我们知道平常写的C语言代码里面的代码和数据都会在内存中的不同分区。用malloc申请出来的内存在堆区上。局部变量在栈区上。所以我们所写的代码和数据都有自己对应的分区。
接下来的讲解都是按32位机器说明。
首先计算机是按字节寻址的。也就是说计算机想要查看内存的内容,是按1个字节一个字节的查看。
现在就有了一个计算机查看内存的最小单位,1个字节。
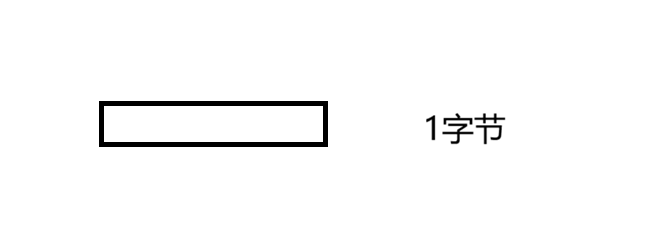
我们把这一个小长方形看成1一个字节的存储空间。因为是32位的机器,所以最多可以表示2322^{32}232个数字。
我们知道地址其实就是用数字来表示,所以现在我们就有2的32次方个小长方形,每个小长方形的大小是1个字节。所以现在就有一个由2322^{32}232个小长方形组成的一个连续的空间,大小为2322^{32}232乘以1个字节,为4GB。
前面说了程序里面的代码和数据会被存放在不同的区域。
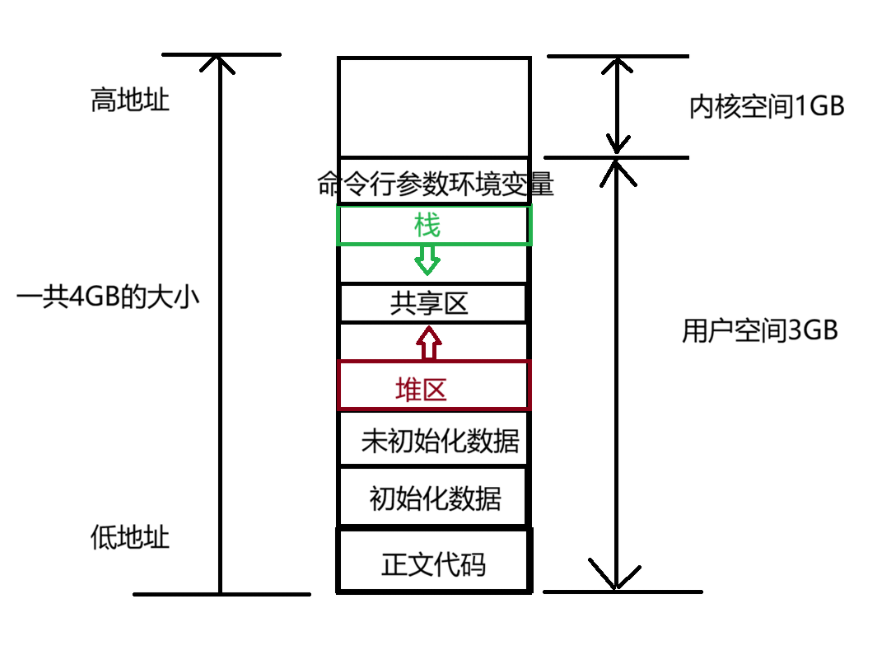
这个4GB的空间就是进程地址空间(地址空间)。对于每一个进程来说。每一个进程都需要连续的4GB的内存空间。
现在给大家看一个现象。
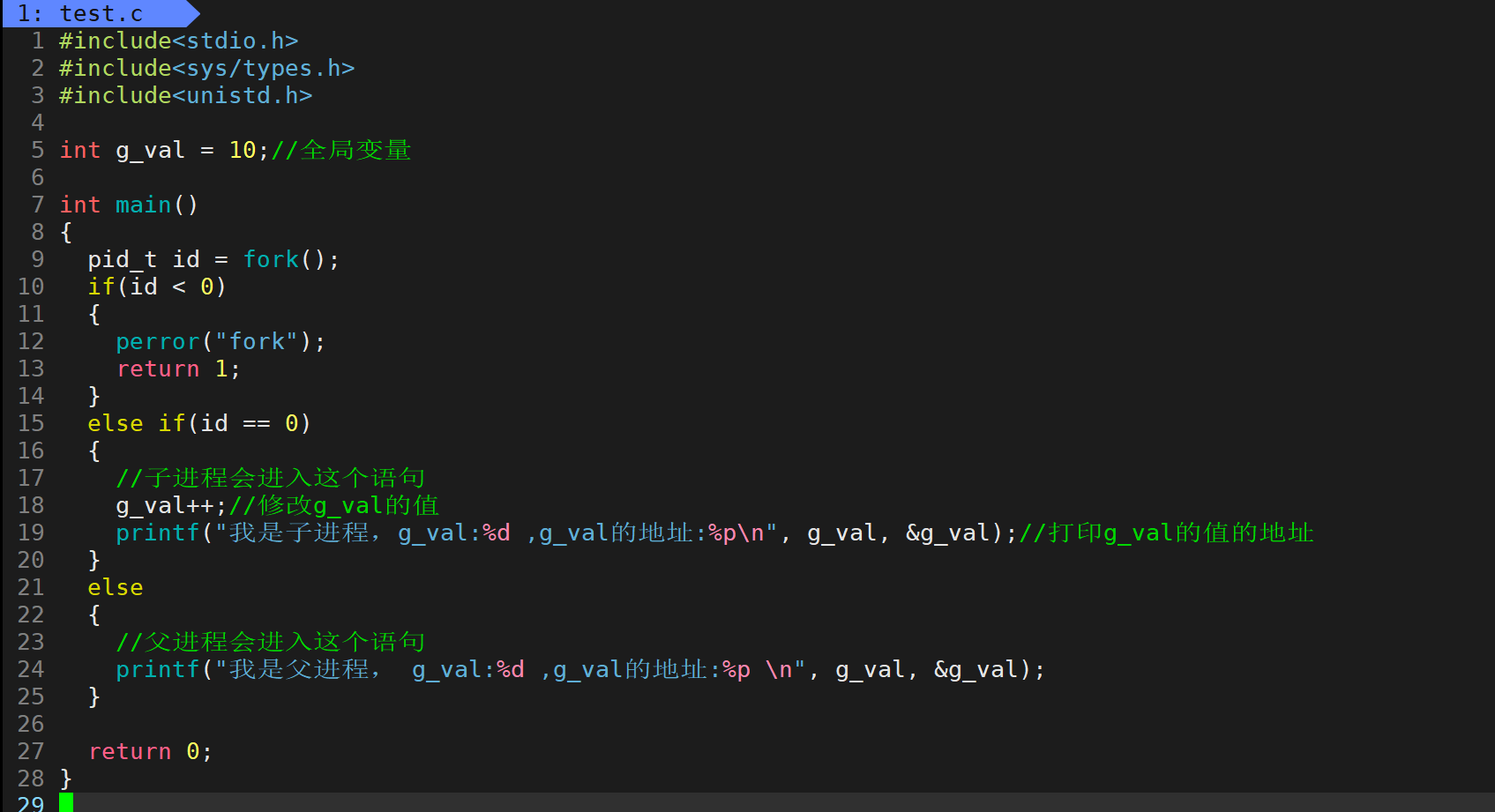
现在有一个代码,我们知道子进程是共享父进程的代码和数据的。但如果有一方修改数据的话。会发生写时拷贝。子进程要对g_val修改就会再创建一个变量g_val然后拷贝一份原先的g_val的值,再对新的g_val进行修改。这就是写时拷贝。
上面的代码子进程对数据进行了修改,并打印数据和数据的地址。
父进程不对数据进行修改,只打印数据和地址。
运行程序来看一下结果。

可以看出子进程确实发生了写实拷贝,并没有改变父进程的数据。
但是这里有个奇怪的现象,就是子进程的g_val的地址和父进程g_val的地址是相同的!
那就很奇怪,现在看到的现象就是。同一块地址空间里面的内容居然是不同的值。这是不符合物理现象的。所以我们可以初步的判断这里的地址一定不是真实的物理地址。这里就直接把结论给大家,这个地址是虚拟地址。我们用户的任何取地址操作所看见的地址全是虚拟地址!
我们用户是无法看见真实的物理地址,只能看到虚拟地址。
现在就有了虚拟地址这个概念。
在上面说过,每一个进程都需要一块连续的大小为4GB的内存。但我们知道平常运行电脑都是有非常多的进程一起运行。如果每个进程都需要连续的4GB内存。很显然内存是不够用的。所以其实上面所说的进程地址空间也是虚拟地址的概念.
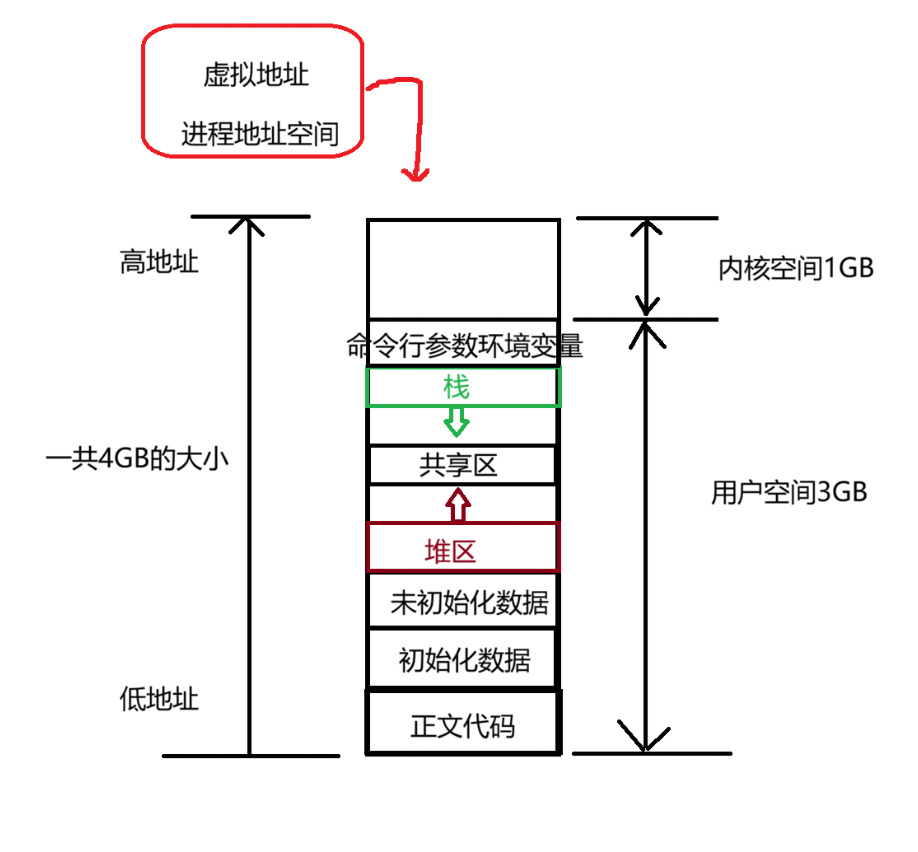
所谓的虚拟地址,其实就是每个进程都需要一块连续的4GB大小的内存。但是显示不可能给每一个进程都分一个连续的4GB大小的内存。这里的进程空间地址只是操作系统骗进程说:"你现在拥有着一块连续的4GB大小的空间给你使用"。实际上并没有分配这么多的内存给进程。
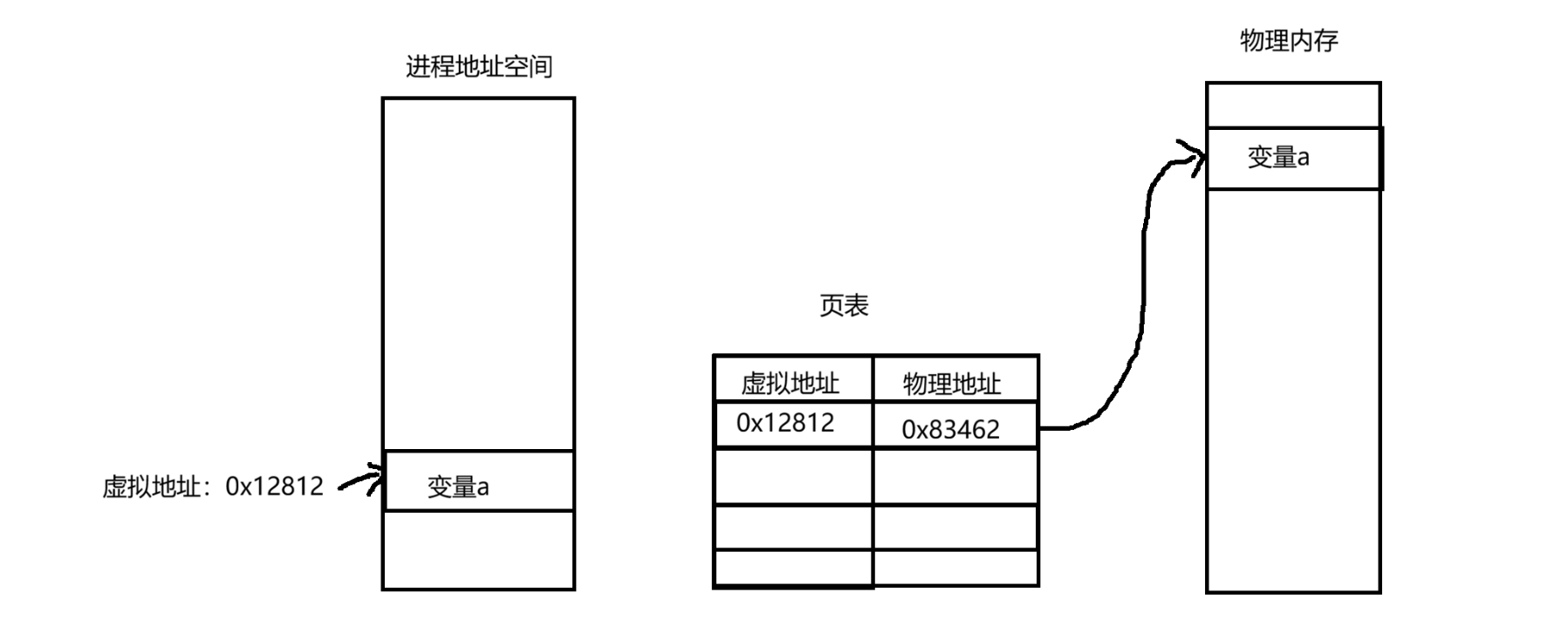
现在知道我们获得的地址都是虚拟地址。现在有一个东西,叫做页表。这个页表的作用就是将虚拟地址转换成真实的物理地址。
比如现在有一个程序,这个程序里面有一个变量a。当运行这个程序时,这个程序一定是加载到真实的物理地址中。比如执行到a += 3这条语句。
变量a有自己的虚拟地址,然后页表就会把这个虚拟地址转换成真实的物理地址。然后对物理地址中的变量a进行修改。
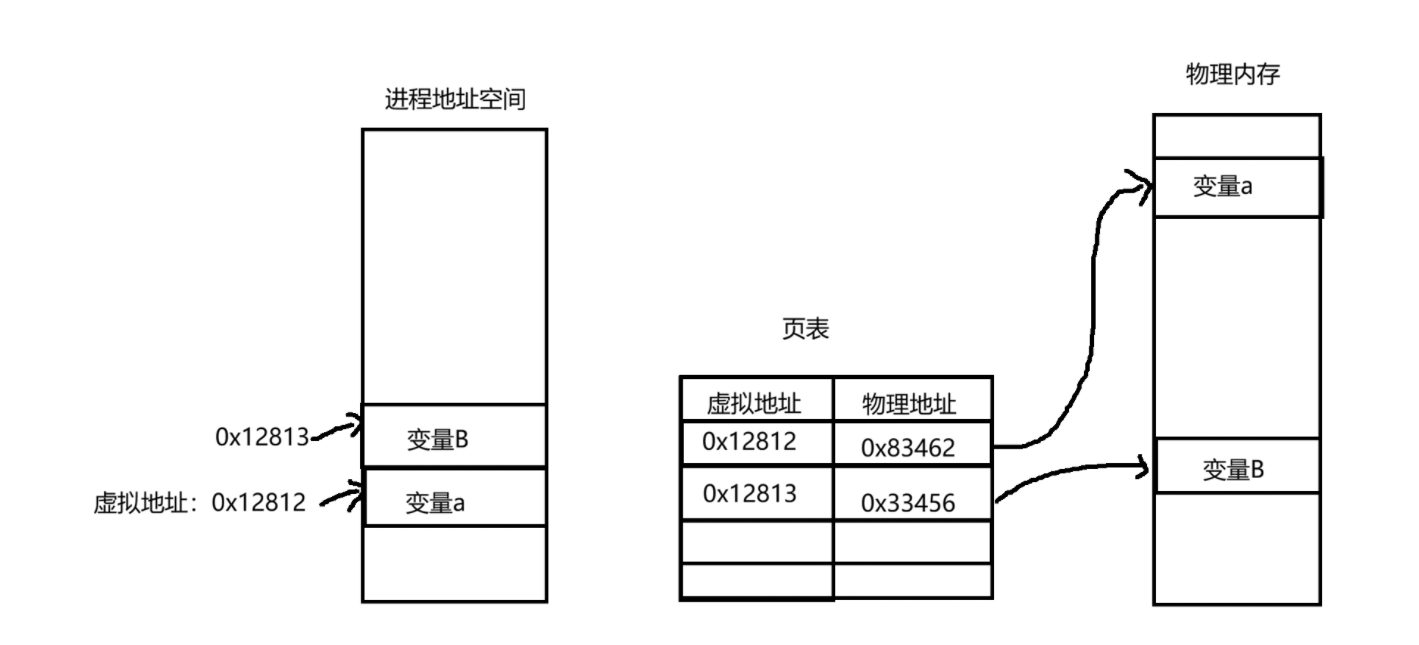
现在就有一个结论,每个进程。都有自己各自的进程地址空间和自己的页表。
这个页表的作用就是能够让虚拟地址映射到真实的物理地址。还有一个重要的作用就是,进程需要连续的4GB空间大小的内存。有了页表的存在,就可以让进程在逻辑上是连续的4GB空间大小(因为有进程地址空间的存在)。在物理上只需要零散的、不连续的空间。
画张图来让大家好理解。
当我们运行一个程序时,如果这个程序体积很大(比如有 2GB),一次性把全部内容都加载到物理内存里,会给系统带来很大的负担。
有了虚拟内存和页表机制,我们就可以采用更高效的方式来处理:
按需启动,只加载必要部分程序启动时,操作系统并不会把整个 2GB 的程序全部塞进物理内存,而是只加载一小部分(比如 1GB)的核心代码和数据,让程序先运行起来。
执行中发现 "缺页"当程序继续执行,需要用到还没加载到内存的代码或数据时,CPU 会去查询页表。如果发现这个虚拟地址对应的物理页不存在(也就是 "缺页"),CPU 就会触发一个缺页中断。
操作系统介入,加载缺失内容操作系统收到缺页中断后,会把程序中缺失的那部分代码或数据从磁盘加载到物理内存的空闲页中,然后更新页表,把这个虚拟地址映射到刚刚加载好的物理页上。
程序继续执行,全程透明映射完成后,程序就可以继续正常执行了。整个过程对程序本身是完全透明的,它完全不知道自己的代码是分批加载的,只需要按虚拟地址访问即可。
现在我们再回头看写时拷贝,就能彻底理解了。
当调用 fork 创建子进程时,子进程一开始会共享父进程的代码和数据,并不会立刻复制一份物理内存。但我们前面讲过:每个进程都有独立的进程地址空间和独立的页表,子进程当然也不例外。
所以操作系统会做两件事:
给子进程创建一份属于自己的进程地址空间;
给子进程创建一份属于自己的页表。
而且这两份东西,都是直接拷贝父进程的。所以子进程的进程地址空间布局和页表内容,一开始和父进程完全一样。
这就导致:父子进程的虚拟地址相同,页表映射也相同,最终指向同一块物理内存。
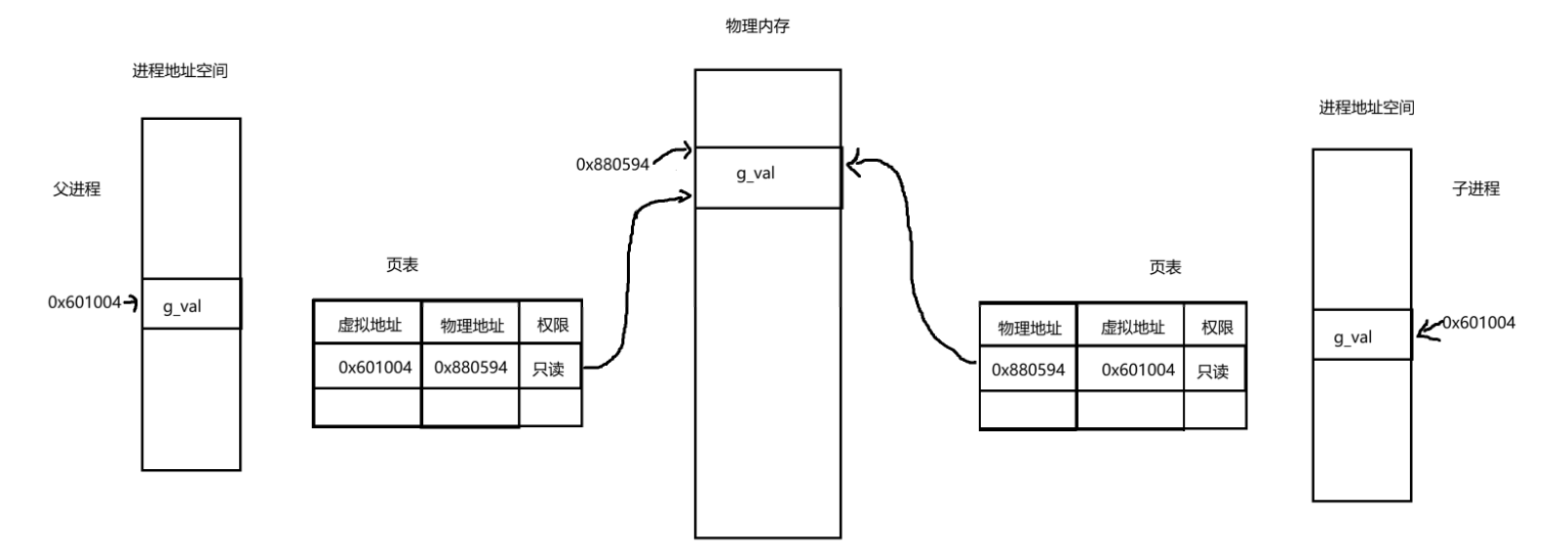
在上面的图中,发现页表中记录着权限。这里的权限是该进程对这个物理地址空间的权限。
子进程共享父进程的数据和代码。当子进程和父进程都没有对这个数据进行修改时。权限都是只读的。当进程要对这个g_val修改时(这里时子进程修改)。操作系统会先把g_val的虚拟地址在页表中查找看看有没有对应的物理地址。这里发现有对应的物理地址。操作系统就尝试对这个物理地址空间里面的内容进行修改。但是修改时发生了权限问题。只有读的权限,没有写的权限。所以此时就发生了写时拷贝。操作系统重新给子进程申请了新的变量g_val。并对这个g_val的值进程修改,然后让子进程的页表修改虚拟地址和物理地址的映射。并且原先对g_val的权限编程可读可写。父进程的对g_val的权限不变。
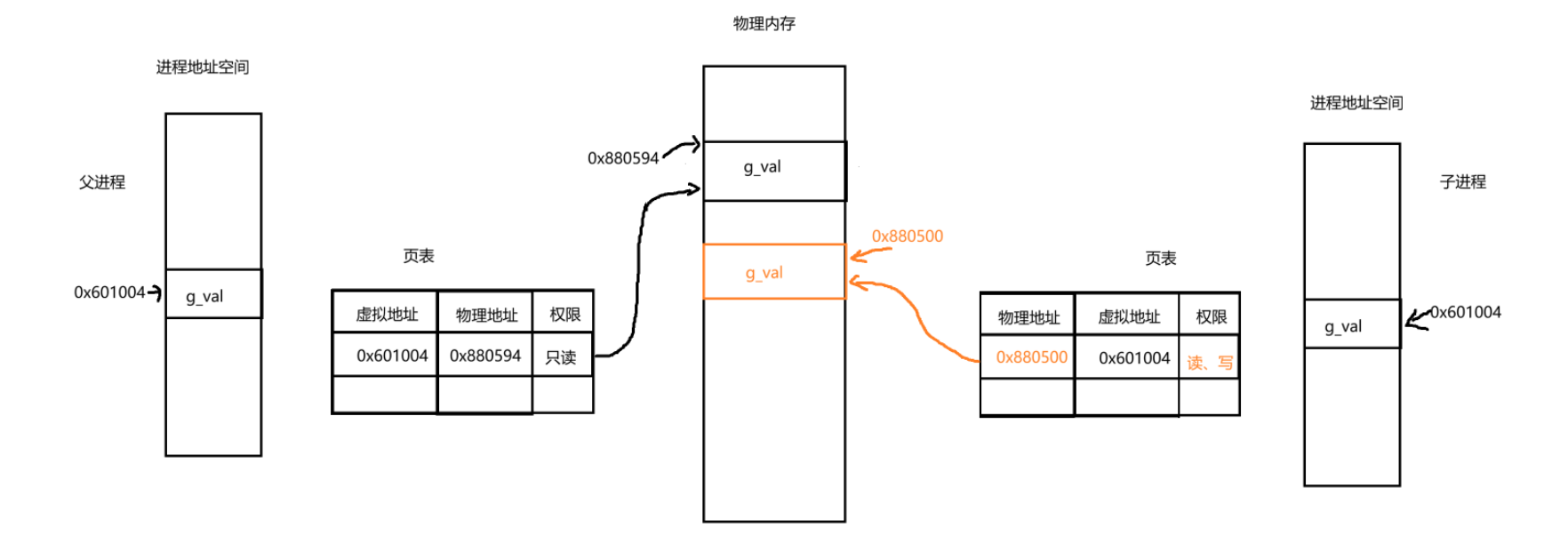
这就是为什么父进程和子进程都对g_val取地址。明明地址是一样的,但是内容却不一样。
现在来大致的讲一下操作系统是这么骗每个进程都有4GB内存空间。
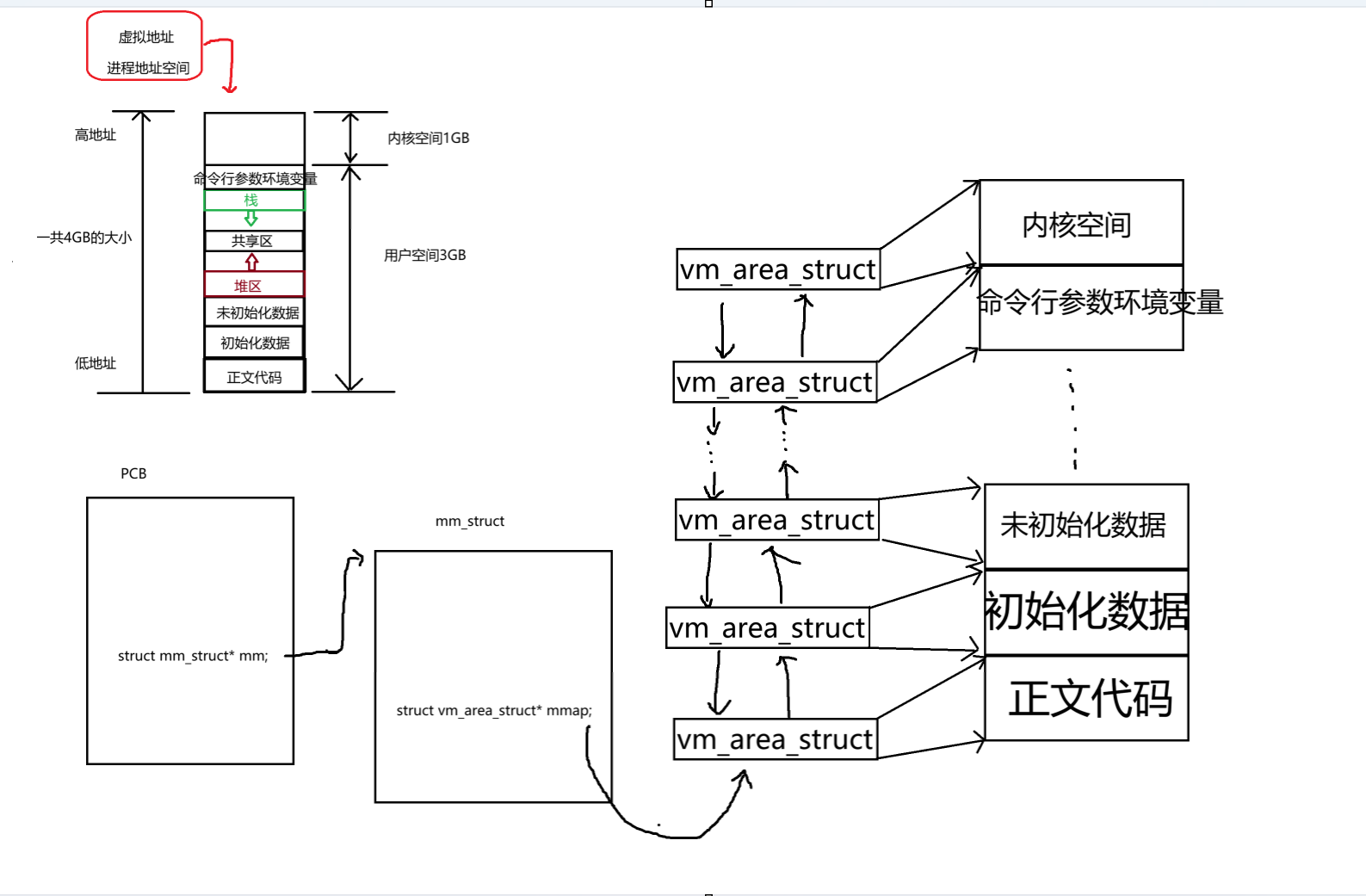
在进程的PCB中,有一个结构体指针
c
struct mm_struct * mm;这个结构体指针指向了一个mm_struct 结构体对象
大致写一下这个结构体的内容
c
struct mm_struct {
// 1. 代码段:进程可执行代码的虚拟地址范围
unsigned long start_code; // 代码段起始虚拟地址(.text 段开头)
unsigned long end_code; // 代码段结束虚拟地址
// 2. 数据段:全局/静态变量的虚拟地址范围
unsigned long start_data; // 已初始化数据段起始(.data 段)
unsigned long end_data; // 已初始化数据段结束
// 3. 堆:动态内存的虚拟地址范围(向上增长)
unsigned long start_brk; // 堆的初始起始地址
unsigned long brk; // 堆的当前结束地址(扩容就是改这个值)
// 4. 栈:函数调用/局部变量的虚拟地址范围(向下增长)
unsigned long start_stack; // 栈的起始地址(高地址,栈顶端)
// 5. 命令行参数/环境变量:栈中特殊区域的虚拟地址
unsigned long arg_start; // 命令行参数起始地址
unsigned long arg_end; // 命令行参数结束地址
unsigned long env_start; // 环境变量起始地址
unsigned long env_end; // 环境变量结束地址
struct vm_area_struct *mmap; // 管理所有虚拟内存区域(VMA)的链表头
};我们先理清一个核心概念:内存地址本质就是给内存空间编的 "数字编号",这个编号本身就是一个整数。
为什么这里要用 unsigned long 来存储这些地址?核心原因很直白:
首先,4GB 内存需要多少个编号?
1 字节的内存需要 1 个编号,4GB = 4 * 1024 * 1024 * 1024 字节 = 2³² 字节,也就是说需要从 0 到 2³²-1 总共 2³² 个编号;
其次,unsigned long 在 32 位系统中正好是 4 个字节(1 字节 = 8 比特,4*8=32 比特),也就是 32 位的无符号整数;
最后,32 位无符号整数的取值范围刚好是 0 ~ 2³²-1,完美覆盖 4GB 内存所需的所有地址编号 ------ 最小值 0 对应最低地址,最大值 2³²-1(也就是 0xFFFFFFFF)对应最高地址。
简单说:unsigned long 的位数和 4GB 地址空间的编号范围完全匹配,用它来存地址,既能装下所有编号,又不会浪费空间。
可能有人会问:为什么不用 int?因为 int 是有符号的 32 位整数,取值范围是 -2³¹ ~ 2³¹-1,最大值只有 2147483647(对应 2GB),根本装不下 4GB 地址的最大值;而 unsigned long 是无符号的,没有负数区间,刚好能把 4GB 地址的所有编号装下。
核心结论:进程把 mm_struct 当成了自己的内存
对进程来说,它完全感知不到物理内存的存在。
进程以为 start_code 到 end_code 之间的所有虚拟地址,都是自己实实在在的代码内存;
以为 start_brk 到 brk 之间的地址,都是自己已分配的堆内存;
以为 start_stack 往下的地址,都是自己独占的栈内存;
哪怕这些地址只是 mm_struct 里的数字,没有对应的物理内存,进程也会坚信 "这些都是我的内存空间"。
简单说:操作系统用 mm_struct 里的虚拟地址边界,给进程构建了一个 "4GB 内存的假象",进程把这个结构体里记录的地址范围,当成了自己真正拥有的内存。
我们发现上面的mm_struct中还有一个结构体指针
c
struct vm_area_struct *mmap;(注:这里就给大家展示vm_area_struct的内容了,本人水平有限,大致讲一下这个结构体的作用)
mm_struct 模拟出了 4GB 虚拟地址空间的 "整体大小和框架",而 VMA (vm_area_struct)则相当于模拟了这个空间里的 "具体区域和内容"。
具体拆解来看:
mm_struct 负责 "模拟框架"它通过 start_code、brk、start_stack 等 unsigned long 类型的字段,划定了 4GB 虚拟空间的整体边界(0 ~ 0xFFFFFFFF),也标记了代码段、堆、栈等大区域的大致范围。对进程而言,这些数值就代表 "我有 4GB 内存可用"------mm_struct 只需要让进程感知到 "空间的大小和整体划分",不用关心每个区域的细节。
VMA 负责 "模拟内容"mm_struct 里的 mmap 指针指向的 VMA 链表,才是填充这 4GB 空间 "具体内容" 的核心:
它把 mm_struct 划定的大框架,拆分成正文代码、初始化数据、堆、栈等一个个具体区域;
给每个区域标记 "能不能读、能不能写、能不能执行" 的属性,甚至定义 "堆向上增长、栈向下增长" 的规则;
哪怕这些区域暂时没有对应的物理内存,VMA 也会先把 "区域的存在和属性" 模拟出来,让进程觉得 "我的 4GB 空间里,这里是代码、那里是堆,都是实实在在的内容"。
举个最直观的例子:进程看到 mm_struct 里的 start_code 和 end_code,只知道 "我有一块代码内存";但看到 VMA 定义的代码段属性,才会觉得 "这块代码内存是只读的、能执行的"------ 前者是 "模拟空间大小",后者是 "模拟空间内容"。
总结
mm_struct 核心作用是模拟 4GB 虚拟空间的 "整体框架和大小",让进程感知到自己拥有完整的内存空间;
VMA 核心作用是模拟这个空间里的 "具体区域和内容",定义每个区域的属性、范围和规则;
二者配合,让进程完全相信自己拥有一块 "有大小、有内容" 的 4GB 内存,这就是操作系统虚拟内存管理的核心 "欺骗" 逻辑。