设计排行榜
没有唯一的最好的技术,只有根据具体的场景来选择(包括需求和成本,也不要因为某一种技术高级就对那个崇拜)
1需求分析
排行榜常见场景:游戏排行榜,商品排行榜,视频排行榜,社交排行榜。
分析排行榜的特点:受到关注的排行榜有着高并发读的需求,同样用户为了竞争排名也有高并发写的需求,用户为了实时看到结果也需要考虑实时性。有的排行榜还需要能做到能以月、周、天、小时甚至分钟为周期滚动排名。所以总结一下:
代码角度的需求:维护读多写多,保障实时性,可以实现周期滚动的一个数据结构。
附加需求:保障更新幂等性,同积分怎么排序。(针对基础的扩展高并发,幂等性,分布式之类的)
2技术选型
mysql的order:不能承受高并发的读写,做不到动态排序滚榜需要每次重新排序很浪费效率。
redis的zset,专业对口底层跳表,按照score规则排序,能接受高并发读写,动态排序保障实时性。缺点是redis的内存比较珍贵,以及存在的大key问题。
所以这里选择呢使用zset来进行排行榜的基本技术栈,他很符合上面的几个需求,而对于滚榜的日榜周榜月榜需求。可以采用多个zset进行多写单读。
对于这里的附加需求:同积分怎么排序,幂等性。
按照排行榜的结构特点,我们需要保障同积分下按照先到的时间在前。但是zset只有score这一个指标,所以想要保证这个可以采取整数部分分数,小数点后用时间戳这种。或者也可以用一些数学公式确保这两个变量的排序优先级。
时间的数学公式:
Scorefinal=Scoreuser+(1−Timestampnow1013)Score_{final} = Score_{user} + (1 - \frac{Timestamp_{now}}{10^{13}})Scorefinal=Scoreuser+(1−1013Timestampnow)
而对于幂等性,在这里可能因为网络波动导致对积分重复加导致不公平,可以很经典的使用redis全局唯一id来保证。
再看redis的一些缺点:
内存比较珍贵,这个没什么好的办法,或者考虑使用rocksdb这种磁盘kv离开村部分节约内存。或者换别的实现方式但是好像没有比这个更适合的了。
对于大key问题,根据具体业务的用户数量和实时性来抉择,这里可以进行消息队列削峰,或者大key的拆分但是还会引出读放大的问题。
综上所述,对于正常的数量少的情况,只考虑使用redis的zset就可以。但是如果公司对安全比较看重就是规定不能出现容器数量达到一定的zset(限制10000)/公司考虑到内存成本及较高且用户群体非常多可能是全民就要考虑别的方案。
另一种可能:
zset理论上限能存储储2^31-1个成员,即大约42亿个。所以只要内存够大存半个地球的用户也可以。
还有不应该主观因为ZSET 存储了几千万个用户排名就武断地认为这会影响Redis的性能。测试经验表明,这个成员数量级的ZSET的性能表现没有明显劣化。至于ZSET存储几亿个成员 时性能表现如何,只能持保留意见,因为这样的需求罕见。
对于上面的热点key也是大key是提出了拆分的方法,但还有读放大的坏处,所以还可以提供一些别的思路作为扩展。
需求进一步分析:
我们先分析排行榜产品的特点。一个几千万人参与的排行榜,前几百名之后的用户会 在乎他是第80001名还是第80002名吗?实际上,这些尾部用户最多会关心其大致排名是 怎样的,当他有朝一日跻身彰显名次的头部位置时,才会对名次和与上一名的差距精打细算。
于是,我们就有了一个初步的想法:前N名用户使用ZSET精确排名,其他用户粗估 排名。现在问题就可以聚焦到如何实现海量用户的粗估排名上了。
对于粗略排名的技术栈的技术选型:
如果放宽对排名精度的要求,那么可以通过分段思想来释放排行榜所需的大量存储空 间:把积分按固定范围分成多个等长的分段,每个分段都保存当前积分处于此分段的用户数量,
可以看到,所谓的粗估排名就体现为假设每个分段中的用户积分都是均匀分布的,所 以分段的长度直接决定了排名的精度,长度越短,精度越高,但是分段数目也越多。
如果分段数目较多,那么从最高分段遍历就不太合适了,这个时间复杂度为O(7V)的 操作会降低查询效率。在这个场景中适合的数据结构是线段树,它以二叉树的形式维护多 个分段,并可以在O(logN)时间内实现数据修改、区间查询等操作。
线段树方案仅使用一个成员极少的Hash对象就实现了排行榜粗估排名,而无视参与 者人数,节约了大量存储空间,可谓是"四两拨千斤"。不过,线段树并不存储每个用户 的具体分数,所以它注定存在如下一些缺点。
缺点:
排名不准确,不能得到具体排名列表。
如果单纯使用线段树方案,则适合全民参与的,且在其他系统中维护积分的场景。比 如QQ等级,由用户登录时间累积得到的太阳、月亮、星星的数量会由专门的等级服务维 护。如果要对QQ的全部用户按照等级排名,并为每个用户展示其排名,那么就很适合使 用线段树方案。
那么在这种结合下,可以采用前部分排名靠前的具体排名和后半部分粗略排名的结合设计:
比如排行榜可以展示前 10000名用户的列表,对于10000名以后的用户,并不展示其排名的前面、后面都有哪些 人,只告诉其名次是多少即可。所以,实现超长排行榜的终极解决方案是ZSET精确排名 与线段树粗估排名的结合,前者负责维护前10000名用户的详细排名和排行榜列表,后者负责展示每个用户,尤其是10000名以后的用户的粗估排名。不过,由于线段树无法存储 用户积分,所以需要使用额外的系统来做这件事情,比如计数服务。
(粗略部分用线段树导致排名靠后的用户想要具体排名就得用计数服务)
3具体设计
纯zset:
这种只负责一个具体的功能的就说下对外暴漏的接口吧:
更新分数接口:UpdateRanking
获取榜单列表接口:GetRankingList
查询个人排名接口:GetRank
其中大部分都靠第二个来完成
zset+粗略排名
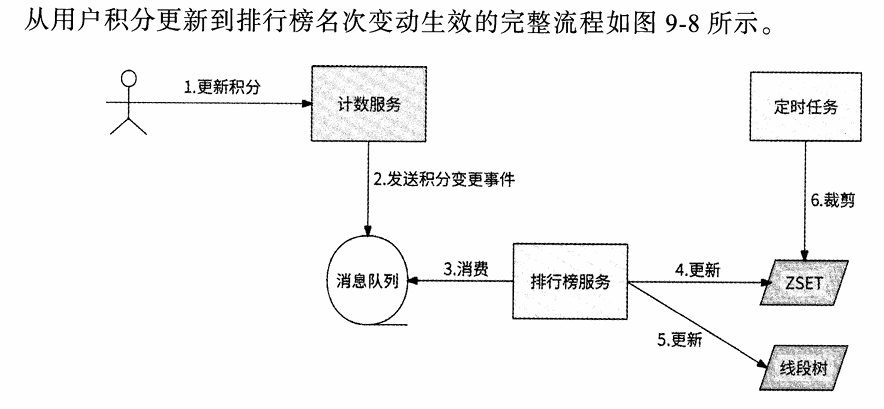
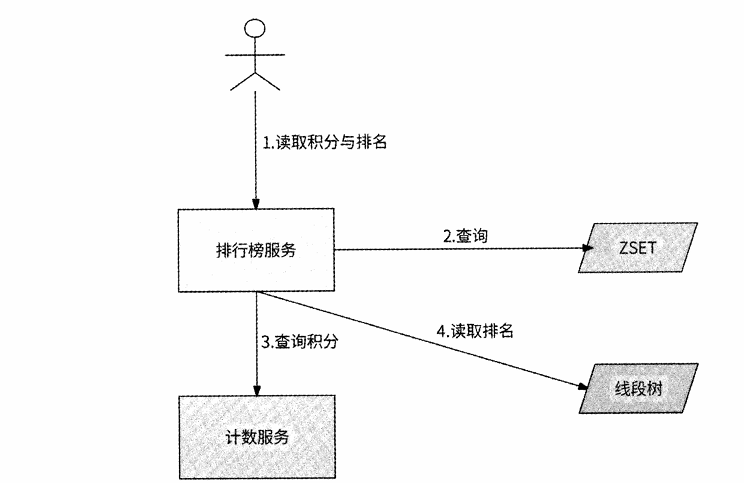
这种方案能节约很大的内存,且不害怕大key问题,部落需要依赖于计数服务。
4该怎么选
(在满足的技术选型有多种,且不同需求有不同的选择时就会写这个,不要因为某一种高级就偏向于某一种,还是要结合具体需求)
绝大部分公司只需要排行榜这个功能:zset
用户涉及到全民排行榜/公司严格限制zset容器数量:zset+粗略排名(可以是线段树,也可以是别的)
选择 ZSet 的标准线:
- 内存预算: 一个存储 1000 万用户(UserID 为 long, Score 为 double)的 ZSet 大约占用 1GB 到 1.5GB 内存。如果你的榜单有 100 个(日榜、周榜、各种活动榜),内存成本就是百 GB 级别。
- 运维红线: 大多数互联网公司内部规范建议单个 ZSet 成员不要超过 50 万 - 100 万 。超过这个数,建议**分桶(Sharding)*或者采用你的*线段树方案。
如果有涉及掉这些就考虑后者。
而对于之前说的rocksdb,可以考虑作为冷热数据分离的冷,或者作为底层全量库,redis作为topn的缓存层。
总之,这里只是讲很多可能性和思路,具体还是要根据用户量和需求来做具体的选择,不然都是空谈。