想象一个智能保安,不仅盯着大门,还能主动发现问题并通知你。Nagios 就是这样的 IT 基础设施监控系统,7x24 小时守护着你的服务器和服务!
📑 目录
- [Nagios 概述](#Nagios 概述)
- 名词解释(命令与概念)
- [Nagios 核心架构](#Nagios 核心架构)
- 插件系统详解
- [NRPE 远程监控](#NRPE 远程监控)
- 通知机制详解
- 完整配置示例
- 高级特性
- 故障排查
- 与同行监控软件对比及适用场景
- 总结与官方参考
🎯 Nagios 概述
什么是 Nagios?
Nagios 是一个开源的监控系统,用于监控 IT 基础设施的健康状态,包括服务器、网络设备、服务和应用程序。
为什么需要监控?
想象你在管理一个大型商场:
- 没有监控 = 等顾客投诉了才知道空调坏了
- 有监控 = 空调一有问题,保安马上通知你去修
Nagios 的核心价值
| 特性 | 说明 | 生活类比 |
|---|---|---|
| 主动监控 | 定期检查,不等出事 | 定期体检而非生病才去医院 |
| 集中管理 | 一个平台监控所有 | 一个控制室监控整个商场 |
| 灵活扩展 | 插件机制支持自定义 | 可以增加各种检测设备 |
| 多渠道通知 | 邮件/短信/电话 | 多种方式联系保安 |
| 历史数据 | 趋势分析和容量规划 | 商场客流量分析 |
为什么叫 Nagios? 名称来自 "Nagios Ain't Gonna Insist On Sainthood" 的缩写,寓意「不苛求完美、务实可用」的监控工具;也常被理解为「Network Analyzer for Generic Infrastructure and Operational Systems」的联想。
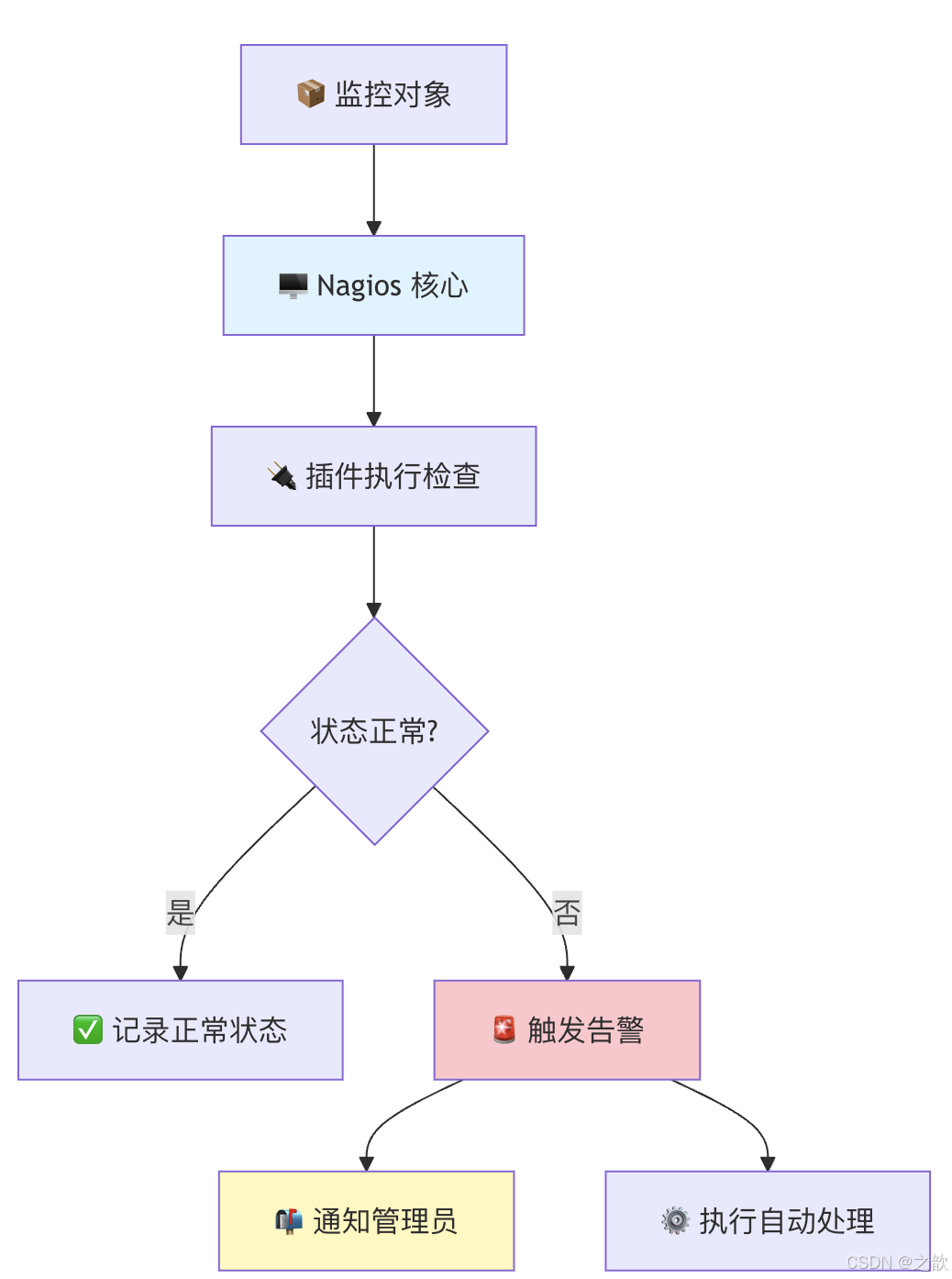
监控架构
🖥️ Nagios 监控架构
📦 被监控对象
📬 通知方式
📡 监控方式
🐧 Linux 服务器
🔄 Nagios Core
监控引擎
📌 本地监控
NRPE
🌐 远程监控
SNMP/SSH
📥 被动监控
NSCA
📧 邮件通知
📱 短信通知
🖼️ Web 界面
🪟 Windows 服务器
🔀 网络设备
📋 应用服务
🔌 插件库
Plugins
📖 名词解释(命令与概念)
以下对文档中出现的命令、配置项、对象类型 做简要解释,并配上生活例子与「为什么」,便于记忆与理解。官方对象定义见 Object Configuration Overview。
核心对象(官方用语)
| 名词 | 英文 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|---|
| Host | Host | 被监控的一台设备(服务器、交换机、打印机等),有地址,下挂多个 Service | 商场里的一栋楼,有门牌号,楼里有多个店铺 | 为什么先定义 Host?Service 必须挂在 Host 上,没有主机就没有「在这台机器上查什么」的归属 |
| Service | Service | 挂在该主机上的可检查项(如 CPU 负载、磁盘、HTTP 服务) | 楼里的每家店铺:水电、电梯、消防 | 为什么分 Host 和 Service?主机宕机时不必对每个服务都告警一遍,先报主机再按需报服务 |
| Command | Command | 定义「执行什么程序/脚本」做检查或发通知 | 保安手册里写明的「怎么查消防栓」「怎么打电话报修」 | 为什么单独定义?同一命令可被多台主机、多个服务复用;改一次全局生效 |
| Contact | Contact | 接收告警通知的人,有邮箱、手机等联系方式 | 值班经理、物业主任 | 为什么有 Contact Group?不同时段、不同主机组可通知不同的人,避免所有人被同一批告警轰炸 |
| Timeperiod | Time Period | 时间区间,用于「何时执行检查」「何时允许发通知」 | 营业时间、夜间时段、节假日 | 为什么需要?下班时间可能只通知值班;维护窗口内可以不告警或只发摘要 |
| Host Group / Service Group | Host Group / Service Group | 主机组、服务组,便于界面分组和批量配置 | 按楼层分的店铺组、按类型的设备组 | 为什么用组?Web 界面按组查看;配置时可用 hostgroup_name 一次给多台主机挂同一服务 |
检查与状态相关
| 名词 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| 主动检查 | Nagios 调度插件主动去查(如定期 ping、调 check_nrpe) | 保安每隔 5 分钟巡一次楼 | 为什么默认用主动?能统一调度、统一重试和状态判断;适合大多数可访问的设备 |
| 被动检查 | 外部程序把检查结果「提交」给 Nagios,Nagios 不主动执行插件 | 店铺自己上报「今日消防自查合格」 | 为什么需要被动?设备在防火墙后、或由外部系统(如应用)上报时,Nagios 无法主动连过去 |
| 软状态 / 硬状态 | 软状态:刚异常,未达重试次数;硬状态:连续多次异常,确认故障 | 软=第一次量体温偏高;硬=连续三次都高,确认发烧 | 为什么要有软状态?避免网络抖动、偶发超时就立刻告警,减少误报;max_check_attempts 控制几次后变硬 |
| max_check_attempts | 从异常到判定为硬状态所需的连续失败次数 | 量几次体温都高才叫发烧 | 为什么常设为 3?一次失败可能是偶发,多次仍失败才认为真有问题,平衡及时性与误报 |
| check_interval / retry_interval | 正常时多久查一次;异常时多久重试一次 | 平时每小时巡一次楼;发现问题时每 1 分钟再查一次 | 为什么 retry 更短?尽快确认是暂时故障还是持续故障,从而决定是否发通知 |
| 插件状态码 0/1/2/3 | OK / WARNING / CRITICAL / UNKNOWN,插件用退出码告诉 Nagios 结果 | 体检报告:正常/注意/异常/无法判断 | 为什么是 4 种?区分「正常」「需关注」「必须处理」「检查本身出错」四类,便于告警分级和静默 |
远程检查与插件
| 名词/命令 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| NRPE | Nagios Remote Plugin Executor,在远程 Linux 上执行插件并把结果回传 | 总部派巡检员到分店现场检查,而不是打电话问 | 为什么用 NRPE?很多指标只有在本机才能查(磁盘、负载、进程),NRPE 让远程机「本地执行、回传结果」 |
| check_nrpe | Nagios 端调用的插件,通过 NRPE 协议连到被监控机并执行指定命令名 | 总部给巡检员打电话:「去执行 check_disk」 | 为什么需要 -c?被监控机上可能定义多条 commandxxx,-c 指定执行哪一条(如 check_disk、check_load) |
| check_disk -w 20% -c 10% | 检查磁盘剩余空间;-w 警告线,-c 严重线 | 库存低于 20% 提醒补货,低于 10% 紧急 | 为什么用百分比?不同机器盘大小不同,百分比比固定 GB 更通用 |
| check_load -w 5,4,3 -c 10,8,6 | 检查 1/5/15 分钟平均负载;三组数字对应三个时间段 | 三个时段的工作量:偶尔高没事,持续高要处理 | 为什么看三个值?1 分钟反映瞬时,15 分钟反映趋势;同时设 -w/-c 便于区分「有点忙」和「过载」 |
通知相关
| 名词 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| notification_interval | 处于非 OK 状态时,每隔多久重复发一次通知 | 故障未解决时,每 30 分钟再提醒一次 | 为什么不能只发一次?可能漏看;重复提醒直到处理或恢复,避免遗忘 |
| notification_period | 允许发通知的时间段(由 Timeperiod 定义) | 只在工作时间打电话,深夜只发邮件 | 为什么限制?避免凌晨电话轰炸;不同时段用不同通知方式 |
| notification_options | 哪些状态变化会触发通知(d=down,u=unreachable,r=recovery 等) | 只在下行、不可达、恢复时通知,忽略 flapping | 为什么可配置?不同角色关心不同事件,减少无关告警 |
| Event Handler | 当服务/主机状态变化时自动执行的命令(如重启服务) | 发现火情先自动启动喷淋,再通知人 | 为什么有用?部分故障可自动恢复,减少人工介入;也可用于联动工单系统 |
相近概念对比(为什么容易混淆?)
| 对比项 | A | B | 区别一句话 | 何时用 A / 何时用 B |
|---|---|---|---|---|
| 主动检查 vs 被动检查 | 主动:Nagios 调插件去查 | 被动:外部提交结果给 Nagios | 谁发起:Nagios 发起 vs 外部发起 | 绝大多数用主动;设备在防火墙后或由应用上报时用被动 |
| Host 检查 vs Service 检查 | 主机是否「活着」(如 ping) | 主机上的某项服务/指标 | 主机级 vs 服务级 | 先有 Host 存活,再查其上的 Service;主机挂了可只报主机不刷屏服务 |
| 检查命令 vs 通知命令 | check_*:执行检测 | notify-*:发邮件/短信等 | 一个得到状态,一个把状态告诉人 | 检查命令在 check_command;通知命令在 contact 或模板的 notify-by-* |
| NRPE vs SNMP | 在远程执行插件(脚本) | 远程读 MIB 变量(标准协议) | 执行任意脚本 vs 读标准 OID | 需要磁盘、负载等复杂指标用 NRPE;纯网络设备、简单指标可用 SNMP |
| Nagios Core vs Nagios XI | 开源核心引擎,配置靠手写 | 商业版,Web 配置、报表、向导 | 免费手写配置 vs 付费图形化 | 学习、小规模用 Core;企业要省人力、要报表用 XI |
🏗️ Nagios 核心架构
核心组件详解
🖥️ Nagios Core
📄 配置文件
⏱️ 调度器
📬 通知系统
▶️ 插件执行器
🔌 检查插件
🖥️ 主机定义
📋 服务定义
⌨️ 命令定义
👤 联系人定义
📦 监控对象
核心组件说明
| 组件 | 英文 | 说明 | 配置文件 | 为什么重要? |
|---|---|---|---|---|
| 核心引擎 | Core | 调度和处理所有监控任务 | nagios.cfg | 为什么叫「核心」?Nagios 只做调度与状态机,不直接查磁盘或端口,所有「查」都交给插件 |
| 主机定义 | Host | 定义要监控的服务器 | hosts.cfg | 为什么先配主机?服务必须挂在主机上;主机 down 时可只发主机告警,减少刷屏 |
| 服务定义 | Service | 定义要监控的服务 | services.cfg | 为什么和主机分开?同一主机可有多个服务;可对服务设不同检查间隔、不同联系人 |
| 命令定义 | Command | 定义检查和通知命令 | commands.cfg | 为什么集中定义?多处复用;宏(如 H O S T A D D R E S S HOSTADDRESS HOSTADDRESS)由 Nagios 在运行时替换,便于模板化 |
| 联系人定义 | Contact | 定义接收通知的人 | contacts.cfg | 为什么有 contact_groups?不同主机/服务可通知不同组;夜间可只通知值班组 |
| 时间周期 | Timeperiod | 定义监控和通知时间 | timeperiods.cfg | 为什么分 check_period 和 notification_period?可以 24x7 检查但只在工作时间发通知,避免深夜电话 |
对象关系图
🖥️ Host
主机
📋 Service
服务
⌨️ Command
检查命令
👤 Contact
联系人
🕐 Timeperiod
时间周期
📂 Host Group
主机组
📂 Service Group
服务组
👥 Contact Group
联系人组
📬 Notification
通知命令
🔌 插件系统详解
为什么需要插件?
插件就像"专业检测工具",Nagios 本身不检查任何东西,它只是调用插件来检查,然后把结果展示和通知。
生活类比:
- Nagios = 医院调度中心
- 插件 = 各种检测设备(体温计、血压计、X光机)
- 你只需要决定什么时候用哪个设备检查
插件工作原理
- 调用插件 2. 执行检查 3. 返回结果 4. 返回状态码 5. 处理状态 0
1
2
3
🖥️ Nagios Core
🔌 检查插件
📦 监控对象
状态判断
✅ OK 正常
⚠️ WARNING 警告
🚨 CRITICAL 严重
❓ UNKNOWN 未知
状态码说明
| 状态码 | 状态名 | 颜色 | 含义 | 行动 | 为什么这样设计? |
|---|---|---|---|---|---|
| 0 | OK | 绿色 | 一切正常 | 无需行动 | 为什么 0 是正常?Unix 惯例:退出码 0 表示成功,非 0 表示异常;便于 shell 脚本判断 |
| 1 | WARNING | 黄色 | 有潜在问题 | 尽快查看 | 为什么单独 WARNING?可配置「只对 CRITICAL 打电话、WARNING 仅邮件」,分级告警 |
| 2 | CRITICAL | 红色 | 严重问题 | 立即处理 | 为什么 2 比 1 严重?数字越大越严重,便于排序和升级策略 |
| 3 | UNKNOWN | 灰色 | 无法判断 | 检查配置 | 为什么需要 UNKNOWN?插件超时、脚本报错、权限不足时不应误报为 CRITICAL,避免误处理 |
常用插件介绍
📋 服务插件
🔍 check_dns
DNS 服务
📧 check_smtp
邮件服务
🗄️ check_mysql
数据库
🔐 check_ssh
SSH 服务
🌐 网络插件
📡 check_ping
连通性
🔌 check_tcp
TCP 端口
📤 check_udp
UDP 端口
🌍 check_http
HTTP 服务
🖥️ 系统插件
💾 check_disk
磁盘空间
📊 check_load
CPU 负载
📋 check_procs
进程数量
👤 check_users
登录用户
插件使用示例
bash
# 1. check_disk - 检查磁盘空间
/usr/local/nagios/libexec/check_disk -w 20% -c 10%
# -w: 警告阈值(剩余小于20%)
# -c: 严重阈值(剩余小于10%)
# 为什么用百分比?不同机器盘大小不同,20% 对 100G 和 10T 都有一致语义
# 输出: DISK OK - free space: / 10240 MB (80% inode=99%);
# 2. check_load - 检查 CPU 负载
/usr/local/nagios/libexec/check_load -w 5,4,3 -c 10,8,6
# 为什么三个数?分别对应 1/5/15 分钟平均负载;多核机器可适当放大阈值
# 输出: OK - load average: 2.50, 2.20, 1.80
# 3. check_procs - 检查进程数量
/usr/local/nagios/libexec/check_procs -w 150 -c 200
# 为什么限制进程数?进程爆炸会拖垮系统;-s Z 可单独查僵尸进程
# 输出: PROCS OK: 125 processes
# 4. check_http - 检查 Web 服务
/usr/local/nagios/libexec/check_http -H www.example.com -w 5 -c 10
# -w: 响应时间警告阈值5秒 -c: 响应时间严重阈值10秒
# 为什么既看状态码又看时间?200 但慢到 10 秒也算故障体验
# 输出: HTTP OK: HTTP/1.1 200 OK - 1234 bytes in 0.452 second response time
# 5. check_mysql - 检查 MySQL
/usr/local/nagios/libexec/check_mysql -H localhost -u nagios -p password -d mydb
# 为什么用只读账号?nagios 只需 SELECT 查状态,最小权限原则
# 输出: Uptime: 123456 Threads: 10 Questions: 1234567 Slow queries: 12 Opens: 1234🔄 NRPE 远程监控
什么是 NRPE?
NRPE (Nagios Remote Plugin Executor) 允许 Nagios 在远程 Linux 服务器上执行插件,获取本地资源信息。
为什么需要 NRPE?
想象商场监控:
- SNMP = 通过电话问保安"店里情况怎样"
- NRPE = 派人到店里直接检查
NRPE 更直接,能获取更详细的本地信息。
NRPE 工作流程
🔧 Plugins 📡 NRPE Daemon 🔌 check_nrpe 🖥️ Nagios Server 🔧 Plugins 📡 NRPE Daemon 🔌 check_nrpe 🖥️ Nagios Server 1. 执行 check_nrpe 2. 连接端口 5666 3. 执行本地插件 4. 返回检查结果 5. 返回状态和输出 6. 返回给 Nagios 7. 处理告警/记录状态
为什么 NRPE 用固定端口 5666? 便于防火墙放行;NRPE 服务端只监听该端口,Nagios 端用 check_nrpe 连过去并指定要执行的命令名(-c),由被监控机本地执行插件后把退出码和输出回传。
NRPE 安装配置
服务端(被监控机器)安装
bash
# 1. 安装 NRPE 和插件
yum install nrpe nagios-plugins -y
# 或
apt install nrpe nagios-plugins -y
# 2. 配置 NRPE
vim /etc/nagios/nrpe.cfg
# 关键配置项:
# 允许的监控服务器 IP(只接受这些 IP 的连接,为什么?安全:避免任意机器执行本机命令)
allowed_hosts=127.0.0.1,192.168.1.100
# 监听端口(默认 5666,为什么?与 check_nrpe 默认一致,防火墙好配)
server_port=5666
# 命令定义示例
command[check_disk]=/usr/lib/nagios/plugins/check_disk -w 20% -c 10%
command[check_load]=/usr/lib/nagios/plugins/check_load -w 5,4,3 -c 10,8,6
command[check_procs]=/usr/lib/nagios/plugins/check_procs -w 150 -c 200
command[check_users]=/usr/lib/nagios/plugins/check_users -w 10 -c 20
command[check_zombie_procs]=/usr/lib/nagios/plugins/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/lib/nagios/plugins/check_procs -w 200 -c 250
# 3. 启动 NRPE 服务
systemctl enable nrpe
systemctl start nrpe
# 4. 检查 NRPE 状态
netstat -tlnp | grep 5666
systemctl status nrpe
# 5. 本地测试
/usr/lib/nagios/plugins/check_nrpe -H 127.0.0.1
# 输出: NRPE v3.2.1客户端(Nagios 服务器)配置
bash
# 1. 安装 check_nrpe 插件
yum install nagios-plugins-nrpe -y
# 或编译安装
wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-4.0.0/nrpe-4.0.0.tar.gz
tar xzf nrpe-4.0.0.tar.gz
cd nrpe-4.0.0
./configure
make check_nrpe
cp src/check_nrpe /usr/local/nagios/libexec/
# 2. 测试 NRPE 连接
/usr/local/nagios/libexec/check_nrpe -H 192.168.1.10
# 3. 测试具体命令
/usr/local/nagios/libexec/check_nrpe -H 192.168.1.10 -c check_diskNRPE 主机配置示例
bash
# 定义主机
define host {
use linux-server
host_name web-server-01
alias Web Server 01
address 192.168.1.10
max_check_attempts 3
check_period 24x7
notification_interval 30
notification_period 24x7
}
# 定义服务 - 磁盘检查
define service {
use generic-service
host_name web-server-01
service_description Disk Space
check_command check_nrpe!check_disk
max_check_attempts 3
check_interval 5
retry_interval 1
}
# 定义服务 - CPU 负载
define service {
use generic-service
host_name web-server-01
service_description CPU Load
check_command check_nrpe!check_load
}
# 定义服务 - 进程数
define service {
use generic-service
host_name web-server-01
service_description Total Processes
check_command check_nrpe!check_total_procs
}NRPE 命令定义
bash
# 在 Nagios 服务器上的 commands.cfg 添加
define command {
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
# 带 SSL 的 NRPE
define command {
command_name check_nrpe_ssl
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -n -c $ARG1$
}
# 带参数的 NRPE
define command {
command_name check_nrpe_args
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ -a $ARG2$
}📬 通知机制详解
通知类型
📋 触发条件
通知类型
🚨 硬状态通知
⚠️ 软状态通知
✅ 恢复通知
🔧 计划维护通知
到达告警阈值
临时故障
问题解决
维护开始/结束
硬状态 vs 软状态
| 状态类型 | 说明 | 通知时机 | 生活类比 |
|---|---|---|---|
| 软状态 | 临时检测异常 | 不立即通知 | 偶尔咳嗽,不必马上叫医生 |
| 硬状态 | 持续检测异常 | 立即通知 | 持续高烧,立即就医 |
1️⃣ 第1次检查
CRITICAL
⚠️ 软状态
max_check_attempts=3
2️⃣ 第2次检查
CRITICAL
⚠️ 软状态
3️⃣ 第3次检查
CRITICAL
🚨 硬状态
发送通知!
为什么默认「硬状态才发通知」? 软状态可能是网络抖动或瞬时负载,若每次都通知会造成告警疲劳;连续多次(如 3 次)仍异常再通知,既减少误报又不过晚。
通知方式配置
邮件通知
bash
# 1. 安装邮件服务
yum install postfix mailx -y
systemctl enable postfix
systemctl start postfix
# 2. 配置 Nagios 通知命令
define command {
command_name notify-host-by-email
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress: $HOSTADDRESS$\nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n" | /usr/bin/mail -s "** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" $CONTACTEMAIL$
}
define command {
command_name notify-service-by-email
command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$\n" | /usr/bin/mail -s "** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" $CONTACTEMAIL$
}
# 3. 配置联系人
define contact {
contact_name admin
alias Nagios Admin
use generic-contact
email admin@example.com
pager 13800000000
}
# 4. 测试邮件
echo "Test email from Nagios" | mail -s "Nagios Test" admin@example.com短信通知(使用网关)
bash
# 定义短信通知命令
define command {
command_name notify-service-by-sms
command_line /usr/local/bin/sms_send.sh $CONTACTPAGER$ "Nagios: $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ - $SERVICEOUTPUT$"
}
# 短信发送脚本示例
cat > /usr/local/bin/sms_send.sh << 'EOF'
#!/bin/bash
# 短信网关 API 调用示例
PHONE=$1
MESSAGE=$2
# 调用短信网关 API
curl -s "https://sms.api.com/send?phone=$PHONE&message=$(echo -n "$MESSAGE" | url编码)" || echo "短信发送失败"
EOF
chmod +x /usr/local/bin/sms_send.shWebhook 通知(钉钉/企业微信)
bash
# 钉钉通知脚本
cat > /usr/local/bin/dingtalk_notify.sh << 'EOF'
#!/bin/bash
WEBHOOK_URL="https://oapi.dingtalk.com/robot/send?access_token=YOUR_TOKEN"
MESSAGE=$1
curl -H "Content-Type: application/json" -X POST -d "{
\"msgtype\": \"text\",
\"text\": {
\"content\": \"$MESSAGE\"
}
}" $WEBHOOK_URL
EOF
chmod +x /usr/local/bin/dingtalk_notify.sh
# Nagios 命令定义
define command {
command_name notify-by-dingtalk
command_line /usr/local/bin/dingtalk_notify.sh "** $NOTIFICATIONTYPE$ Alert: $HOSTNAME$/$SERVICEDESC$ is $SERVICESTATE$ **"
}通知时间周期
bash
# 定义 24x7 全天候监控
define timeperiod {
timeperiod_name 24x7
alias 24 Hours A Day, 7 Days A Week
sunday 00:00-24:00
monday 00:00-24:00
tuesday 00:00-24:00
wednesday 00:00-24:00
thursday 00:00-24:00
friday 00:00-24:00
saturday 00:00-24:00
}
# 定义工作时间
define timeperiod {
timeperiod_name workhours
alias Work Hours
monday 09:00-18:00
tuesday 09:00-18:00
wednesday 09:00-18:00
thursday 09:00-18:00
friday 09:00-18:00
}
# 定义非工作时间
define timeperiod {
timeperiod_name nonworkhours
alias Non Work Hours
sunday 00:00-24:00
monday 00:00-09:00,18:00-24:00
tuesday 00:00-09:00,18:00-24:00
wednesday 00:00-09:00,18:00-24:00
thursday 00:00-09:00,18:00-24:00
friday 00:00-09:00,18:00-24:00
saturday 00:00-24:00
}📝 完整配置示例
目录结构
/usr/local/nagios/
├── etc/
│ ├── nagios.cfg # 主配置文件
│ ├── objects/
│ │ ├── commands.cfg # 命令定义
│ │ ├── contacts.cfg # 联系人定义
│ │ ├── timeperiods.cfg # 时间周期定义
│ │ ├── templates.cfg # 模板定义
│ │ ├── hosts.cfg # 主机定义
│ │ └── services.cfg # 服务定义
│ └── nrpe.cfg # NRPE 配置
├── bin/
│ └── nagios # Nagios 主程序
├── libexec/
│ └── check_* # 各种检查插件
└── share/
└── (Web 界面文件)主配置文件关键项
bash
# nagios.cfg 主要配置
# 日志文件
log_file=/usr/local/nagios/var/nagios.log
# 配置文件目录
cfg_dir=/usr/local/nagios/etc/objects
# 检查结果缓存
check_result_path=/usr/local/nagios/var/spool/checkresults
# 状态文件
status_file=/usr/local/nagios/var/status.dat
# 命令检查间隔(秒)
command_check_interval=5s
# 最大并发检查数
max_concurrent_checks=20
# 日志轮转
log_rotation_method=d
log_archive_path=/usr/local/nagios/var/archives
# 状态更新间隔
status_update_interval=10s
# 通知间隔
notification_interval=30模板配置
为什么用模板? 几十台主机、几百个服务若逐个写全所有属性会重复且难维护。用 name 定义模板(register 0 表示不注册为实际对象)、再用 use 继承,只写 host_name、address、差异项即可;改模板一处,所有引用该模板的主机/服务一起生效。生活类比:像「标准合同模板」,每份只填姓名、金额,其余条款统一。
bash
# 通用主机模板
define host {
name generic-host
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
failure_prediction_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
check_period 24x7
check_interval 5
retry_interval 1
max_check_attempts 3
check_command check-host-alive
notification_interval 30
notification_period 24x7
notification_options d,u,r
contact_groups admins
register 0
}
# Linux 主机模板
define host {
name linux-server
use generic-host
check_period 24x7
check_interval 5
retry_interval 1
max_check_attempts 3
check_command check-host-alive
notification_period workhours
notification_interval 120
notification_options d,u,r
contact_groups admins
register 0
}
# 通用服务模板
define service {
name generic-service
active_checks_enabled 1
passive_checks_enabled 1
parallelize_check 1
obsess_over_service 1
check_freshness 0
notifications_enabled 1
event_handler_enabled 1
flap_detection_enabled 1
failure_prediction_enabled 1
process_perf_data 1
retain_status_information 1
retain_nonstatus_information 1
is_volatile 0
check_period 24x7
max_check_attempts 3
check_interval 5
retry_interval 1
contact_groups admins
notification_options w,u,c,r
notification_interval 60
notification_period 24x7
register 0
}🚀 高级特性
依赖关系
为什么需要依赖? 例如:交换机挂了,下面的服务器会集体「不可达」,若每台都发告警会刷屏。定义「主机 A 依赖 交换机 B」后,B 宕机时 Nagios 可只通知 B 故障,并抑制对 A 的告警(或标记为因依赖不可达),减少噪音。生活类比:整栋楼停电时,不必每个房间都报「灯不亮」,只报「楼停电」即可。
🖥️ 交换机
🖥️ Web 服务器
📋 HTTP 服务
📋 磁盘/负载
bash
# 服务依赖:Web 服务依赖系统运行
define servicedependency {
host_name web-server-01
service_description HTTP
dependent_host_name web-server-01
dependent_service_description Disk Space
execution_failure_criteria n
notification_failure_criteria w,u,c
}
# 主机依赖:虚拟机依赖物理机
define hostdependency {
host_name vm-server-01
dependent_host_name vm-server-02
notification_failure_criteria d,u
}事件处理器
生活类比 :事件处理器 = 火警时先自动启动喷淋和排烟,再通知值班;不是等人工到了才处理。
为什么有用? 部分故障可自动恢复(如进程僵死时重启、清理临时文件),减少人工介入;也可用于联动工单、自动扩容等。注意:event_handler 只在状态变化时执行,且要避免脚本长时间阻塞或失败导致 Nagios 卡住。
bash
# 自动重启服务的事件处理器
define command {
command_name restart-httpd
command_line /usr/local/bin/restart_service.sh httpd $HOSTADDRESS$
}
# 服务定义中使用事件处理器
define service {
use generic-service
host_name web-server-01
service_description HTTP
check_command check_http
event_handler restart-httpd
event_handler_enabled 1
}
# 重启脚本示例
cat > /usr/local/bin/restart_service.sh << 'EOF'
#!/bin/bash
SERVICE=$1
HOST=$2
LOGFILE="/var/log/nagios/eventhandlers.log"
echo "`date` - Attempting to restart $SERVICE on $HOST" >> $LOGFILE
ssh nagios@$HOST "sudo systemctl restart $SERVICE" >> $LOGFILE 2>&1
EOF被动检查
生活类比:主动检查 = 保安定时去每间店巡检;被动检查 = 店铺自己按约定时间把「自查结果」报到总台。总台(Nagios)不主动连店铺,只接收上报的结果。
为什么需要被动检查? 设备在防火墙后、或由应用/中间件自己上报状态时,Nagios 无法主动建连;此时用 submit_check_result 或 NSCA 把结果推给 Nagios,Nagios 只做状态更新和通知。注意要设 check_freshness 和 freshness_threshold,否则外部一旦停止上报,Nagios 会一直认为「最后结果」有效。
bash
# 用于无法主动检查的场景(如防火墙后)
# 1. 启用被动检查的服务定义
define service {
use generic-service
host_name firewall-protected-server
service_description Application Status
active_checks_enabled 0
passive_checks_enabled 1
check_freshness 1
freshness_threshold 3600
}
# 2. 提交被动检查结果
/usr/local/nagios/libexec/submit_check_result \
firewall-protected-server \
'Application Status' \
0 \
"Application is running OK"🔧 故障排查
常见问题诊断
是
否
是
否
是
否
是
🔧 Nagios 问题
无法连接 NRPE?
🔥 检查防火墙
端口 5666
命令执行错误?
📂 检查插件权限
chmod +x
配置文件错误?
✔️ 使用 -v 验证配置
通知不发送?
📧 检查邮件服务
查看日志
为什么先验证配置再重启? nagios -v 会检查语法和对象引用,错误时不会启动或运行中出错;先 -v 通过再 reload,避免误以为「改好了」却因笔误导致服务异常。
排查命令
| 命令/操作 | 作用 | 为什么常用? |
|---|---|---|
nagios -v nagios.cfg |
验证配置文件语法与对象引用 | 为什么先 -v?修改配置后若语法错误或引用缺失,Nagios 会拒绝启动;-v 只检查不启动,安全 |
tail -f nagios.log |
实时看日志 | 为什么看日志?告警没发、检查失败原因、通知命令错误都会写在日志里,是排错第一手资料 |
check_nrpe -H IP -c check_disk |
从 Nagios 本机测试对某台机的 NRPE 检查 | 为什么手动测?可区分是「NRPE 不通」还是「Nagios 配置错」;-c 必须与被监控机上 commandxxx 一致 |
telnet IP 5666 |
测到 NRPE 端口是否可达 | 为什么用 telnet?快速判断防火墙/网络是否放行 5666;若不通先解决网络再查插件 |
nagiosstats |
查看当前检查数、延迟等统计 | 为什么有用?检查过多或延迟过大时需调 max_concurrent_checks 或检查间隔 |
nagios -d ... |
调试模式启动 | 为什么 -d?前台运行、输出详细,便于看启动阶段错误;生产一般用 systemd 后台运行 |
bash
# 1. 验证配置文件
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
# 2. 查看 Nagios 日志
tail -f /usr/local/nagios/var/nagios.log
# 3. 手动运行插件测试
/usr/local/nagios/libexec/check_nrpe -H 192.168.1.10 -c check_disk
# 4. 检查 NRPE 连接
telnet 192.168.1.10 5666
# 5. 查看当前状态
/usr/local/nagios/libexec/nagiosstats
# 6. 调试模式
/usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg性能优化
| 项 | 建议 | 为什么? |
|---|---|---|
| 检查间隔 | 关键 1~5 分钟,普通 5~15 分钟,非关键 15~60 分钟 | 为什么分级?全用 1 分钟会堆积大量并发检查,调度延迟变大;非关键项稍长间隔即可 |
| max_parallel_checks | 如 20~50,视 CPU 与网络 | 为什么不能无限大?并发过多会拖慢单次检查、增加超时;太小则检查排队、延迟上升 |
| cached_service_check_horizon | 如 15 | 为什么用缓存?同一服务短时间多次被需要时(如多视图)可复用结果,减少重复执行插件 |
| enable_performance_data | 不做图表时可关 | 为什么可关?性能数据输出和后续处理占资源;若不用 PNP4nagios 等绘图可关闭 |
bash
# 1. 调整检查间隔
# - 关键服务:1-5 分钟
# - 普通服务:5-15 分钟
# - 非关键服务:15-60 分钟
# 2. 启用并行检查
max_parallel_checks=20
# 3. 使用缓存
cached_service_check_horizon=15
# 4. 优化性能数据处理
enable_performance_data=0 # 不需要图表数据时可禁用🔀 与同行监控软件对比及适用场景
了解 Nagios 与 Zabbix、Prometheus、Icinga、Cacti、Grafana 等监控方案的差异,有助于在选型或迁移时做出更合适的选择。下表从架构、配置方式、强项、弱项、典型场景 等维度做简要对比;文末按适用场景给出选型建议。
同行软件对比总览
| 维度 | Nagios Core | Zabbix | Prometheus | Icinga 2 | Cacti | Grafana |
|---|---|---|---|---|---|---|
| 定位 | 调度引擎 + 插件,状态与告警为主 | 一体化监控套件(采集+告警+展示) | 时序库 + 拉取模型,云原生指标 | Nagios 分支,兼容插件、现代架构 | 网络流量/指标绘图 | 可视化与仪表板(多数据源) |
| 架构 | 单机/主从,插件拉取或 NRPE | Server-Agent + 中心数据库(如 MySQL) | 拉取、多副本、无中心 DB | 集群、API、可分布式 | RRDTool 存图 + 轮询 | 无存储,连 Prometheus/Influx 等 |
| 配置方式 | 手写配置文件 | Web 界面 + 模板、自动发现 | YAML + 服务发现 | 配置文件或 Icinga Director | Web + 设备/图模板 | 面板配置、连已有数据源 |
| 告警 | 灵活,依赖脚本/插件 | 内置丰富:分级、依赖、聚合 | Alertmanager,需自配规则 | 内置,可与 Nagios 类似 | 阈值告警较基础 | 依赖数据源告警或外部系统 |
| 可视化 | Web 以状态/列表为主,图需外挂 | 内置图表、大屏、拓扑 | 自带简单 UI,常配 Grafana | Web2 + 可选 Grafana | 专注网络/流量图 | 强项:仪表板、多数据源 |
| 扩展 | 插件生态成熟,NRPE/SNMP | 内置 Agent、SNMP、JMX、IPMI | Exporters、Pushgateway | 兼容 Nagios 插件 + 集群 | 插件/脚本扩展 | 数据源插件、告警通道 |
| 学习/运维成本 | 中等,需熟悉配置语法 | 中等偏高,功能多 | 中等,概念清晰 | 中等,有 Web 可选 | 偏低,偏「画图」 | 低(仅展示时) |
| 许可证 | GPL,商业版 Nagios XI | GPL | Apache 2.0 | GPL | GPL | AGPL(企业功能付费) |
为什么会有这么多方案? 监控需求差异大:有人只要「有没有宕机、发邮件」;有人要网络流量图、容量规划;有人要云原生、K8s、多维度指标与 PromQL。没有一种工具在所有场景下都最优,所以会并存多种形态。
与各产品的简要对比
Nagios vs Zabbix
| 对比项 | Nagios Core | Zabbix |
|---|---|---|
| 强项 | 轻量、插件多、配置可版本管理、告警脚本自由 | 开箱即用的 Web 配置、自动发现、图表、SNMP/JMX 支持好 |
| 弱项 | 无内置图表、配置手写、大规模时需自己规划 | 部署与调优相对重,大量主机时对 DB 和前端有要求 |
| 适用 | 中小规模、偏「状态+告警」、习惯用配置文件 | 企业内网、机房+网络设备多、需要统一界面和报表 |
生活类比:Nagios 像自己组装音响,线材、功放都可换;Zabbix 像买一套家庭影院,功能全但按说明书来。
Nagios vs Prometheus
| 对比项 | Nagios Core | Prometheus |
|---|---|---|
| 强项 | 主机/服务存活、告警逻辑成熟、NRPE 等本地检查 | 指标、多维标签、PromQL、适合 K8s/微服务、生态(Grafana、Alertmanager) |
| 弱项 | 不侧重时序与多维查询,画图需外挂 | 默认拉取,短生命周期、防火墙内目标要 Exporters 或 Pushgateway |
| 适用 | 传统机房、物理机/虚拟机、关注「是否活着」「服务是否可用」 | 云原生、容器、需要「按标签查、算率、做 SLO」 |
为什么 Prometheus 和 Nagios 常一起出现? 很多团队用 Nagios(或 Icinga)做「可用性告警」,用 Prometheus + Grafana 做「指标与曲线」,两者互补而非替代。
Nagios vs Icinga 2
| 对比项 | Nagios Core | Icinga 2 |
|---|---|---|
| 强项 | 生态久、资料多、第三方集成多 | 兼容 Nagios 插件与部分配置,集群、REST API、Icinga Director(Web 配置) |
| 弱项 | 无集群、配置全手写、扩展大集群要自己拆 | 概念略多(Zone、Endpoint),从零学要一点时间 |
| 适用 | 已有 Nagios 且规模不大、不想大改 | 想要「类 Nagios」但需要集群、API、Web 配置、更好扩展 |
为什么 Icinga 常被说是 Nagios 替代? Icinga 最初是 Nagios 分支,Icinga 2 重写后保留「主机/服务/插件」思路,并加了集群和现代配置方式,适合「从 Nagios 升级又不想丢掉插件」的场景。
Nagios vs Cacti / Grafana
- Cacti :侧重网络设备流量、带宽图,基于 RRDTool 存数据画图,轮询 SNMP 等。和 Nagios 的关系:Cacti 画图、Nagios 告警,历史上常一起用。
- Grafana :侧重可视化与仪表板,不存指标,接 Prometheus、InfluxDB、Zabbix、Elasticsearch 等。和 Nagios 的关系:Nagios 负责告警与状态,Grafana 负责把各类数据源画成一张张图,两者可并存。
按适用场景选型(何时用谁?)
状态/告警/简单稳定
一体化+Web+自动发现
云原生/K8s/指标/PromQL
只要画图/多数据源展示
网络流量/带宽图
📋 你的主要需求
更看重哪一类?
🖥️ Nagios / Icinga
📊 Zabbix
📈 Prometheus + Grafana
🖼️ Grafana
🌐 Cacti
传统机房、物理机、少量主机
企业内网、设备多、要报表
容器、微服务、SLO
已有数据源,做大盘
路由器、交换机流量
| 场景 | 更合适的选择 | 说明 |
|---|---|---|
| 传统机房,几十台服务器,要存活+服务+邮件告警 | Nagios Core 或 Icinga 2 | 配置一次可稳定跑很久;NRPE + 插件即可覆盖磁盘、负载、HTTP 等 |
| 企业内网,大量网络设备+服务器,要统一 Web 和报表 | Zabbix | 自动发现、SNMP 模板、图表和大屏较完整,适合「一个平台看全」 |
| 云原生、K8s、微服务,要指标、标签、SLO | Prometheus + Grafana(+ Alertmanager) | 拉取、多维、PromQL、与 K8s 服务发现契合 |
| 已有 Nagios,想加图表或大盘 | 保留 Nagios,用 Grafana 接其他数据源;或 PNP4nagios 等接 Nagios 性能数据 | 告警仍由 Nagios 做,图单独看 |
| 主要看网络流量、带宽趋势 | Cacti,或 Zabbix 的图表 | Nagios 不擅长「画流量图」,Cacti 专精于此 |
| 要集群、API、Web 配主机/服务,又希望兼容 Nagios 插件 | Icinga 2 + Icinga Director | 从 Nagios 迁移路径清晰,扩展性更好 |
| 多数据源统一展示(日志、指标、APM) | Grafana 作为展示层 | 数据仍由 Prometheus/Zabbix/ELK 等采集,Grafana 只做仪表板 |
小结(为什么了解对比有用?)
- 选型:新项目可按「传统 vs 云原生」「要图 vs 要告警」「能否接受手写配置」快速缩小范围。
- 迁移:已有 Nagios 可考虑 Icinga 2 做功能增强,或引入 Prometheus+Grafana 做指标与可视化,Nagios 继续做可用性告警。
- 组合:实践中常见「Nagios/Icinga 负责告警 + Prometheus+Grafana 负责指标与图」或「Zabbix 一体机」,按团队习惯与规模选择即可。
🎯 总结与官方参考
核心要点记忆口诀
Nagios 监控要记牢
核心引擎调度好
插件执行来检查
状态码很重要
NRPE 远程检查本地数据
通知系统及时告警发邮件
模板配置减少重复劳动
依赖关系理清监控架构生活类比总结
- Nagios Core = 医院调度中心
- Plugins = 各种检测设备
- NRPE = 派人到店里检查
- Notifications = 给医生打电话
- Templates = 病历模板
- Dependencies = 部门间的上下级关系
最佳实践
| 实践 | 说明 | 为什么? |
|---|---|---|
| 合理设置检查间隔 | 关键服务 1~5 分钟,非关键 15~60 分钟 | 为什么不能全 10 秒?检查过多会占满调度和网络,监控本身变成负担;按重要性分级 |
| 使用模板 | generic-host、generic-service、linux-server 等 | 为什么用模板?主机/服务共性用 use 继承,只改差异项,减少重复且改一处全局生效 |
| 设置告警阈值 | -w/-c 与业务匹配,避免过于敏感 | 为什么阈值要调?过严会告警疲劳,过松会漏报;需结合业务试跑一段时间再微调 |
| 定期维护 | 清理下线主机、过期服务、无用 contact | 为什么清理?配置膨胀后验证慢、界面乱;定期归档或删除有利于长期可维护性 |
| 测试告警 | 故意制造一次 WARNING/CRITICAL 测邮件/短信 | 为什么专门测?通知命令或联系人有误时,只有真告警才会暴露,提前测可避免「告警发了但没人收到」 |
| 文档记录 | 记录自定义命令、脚本、联系人职责 | 为什么文档化?人员变动或半年后自己也会忘;自定义 check 和 event handler 尤其要写清用途与参数 |
最后提醒:监控系统本身也需要监控!确保 Nagios 自己的健康也被监控!(为什么?Nagios 挂了就没人告警了,可用另一台机器用 check_http 或 ping 监控 Nagios 主机,或使用 Nagios 的 HA 方案。)
📚 官方文档与参考
本文内容与 Nagios Core 官方文档 对应,以下链接便于核对与深入阅读。
| 资源 | 链接 | 用途 |
|---|---|---|
| 对象配置总览 | Object Configuration Overview | Host、Service、Command、Contact、Timeperiod 等对象说明 |
| 主配置文件选项 | Main Configuration File | nagios.cfg 中 cfg_dir、check_interval、max_concurrent_checks 等 |
| 通知 | Notifications | 通知逻辑、notification_interval、escalation |
| 依赖关系 | Host and Service Dependencies | servicedependency、hostdependency、抑制告警 |
| Nagios 文档中心 | Nagios Core Documentation | 安装、快速入门、完整手册 |