文章目录
- Pre
- 引言
- 一、新增依赖
- 二、TavilySearchTool实现
-
- [2.1 工具定义](#2.1 工具定义)
- [2.2 执行搜索并格式化结果](#2.2 执行搜索并格式化结果)
- 三、注册到Agent
- 四、执行流程示例
- 五、设计思考
-
- [5.1 为什么选Tavily而不是Google/Bing API?](#5.1 为什么选Tavily而不是Google/Bing API?)
- [5.2 搜索结果如何流入Agent决策链?](#5.2 搜索结果如何流入Agent决策链?)
- [5.3 环境变量管理](#5.3 环境变量管理)
- 总结
Pre
大模型开发 - 用纯Java手写一个多功能AI Agent:01 从零实现类Manus智能体
大模型开发 - 手写Manus之基础架构:02 用纯Java从零搭建AI Agent骨架
大模型开发 - 手写Manus之Sandbox执行代码:03 用Docker为AI Agent打造安全沙箱
引言
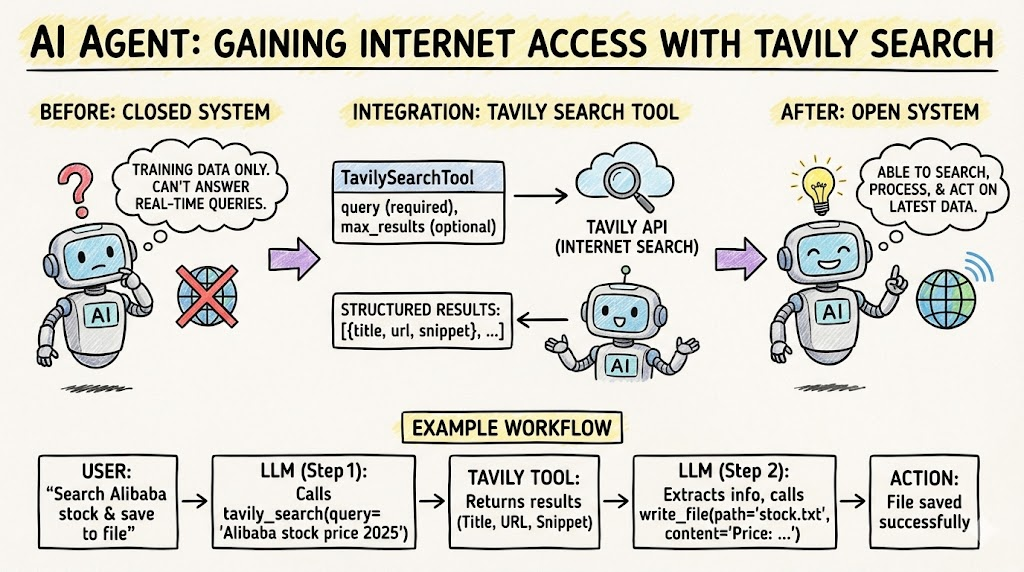
前两篇文章中,我们的Agent已经具备了文件读写和Docker沙箱代码执行能力。但它仍然是一个"闭环"系统------无法获取互联网上的实时信息。
当用户问"阿里巴巴最新股价是多少"时,大模型的训练数据有截止日期,无法回答实时问题。我们需要给Agent一双"眼睛",让它能够搜索互联网获取最新信息。
本文将集成Tavily搜索引擎,为Agent添加网页搜索能力。Tavily是一个专为AI Agent设计的搜索API,返回结构化的搜索结果,非常适合程序化处理。
一、新增依赖
通过langchain4j提供的Tavily封装,几行代码即可集成:
xml
<!-- Tavily搜索引擎 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-tavily</artifactId>
<version>0.36.2</version>
</dependency>二、TavilySearchTool实现
2.1 工具定义
java
public class TavilySearchTool extends BaseTool {
private final WebSearchEngine searchEngine;
public TavilySearchTool() {
super("tavily_search", "Search the web for information using Tavily search engine");
// 从环境变量获取API Key
String apiKey = System.getenv("TAVILY_API_KEY");
if (apiKey == null || apiKey.trim().isEmpty()) {
throw new IllegalStateException("TAVILY_API_KEY environment variable is required");
}
this.searchEngine = TavilyWebSearchEngine.builder()
.apiKey(apiKey)
.build();
}
@Override
public Map<String, Object> getParametersSchema() {
Map<String, Map<String, Object>> properties = new HashMap<>();
properties.put("query", stringParam("The search query to execute"));
properties.put("max_results",
intParam("Maximum number of search results to return (default: 5, max: 20)"));
return buildSchema(properties, List.of("query"));
}
}参数设计只需两个字段:
query(必填):搜索关键词max_results(可选):返回结果数量上限
2.2 执行搜索并格式化结果
java
@Override
public ToolResult execute(Map<String, Object> parameters) {
try {
String query = getString(parameters, "query");
if (query == null || query.trim().isEmpty()) {
return ToolResult.error("Query parameter is required");
}
// 执行搜索
WebSearchResults results = searchEngine.search(query);
// 格式化结果
Map<String, Object> response = new HashMap<>();
response.put("query", query);
response.put("total_results", results.results().size());
List<Map<String, Object>> searchResults = results.results().stream()
.map(result -> {
Map<String, Object> item = new HashMap<>();
item.put("title", result.title());
item.put("url", result.url());
item.put("snippet", result.snippet());
return item;
})
.toList();
response.put("results", searchResults);
return ToolResult.success(response);
} catch (Exception e) {
return ToolResult.error("Search failed: " + e.getMessage());
}
}每条搜索结果包含三个字段:
title:网页标题url:网页链接snippet:内容摘要
这些结构化数据会被传回大模型,大模型可以从中提取关键信息回答用户问题。
三、注册到Agent
在ManusAgent中一行代码完成注册:
java
toolCollection.addTool(new TavilySearchTool());四、执行流程示例
用户输入:"搜索阿里巴巴最新股价,并写入到文件中"
java
Step 1: LLM推理 → 调用tavily_search工具
query: "阿里巴巴最新股价 2025"
→ 返回搜索结果:
[{title: "阿里巴巴(BABA)股票价格...", url: "...", snippet: "..."},
{title: "阿里巴巴集团今日股价...", url: "...", snippet: "..."}]
Step 2: LLM推理 → 从搜索结果中提取信息,调用write_file工具
file_path: "workspace/alibaba_stock_price.txt"
content: "阿里巴巴(BABA)最新股价: ..."
→ 文件写入成功
Step 3: LLM推理 → finish_reason="stop"
→ 任务完成文件系统 (write_file) Tavily Search 工具 大语言模型 (LLM) 用户 文件系统 (write_file) Tavily Search 工具 大语言模型 (LLM) 用户 Step 1: 实时信息检索 Step 2: 信息提取与持久化 Step 3: 流程终结 调用 tavily_search (query: "阿里巴巴最新股价 2025") 1 返回搜索结果集 (BABA 股价、今日详情等) 2 提取核心股价数据 3 调用 write_file (path="workspace/alibaba_stock_price.txt") 4 返回: 文件写入成功 5 任务完成 (finish_reason="stop") 6
五、设计思考
5.1 为什么选Tavily而不是Google/Bing API?
Tavily专为AI Agent场景设计,有几个优势:
- 返回结构化数据:直接提供title/url/snippet,无需解析HTML
- 内容摘要质量高:snippet包含与查询最相关的内容片段
- API简洁:一个方法调用即可,不需要复杂的配置
5.2 搜索结果如何流入Agent决策链?
java
搜索结果 → ToolResult → toolMessage → Memory → 下一轮LLM输入搜索结果被封装为toolMessage存入Memory后,大模型在下一轮推理时可以看到完整的搜索结果,并据此做出决策------比如提取关键信息、综合多个来源、或者发起更精确的二次搜索。
5.3 环境变量管理
项目使用环境变量管理API Key,避免硬编码:
bash
export DASHSCOPE_API_KEY=your_dashscope_key
export TAVILY_API_KEY=your_tavily_key总结
通过集成Tavily搜索引擎,Agent获得了访问互联网实时信息的能力。这是从"封闭系统"到"开放系统"的关键一步。
现在Agent的工具箱中有三个工具:
- write_file / read_file --- 文件操作
- sandbox --- 代码执行
- tavily_search --- 网页搜索
Agent可以搜索信息、编写代码处理数据、将结果保存到文件------工具之间的组合使用让Agent的能力远超单个工具的简单叠加。
