MiniCPM-o 4.5 这两天在开源圈很热:OpenBMB / 面壁智能把一套"看图/看视频 + 听 + 说 + 文本输出"的端到端多模态模型 开源出来,参数量 9B,但主打能力不是"更大更强",而是更工程化的三件事:实时流式交互、边听边说(不是对讲机式一问一答)、端侧友好部署。官方仓库把它描述为面向视觉、语音与"全程流式"的 Omni 模型。
目录
-
这次开源到底"新"在哪
-
"边听边说"到底是什么意思
-
为什么 9B 还能做多模态:关键工程拼图
-
你怎么用:从在线体验到本地部署
-
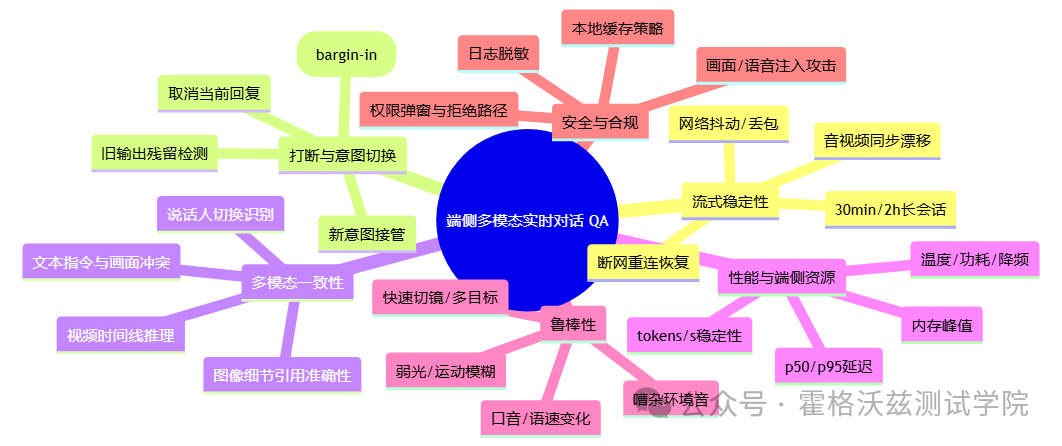
对软件测试/QA 的价值:测试对象升级了
-
可直接复用的测试清单
1. 这次开源到底"新"在哪
一句话:它把"多模态 + 实时对话 + 端侧部署"做成了可落地的一整套工程路径,而不是"论文里能跑"。
你能从官方信息里看到几个硬点:
-
GitHub 官方仓库明确写了 2026-02-03 开源 MiniCPM-o 4.5,并强调"full-duplex multimodal live streaming"(持续输入与持续输出同时进行)。
-
Hugging Face 模型卡强调了实时语音对话、多模态能力与功能点。
-
官方提供了可直接体验的 Demo(Hugging Face Space)。
-
生态适配也很积极:Ollama 等分发页直接写了"实时连续音视频输入 + 同时生成文本与语音输出"。
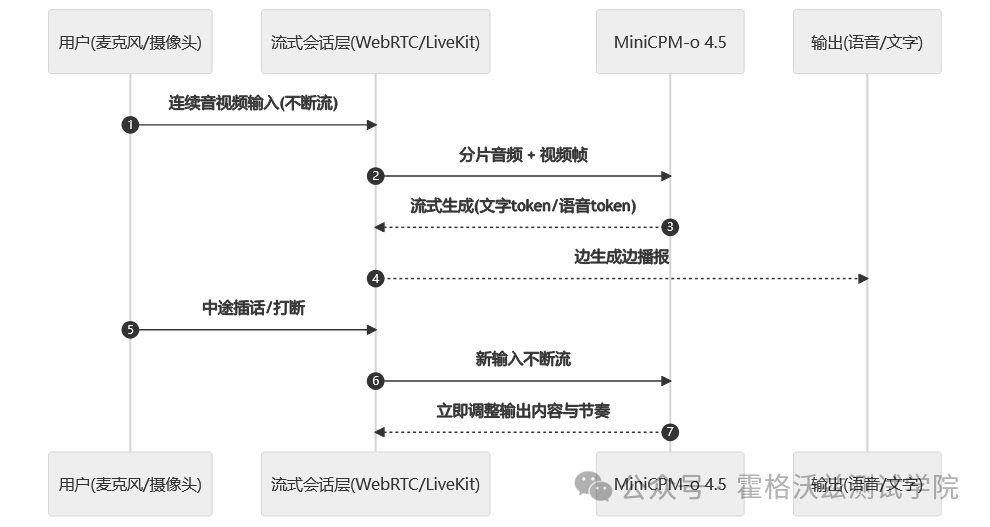
2. "边听边说"到底是什么意思
很多语音助手其实是"对讲机模式":你说完一句 → 它再回一句。 MiniCPM-o 4.5 主打的不是这个,它更像真人交流:它在输出语音的同时,仍然持续接收新的音/视频输入。你可以插话、打断、改口,它需要能立刻调整回应(而不是"等我说完你再来")。
工程上这意味着三类新难点会被强行暴露出来:
-
输入输出不能互相阻塞:输出语音时,摄像头/麦克风输入流 reminding 不能停。
-
中途打断要能"刹车+换挡":停止旧输出、切换新意图、避免继续胡说八道。
-
时间对齐变成关键指标:视频帧、音频片段、文本指令要对齐,否则就会"听到 A 回答 B"。
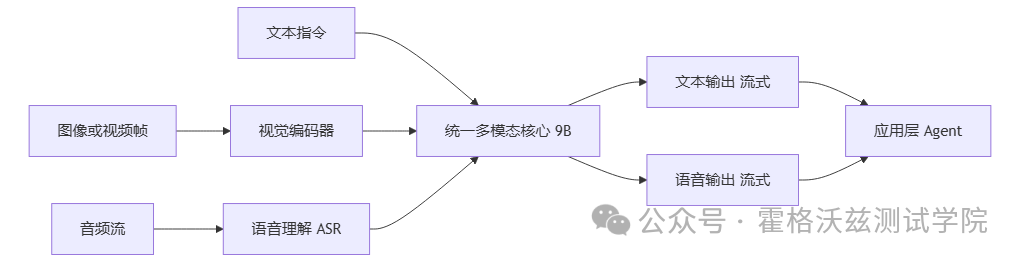
3. 为什么 9B 还能做多模态:关键工程拼图
你可以把它理解成"一个统一调度的多模态系统",而不只是"语言模型外面挂几个插件"。官方仓库把它定位为面向视觉、语音与实时流式的 Omni 模型。
其中对落地最关键的拼图之一,是 llama.cpp-omni 这条路线:它明确写了"full-duplex streaming mechanism"(输入流:视频+音频;输出流:语音+文字;互不阻塞),并把模型拆成 GGUF 模块去跑本地推理。
4. 你怎么用:从在线体验到本地部署
想"先感受一下":
- 直接打开官方 Demo(浏览器授权麦克风/摄像头即可)。
想"落到本地/内网":
-
按官方路线走(模型卡 + 仓库指引),结合你们已有推理框架选择 vLLM / SGLang / Ollama / llama.cpp 等路线。
-
如果你们目标是端侧/本地低延迟,llama.cpp-omni 这条流式实现值得重点关注。
5. 写在最后
对测试同学来说,这类模型最关键的变化是:
被测对象从"回合制对话接口"升级为"实时流系统"。
以前测大模型,很多团队是:喂一段文本 → 看一段输出 → 做断言。 现在要测的是一整套"持续输入、持续输出、可被打断、跨模态对齐"的系统行为。
你会立刻多出一批新的核心测试面:
-
流式稳定性:长时间会话是否丢帧、卡顿、音视频不同步、延迟飘。
-
打断与恢复:插话后能否立刻停旧回新;会不会"前半句说 A、后半句接着说 B"。
-
多模态一致性:同一段画面+音轨+指令,结论是否自洽,是否能正确引用画面细节。
-
端侧性能波动:p95 延迟、功耗、温度、内存峰值、降频后的体验退化曲线。
-
安全与合规:权限、缓存、日志脱敏、提示注入(尤其是"通过画面文字/语音指令注入")。
这也是为什么说"难点在流":能力很炫,但 QA 的工作量会更像测实时音视频系统 + 智能决策系统的组合。
6. 可直接复用的测试清单