note
✦ 基于混合结构,397B总参/17B激活,能力匹配 >1T 参数的 Qwen3-Max;
✦ 原生多模态设计,同量级下多模态任务表现优于 Qwen3-VL;
✦ 覆盖 201 种语言;
✦ 在代码生成、智能体推理与多模态理解方面表现卓越;
文章目录
一、Qwen3.5模型
基本信息
- 类型:带视觉编码器的因果语言模型
- 训练阶段:预训练与后训练
语言模型参数
- 参数总量:3970亿
- 激活参数量:170亿
- 隐藏层维度:4096
- Token嵌入维度:248320(已填充)
- 层数 :60
- 隐藏层结构 :
15 * (3 * (门控 DeltaNet -> MoE) -> 1 * (门控注意力 -> MoE))
- 隐藏层结构 :
门控 DeltaNet 模块
- 线性注意力头数量 :
- V(值)头:64
- QK(查询-键)头:16
- 头维度:128
门控注意力模块
- 注意力头数量 :
- Q(查询)头:32
- KV(键-值)头:2
- 头维度:256
- 旋转位置嵌入维度:64
混合专家系统(MoE)
- 专家总数:512
- 激活专家数:10个路由专家 + 1个共享专家
- 专家中间层维度:1024
输出与训练
- 语言模型输出维度:248320(已填充)
- MTP(多步训练策略):采用多步训练
上下文长度
- 原生支持:262,144个token
- 可扩展至:最多1,010,000个token
1、效率优化
在 32k 上下文长度下,Qwen3.5-397B-A17B 的吞吐量达到 Qwen3-Max 的 8.6 倍,同时保持相当的性能表现。这得益于 Next 混合架构的三项关键设计:
- 更高稀疏度的 MoE:单次推理仅激活 17B 参数,按需调用专家模块;
- 门控 DeltaNet 与门控注意力混合机制:兼顾长序列处理速度与推理质量;
- 多 token 预测:单次前向推理预测多个 token,显著提升生成效率
2、泛化能力提升
在同等规模下,Qwen3.5-397B-A17B 超越 Qwen3-VL,得益于三项设计:
- 原生多模态融合:通过训练阶段的早期文本-视觉融合,视觉与语言在统一表征空间中联合学习,提升 GUI 理解、视频分析等跨模态任务的连贯性;
- 多语言覆盖扩展:训练数据覆盖语言从 119 种扩展至 201 种,强化全球用户的语言表达理解;
- 词表扩容至 250k:编解码效率提升 10--60%,尤其改善长尾语言与复杂表达的 tokenization 效果。

3、多模态能力提升
过去的多模态模型通常是:"视觉编码器 + 语言模型"的拼接:图片先被转成特征,再喂给语言模型理解。我们在 Qwen3.5-397B-A17B 训练阶段就把文本和视觉数据融合,让模型在统一的空间里同时学习"看"和"说"。一个模型,端到端,全搞定------从视觉推理、空间定位到 GUI 操作与视频理解,任务连贯性显著提升。
依托覆盖图像、视频、STEM 与 GUI 的多元视觉数据训练,Qwen3.5 在同等规模下超越 Qwen3-VL,真正迈向原生多模态 Agents。
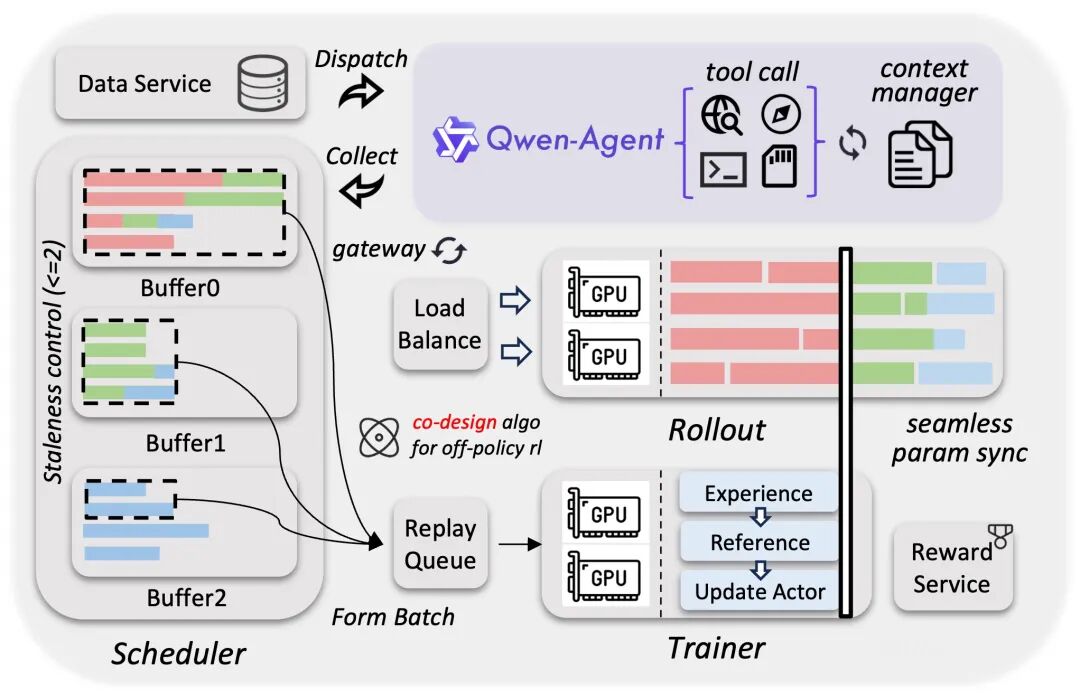
二、LLM infra优化
通过训推分离架构的解耦式设计,该框架显著提升了硬件利用率,实现了动态负载均衡和细粒度的故障恢复。配合 FP8 训推、Rollout 路由回放、投机采样以及多轮 Rollout 锁定等技术,我们进一步优化了系统吞吐,提高了训推一致性。
通过系统与算法协同设计,该框架在严格控制样本陈旧性的基础上有效缓解了数据长尾问题,提高了训练曲线的稳定性和性能上限。
框架面向原生智能体工作流设计,能够实现稳定、无缝的多轮环境交互,消除了框架层的调度中断。这种解耦设计使得系统能够扩展百万级规模的 Agent 脚手架与环境,从而显著增强模型的泛化能力。上述优化最终取得了 3×--5× 的端到端加速,展现了卓越的稳定性、高效率与可扩展性。
Reference
2 https://github.com/QwenLM/Qwen3.5?spm=a2ty_o06.30285417.0.0.72bcc921bSC8dm\&file=Qwen3.5