1.列表
list
python的列表 用起来和C++的vector很相似 是数组
只不过C++的vector每个元素是一样的
但是python列表每个元素可以是不一样的
python
# 创建空列表的两种方式
alist = []
alist = list()
print(type(alist))
# 创建带初始值的列表并打印
alist = [1, 2, 3, 4]
print(alist)
# 正向下标和负向下标访问
alist = [1, 2, 3, 4]
print(alist[3])
print(alist[-1])但是和vector不同的是列表是可以执行切片操作
Python 切片遵循「左闭右开」(左包含,右不包含)
python
# 1. 切片操作的基本使用
# a = [1, 2, 3, 4]
# print(a[1:3])
# 2. 使用切片的时候,省略边界.
a = [1, 2, 3, 4]
# 省略后边界,意思是从开始位置,一直取到整个列表结束.
print(a[1:])
# 省略前边界,意思是从列表的 0 号元素开始取,一直取到结束的后边界.
print(a[:2])
# 此处切片中的下标也可以写成负数.
print(a[:-1])
# 还可以把开始边界和结束边界,都省略掉!得到的还是列表自身.
print(a[:])
# 3. 带有步长的切片操作.
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[::1])
print(a[::2])
print(a[1:-1:2])
# 4. 步长的数值还可以是负数. 当步长为负数的时候, 意思是从后往前来取元素.
print(a[::-1])
print(a[::-2])
# 5. 当切片中的范围超出有效下标之后, 不会出现异常! 而是尽可能的把符合要求的元素给获取到.
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[1:100])
python
# 1. 使用 for 循环遍历列表
alist = [1, 2, 3, 4]
for elem in alist:
print(elem)
# 2. 使用 for + range 按下标遍历
alist = [1, 2, 3, 4]
for i in range(0, len(alist)):
print(alist[i])
#//上面两种方法的区别是一种可以改变数组的值 一种不可以
# 3. 使用 while 循环手动控制下标遍历
alist = [1, 2, 3, 4]
i = 0
while i < len(alist):
print(alist[i])
i += 1
# 4. 使用 append 方法向列表末尾添加元素
alist = [1, 2, 3, 4]
alist.append('hello')
print(alist)
# 5. 使用 insert 方法向指定位置插入元素
alist = [1, 2, 3, 4]
alist.insert(1, 'hello')
print(alist)
python
# 1. insert 插入元素(下标越界时插入到末尾)
a = [1, 2, 3, 4]
a.insert(1, 'hello')
a.insert(100, 'hello')
print(a)
# 2. in / not in 判断元素是否存在
a = [1, 2, 3, 4]
print(1 in a)
print(10 in a)
print(1 not in a)
print(10 not in a)
# 3. index 获取元素下标(不存在则报错)
a = [1, 2, 3, 4]
print(a.index(2))
print(a.index(3))
# print(a.index(10)) # 找不到不会返回-1 而是抛异常
# 4. pop 删除元素(无参删末尾,有参删指定下标)
a = [1, 2, 3, 4]
a.pop()
print(a)
a = [1, 2, 3, 4]
a.pop(1)
print(a)
# 5. remove 按值删除元素
a = ['aa', 'bb', 'cc', 'dd']
a.remove('cc')
print(a)
# 6. + 拼接列表(生成新列表)
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
c = b + a
print(c)
print(a)
print(b)
# 7. extend 拼接列表(修改原列表,返回 None)
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
c = a.extend(b)
print(a)
print(b)
print(c)extend方法,其实是没有返回值的!! 拿一个变量来接收一个没有返回值的方法的返回值
得到的旧是None
None类似于C++中的nullptr 和null
2.元组
元组和列表的核心区别在于
核心区别:列表可变(可增删改),元组不可变(创建后不能改);
python
# 1. 创建元组
a = ()
print(type(a))
b = tuple()
print(type(b))
# 2. 创建元组的时候,指定初始值
a = (1, 2, 3, 4)
print(a)
# 3. 元组中的元素也可以是任意类型的
a = (1, 2, 'hello', True, [])
print(a)
# 4. 通过下标来访问元组中的元素,下标也是从 0 开始,到 len - 1 结束
a = (1, 2, 3, 4)
print(a[1])
print(a[-1])
# print(a[100]) # 此行会抛出 IndexError
# 5. 通过切片来获取元组中的一个部分
a = (1, 2, 3, 4)
print(a[1:3])
# 6. 也同样可以使用 for 循环等方式来进行遍历元素
a = (1, 2, 3, 4)
for elem in a:
print(elem)
# 7. 可以使用 in 来判定元素是否存在,使用 index 查找元素的下标
a = (1, 2, 3, 4)
print(3 in a)
print(a.index(3))
# 8. 可以使用 + 来拼接两个元组
a = (1, 2, 3)
b = (4, 5, 6)
print(a + b)
# 10. 当进行多元赋值的时候,其实本质上是按照元组的方式来进行工作的
def getPoint():
x = 10
y = 20
return x, y # 等价于 return (x, y)
x, y = getPoint()
print(type(getPoint())) # 注意:这里打印的是函数类型,若要打印返回值类型,需调用函数:print(type(getPoint()))这些是元组不支持的
3.字典
dict
字典和C++的unordered_map很类似
一个字典中的 key 的类型不一定都一样。
一个字典中的 value 的类型也不必都一样~
字典对于 key 是啥类型,有约束......
对于 value 是啥类型,没约束~
判断这个类型能否作为key
可以用hash这个函数判断是否可以哈希
python
# 1. 创建字典
a = {}
print(type(a))
b = dict()
print(type(b))
# 2. 创建字典的同时设置初始值
a = {'id': 1, 'name': 'zhangsan'}
a = {
'id': 1,
'name': 'zhangsan',#最后一个,写不写都可
}
# 3. 使用 in 来判定某个 key 是否在字典中存在
a = {
'id': 1,
'name': 'zhangsan'
}
print('id' in a)
print('classId' in a)
# in 只是判定 key 是否存在,和 value 无关!
print('zhangsan' in a)
# not in 来判定 key 在字典中不存在
print('id' not in a)
print('classId' not in a)
# 4. 使用 [] 来根据 key 获取到 value
a = {
'id': 1,
'name': 'zhangsan',
100: 'lisi'
}
print(a['id'])
print(a['name'])
print(a[100])
# print(a['classId']) # 此行会抛出 KeyError
# 5. 在字典中新增元素,使用 [] 来进行
a = {
'id': 1,
'name': 'zhangsan'
}
# 这个操作就是往字典里插入新的键值对
a['score'] = 90
print(a)
# 6. 在字典中,根据 key 修改 value,也是使用 [] 来进行的
a['score'] = 100
print(a)
# 7. 使用 pop 方法,根据 key 来删除键值对
a.pop('name')
print(a)
# 8. 遍历字典
# for key in a:
# print(key, a[key])
# print(a.keys())
# print(a.values())
# print(a.items())
for key, value in a.items():
print(key, value)keys 获取到字典中的所有 key
values 获取到字典中的所有 value
items 获取到字典中的所有键值对
这三个函数返回的结果是不同的自定义类型
4.文件
python
# 使用 write 来实现写文件的操作
f = open('d:/Python环境/test.txt', 'w')
f.write('hello')
f.close()
# 写文件的时候,需要使用 w 的方式打开。如果是 r 方式打开,则会抛出异常。
# f = open('d:/Python环境/test.txt', 'r')
# f.write('world')
# f.close()
# 1. 使用 read 来读取文件内容。指定读几个字符。
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
result = f.read(2)
print(result)
f.close()
# 2. 更常见的需求,是按行来读取~~
# 最简单的办法,直接 for 循环。
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
for line in f:
print(f'line = {line}', end='')
f.close()
# 3. 还可以使用 readlines 方法直接把整个文件所有内容都读出来,按照行组织到一个列表里。
f = open('d:/Python环境/test.txt', 'r', encoding='utf8')
lines = f.readlines()
print(lines)
f.close()要注意一点我们要关注我们读的时候以什么encoding方式读取 要和文件的一致
Python 有一个重要的机制,垃圾回收机制 (GC),自动的把不使用的变量,给进行释放~
虽然 Python 给了我们一个后手,让我们一定程度的避免上述问题,但是也不能完全依赖,自动释放机制~~因为自动释放不一定及时
上下文管理器起到的效果:
当 with 对应的代码块执行结束,就会自动执行 f 的 close() 方法,无需手动调用。
类似C++的智能指针
5.IO
python
input(prompt=None)
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)prompt:可选参数,是显示在控制台的提示文字,告诉用户该输入什么;
返回值:字符串(str 类型)。
*objects:要输出的一个或多个内容(可以是任意类型:字符串、数字、列表、字典等);
sep:多个内容之间的分隔符,默认是空格;
end:输出结束后添加的字符,默认是换行符 \n(所以每次 print 都会换行);
其他参数(file/flush):新手暂时不用关注,主要用于输出到文件等进阶场景。
看起来可能有点麻烦但是用起来真的很简单
此外
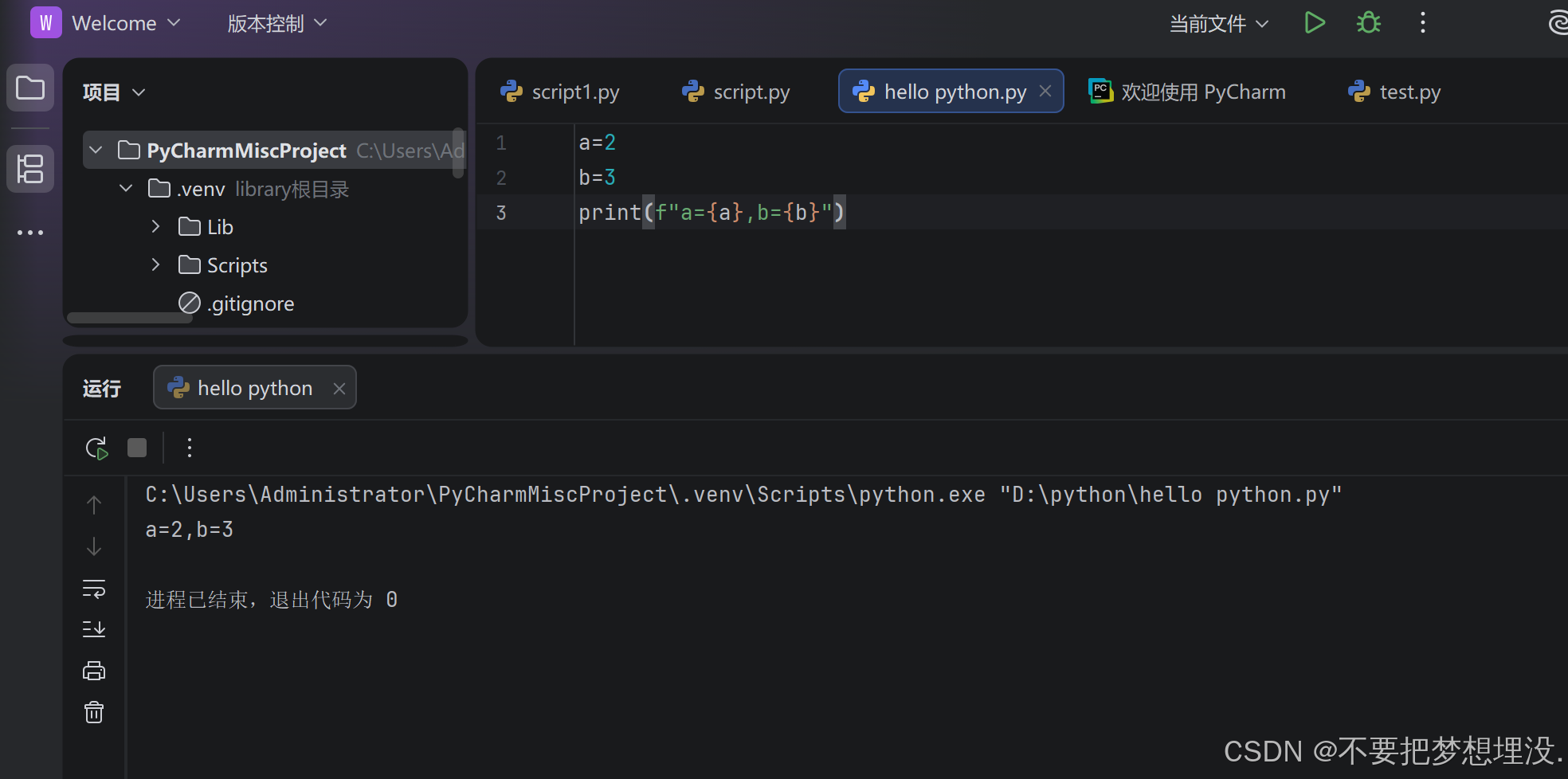
f-string 的本质是「格式化字符串字面量」,f 是一个修饰符,只能作用在被引号包裹的字符串上。如果没有引号,Python 无法识别这是字符串,会直接报语法错误:
语法:在字符串的引号前加 f 或 F,然后用 {} 包裹变量、表达式,就能把它们嵌入到字符串里。
优势:比 % 格式化和 str.format() 更直观、性能更好,代码可读性也更高。
f-string类似C++的占位符 比如%d %s等等