Redis 的核心设计哲学是 "双层模型":
外层(对象层): 开发者使用的 5 大基础类型(String, List, Hash, Set, ZSet)。
内层(编码层): Redis 根据数据量大小和类型,自动切换的底层实现(如 Listpack, QuickList, HashTable, SkipList),以在"省内存"和"高性能"之间寻找平衡。
一、 核心架构:双层模型 (redisObject)
无论存储什么数据,Redis 都会用一个统一的结构体 redisObject 来封装。
java
struct redisObject {
unsigned type:4; // 【面子】对外类型:String, List, Hash...
unsigned encoding:4; // 【里子】底层编码:int, raw, listpack, hashtable...
void *ptr; //指向底层真实数据的指针
...
};设计原则:
小数据/特定类型
→
→ 时间换空间(使用紧凑型结构,如 Listpack,省内存但需遍历)。
大数据/通用类型
→
→ 空间换时间(使用索引型结构,如 HashTable/SkipList,占内存但查得快)。
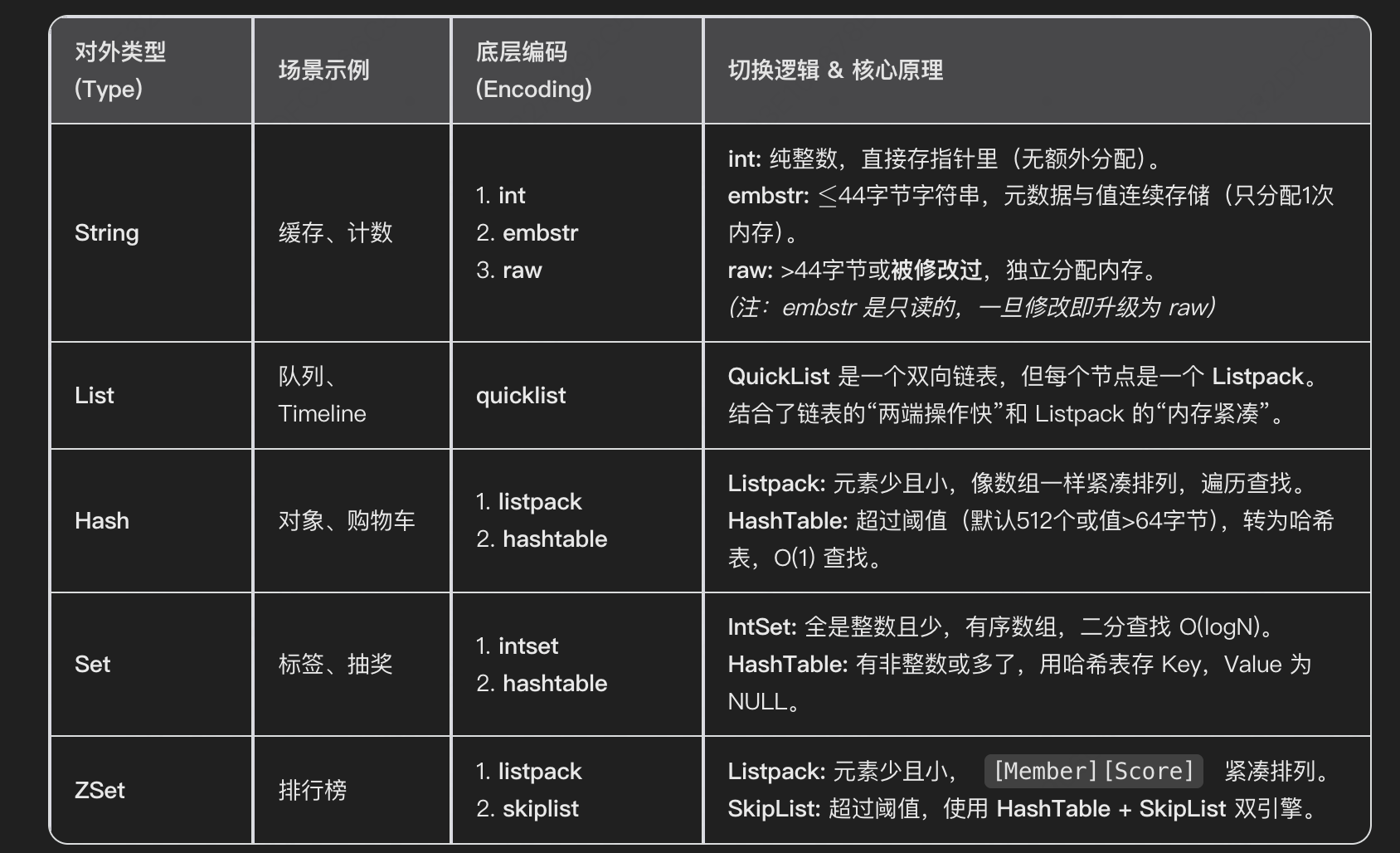
二、五类数据结构说明
- String (字符串)
最基础的类型,二进制安全,最大 512MB。
底层编码 (Encoding)
int:纯整数。值直接存入指针字段,无额外内存分配。
embstr:短字符串 (≤44字节)。元数据与值在连续内存中,只分配 1 次内存。只读(修改即升级)。
raw:长字符串 (>44字节) 或 被修改过的字符串。元数据与值分离,分配 2 次内存,适合频繁修改。
关键场景与演示
场景 A:高频计数器 (视频播放量、点赞数)
利用 INCR 的原子性,无需加锁。
java
# 演示:文章ID 1001 的阅读量
SET article:read:1001 0
INCR article:read:1001 # 结果: 1 (底层编码: int)
INCR article:read:1001 # 结果: 2
场景 B:分布式锁
利用 SETNX (Set if Not Exists) 实现互斥。
java
# 演示:尝试获取锁,10秒自动过期
SET lock:resource_A "uuid_owner" NX EX 10
# 返回 OK 表示获取成功,返回 nil 表示已被占用场景 C:对象缓存 (JSON)
java
# 演示:存用户信息
SET user:1001 '{"name":"Xiaomei", "age":18}' # (底层编码: embstr 或 raw)- List (列表)
双向链表,支持两端操作。
底层编码 (Encoding)
quicklist:唯一实现。
宏观上是双向链表。
微观上每个节点是一个 Listpack (紧凑列表)。
优势: 既避免了普通链表的内存碎片(指针太多),又避免了巨大 ZipList 的更新性能问题。
关键场景与演示
场景 A:消息队列 (生产者/消费者)
利用 LPUSH 入队,BRPOP 阻塞式出队。
java
# 生产者
LPUSH task_queue "send_email_1"
LPUSH task_queue "send_sms_2"
# 消费者 (如果没有消息,阻塞等待 5秒)
BRPOP task_queue 5
# 返回: 1) "task_queue" 2) "send_email_1"场景 B:用户动态/时间线 (Timeline)
微信朋友圈,只保留最新的 1000 条。
java
# 新增一条动态
LPUSH user:moments:1001 "msg_id_999"
# 保持列表长度为 1000,踢出旧的
LTRIM user:moments:1001 0 999- Hash (哈希)
键值对集合,适合存储对象。
底层编码 (Encoding)
listpack:小数据时(默认元素<512个 且 值<64字节)。数据像数组一样紧凑排列,查询靠遍历。
hashtable:大数据时。标准的哈希表,查询 O(1)。
关键场景与演示
场景 A:购物车
用户 ID 为 Key,商品 ID 为 Field,数量为 Value。
java
# 用户 888 加购商品 item_1,数量 2
HINCRBY cart:888 item_1 2
# 用户 888 加购商品 item_2,数量 1
HINCRBY cart:888 item_2 1
# 获取购物车所有商品
HGETALL cart:888
# 结果: 1) "item_1" 2) "2" 3) "item_2" 4) "1"场景 B:存储对象 (部分更新)
比 String 存 JSON 更灵活,可以只改某个字段。
java
HSET user:1001 name "Xiaomei" age 18 balance 100
# 只修改余额,不影响其他字段
HINCRBY user:1001 balance -10- Set (集合)
无序、去重。
底层编码 (Encoding)
intset:纯整数且数量少。有序数组,二分查找 O(logN)。
hashtable:有非整数 或 数量多。Value 指向 NULL 的哈希表。
关键场景与演示
场景 A:抽奖活动
利用 Set 的去重和随机弹出特性。
java
# 参与抽奖
SADD lottery_pool "UserA" "UserB" "UserC" ...
# 随机抽取 1 名幸运儿 (不放回)
SPOP lottery_pool 1场景 B:社交关系 (共同好友)
利用集合运算(交集、并集、差集)。
java
SADD user:A:friends "Jack" "Rose" "Tom"
SADD user:B:friends "Rose" "Tom" "Jerry"
# 计算共同好友 (交集)
SINTER user:A:friends user:B:friends
# 结果: "Rose", "Tom"- ZSet (有序集合)
带权重的去重集合,Redis 最复杂的数据结构。
底层编码 (Encoding)
listpack:小数据时。MemberScore 紧凑排列。
skiplist:大数据时。采用 HashTable + SkipList 双引擎架构。
核心原理回顾
HashTable: 存 Member -> Score,实现 O(1) 查分。
SkipList: 存 Score 排序,实现 O(logN) 范围查询。
Span (跨度): 跳表指针上记录"跨过了几个节点",用于 O(logN) 快速计算排名 (ZRANK)。
关键场景与演示
场景 A:游戏排行榜
Score 是分数,Member 是玩家 ID。
java
# 记录分数
ZADD game:rank 1000 "PlayerA"
ZADD game:rank 2500 "PlayerB"
ZADD game:rank 1800 "PlayerC"
# 获取前 3 名 (分数从高到低)
ZREVRANGE game:rank 0 2 WITHSCORES
# 结果: 1) "PlayerB" 2500 2) "PlayerC" 1800 3) "PlayerA" 1000
java
# 获取 PlayerC 的排名 (从 0 开始)
ZREVRANK game:rank "PlayerC"
# 结果: 1场景 B:延时队列
Score 是执行时间的时间戳。
java
# 任务:5秒后发送邮件 (当前时间戳 + 5)
ZADD delay_queue 1708123456 "task_email_001"
# 轮询:获取当前时间之前的所有任务
ZRANGEBYSCORE delay_queue 0 1708123451
# 如果拿到任务,执行并 ZREM 删除- 附录:底层数据结构演进总结
结构名称 状态 核心特点 解决了什么问题?

三、深度解析:关键底层结构 - 紧凑列表的进化史 (ZipList → Listpack)
这是 Redis 为了节省内存而设计的连续内存块结构。
ZipList (已淘汰):
结构: prev_lenencodingdata。
致命伤: prev_len 记录前一个节点的长度。如果前一个节点变大,prev_len 也要变大,可能导致后续所有节点都跟着扩容,引发 "连锁更新 (Cascading Update)",性能瞬间雪崩。
Listpack (新标准):
结构: encodingdataelement_len。
改进: 把长度记录在当前节点的尾部。修改当前节点,不影响后续节点。彻底解决了连锁更新问题。 - 万能的 HashTable (Dict)
Redis 复用了哈希表来实现 Hash 和 Set。
实现 Hash: Key 是字段名,Value 是字段值。
实现 Set: Key 是集合元素,Value 是 NULL。利用哈希表的 Key 唯一性实现去重。
扩容机制: 采用 "渐进式 Rehash",不一次性搬迁所有数据(会卡死主线程),而是分多次慢慢搬。
- 有序集合的"双引擎" (ZSet)
ZSet 必须同时满足"根据 ID 查分"和"根据分数排行"。
HashTable: 存储 Member Score。实现 O(1) 查分。
SkipList (跳表): 存储按 Score 排序的数据。实现 O(logN) 范围查询。
原理: 多层级的有序链表,利用随机层数建立索引。
对比红黑树: 实现更简单,范围查询更高效(直接遍历链表),内存更省。
- 排名的秘密 (Span)
为什么 ZRANK (查排名) 这么快?
痛点: 普通链表查排名需要从头数(O(N))。
方案: Redis 在跳表的指针(箭头)上记录了 "跨度 (span)"。
原理: span 表示这个箭头跨过了多少个节点。查找目标时,将路径上经过的所有 span 累加,即为排名。
结果: 排名计算复杂度降为 O(logN)。
四、 总结记忆口诀
String 看长度: 存数字用 int,短串用 embstr,长串或改过用 raw。
List 是混血: QuickList 也就是"链表挂 Listpack"。
Hash/ZSet 变身: 小时候是 Listpack(省内存),长大了变 HashTable/SkipList(拼速度)。
Set 很单纯: 纯整数用 IntSet,杂质多用 HashTable。
ZSet 有双核: 字典查分,跳表排序(带 span 算排名)。