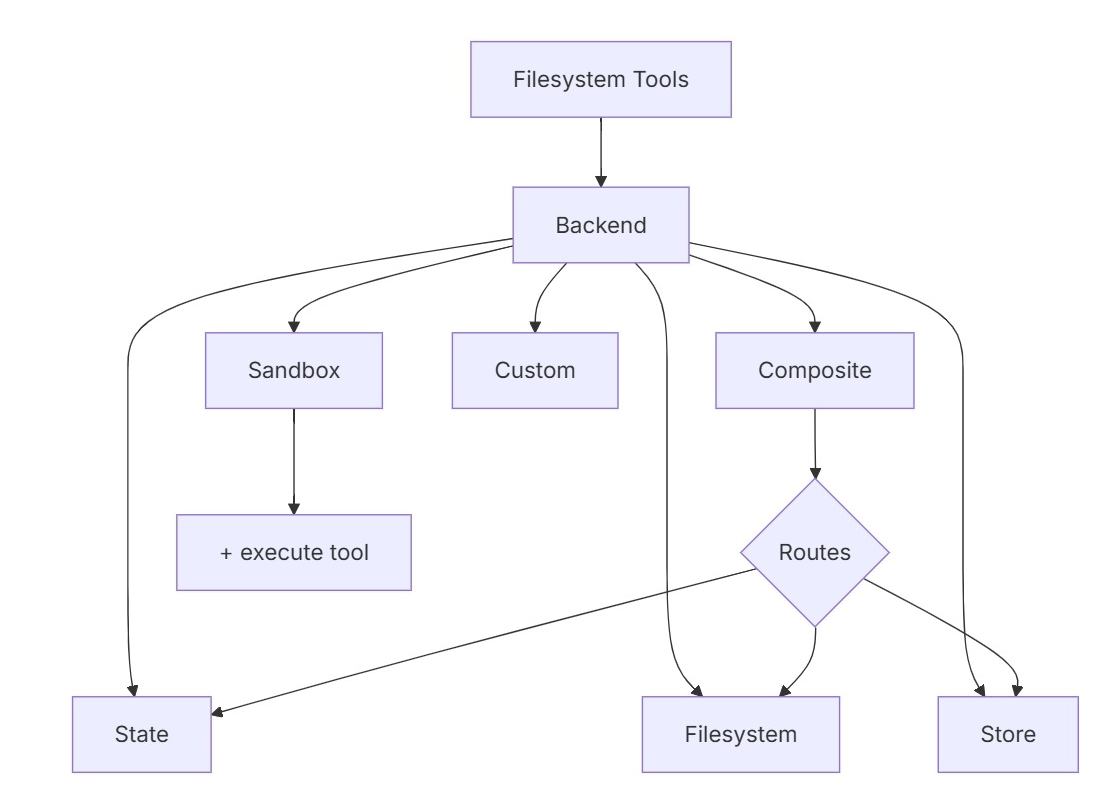
在 Deep Agents 框架中,Backend(后端) 是一个核心抽象层,它定义了 Agent 如何与底层存储系统进行交互。简单来说,它是 Agent 的"文件系统驱动",决定了所有文件操作工具(如 ls、read_file、write_file 等)最终将数据存储在哪里、如何读取、以及是否支持执行命令。他的框架如下
为什么需要 Backend?
-
解耦与灵活性:Agent 本身不需要关心文件是存在内存、本地磁盘、远程数据库还是云端对象存储中。通过切换不同的 Backend,同一个 Agent 可以在不同环境中无缝运行。
-
安全性:可以对 Agent 的读写范围进行限制(例如只允许访问特定目录),或通过沙箱后端隔离危险操作。
-
可扩展性:开发者可以轻松实现自定义 Backend,将任何数据源(如 S3、PostgreSQL)映射为 Agent 可访问的虚拟文件系统。
Backend 的核心功能
所有 Backend 都必须实现 BackendProtocol 中定义的一组方法,这些方法对应 Agent 可调用的文件工具:
| 方法 | 对应工具 | 描述 |
|---|---|---|
ls_info(path) |
ls |
列出目录下的文件信息(路径、大小、修改时间等) |
read(file_path, offset, limit) |
read_file |
读取文件内容(支持分块读取和图片多模态返回) |
grep_raw(pattern, path, glob) |
grep |
在文件中搜索文本,返回匹配结果 |
glob_info(pattern, path) |
glob |
根据模式匹配文件路径 |
write(file_path, content) |
write_file |
创建或覆盖文件 |
edit(file_path, old_string, new_string, replace_all) |
edit_file |
编辑文件内容(精确替换) |
内置 Backend 类型
Deep Agents 提供了多种即插即用的 Backend,以适应不同场景:
| 后端类型 | 特点 | 适用场景 |
|---|---|---|
| StateBackend | 默认后端,文件存储在 LangGraph 的当前线程状态中,通过检查点实现跨轮次持久化,但不同线程间不共享。 | 临时工作区、中间结果存储、子Agent间共享文件。 |
| FilesystemBackend | 直接映射到本地磁盘的某个根目录(支持 virtual_mode 限制路径逃逸)。 |
本地开发、CI/CD、需要与真实文件系统交互的场景。 |
| StoreBackend | 基于 LangGraph 的 BaseStore(如内存、Redis、Postgres 等),文件可跨线程持久化。 |
需要长期记忆、跨会话保存用户偏好或知识的场景。 |
| SandboxBackend | 在隔离环境中执行代码,除文件工具外还提供 execute 命令。 |
运行不可信代码、需要环境隔离的生产系统。 |
| CompositeBackend | 路由后端:根据路径前缀将不同区域映射到不同的后端(如 /memories/ 用 StoreBackend,其余用 StateBackend)。 |
需要混合存储策略(临时+持久)的场景。 |
如何选择和使用 Backend?
在创建 Deep Agent 时,通过 create_deep_agent(backend=...) 指定 Backend。可以传入:
-
一个实现了
BackendProtocol的实例(如FilesystemBackend(root_dir=".")) -
一个工厂函数
lambda rt: StateBackend(rt)(对于需要运行时ToolRuntime参数的后端)
例如:
python
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
backend=FilesystemBackend(root_dir="/my/project", virtual_mode=True)
)自定义 Backend
如果需要对接外部存储(如 S3、数据库),只需继承 BackendProtocol 并实现上述方法。你还可以通过包装现有后端添加策略钩子(如禁止写入某些路径),实现企业级权限控制。
python
from deepagents.backends.protocol import BackendProtocol, WriteResult, EditResult
from deepagents.backends.utils import FileInfo, GrepMatch
class S3Backend(BackendProtocol):
def __init__(self, bucket: str, prefix: str = ""):
self.bucket = bucket
self.prefix = prefix.rstrip("/")
def _key(self, path: str) -> str:
return f"{self.prefix}{path}"
def ls_info(self, path: str) -> list[FileInfo]:
# List objects under _key(path); build FileInfo entries (path, size, modified_at)
...
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> str:
# Fetch object; return numbered content or an error string
...
def grep_raw(self, pattern: str, path: str | None = None, glob: str | None = None) -> list[GrepMatch] | str:
# Optionally filter server‑side; else list and scan content
...
def glob_info(self, pattern: str, path: str = "/") -> list[FileInfo]:
# Apply glob relative to path across keys
...
def write(self, file_path: str, content: str) -> WriteResult:
# Enforce create‑only semantics; return WriteResult(path=file_path, files_update=None)
...
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
# Read → replace (respect uniqueness vs replace_all) → write → return occurrences
...源码详解
在 Deep Agents 框架中,protocol.py 和 filesystem.py 共同构成了后端抽象层的核心。前者定义了统一的后端接口协议,后者则提供了基于本地文件系统的具体实现。理解这两个文件,有助于掌握 Deep Agents 如何将文件操作与底层存储解耦,以及如何安全、高效地扩展不同的存储后端。下面重点介绍这两个代码
protocol.py ------ 后端接口协议
protocol.py 定义了所有后端必须遵循的抽象基类 BackendProtocol,以及配套的数据结构。它的核心作用是建立一套标准的文件操作契约 ,使得 Agent 中的文件工具(如 read_file、write_file)可以无需关心后端的具体实现(内存、磁盘、数据库、云存储等),只需调用协议中约定的方法。
核心数据结构
协议中定义了若干 TypedDict 和 dataclass,用于统一方法返回值的格式:
| 数据结构 | 用途 | 关键字段 |
|---|---|---|
FileInfo |
文件/目录的元信息 | path(必须)、is_dir、size、modified_at |
GrepMatch |
搜索结果的一条匹配记录 | path、line(行号)、text(匹配行内容) |
WriteResult |
write 操作的返回结果 |
error、path、files_update(状态后端专用) |
EditResult |
edit 操作的返回结果 |
error、path、files_update、occurrences |
FileUploadResponse |
文件上传操作的返回结果 | path、error(标准化错误码) |
FileDownloadResponse |
文件下载操作的返回结果 | path、content、error(标准化错误码) |
ExecuteResponse |
命令执行的结果(仅沙箱后端) | output、exit_code、truncated |
TypedDict 是 Python 类型系统提供的一种方式,允许开发者定义字典类型,这些字典的键是固定的,每个键对应的值也有固定的类型。这对于静态类型检查非常有用,因为它使得类型检查器可以确保代码中字典的使用与定义时预期的结构相匹配。
class FileInfo(TypedDict):
path: str
is_dir: NotRequired[bool]
size: NotRequired[int]
modified_at: NotRequired[str]
class GrepMatch(TypedDict):
path: str
line: int
text: str-
轻量:不需要定义类,直接使用字典字面量即可创建对象,方便在代码各处快速构造。
-
兼容性:这些数据结构往往用于 API 响应,直接以字典形式传递最为自然,与 JSON 序列化无缝衔接。
-
可扩展性 :使用
NotRequired标记可选字段,允许后端实现者按需提供元数据(例如某些后端可能无法提供size)。 -
类型提示:为 IDE 和类型检查器提供准确的字段信息,减少错误。
-
FileInfo用于ls_info、glob_info的返回值,每个条目就是一个字典,字段可能因后端而异。
抽象方法概览
BackendProtocol 要求所有子类实现以下核心方法(同步和异步版本,异步版本默认通过 asyncio.to_thread 委托给同步方法):
| 方法 | 描述 | 关键行为 |
|---|---|---|
ls_info(path) |
列出目录下的文件/目录元信息 | 返回 FileInfo 列表,目录路径以 / 结尾 |
read(file_path, offset, limit) |
读取文件内容(带行号) | 支持分页读取;返回带行号的格式化文本;失败时返回错误字符串 |
grep_raw(pattern, path, glob) |
在文件中搜索字面字符串 | 返回匹配列表 GrepMatch;若正则无效则返回错误字符串 |
glob_info(pattern, path) |
按 glob 模式匹配文件 | 返回匹配文件的 FileInfo 列表 |
write(file_path, content) |
创建新文件(禁止覆盖) | 返回 WriteResult;成功时返回路径,失败返回错误 |
edit(file_path, old_string, new_string, replace_all) |
精确替换文件内容 | 返回 EditResult;包含替换次数 |
upload_files(files) |
批量上传字节数据 | 返回 FileUploadResponse 列表,支持部分成功 |
download_files(paths) |
批量下载文件 | 返回 FileDownloadResponse 列表,支持部分成功 |
dataclass 是 Python 3.7+ 引入的装饰器,用于自动生成
__init__、__repr__等方法,创建不可变或可变的简单数据容器。