哨兵机制
引言
在之前的讨论中,我们了解了Redis的主从复制机制。简单来说,它的核心目的就是为了"防挂"------通过把主节点的数据实时同步到多个从节点,实现数据冗余。这样即使一台机器倒下,数据也不会丢失。但这里有个致命的短板:主节点依然是唯一的"单点"。如果主节点真的"阵亡"了,虽然从节点手里有数据,但它们缺乏一个"大脑"来指挥谁该接替成为新的主节点。此时,整个集群对外是不可用的,因为没有节点能处理写请求。
为了解决这个问题,Redis引入了哨兵(Sentinel)机制。它就像一个不知疲倦的指挥官,时刻盯着主节点的健康状况。一旦发现主节点"挂了",它能自动从众多从节点中,通过一套严谨的选举算法挑选出一位Leader,将其提升为新的主节点,从而实现故障的自动转移与恢复。
本篇文章我们就来讲解一下哨兵机制~~
哨兵是如何工作的?
我们先从最基础的逻辑出发:假设只有一个哨兵在盯着一个主从集群,它是如何一步步完成监控、判断和切换的?
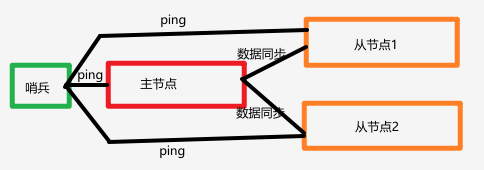
1. 持续监控
哨兵启动后,它会一刻不停地与它监控的Redis实例进行通信。
- 心跳检测(PING) :哨兵会以每秒一次的频率,向主节点(Master)和从节点(Slave)发送
PING命令。如果主节点回复了PONG,哨兵就知道:"老板还活着,一切正常。"如果主节点没有回复,或者回复了错误信息,哨兵就会把这个"异常"记录下来。 - 信息更新(INFO) :哨兵会每隔10秒向主节点发送
INFO命令。这不仅仅是为了看主节点死没死,更重要的是获取主节点的最新状态,以及它旗下有哪些从节点。这样哨兵就能自动发现集群的拓扑结构变化。
2. 故障判断
当主节点真的挂了(或者网络断了),哨兵不会立马大张旗鼓地进行切换,它有一套严谨的判断逻辑。
- 主观下线(SDOWN - Subjectively Down) :这是哨兵的"个人判断"。如果哨兵在配置的
down-after-milliseconds毫秒内(比如设置的5000毫秒),一直没能收到主节点的有效回复,它就会在自己心里给主节点打上一个标签:"主观下线"。此时,哨兵虽然觉得主节点"好像挂了",但它还不确定是不是自己网络的问题,或者是主节点只是暂时卡顿。 - 客观下线(ODOWN - Objectively Down):虽然我们只有一个哨兵,但为了逻辑的完整性,我们可以理解为:当哨兵确认主节点无法响应,并且准备开始行动时,它会将状态升级为"客观下线"。这意味着"抢救"流程(故障转移)现在正式合法启动了。
3. 执行切换
一旦确认主节点"没救了",哨兵就要扮演"指挥官"的角色,开始执行故障转移(Failover)。
- 挑选"接班人"(选主) :哨兵不会随便选一个从节点当主节点,它有一套严格的筛选标准(通常遵循以下优先级):
- 排除法:先把那些连不上、或者数据严重落后的从节点踢出候选名单。
- 看优先级 :选择配置了
slave-priority值最小的从节点(这个值可以在配置文件里手动设,值越小越优先)。 - 看数据新鲜度:如果优先级一样,就选那个复制偏移量(offset)最大的从节点,也就是数据最完整的那个。
- 看Run ID:如果以上都一样,就选Run ID最小的那个(本质上是随机选一个)。
- 发布命令(角色变更) :选好"接班人"后,哨兵会向这个选中的从节点发送一条
SLAVEOF NO ONE命令。这条命令的意思是:"你别当小弟了,你现在是老大(Master)!"接着,哨兵会更新其他从节点的配置,命令它们执行SLAVEOF指向新的主节点,让它们开始同步新老大的数据。 - 通知四方(配置更新):最后,哨兵会把新主节点的地址告诉客户端。客户端收到通知后,就会把后续的写请求发送到新的主节点上。
那么万一我们现在这个哨兵他挂了,然后不就检测不到了吗?其实,还是一样的思想,既然主节点能够靠主从复制防止数据丢失,那么我们也可以有多个哨兵~也就组成了哨兵集群!(感觉有点像多人成军的感觉,果然团结就是力量这句话的含金量还在上升)
哨兵集群
为了解决哨兵自身的单点故障问题,Redis引入了哨兵集群(Sentinel Cluster)的概念。其核心思想与主从复制解决主节点单点故障的思路完全一致:通过冗余来保证高可用。
在哨兵集群中,会部署多个哨兵实例。这些哨兵实例之间会建立TCP连接,并通过发布/订阅机制(通常是sentinel频道)来交换信息。它们会互相监控彼此的健康状况。
互相监控: 哨兵A会定期向哨兵B、哨兵C发送PING命令。如果哨兵A在一定时间内没有收到哨兵B的回复,它会将哨兵B标记为"主观下线"。当集群中足够多的哨兵都同意哨兵B下线时,哨兵B就会被标记为"客观下线"。
故障转移的决策: 当主节点发生故障时,哨兵集群会通过"Raft算法"的简化版进行投票选举,选出一个哨兵来领导(Leader)故障转移过程。这确保了即使部分哨兵失效,只要集群中还有半数以上的哨兵存活,整个监控系统就能正常工作。
通过这种集群化部署,哨兵系统自身也具备了高可用性,从而为Redis集群提供了端到端的故障自动恢复能力。
配置
在sentinel.conf配置文件中,有几个核心参数直接决定了哨兵的灵敏度与稳定性:
| 参数 | 默认值 | 作用说明 |
|---|---|---|
sentinel monitor <master-name> |
无 | 定义监控的主节点IP、端口及法定票数(quorum) |
sentinel down-after-milliseconds |
30000 | 判定主观下线的超时时间,建议设为5000-10000 |
sentinel failover-timeout |
180000 | 整个故障转移流程的超时时间 |
sentinel parallel-syncs |
1 | 故障转移后,同时向新Master同步数据的从节点数量 |
配置建议: down-after-milliseconds不宜过小,否则网络偶尔抖动就会触发误判;也不宜过大,否则故障发现不及时。通常根据业务容忍度调整为5秒左右。
脑裂问题
当主节点因网络分区与哨兵集群隔离,但主节点本身仍在运行时,哨兵会选举新主。当网络恢复后,旧主会被降级为从节点。虽然Redis通过复制偏移量机制尽量减少数据丢失,但在网络分区期间,旧主上写入的数据仍可能丢失。生产环境建议开启min-slaves-to-write配置,限制主节点在没有足够从节点时拒绝写入,从而降低数据丢失风险。
总结与选型建议
至此,我们通过"主从复制 + 哨兵集群",我们成功解决了Redis的高可用性问题。即使主节点宕机,或者某个哨兵"罢工",系统依然能自动选出新的领导者,保证服务不中断。
但还有一个核心问题悬而未决: 我们的数据和流量总是在不断增长的,单台机器总有撑不住的一天。怎么让Redis像搭积木一样,想扩容就扩容?
答案就是Redis 集群(Cluster)。通过数据分片,我们可以将庞大的数据集分散到多台机器上,实现横向扩展。下一节,我们就来讲一讲集群。