2026年,Dest1ny重新归来,冲击5000粉丝!
所以今年Dest1ny充满诚意,真的从0到1去认真写一下这个专题,希望真的可以帮助到各位师傅。
寒冬真来了嘛?我觉得危险和机遇并存的阶段来了,学习大模型一定是可以在未来的工作生涯帮助到你的。
也欢迎评论区留言,告诉Dest1ny关于大模型,你们想知道什么?我后面打算跟大家一起去写一个打CTF的智能体!
都是0基础,大家一起来学吧!!
0x01 引言:当二进制遇见 Transformer
在传统的网络安全攻防中,我们习惯了与规则(Rules)和特征(Signatures)打交道。无论是 WAF 的正则拦截,还是杀软的静态扫描,本质上都是在"已知的威胁"中寻找模式。然而,当 CTF 题目变得越来越复杂、内存漏洞的利用链越来越隐蔽时,传统的自动化工具开始显得力不从心。
2023 年以来,大语言模型(LLM)的爆发为安全领域注入了新的变量。但这是否意味着在CTF比赛中,我们只需要把题目丢给 ChatGPT 就能拿到 Flag?答案是否定的。本专题将深入探讨如何构建一个真正的"安全大模型机器人",而第一站,Dest1ny要跟大家彻底解构大模型在安全语境下的基本概念。
0x02 大模型的底层黑盒:不仅是概率预测
1. Token:安全语料的"颗粒度"
大模型不读文字,它处理的是 Token。在通用语境下,"Security"是一个 Token,但在安全领域,我们经常面对的是十六进制流量:\x41\x41\x41\x41。
如果模型的分词器(Tokenizer)不够强,它会将这段溢出 Payload 识别为一串乱码,从而丢失语义。
- 深度解析:高质量的安全模型必须在预训练阶段见过大量的汇编代码、Base64 编码和混淆后的脚本,才能在处理 CTF 题目时保持"敏感度"。
所以如果你看 大模型的token计费表,你会发现 输出 Token 通常比输入贵 3-5 倍。
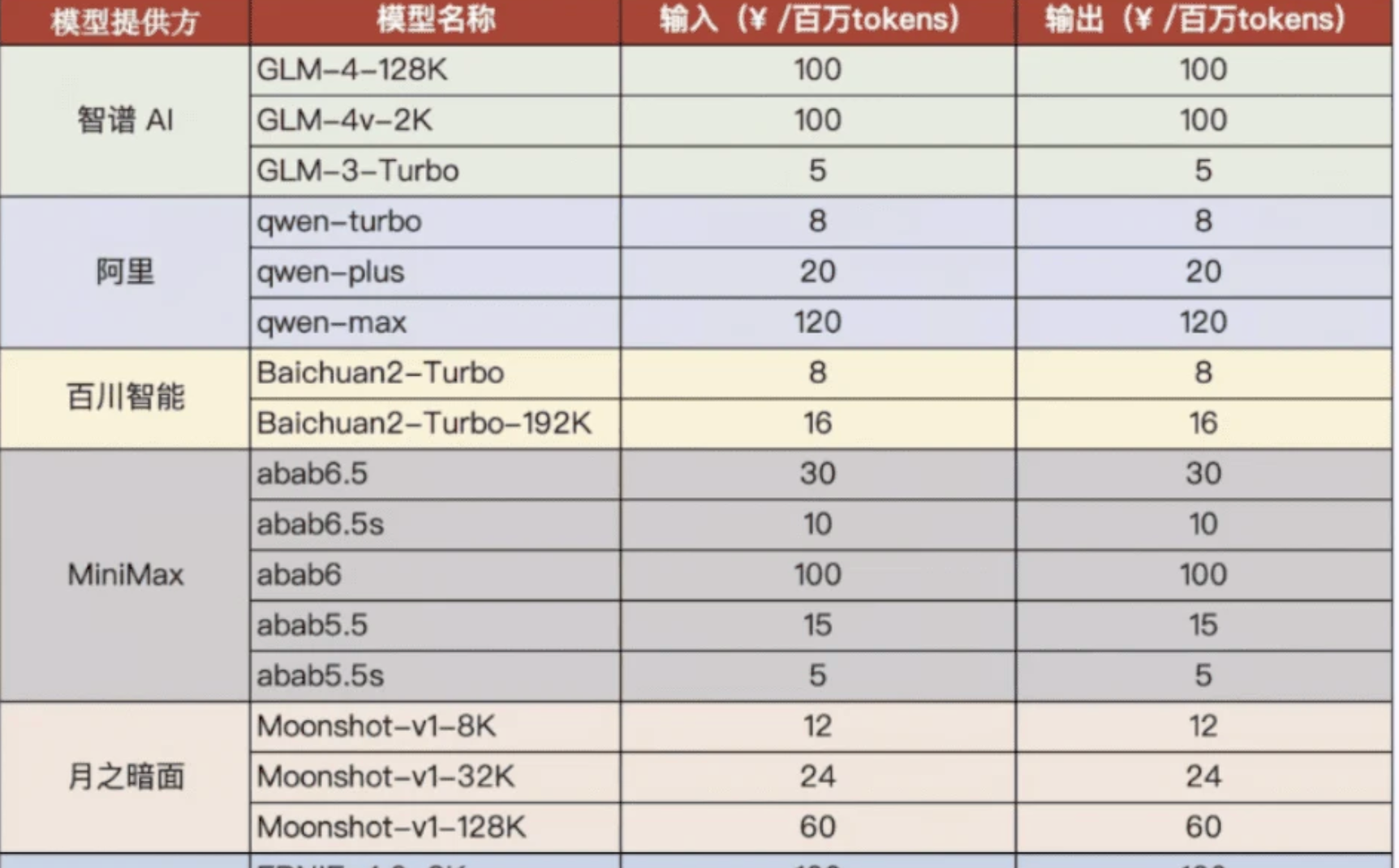
-
输入(Input)是并行的:AI 读你的 1000 字资料时,可以"一目十行",一次性把这些数据塞进内存,计算压力相对较小。
-
输出(Output)是串行的:AI 写代码时是"一个字一个字"蹦出来的。每写一个字,它都要把之前写的所有内容重新扫一遍,再预测下一个字。这就像写论文,读文献很快,但自己动笔写每一行都要绞尽脑汁。
所以如果我们后面需要去跑一个CTF的大模型,肯定是需要去注意这一点的,没有意义的token消耗我们肯定是要避免的,因为你如果一个签到题跑一下token烧一大堆,那成本问题就可以直接宣布这个模型的失败。
2. Transformer 的"上帝视角"
大模型之所以能看懂逻辑,靠的是 Attention(注意力机制)。
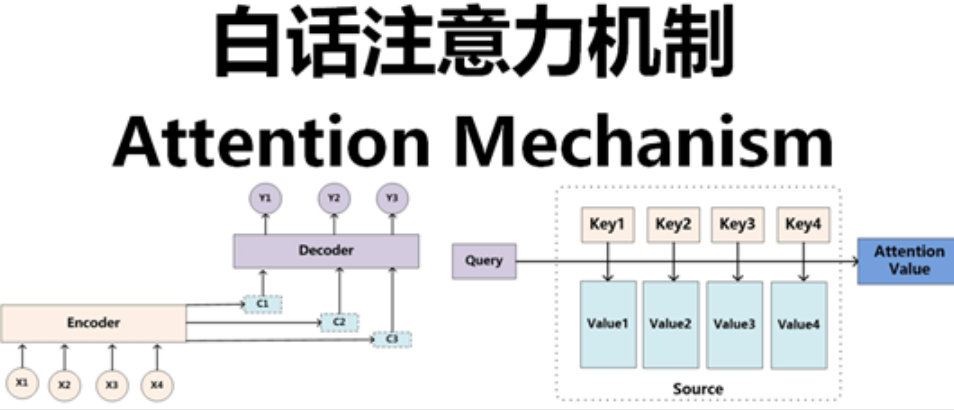
在分析一个 C 语言源码的缓冲区溢出漏洞时,模型不仅在看 strcpy 这个函数,它同时在"注意"栈帧的分配、全局变量的定义以及输入流的来源。这种跨行、跨文件的关联能力,是以往静态分析工具(SAST)难以企及的。
所以我们会发现,其实很多时候,AI只是再模拟人的一种思考方式和行为,只是人的大脑是有限的,AI可以将这些思考方式和行为无限加强,所以人的大脑里的神经网络也是可以被算法给模拟出来的,原理在这里不讲,我们聚焦业务需求这一块。
0x03 为什么通用 AI 做不了"老练"的黑客?
尽管 GPT-4 或 Gemini 3 Pro 极其聪明,但在 CTF 赛场上,它们往往表现得像个"理论派"。
1. 知识的"半衰期"
安全领域的知识更新速度极快。一个新的内核提权漏洞从发布到被修补可能只有一周。大模型的预训练数据通常有半年的滞后期,这导致它在面对最新的 CTF 题型时,只能凭借旧知识"盲目猜测"。
2. 安全过滤的"紧箍咒"
为了合规,主流大模型都内置了强烈的拒绝机制。当你询问:"如何编写一个针对某 CMS 的反序列化 Exp?"AI 往往会回复:"对不起,我不能协助进行攻击性活动。"
解决之道 :这就引出了为什么我们要研究一些开源安全模型,或者通过 RAG 来绕过这种"道德审查",将任务定义为"安全教育与研究"。
但是也衍生出了一个安全问题,如果是一个商用大模型无底线的输出了一些敏感信息,这也是一个极大的安全隐患,又或者说我们如何jailbreak大模型,证明它有漏洞呢?
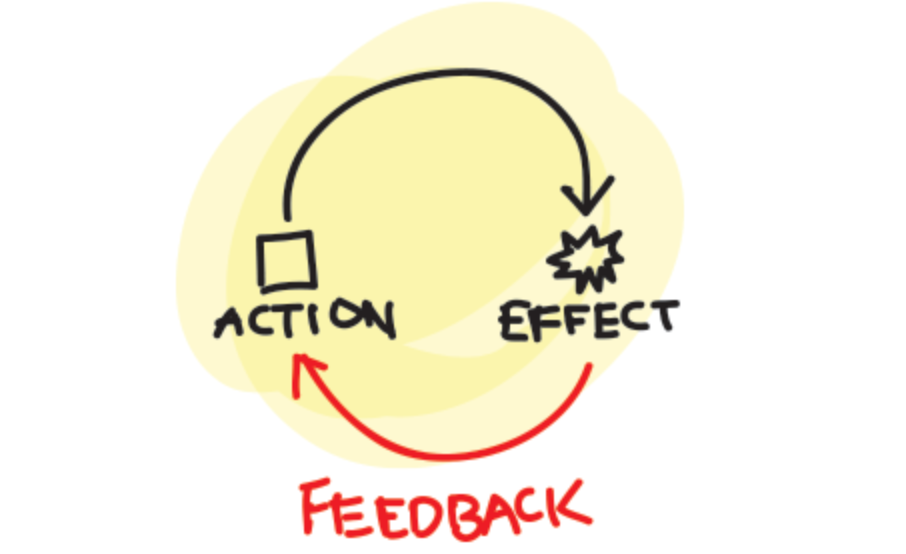
3. 精度迷思:偏移量的 1 字节生死线
大模型是基于概率生成的,但在 Pwn 题中,返回地址(Return Address)错了一个字节,程序就会直接 Crash。AI 经常会给出"大概正确"的思路,但给出的代码往往跑不通。这就是为什么我们需要反馈循环(Feedback Loop)。
0x04 RAG:给机器人插上"记忆卡"
检索增强生成(RAG, Retrieval-Augmented Generation) 是我们后面项目的核心技术。
1. 什么是 RAG?
如果说大模型是 AI 的"大脑",那么 RAG 就是它的"图书馆"。
-
传统模型:靠记忆考试。
-
RAG 模型:带着所有 CTF 题解、PDF 教材、工具手册进场,开卷考试。
2. 向量化(Embedding)的技术细节
我们将 PDF 资料转为 Markdown 后,需要通过 Embedding 模型将其映射到多维空间中。每一段知识都是空间中的一个点。
当用户提问时,系统会计算问题向量与知识块向量之间的余弦相似度。
通过数学公式,AI 可以在毫秒级时间内,从数百万字的资料中精准定位到那一段"绕过某特定 WAF 的正则技巧"。
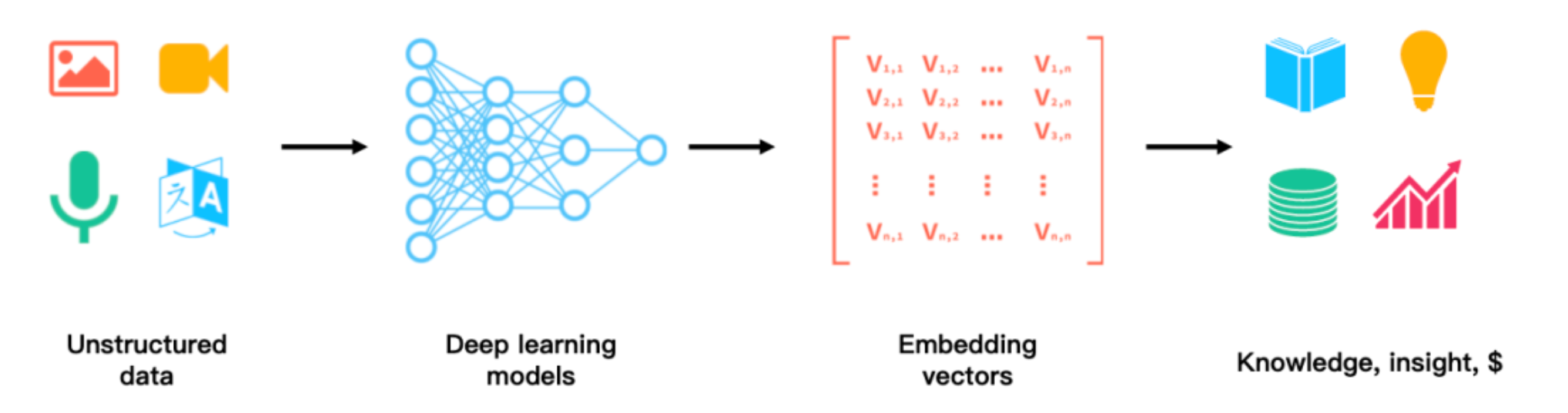
简单来说,将数据全部数字化,变成AI方便去对比和搜索的标记,举个例子:
想象一个三维坐标系 (x, y, z)。我们给词语定义三个维度:是否属于计算机 、是否属于生物 、是否具有攻击性。
"木马病毒":坐标可能是 (0.9, 0.1, 0.8) ------ 高度属于计算机,不属于生物,攻击性强。
"流感病毒":坐标可能是 (0.1, 0.9, 0.7) ------ 不属于计算机,高度属于生物,攻击性强。
"杀毒软件":坐标可能是 (0.9, 0.1, 0.1) ------ 高度属于计算机,不属于生物,攻击性弱。
当 AI 计算时,它会发现"木马"和"杀毒软件"在"计算机"维度离得很近,但在"攻击性"维度离得很远。
0x05 智能体(Agent):Agentic Workflow 的崛起
这是本系列最核心的观点:AI 不应该是工具,AI 应该是工具的使用者。
1. 思维链(CoT)与反思
一个优秀的 CTF 专家在解题时会经历:扫描 -> 失败 -> 分析报错 -> 调整脚本 -> 再次尝试。
我们的机器人通过 Agent 架构模仿这一过程。当 Gemini 3 运行一个 Python 脚本报错时,它不会停下来,而是会将报错信息(Stderr)作为新的输入,问自己:"我哪里做错了?"
2. 这里的工具链调用
通过工具调用(Function Calling),AI 变成了 Kali 的指挥官:
-
识别需求:发现目标是 Web。
-
调用工具 :执行
nmap -sV。 -
获取回显:发现 8080 端口。
-
深入分析 :查阅
./docs/里的 MD 笔记,决定使用dirsearch爆破。
0x06 SecGPT 带来的启示:数据为王
在研究 SecGPT 项目时,我们发现它的强大不仅在于模型,更在于它对安全语料的结构化处理。
-
数据清洗:将杂乱的网页转为干净的 Markdown。
-
指令微调:将安全专家的思维逻辑变成"指令-回复"的对。
这告诉我们:在构建 CTF 机器人时,预处理(Preprocessing) 的工作量占到了 70%。其实就是对于给AI的数据质量直接影响AI给你的结果,如果不经过Preprocessing,数据直接投喂给AI,那么结果肯定也不会太好。
0x07 总结:安全大模型的三位一体
一个能够实战的安全机器人 = 强大的底座逻辑(LLM) + 私有化的专家库(RAG) + 自动化的执行能力(Agent)。当然我觉得这里面还有很多步骤,需要我们一点点来搞!
-
LLM 提供泛化能力,理解我们的自然语言指令。
-
RAG 提供深度专业知识,弥补模型预训练知识的不足。
-
Agent 提供实战接口,让 AI 真正触碰虚拟机里的 Shell。
希望大家对大模型有个初步的认识,如果喜欢可以多点点关注和点赞,点赞多的话,我就继续写这个专题!
大家新年快乐!!