KServe控制平面负责管理推理服务的生命周期,与Kubernetes API协同工作,处理资源编排,并提供自动扩缩容能力。它作为KServe平台的核心,确保模型服务工作负载能够根据需求正确部署、监控和扩缩容。
在 AI 模型规模化落地的场景中,KServe 作为 Kubernetes 原生的模型推理服务平台,已成为企业级模型部署的主流选择。而传统基于 Ingress 的流量管理方式,存在功能单一、扩展性差、多协议支持不足等问题,难以满足生产环境的复杂需求。本文将深入讲解 KServe + Gateway API 的标准部署模式,从核心概念、实战部署到生产级优化,带你落地一套标准化、高可用、易运维的模型推理服务架构。
一、核心概念:为什么选择 Gateway API 作为 KServe 的流量入口?
在开始部署前,我们先理清两个核心组件的定位,以及 Gateway API 相比传统 NodePort/Ingress 的核心优势。
1. KServe:Kubernetes 原生的模型推理服务平台
KServe 通过自定义资源(CRD)InferenceService封装了模型部署的全生命周期,支持 TensorFlow、PyTorch、SKLearn 等主流框架,可自动完成模型服务的部署、扩缩容、健康检查等操作,让开发者无需关注底层 Kubernetes 资源的配置。
2. Gateway API:Kubernetes 官方标准化流量管理方案
Gateway API 是 Kubernetes SIG-NETWORK 推出的新一代流量管理标准,替代传统 Ingress 资源,通过分层解耦的资源模型(GatewayClass、Gateway、Route)实现更灵活的流量管控,核心优势包括:
- 标准化:统一的 API 规范,适配 Istio、Kong、Nginx Gateway 等主流网关实现;
- 多协议支持:原生支持 HTTP/HTTPS、gRPC、TCP/UDP,完美适配 AI 模型推理的 gRPC 接口;
- 生产级特性:支持跨命名空间路由、流量权重(灰度发布)、TLS 统一终止、多租户隔离;
- 高可用:结合 LoadBalancer 实现故障自动转移,规避 NodePort 的单点故障风险。
3. 为什么不选 NodePort/Ingress?
- NodePort:仅适用于开发测试,存在端口稀缺、无健康检查、无安全防护、运维成本高的问题;
- 传统 Ingress:功能单一,多协议支持差,扩展能力有限,无法满足模型服务的灰度发布、跨命名空间隔离等生产需求。
二、KServe + Gateway API 流量链路全解析
我们拆解外部请求从接入到模型推理的完整链路:
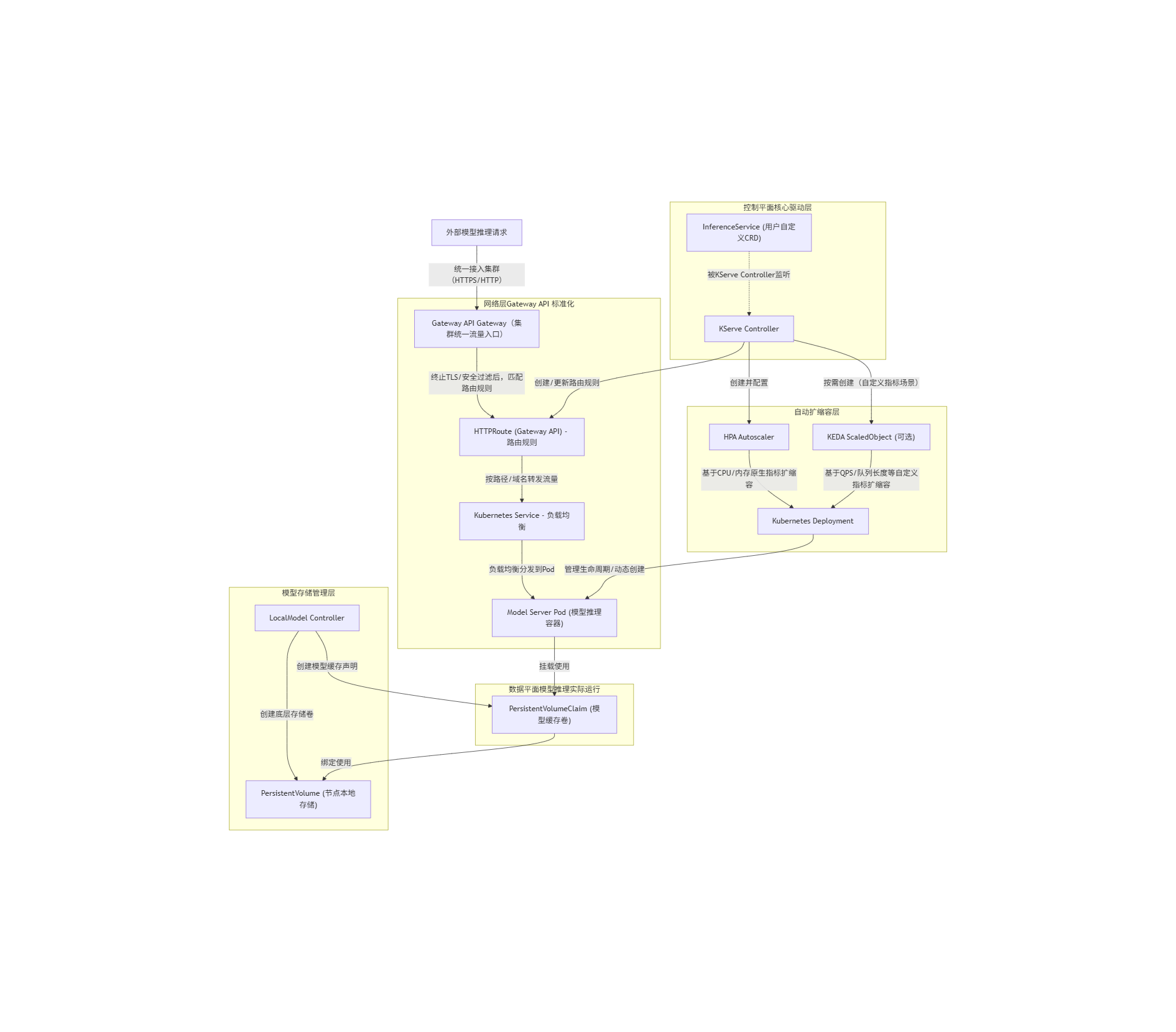
完整流量链路
步骤 1:外部流量接入 Gateway
外部请求(HTTP/HTTPS)通过 Gateway 绑定的 LoadBalancer IP/域名 接入集群(这是集群的唯一流量入口),Gateway 会先做基础的安全处理:
- 若为 HTTPS 请求:Gateway 做 TLS 终止(解密 HTTPS 流量,转为 HTTP 转发给后端,统一管理证书);
- 安全过滤:执行黑白名单、速率限制、WAF 防护等,拦截恶意请求。
步骤 2:Gateway 匹配 HTTPRoute 路由规则
Gateway 接收合法流量后,会匹配集群中关联到自身的 HTTPRoute 资源(由 KServe Controller 自动创建):
- HTTPRoute 定义了精细化路由规则 :比如 "域名
inference.example.com+ 路径/models/mnist" 的流量转发到哪个 Service; - Gateway 会根据请求的域名、路径、请求头(如
Content-Type)等,匹配到对应的 HTTPRoute 规则,确定流量的转发目标。
步骤 3:HTTPRoute 转发流量到 Kubernetes Service
匹配到路由规则后,HTTPRoute 会将流量转发到规则中指定的 Kubernetes Service(KServe 为模型服务自动创建的 Service):
- Service 是后端 Pod 的 "固定访问入口",与 Pod 的动态扩缩容解耦(即便 Pod 数量变化,Service 地址不变);
- 若配置了流量权重(如灰度发布),HTTPRoute 会按权重将流量分发到多个 Service(如 10% 到新版本模型 Service,90% 到旧版本)。
步骤 4:Service 负载均衡转发到 Model Server Pod
Service 收到流量后,通过 kube-proxy 实现负载均衡,将流量均匀分发到后端的 Model Server Pod:
- Service 会自动感知后端 Pod 的健康状态(通过 Kubernetes Endpoint),只转发流量到 "就绪(Ready)" 的 Pod;
- 若 Pod 因 HPA/KEDA 动态扩缩容(比如流量高峰时 Pod 数从 2 个扩到 10 个),Service 会自动更新 Pod 列表,保证流量均匀分发。
补充:Pod 处理请求的最终环节
Model Server Pod 接收流量后,挂载 PVC(模型缓存卷) 加载本地缓存的模型文件,执行推理计算,最终将结果按原路返回给外部请求。
三、KServe + Gateway API 标准部署实战
以下实战基于 Kubernetes 1.24+、Istio 1.18+、KServe 0.11+,以 Istio 作为 Gateway API 的实现,完整落地一套模型推理服务。
前置环境准备
-
确保 Kubernetes 集群已安装 Istio(作为 Gateway API 的实现):
安装Istio(极简版,仅核心组件)
istioctl install --set profile=default -y
为KServe命名空间开启Istio注入
kubectl label namespace kserve istio-injection=enabled --overwrite
-
安装 Gateway API 标准 CRD(所有操作的基础):
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.1.0/standard-install.yaml
验证CRD安装成功
kubectl get crd | grep gateway.networking.k8s.io
-
安装 KServe:
安装KServe核心组件
kubectl apply -f https://github.com/kserve/kserve/releases/download/v0.11.1/kserve.yaml
安装KServe存储控制器(用于模型缓存)
kubectl apply -f https://github.com/kserve/kserve/releases/download/v0.11.1/kserve-storage-init-container.yaml
步骤 1:创建 GatewayClass(绑定 Istio 网关实现)
GatewayClass定义网关的 "实现类型",关联 Istio 控制器:
# gatewayclass.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: istio-gatewayclass
spec:
controllerName: istio.io/gateway-controller
description: "基于Istio实现的GatewayClass,用于KServe模型服务流量管理"执行创建:
kubectl apply -f gatewayclass.yaml步骤 2:创建 Gateway(集群统一流量入口)
Gateway是集群的实际流量入口,绑定 LoadBalancer,配置 HTTP 监听:
# gateway.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: kserve-gateway
namespace: istio-system
spec:
gatewayClassName: istio-gatewayclass
listeners:
- name: http
port: 80
protocol: HTTP
allowedRoutes:
namespaces:
from: All # 允许跨命名空间路由(生产级常用)执行创建并验证:
kubectl apply -f gateway.yaml
# 查看Gateway状态(STATUS为Ready,ADDRESS为LoadBalancer IP)
kubectl get gateway -n istio-system kserve-gateway步骤 3:部署 KServe InferenceService(模型服务)
以 MNIST 手写数字识别模型为例,创建InferenceService:
# kserve-mnist.yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: mnist
namespace: kserve
spec:
predictor:
model:
modelFormat:
name: tensorflow
storageUri: "gs://kfserving-examples/models/tensorflow/mnist"
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "2"
memory: "2Gi"执行创建:
kubectl apply -f kserve-mnist.yaml
# 查看InferenceService状态(READY为True表示部署成功)
kubectl get inferenceservice -n kserve mnist步骤 4:创建 HTTPRoute(路由规则)
HTTPRoute定义流量路由规则,将 Gateway 的流量转发到 KServe 模型服务:
# httproute.yaml
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: kserve-mnist-route
namespace: kserve
spec:
parentRefs:
- name: kserve-gateway
namespace: istio-system # 关联步骤2创建的Gateway
hostnames:
- "inference.example.com" # 访问域名(可自定义)
rules:
- matches:
- path:
type: PathPrefix
value: /v1/models/mnist
backendRefs:
- name: mnist-predictor-default # KServe自动生成的Service名称
port: 8080
weight: 100 # 流量权重(灰度发布时可配置多后端)执行创建:
kubectl apply -f httproute.yaml步骤 5:验证模型服务访问
-
获取 Gateway 的对外访问地址:
GATEWAY_IP=$(kubectl get gateway -n istio-system kserve-gateway -o jsonpath='{.status.addresses[0].value}')
-
发送推理请求(替换为实际的 GATEWAY_IP):
curl -X POST http://${GATEWAY_IP}/v1/models/mnist:predict
-H "Host: inference.example.com"
-H "Content-Type: application/json"
-d '{
"instances": [[[[1.0,2.0,3.0],[4.0,5.0,6.0],[7.0,8.0,9.0]]]]
}'
若返回类似以下结果,说明部署成功:
{
"predictions": [2]
}四、生产级优化配置
1. 配置 TLS 加密(HTTPS)
在 Gateway 层统一做 TLS 终止,只需配置一套证书即可覆盖所有模型服务:
# 改造后的gateway.yaml(添加HTTPS监听)
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: kserve-gateway
namespace: istio-system
spec:
gatewayClassName: istio-gatewayclass
listeners:
- name: https
port: 443
protocol: HTTPS
tls:
mode: Terminate
certificateRefs:
- name: kserve-tls-cert # 集群中已创建的TLS证书Secret
namespace: istio-system
allowedRoutes:
namespaces:
from: All2. 灰度发布(流量权重分配)
通过 HTTPRoute 的weight字段,实现模型版本的灰度发布:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: kserve-mnist-grey-route # 灰度发布路由规则名
namespace: kserve
spec:
# 关联已创建的Gateway(必须与前文Gateway名称/命名空间一致)
parentRefs:
- name: kserve-gateway
namespace: istio-system
# 访问域名(可自定义,需配置本地hosts或DNS解析)
hostnames:
- "inference.example.com"
rules:
- matches:
# 匹配模型推理路径(与KServe模型访问路径一致)
- path:
type: PathPrefix
value: /v1/models/mnist
# 流量权重分配核心配置
backendRefs:
- name: mnist-v1-predictor-default # v1版本Service(KServe自动生成)
port: 8080
weight: 90 # 90%流量转发到v1
- name: mnist-v2-predictor-default # v2版本Service(KServe自动生成)
port: 8080
weight: 10 # 10%流量转发到v23. 自定义指标扩缩容(KEDA)
基于 QPS 等自定义指标,实现更精准的弹性扩缩容:
# keda-scaledobject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: mnist-scaledobject
namespace: kserve
spec:
scaleTargetRef:
name: mnist-predictor-default
minReplicaCount: 2
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-k8s.monitoring.svc:9090
metricName: kserve_inference_requests_per_second
query: sum(rate(kserve_inference_requests_total{service="mnist"}[1m]))
threshold: "100" # QPS超过100时扩容五、总结
KServe + Gateway API 的标准部署模式,是 AI 模型生产级落地的最佳实践,核心优势可总结为:
- 标准化:基于 Kubernetes 官方 Gateway API,摆脱对特定网关的依赖,适配多厂商实现;
- 高可用:Gateway+LoadBalancer 实现全链路健康检查和故障转移,规避单点故障;
- 易运维:统一的流量入口和路由规则,降低多模型服务的管理成本;
- 生产级特性:支持 TLS 加密、灰度发布、弹性扩缩容,满足企业级 AI 模型部署的核心需求。
相比传统的 NodePort/Ingress 方案,该模式在稳定性、安全性、扩展性上均有质的提升,是 KServe 官方推荐的生产级部署方式,也是规模化 AI 模型落地的必经之路。