设计计数点赞系统
1下面是思路分析
计数系统常见场景:
用户视频的点赞,收藏,分享,评论,转发。
用户主页的关注,粉丝,作品,热度。
评论的点赞和回复数量。
分析计数的特点:
这种计数会面临着很多的高并发读请求,高并发写请求。但是不需要准确显示(b站的1播放10赞是常有的),精确性和数量成反比(少的时候看个位低位之类的,多的时候几十万不看准确的)。
所以代码角度真实的需求:维护读多写多,不追求完全准确性,且准确性和数量反比的字段。
附加需求:离线校准。
2技术选型
维护读多写多,不追求完全准确性,且准确性和数量反比的字段。
满足这个的可以看数据库,像是关系型mysql,非关系型redis
对于mysql可以最简单记录到视频属性,也可以统计用户和这个视频的关系,还可以把一种计数全存表里。
对于并发低可以这样,<5000qps。但是并发上来了mysql怎么存都承担不住
所以考虑使用redis存储这些数据,redis有自带的持久化机制,也能承担高并发的访问,也有对数据增减的指令。
再一步技术选型
可以用redis的string存储,string保存数字底层会议证书编码保存,也支持命令加减。这样一个视频会有5个string。这个时候会调用mget。但是存在两个问题:集群下key一次请求多个会映射到多个服务器开发高;且一个视屏对应5个string占用内存大。
解决办法,第一个可以用前主流的Redis集群(如Codis )提供了较好的解决方案:我们可以为 前缀相同的Key打上hashtag标签。Redis集群会保证命中相同hashtag的Redis Key被存 储在集群中的同一个Redis服务节点上。
第二个没办法节约内存,就得考虑换数据结构。
hash可以节约内存,key用视频对应的,值存这五个属性,然后hash底层也有小数据空间的优化。
讲一下内存的对比:string有四个属性分配的大小,实际占用的大小,sds类型,动态数组。而hash在这里只有ziplist比较省内存,虽然具体大小记不太清了。
上述每个命令在Redis底层实现的执行效率都非常高,有较低的延迟,能较好地承载 高并发访问。
还有即使是hash其实也还可以压缩。虽然有点鸡蛋里挑骨头
那么使用一个长度为5的long类型 (长整数类型)数组来保存计数即可,内存占用字节数为5x8=40字节,相比于Redis原生 压缩列表的78字节,减少了几乎一半的内存占用。
别的地方的优化:冷热数据分离
这里涉及到了rocksdb存储引擎,简单来说就是磁盘的kv存储更节约空间。
对于附加需求,离线校准。
因为 Redis 或 RocksDB 的异步写可能因为各种异常导致计数和实际的点赞记录(流水表)对不上。
做法:通常每天凌晨启动一个 Flink/Spark 任务,扫一遍 MySQL 的点赞流水表,算出一个准确值,然后覆盖掉 Redis/RocksDB 里的缓存值。
3具体系统
至此,计数服务的计数要点都已经讲清楚了。接下来,我们可以画出完整的架构图

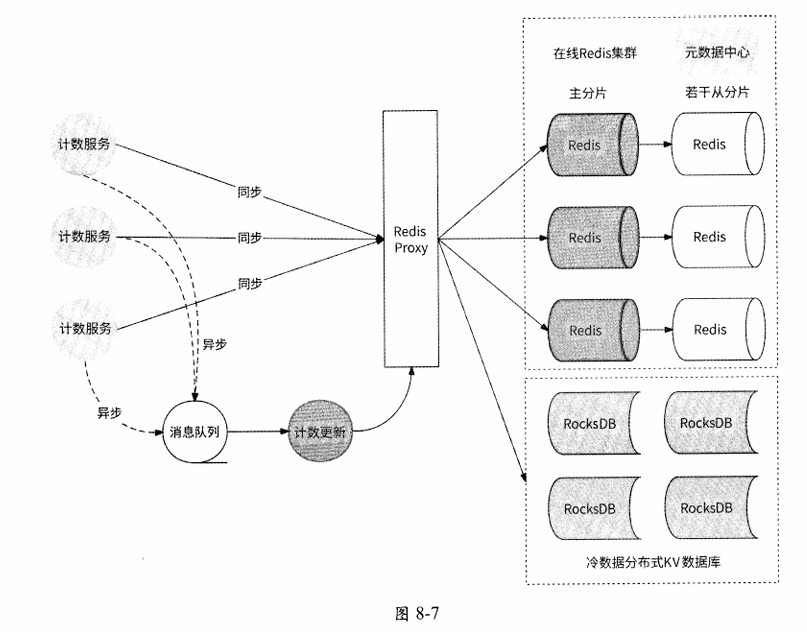
4该怎么选
用户数量少,为了方便,就不要单独搞计数服务,直接存在mysql的表里就可以。
用户数量多用一定需求量,使用redis的hash存储计数服务。
用户数量非常多,且考虑到内存珍贵,使用rocksdb存储引擎进行冷热分离存储。