个 ID,会增加网络请求,影响性能。
解决方案
新增批量获取 ID 接口,限定最大批量数为 5000,满足订单详情等批量插入场景。
核心接口(Java/SpringMVC)
// 原接口:单次获取一个ID
@RequestMapping(value = "/api/segment/get/{key}")
public String getSegmentId(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}
// 改造后新增:批量获取ID
@RequestMapping(value = "/api/segment/getlist/{key}")
public List<String> getSegmentIdList(@PathVariable("key") String key, @RequestParam int keyNumber) {
if(keyNumber==0 || keyNumber>5000) keyNumber=5000; // 限定最大5000
return getList(key,segmentService.getIds(key,keyNumber));
}4.3 服务特性
- 无状态服务,支持集群部署,水平扩容无瓶颈
- 基于 Leaf-segment 双 Buffer 优化,保证高性能
- 按业务 biz_tag 隔离,支持商品、订单、用户等多业务 ID 生成