文章目录
- 一、基础经典模型
-
- 1.MLP (多层感知机)
- 2.CNN (卷积神经网络)
- [3.RNN / LSTM / GRU](#3.RNN / LSTM / GRU)
- 二、视觉模型
- 三、自然语言模型
- 四、多模态大模型 (文本 + 图像 / 视频 / 音频)
- 五、概念
- 六、预训练+微调
- 七、AI行业发展
一、基础经典模型
1.MLP (多层感知机)
最基础的神经网络,用于简单分类、回归
2.CNN (卷积神经网络)
擅长图像、语音、时序等网格数据
3.RNN / LSTM / GRU
传统序列模型,处理文本、时间序列
二、视觉模型
0.视觉模型一览
ResNet / DenseNet:图像分类backbone
ViT(Vision Transformer):用Transformer做视觉
YOLO / Faster R-CNN:目标检测
U-Net:医学图像分割
GAN / StyleGAN:图像生成
Stable Diffusion / Flux:文生图、图生图扩散模型
1.视觉分类:ResNet50
ImageNet 上的 1000 类别分类
ResNet50:图像分类、特征提取;
2.目标检测模型:YOLOv5
YOLOv5:目标检测、实时视频分析;
三、自然语言模型
1.Transformer (传统语言模型)
1.提出
提出人:Ashish Vaswani
提出时间:2017年
论文标题:《Attention is All You Need 》
这篇论文由Vaswani等人提出,标志着Transformer模型的诞生,采用了全新的自注意力机制(Self-Attention),并且摒弃了传统的RNN和LSTM结构,为后续的NLP和机器翻译任务提供了重要的基础。
2.BERT (传统语言模型)
(1)提出
提出人:Google AI :Jacob Devlin
提出时间:2018年
论文标题:《BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding》
BERT(Bidirectional Encoder Representations from Transformers)是由Google AI的研究人员提出的,基于Transformer架构进行预训练并采用双向上下文信息进行训练,显著提升了在多个NLP任务中的表现。
(2)BERT-base与BERT-large的区别:同一篇论文提出,只是编码器层数、隐藏层维度、注意力头数、参数量不同
| BERT-base | BERT-large | |
|---|---|---|
| 编码器层数 | 12 | 24 |
| 隐藏层维度 | 768 | 1024 |
| 注意力头数 | 12 | 16 |
| 参数量 | 1.1亿 | 3.4亿 |
1.层数 (Layers):
①BERT-base:有12个Transformer编码器层 (Transformer blocks)
②BERT-large:有24个Transformer编码器层
2.隐藏层维度 (Hidden Size):
①BERT-base:每个层的隐藏层维度是768
②BERT-large:每个层的隐藏层维度是1024
3.注意力头数 (Attention Heads):
①BERT-base:每个层有12个注意力头 (attention heads)
②BERT-large:每个层有16个注意力头
4.参数量:
①BERT-base:大约1.1亿个参数
②BERT-large:大约3.4亿个参数
总结来说,BERT-large相对于BERT-base在模型的深度(层数)、宽度(每层的隐藏维度)和复杂度(注意力头数)上都有显著增加,因此可以处理更复杂的任务,提供更强的表示能力,但也需要更多的计算资源和内存。
3.chatGPT
1.ChatGPT原理概览:文字接龙游戏
不同于传统问答系统中答案来源于现成的网络或者数据库,ChatGPT的回答是随着提问的进行自动生成的。这一点有点像文字接龙游戏,ChatGPT会基于前面的话不断地生成下一个合适的词汇,直到觉得不必继续生成为止。
比如我们问ChatGPT:"苹果是一种水果吗",ChatGPT会基于这句话进行文字接龙,大概流程如下:
(1)考虑下一个可能的词汇及其对应的概率,如右表(为了方便理解只写了3个可能的形式)所示。
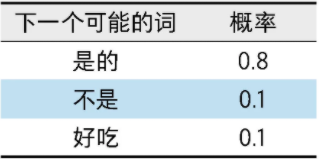
(2)基于上述概率分布,ChatGPT会选择概率最大的答案,即"是的"(因为其概率0.8明显大于其他选项)。
(3)此时这句话的内容变成 "苹果是一种水果么?是的",ChatGPT会看下一个可能的词和对应概率是什么。
不断重复这个步骤,直到得到一个完整的回答。
从上面例子可以看出:
(1)不同于传统问答基于数据库或搜索引擎,ChatGPT的答案是在用户输入问题以后,随着问题自动生成的。
(2)这种生成本质上是在做文字接龙,简单来说是不断在所有可能词汇中选择概率最大的词汇来生成。
2.机器学习的核心:模仿人类进行学习
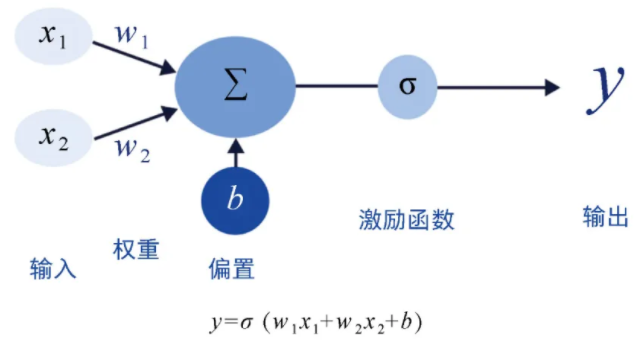
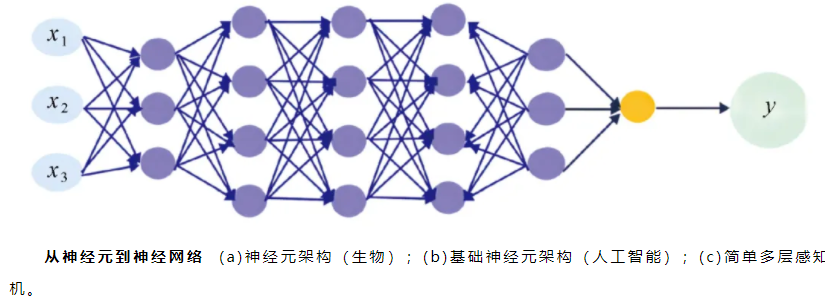
3.神经网络与神经元:可扩展的数学表达能力
4.深度学习新范式:预训练+微调范式 与Scaling Law
深度学习领域从2012年开始蓬勃发展,更大更深且效果更好的模型不断出现。然而随着模型越来越复杂,从头训练模型的成本越来越高。于是有人提出,能否不从头训练,而是在别人训练好的模型基础上训练,从而用更低的成本达到更好的效果呢?
例如,科学家对一个图像分类模型进行拆分,希望研究深度学习模型里的那么多层都学到了什么东西。结果发现,越接近输入层,模型学到的是越基础的信息,比如边、角、纹理等;越接近输出层,模型学到的是越接近高级组合的信息,比如公鸡的形状、船的形状等。不仅仅在图像领域如此,在自然语言、语音等很多领域也存在这个特征。
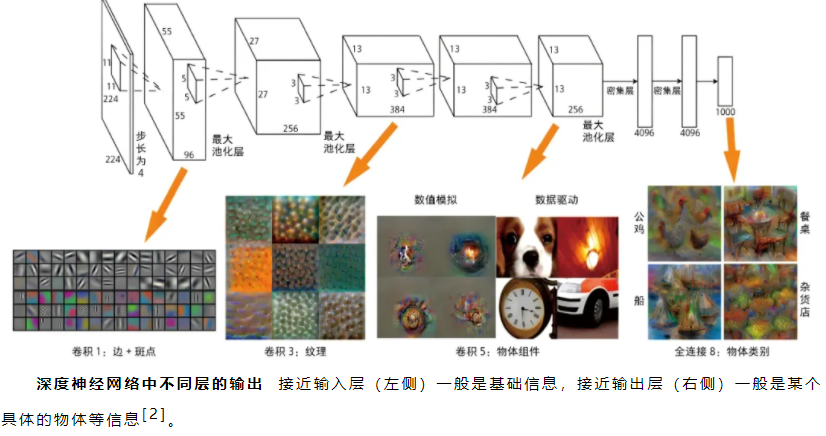
基础信息往往是领域通用的信息,比如图像领域的边、角、纹理等,在各类图像识别中都会用到;而高级组合信息往往是领域专用信息,比如猫的形状只有在动物识别任务中才有用,在人脸识别的任务就没用。因此一个自然而然的逻辑是,通过领域常见数据训练出一个通用的模型,主要是学好领域通用信息;在面对某个具体场景时,只需要使用该场景数据做个小规模训练(微调)就可以了。这就是著名的预训练+微调的范式。
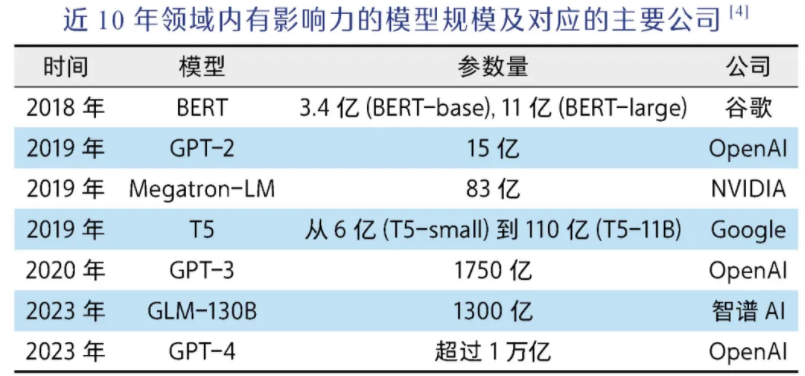
预训练+微调这一范式的出现与普及对领域产生了两个重大影响。一方面,在已有模型基础上微调大大降低了成本;另一方面,一个好的预训练模型的重要性也更加凸显,因此各大公司、科研机构更加愿意花大量成本来训练更加昂贵的基础模型。那么大模型的效果到底与什么因素有关呢?OpenAI在2020年提出了著名的Scaling Law,即当模型规模变大以后,模型的效果主要受到模型参数规模、训练数据规模和使用算力规模影响。
Scaling Law积极的一面是为提升模型效果指明了方向,只要把模型和数据规模做得更大就可以,这也是为什么近年来大模型的规模在以指数级增长,以及基础算力资源图形处理器(graphics processing unit, GPU)总是供不应求;但Scaling Law也揭示了一个让很多科学家绝望的事实:即模型的每一步提升都需要人类用极为夸张的算力和数据成本来"交换"。大模型的成本门槛变得非常之高,从头训练大模型成了学界的奢望,以OpenAI、谷歌、Meta、百度、智谱AI等企业为代表的业界开始发挥引领作用。
5.GPT的野心:
上下文学习与提示词工程
除了希望通过训练规模巨大的模型来提升效果以外,GPT模型在发展过程中还有一个非常雄大的野心:上下文学习(in-context learning)。
正如前文所述,在过去如果想要模型"学"到什么内容,需要用一大堆数据来训练我们的模型;哪怕是前文讲到的预训练+微调的范式,依然需要在已训练好的模型基础上,用一个小批量数据做训练(即微调)。因此在过去,"训练"一直是机器学习中最核心的概念。但OpenAI提出,训练本身既有成本又有门槛,希望模型面对新任务的时候不用额外训练,只需要在对话窗口里给模型一些例子,模型就自动学会了。这种模式就叫作上下文学习。
举一个中英文翻译的例子。过去做中英文翻译,需要使用海量的中英文数据集训练一个机器学习模型;而在上下文学习中,想要完成同样的任务,只需要给模型一些例子,比如告诉模型下面的话:
下面是一些中文翻译成英文的例子:
我爱中国 → I love China
我喜欢写代码 → I love coding
人工智能很重要 → AI is important
现在我有一句中文,请翻译成英文。这句话是:"我今天想吃苹果"。
这时候原本"傻傻的"模型就突然具备了翻译的能力,能够自动翻译了。
有过ChatGPT使用经历的读者会发现,这个输入就是提示词(prompt)。在ChatGPT使用已相当普及的今天,很多人意识不到这件事有多神奇。这就如同找一个没学过英语的孩子,给他看几个中英文翻译的句子,这个孩子就可以流畅地进行中英文翻译了。要知道这个模型可从来没有专门在中英文翻译的数据集上训练过,也就是说模型本身并没有中英文翻译的能力,但它竟然通过对话里的一些例子就突然脱胎换骨"顿悟"了中英文翻译,这真的非常神奇!
上下文学习的相关机制到今天依然是学界讨论的热点,而恰恰因为GPT模型具有上下文学习的能力,一个好的提示词非常重要。提示词工程逐步成为一个热门的领域,甚至出现了一种新的职业叫作"提示词工程师"(prompt engineer),就是通过写出更好的提示词让ChatGPT发挥更大的作用。
ChatGPT原理总结如下:
(1) ChatGPT本质是在做文字接龙的游戏,在游戏中它会根据候选词汇的概率来挑选下一个词。
(2) ChatGPT背后是一个非常庞大的神经网络,比如GPT-3有1700亿个参数(训练成本在100万美元以上)。
(3)基于庞大的神经网络,面对一句话时,模型可以准确给出候选词汇的概率,从而完成文字接龙的操作。
(4)这种有巨大规模进行语言处理的模型,也叫作大语言模型(large language model)。
(5)以GPT为代表的大语言模型具备上下文学习的能力,因此一个好的提示词至关重要。
理解了ChatGPT的原理,相信有读者会进一步提问:ChatGPT虽然很神奇但终归是一个语言模型,为什么大家对它抱有如此高的期望呢?
6.ChatGPT的未来:多模态的AI智能体
表面上看以ChatGPT为代表的大语言模型的能力是正确回答问题,实际上它可以像人类大脑一样对复杂问题进行准确的决策,这就打通了人类技术的所有环节。比如在自动化实验领域,过去我们花了很多时间研究可编程机器人和机器人的精确控制,希望能够用机器人取代人类做一些科学实验,但是最后发现终归还是要由科学家来确定具体合成实验的操作,并给机器人详细编码(硬件或者软件方式)。有了ChatGPT,科学家只需要说出自己的需求,ChatGPT会自动在文献库里搜索相关材料配方,然后编写相关机器人指令,并指挥机器人自动合成相关材料,从而实现真正意义上的自动化实验5。这种能够自动感知环境、做出决策并采取行动的AI机器人,被称为AI智能体(agent)。
4.DeepSeek (大语言模型 LLM)
DeepSeek-V3:对话系统、长文生成、复杂推理、代码辅助等
四、多模态大模型 (文本 + 图像 / 视频 / 音频)
CLIP:图文对齐
Flux、Midjourney:文生图
Sora、Pika:文本 / 图像生成视频
五、概念
1.大语言模型 LLM
大语言模型,是一种使用大量文本数据训练的深度学习模型。
大,指的是,模型的参数量大
2.原理

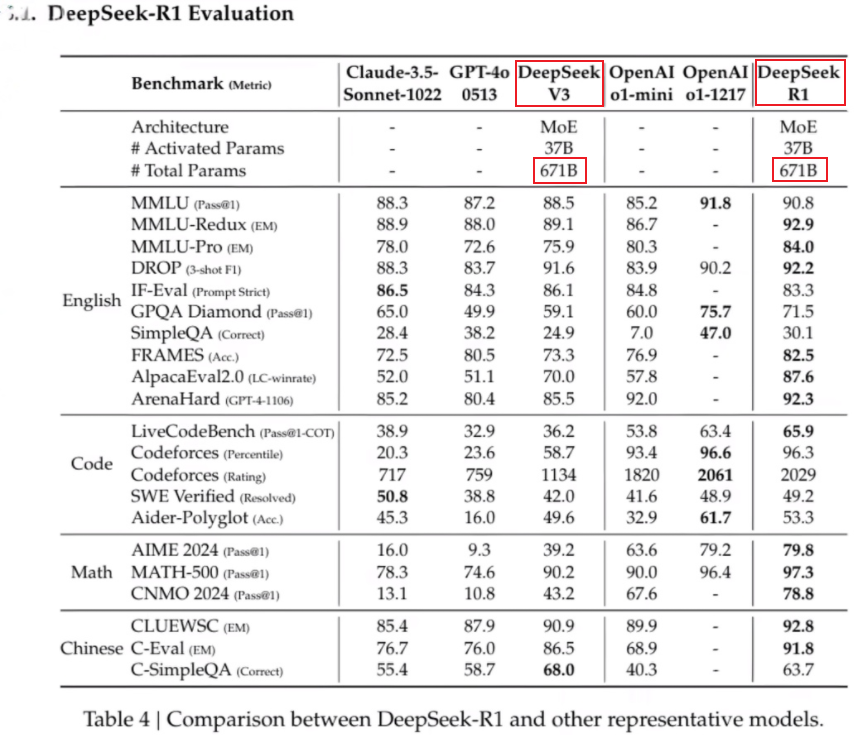
如DeepSeek R1模型,有671B (B指Billion,即6710亿) 个参数
3.知识蒸馏
(1)大模型、小模型、教师模型、学生模型
大模型蒸馏为小模型,部署在本地。
知识蒸馏(distill):是让"教师模型"把学习到的知识传授给"学生模型"的过程。
教师模型,一般是已经训练好的强大模型,比如"满血版R1"。虽然教师模型已经掌握了很多知识,但相应的缺点是体积庞大、运行缓慢、对部署和推理的要求很高 (如16张A100 80G NVIDIA显卡),在移动设备上就很难使用。而蒸馏就可以让我们基于教师模型,来训练一个体积更小、运算更快的"学生模型",适合在资源受限的设备上部署。
让学生模型不需要再从头开始学习。且学生模型仍然能够达到接近教师模型的准确率。
教师模型不仅给出答案,还给出思考过程。
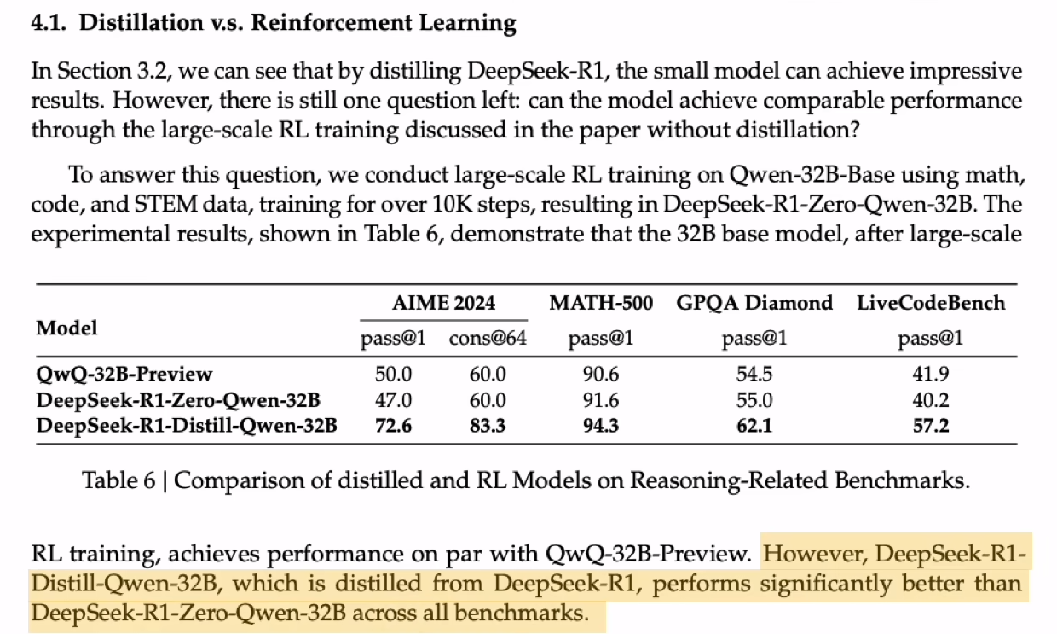
deepseek的论文提到,把R1模型蒸馏到小型模型中,比直接对小型模型进行强化学习,效果更好
4.知识图谱
知识图谱就是把世界上零散的知识,整理成「实体 + 关系」的结构化网络,让机器能像人一样理解知识、梳理逻辑。
(1)知识图谱是什么
知识图谱(Knowledge Graph, KG)
是一种用「图结构」来描述概念、实体、及其之间关系的知识表示方法。
它的目标是:
把零散、无结构的信息 → 变成机器能理解、能查询、能推理的结构化知识。
最早由 Google 在 2012 年提出,用来让搜索更 "懂意思",而不是只匹配关键词。
(2)知识图谱的构成:实体、关系、实体
知识图谱的基本结构:只有 3 样东西
知识图谱再复杂,本质都由 三元组(Triple) 构成:
实体 ------ 关系 ------ 实体
再配上属性描述细节。
(3)大模型和知识图谱的关系
大模型有幻觉,知识图谱绝对准确:
知识图谱的优势如下:
1.事实绝对准确,没有幻觉
2.推理能力强、可解释
3.更新极快:改一条知识立刻生效,不用重新训模型
4.隐私与安全可控:知识可以权限隔离,不会像大模型一样 "记在脑子里"。
5.多跳关联查询无敌
比如:"找出和 A 公司有间接持股、且在 3 个月内有异常交易的所有公司。"
传统数据库查不动,知识图谱秒出。
六、预训练+微调
🧠 预训练(Pre-training)
预训练是指在大规模无标注数据上对模型进行训练,使其学习到通用的语言或视觉特征。例如,BERT 和GPT等模型在海量文本数据上进行预训练,学习语言的基本结构和语义信息。
🔧 微调(Fine-tuning)
微调是在预训练模型的基础上,利用特定任务的有标注数据对模型进行进一步训练,以优化其在该任务上的性能。这一步骤通常需要较少的数据和计算资源,因为模型已经具备了通用的特征表示能力。
七、AI行业发展
胡润百富董事长兼首席调研官胡润表示:
"AI行业的真正启动,始于OpenAI首次发布了ChatGPT模型,由不到30岁的创始人Sam Altman领导,这一事件极大地提升了行业的关注度,并迅速推动了AI的普及化。然而,在这场AI革命中,英伟达无疑是最大的赢家。2022年12月,英伟达的企业价值还在3000多亿美元,仅仅两年后,其企业价值已经飙升至3.3万亿美元,实现了整整10倍的增长。"
胡润百富董事长兼首席调研官胡润提到的"OpenAI首次发布了ChatGPT模型"指的是OpenAI于2022年11月30日正式发布了基于GPT-3.5模型的ChatGPT。 这一发布迅速引发了广泛关注和讨论,成为AI行业的重要里程碑。OpenAI 于2022年11月30日 正式发布了基于GPT-3.5模型的ChatGPT 。 这一发布标志着AI行业的真正启动,极大地提升了行业的关注度,并迅速推动了AI的普及化。
OpenAI于2023年3月14日 发布了GPT-4模型 。 GPT-4是一种多模态大型语言模型,能够处理文本和图像输入,并生成文本输出。与之前的版本相比,GPT-4在多个专业基准测试中表现优异,展现了更强的理解和生成能力。
"根据AI领域两位泰斗斯图亚特·罗素(Stuart Russell)和彼得·诺维格(Peter Norvig)合著的经典著作《人工智能:一种现代的方法》,人工智能的核心目标是通过计算机程序或机器来模拟人类智能,涵盖语言理解、问题解决、学习、认知和决策等多方面能力。因此,AI的本质在于算力和算法的发展,而非依赖于物理形态。基于这一理念,本次榜单专注于非具身智能企业,排除了如机器人(例如优必选)、智能汽车(例如小鹏汽车)、智能飞行器(例如大疆)和智能家居(例如科沃斯)等具身智能企业。"
"理解AI的复杂分类和脉络,可以采取一个较为直观的方法:将OpenAI在2022年底推出的GPT-3.5模型作为一个标志性的分界点。在此之前,人们普遍理解的AI主要是'判定式AI',它侧重于感知智能,输出结果具有较高的确定性和可预测性,例如人脸识别和声音识别。而GPT-3.5模型的问世标志着我们正式迈入了'生成式AI'的新纪元,这一阶段的AI更侧重于认知智能,通过学习数据生成过程来创造新的数据,其输出结果具有显著的随机性和不可预测性,如AI绘图和AI写作。在上榜企业中,'生成式AI'与'判定式AI'的比例是1:5。"
2024胡润中国人工智能企业50强:https://www.hurun.net/zh-CN/Info/Detail?num=AFXL5ISUYV63