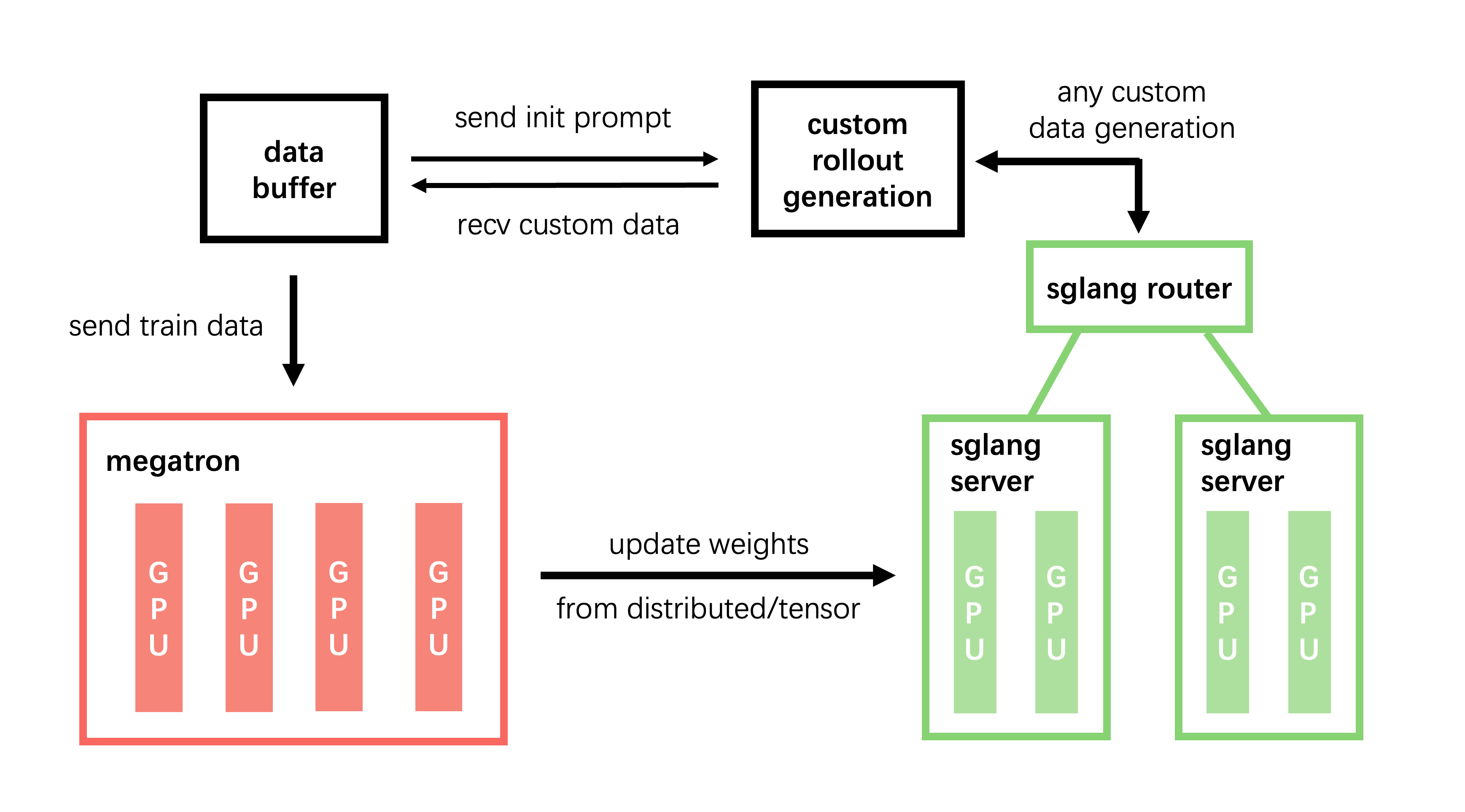
slime是一个专为强化学习(RL)扩展设计的LLM后训练框架,主要提供两个核心功能:高性能训练和灵活的数据生成。通过将Megatron与SGLang相连接,slime实现了高效的多种训练模式以及自定义数据生成接口和基于服务器的引擎。
高性能训练
slime具有出色的训练能力,可针对多个模型进行高效的训练。作为背后的RL框架,slime已为多个模型提供支持,包括:
- GLM-4.7
- GLM-4.6
- GLM-4.5
- Qwen系列(Qwen3Next,Qwen3MoE,Qwen3,Qwen2.5)
- DeepSeek系列(DeepSeek V3,V3.1,DeepSeek R1)
- Llama 3
这些模型的高效训练使得开发者能够更快地实验和迭代,从而加速模型的优化和改进。
灵活的数据生成
slime允许用户设计各种数据生成工作流。通过自定义数据生成接口,开发者可以根据具体需求生成特定的训练数据,这对于提高模型的学习效果至关重要。使用slime,您可以将数据生成的灵活性与训练过程紧密结合,使得模型在适应不同任务时表现得更加出色。
快速入门
对于初学者和开发者,slime提供详尽的快速入门指南,涵盖环境配置、数据准备、训练启动以及关键代码分析。您可以在这里找到快速入门指南。还提供了许多使用案例的示例,帮助用户更好地理解和应用slime。
使用案例
以下是一些利用slime构建的显著项目,展示了其在研究和生产中的广泛应用:
⚛️ P1: 物理奥林匹克的强化学习
P1 是一系列开源物理推理模型,完全通过强化学习训练。P1利用slime作为后训练框架,介绍了一种多阶段的强化学习训练算法,通过自适应的学习调整和稳定化机制逐步提升推理能力,取得了开放源代码物理推理领域的突破性表现。
📈 RLVE: 使用自适应可验证环境扩展LM RL
RLVE 介绍了一种使用可验证环境的方法,该环境以程序生成方式生成问题,并提供可算法验证的奖励。通过在400个可验证环境中进行联合训练,RLVE使每个环境能够在训练过程中根据策略模型的能力动态调整问题难度分布。
⚡ TritonForge: 内核生成的代理RL训练框架
TritonForge 利用slime的SFT和RL能力训练LLM,自动生成优化的GPU内核。通过使用监督微调与强化学习的两阶段训练方法,TritonForge在将PyTorch操作转换为高性能Triton内核方面取得了显著成果。
🚀 APRIL: 通过活动部分回滚加速RL训练
APRIL 引入了一种系统级优化,完美地与slime集成,加速强化学习训练中的回滚生成阶段。通过主动管理部分完成请求,APRIL解决了通常占用90% RL训练时间的长尾生成瓶颈。
🏟️ qqr: 使用ArenaRL和MCP扩展开放式代理
qqr(又名hilichurl)是一个为slime设计的轻量级扩展,用于演化开放式代理。它实现了ArenaRL算法,通过基于锦标赛的相对排名策略(例如,种子单淘汰制、循环赛)来解决判别性崩溃问题,并无缝集成了模型上下文协议(MCP)。qqr借助slime的高吞吐训练能力,实现了在标准化、解耦的工具环境中对代理的可扩展、分布式演化。
这些项目展示了slime的多功能性------从训练代码生成模型到优化RL训练系统,使其成为研究和生产部署的强大基础。
参数解析
在slime中,参数分为三类:
- Megatron参数 :slime读取Megatron中的所有参数,您可以通过传递参数如
--tensor-model-parallel-size 2来配置Megatron。 - SGLang参数 :支持所有安装的SGLang参数,这些参数必须以
--sglang-开头。例如,--mem-fraction-static应作为--sglang-mem-fraction-static传递。 - slime特定参数 :可以参考slime/utils/arguments.py获取详细信息。
有关完整的使用说明,请参阅使用文档。
开发者指南
我们欢迎对slime的贡献!如果您有新的功能建议、性能调优或者用户体验反馈,请随时提交问题或合并请求。同时,可以使用 pre-commit 确保您提交的代码样式一致性:
bash
apt install pre-commit -y
pre-commit install
# 运行pre-commit以确保代码风格一致性
pre-commit run --all-files --show-diff-on-failure --color=always有关调试的提示,请查看调试指南。
同类项目比较
除了slime之外,还有其他类似的项目可供选择,例如:
- Ray RLlib:一个强大的分布式强化学习库,支持多种RL算法,进而帮助开发者轻松地构建和扩展RL应用。
- OpenAI Spinning Up:该项目为新手提供丰富的教育资源和实用的RL工具,适合那些希望迅速了解和实验强化学习的开发者。
- Stable Baselines:一种强化学习库,善于提供标准化的RL算法和训练工具,便于模型的快速开发与调试。
以上这些项目各具特色,在具体需求和使用场景中,可以根据使用者的背景、技术栈和项目目标来选择最适合的解决方案。