提出问题
前面学习RAG时候调用向量检索来获取top_k相似度的向量块,那么内部究竟是怎么进行检索的?难道就是从零到N的暴力遍历吗?那么当向量块数据集达到上百亿的时候怎么办?
原始算法
- KNN :K-NearestNeighbor 暴力搜索
- 通过计算查询点与数据库中每一个点的距离,找出最近的k个邻居。
- 🌰:在一个拥有1000万本未经分类、杂乱堆放的书库里,找一本内容最相似的书。KNN需要从第一本书翻到第1000万本才能找到答案。可见KNN虽然结果精确,但在大规模数据集上速度极慢,不适用于实时应用。

权衡算法
"精度-速度-内存"三角难题
同样还是上面1000万本书的case,如果挨个翻完很难想象其工作量。虽然精确,但在实际应用中存在巨大的成本问题:
-
复杂度灾难 : 它的搜索时间复杂度是 O(n) ,即与数据量n线性相关。当n从1万增长到1000万时,查询耗时大致会增加1000倍。这在生产环境中是不可接受的。
-
内存占用大: 因为它不压缩数据,存储10亿个768维的向量,可能需要近3TB的内存,成本极高。
-
无法支持动态更新: 虽然可以添加向量,但每次添加后,索引结构并无优化,性能会随着数据增加而线性下降。
这就是检索算法也存在的经典的 "精度-速度-内存" 不可能三角。实际开发中,需要在牺牲一定的精度(不至于严重影响结果),来换取速度和内存上的收益。于是乎ANN应运而生。
IVF
- ANN :Approximate Nearest Neighbor
- 在速度和精度之间做了权衡,不保证找到绝对最近的邻居, 但能在极短的时间内找到非常接近的结果。在RAG检索等场景下,这种速度上的提升远比微小的准确性损失更重要。
- 常见的主流ANN算法有IVF和HNSW
IVF
定义
IVF:Inverted File 倒排文件索引
先将向量块分类,然后找出搜索目标属于哪一类,再在这一类附近精搜。
流程
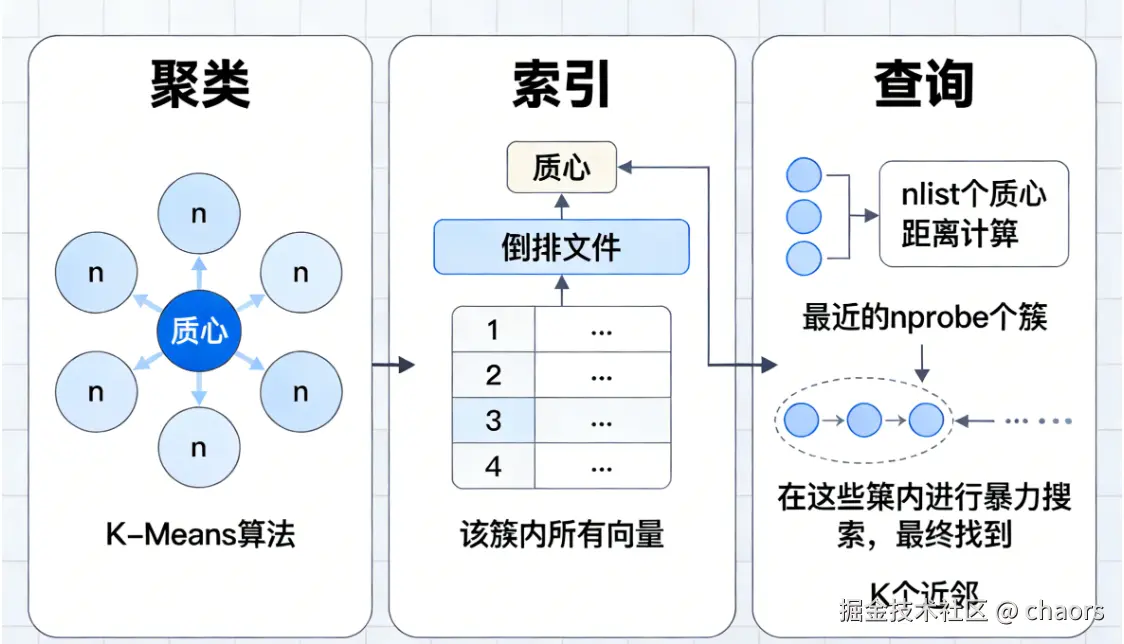
- 聚类(Clustering)
使用K-Means等算法将所有向量数据聚成n个簇(clusters)。每个簇的中心点称为质心(centroid)。
- 索引(indexing)
创建一个"倒排文件" ,即一个从"质心"到"该簇内所有向量"的映射列表。
3、查询(Querying)
计算查询向量与所有 nlist 个质心的距离。选出最近的 nprobe个簇。仅在这
nprobe个簇内进行暴力搜索,找到最终的K个近邻。
HNSW
定义

HNSW:Hierarchical Navigable Small World Graph,分层导航小世界。是一种近似最近邻搜索算法。它的核心设计极为巧妙,可以拆解为两个经典数据结构的融合:
-
分层思想(来自跳表) :构建一个多层的"金字塔"结构。顶层节点极少,连接跨度大,用于快速、粗粒度地定位目标区域;越往底层节点越密集,连接越精细,用于最终的精确定位。
-
图导航思想(来自可导航小世界图NSW) :图中大部分节点不直接相连,但任何两个节点之间都可以通过很少的几步 ("六度分隔"理论) 到达。每一层都是一个图网络,每个数据点(向量)是图中的节点,并与一定数量的最近邻节点相连。搜索时,算法从一个入口点出发,在当前节点的邻居中贪婪地选择离目标最近的点,一步步"导航"过去。
举个🌰:
-
顶层(L2) :只有几个国际枢纽机场(如北京、法兰克福),负责洲际间的快速跳转。对应HNSW最稀疏的层,几步就能从亚洲跳到欧洲。
-
中层(L1) :包含了各省会、主要城市的机场和高速枢纽,负责国家或区域内的转运。
-
底层(L0) :囊括了所有城镇、街道乃至最终的门牌地址,负责最终的精准配送。
流程
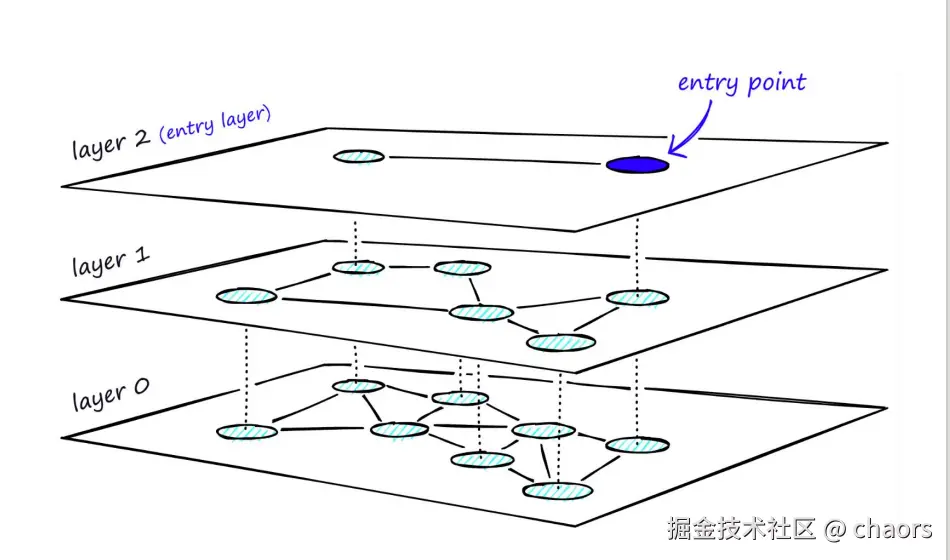
-
顶层入口:从最高层(最稀疏的层)的某个入口节点(entry point)开始。
-
层内贪婪搜索:在当前层,执行一个改进的贪婪算法。算法维护一个动态的"最近邻候选列表"(最多包含 ef个元素),从入口点出发,不断探索当前最近邻的邻居,将更近的节点加入列表,并移动到这个列表中的最近点,直到无法找到更近的邻居为止。此时找到的点,就是该层的"局部最近邻"。
-
向下层跳跃:以上一层找到的"局部最近邻"作为下一层(更密集的一层layer1)搜索的入口点。
-
循环与终结:重复步骤2和3,逐层下降。当到达最底层(layer0层)并完成贪婪搜索后,最终候选列表中的最近点,即为算法返回的近似最近邻。
巅峰对决
那么,我们实际开发中一般用IVF还是HNSW呢?那就取决于我们case的对于 "精度-速度-内存" 不可能三角中三个因素哪个更敏感。
Codding算一下
相比内存,速度更好计算。我们这里就简单写个demo计算下KNN、IVF和HNSW的耗时比较。毕竟基于图的HNSW检索算法,很明显对内存的要求会更高一点。
FAISS
FAISS (Facebook AI Similarity Search)是Meta AI Research开源的高性能向量相似性搜索库。它是一个极致的向量检索引擎,其核心使命只有一个:在十亿甚至百亿级别的高维向量中,以毫秒级速度找到最相似的邻居(Approximate Nearest Neighbor, ANN)
这里因为我们只用到向量检索,并不需要使用存储功能。所以使用FAISS框架,以求极致的性能。
📢⚠️:在引入FAISS库的时候,其库名并不是简单的框架名,及其两个库的区别:
- faiss-cpu:利用中央处理器(CPU)进行计算。CPU核心少(通常几个到几十个),但每个核心能力强,擅长处理复杂的串行逻辑和任务调度。在向量搜索中,它更依赖算法优化(如IVF、HNSW的图遍历)来减少计算量。
- faiss-gpu:利用图形处理器(GPU)进行计算。GPU拥有成千上万个流处理器核心 ,但每个核心能力较弱,擅长对海量同质化数据进行高度并行的简单计算(如矩阵乘法、向量距离计算)。
KNN
- d:向量维度
- xb:向量块个数
- xq:查询向量
- k:取top_k相似的结果
python
# --- 1. 精确近邻 (NN) / 暴力搜索 (作为基准) ---
def flat(d, xb, xq, k):
"""使用暴力搜索计算精确的最近邻"""
print("--- 1. 精确近邻 (NN) 搜索 ---")
t0 = time.monotonic() # 测量时间间隔
# IndexFlatL2 执行的是暴力L2距离搜索
index = faiss.IndexFlatL2(d)
# 构建时间:对于Flat索引,add操作本身就是构建过程,非常快
index.add(xb)
t1 = time.monotonic()
# 搜索时间:计算查询向量与所有10000个基准向量的距离
D, I = index.search(xq, k) # D(距离); I (索引)
t2 = time.monotonic()
print(f"构建耗时: {(t1 - t0) * 1000:.4f} ms")
print(f"搜索耗时: {(t2 - t1) * 1000:.4f} ms")
# print(f"结果 (索引):\n{I}\n")
# print(f"结果 (距离):\n{D}\n")
return I # 返回结果用于后续比较IVF
python
# --- 2. IVF (倒排文件) ---
def ivf(d, xb, xq, k):
"""使用IVF进行近似搜索"""
print("--- 2. IVF ---")
t0 = time.monotonic()
# 步骤 1: 创建IVF索引,这里定义了10个聚类中心 (桶)
nlist = 20
quantizer = faiss.IndexFlatL2(d) # 基索引,用于聚类
index_ivf = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
# 步骤 2: 训练索引 (这是IVF特有的步骤,用于找到聚类中心)
index_ivf.train(xb)
# 步骤 3: 添加向量 (向量被分配到最近的桶中)
index_ivf.add(xb)
t1 = time.monotonic()
# 步骤 4: 设置 nprobe,决定搜索时探查多少个桶
index_ivf.nprobe = 15
# 步骤 5: 搜索
D, I = index_ivf.search(xq, k)
t2 = time.monotonic()
print(f"训练+构建耗时: {(t1 - t0) * 1000:.4f} ms")
print(f"搜索耗时 (nprobe={index_ivf.nprobe}): {(t2 - t1) * 1000:.4f} ms")
# print(f"结果 (索引):\n{I}\n")
return IHNSW
python
# --- 3. HNSW (分层可导航小世界) ---
def hnsw(d, xb, xq, k):
"""使用HNSW进行近似搜索"""
print("--- 3. HNSW ---")
t0 = time.monotonic()
# 步骤 1: 构建HNSW索引。
# 32是每个节点连接的邻居数(M),M越大,图构建越密,精度可能更高,但内存占用和构建时间也随之增加
index_hnsw = faiss.IndexHNSWFlat(d, 32)
# efConstruction构建索引时维护的动态列表大小。控制图的构建质量,越高图质量越好,构建越慢
index_hnsw.hnsw.efConstruction = 128
# 步骤 2: 添加数据 (这是HNSW最耗时的部分,因为它在动态构建图)
index_hnsw.add(xb)
t1 = time.monotonic()
# efSearch查询时维护的动态列表大小。控制搜索的精度和速度,越高越准,越慢
index_hnsw.hnsw.efSearch = 128
# 步骤 3: 搜索
D_hnsw, I_hnsw = index_hnsw.search(xq, k)
t2 = time.monotonic()
print(f"构建耗时: {(t1 - t0) * 1000:.4f} ms")
print(f"搜索耗时 (efSearch={index_hnsw.hnsw.efSearch}): {(t2 - t1) * 1000:.4f} ms")
# print(f"结果 (索引):\n{I_hnsw}\n")
return I_hnswmain函数
ini
f __name__ == '__main__':
# 创建模拟数据: 10000个128维向量
d = 128
nb = 100000
np.random.seed(12)
xb = np.random.random((nb, d)).astype('float32')
# print(xb)
# 创建5个随机查询向量
nq = 5
xq = np.random.random((nq, d)).astype('float32')
k = 6 # 查找最近的6个邻居
# 运行并比较三种方法
flat_results = flat(d, xb, xq, k) # 精确近邻 (NN) / 暴力搜索 (作为基准)
ivf_results = ivf(d, xb, xq, k) # IVF (倒排文件)
hnsw_results = hnsw(d, xb, xq, k) # HNSW (分层可导航小世界)
# 计算近似算法的召回率 (与精确结果对比)
def recall(flat_results, ann_results):
assert flat_results.shape == ann_results.shape
# 计算每个查询的交集大小
common_elements = (np.isin(ann_results, flat_results).sum(axis=1))
return np.mean(common_elements) / k
print("--- 性能对比 ---")
print(f"IVF 召回率 (与精确结果相比): {recall(flat_results, ivf_results):.2%}")
print(f"HNSW 召回率 (与精确结果相比): {recall(flat_results, hnsw_results):.2%}")对照结果
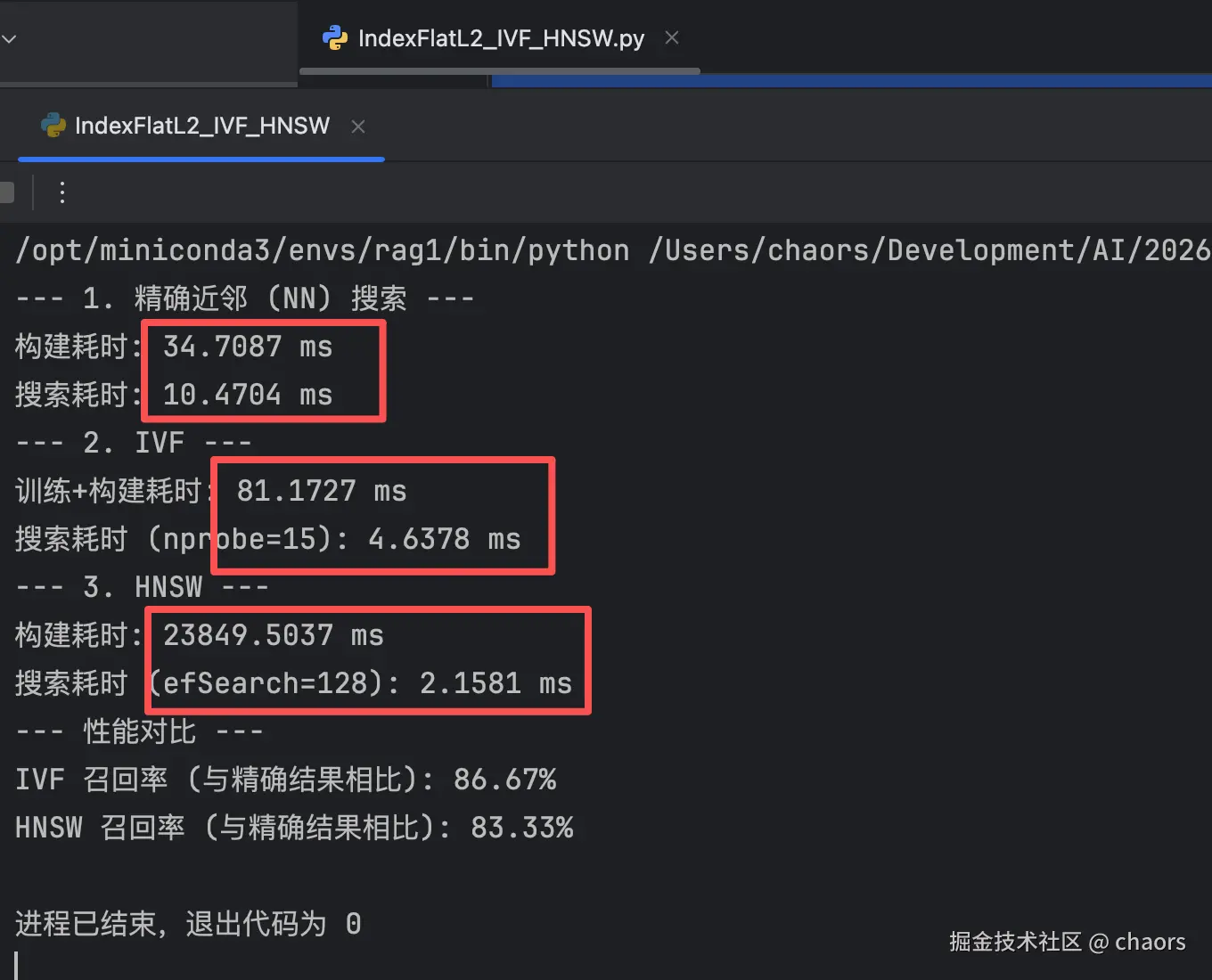
显然:
- 从构建耗时上,KNN < IVF < HNSW
- 从检索耗时上,KNN > IVF > HNSW
但是,往往在实际开发中我们更关注检索耗时。我们在简单改变下相关变量看下变化:
- 条件0
- IVF(nlist) = 20
- IVF(nprobe) = 15
- HNSW(efConstruction) = 128
- HNSW(efSearch) = 128
- 条件1
- IVF(nlist) = 30
- IVF(nprobe) = 10
- HNSW(efConstruction) = 128
- HNSW(efSearch) = 64
| 特征 | KNN | IVF | HNSW |
|---|---|---|---|
| 搜索类型 | 暴力遍历 | 基于聚类 | 基于图 |
| 构建速度0 | 34ms | 87ms | 23849ms |
| 构建速度1 | 36ms | 83 | 23560 |
| 搜索速度0 | 10ms,慢 | 4ms,快 | 2ms,非常快,尤其是在超大规模数据集的情况下 |
| 搜索速度0 | 10ms | 3ms | 3.4ms |
| 召回率0 | 100% | 86.67% | 83.33% |
| 召回率1 | 100% | 80% | 50.33% |
| 内存占用 | 不友好,空间复杂度是O(n) | 内存占用相对较低,尤其适合与量化技术结合,处理无法完全载入内存的超大规模数据集 | 索引需要将所有向量载入内存以获得高性能,内存开销巨大 |
| 动态数据 | 不算"友好",随着数据量线性增长,每次预测的计算开销会越来越大,响应速度变慢,成为在线服务系统的瓶颈。 | 对新增数据不友好,通常需要定期重建索引 | 支持增量添加数据,无需完全重建索引,适合动态变化的数据集 |
| 应用场景 | 暴力遍历 | 适合静态的、超大规模的数据集,对内存资源有限的场景非常友好 | 对查询性能和召回率要求极高的实时应用,且数据集可以完全加载到内存中 |
关于HNSW的思考
根据以上表格发现,参数不同,HNSW召回率会有相应变化。所以HNSW参数调整是其最终好用的关键。
